TP-AS: 一种面向长文本的两阶段自动摘要方法
2018-07-18汤大权
王 帅,赵 翔,2,李 博,葛 斌,2,汤大权,2
(1. 国防科学技术大学 信息系统工程重点实验室,湖南 长沙 410073;2. 地球空间信息技术协同创新中心,湖北 武汉 430079)
1 背景和相关工作
随着互联网的飞速发展,人们越来越多地依赖网络来获取所需要的信息。在用户普遍面临信息过载的后信息时代,如何更加有效地浏览和查阅互联网上的海量信息成了当前科学领域的研究热点。自动文本摘要技术利用计算机对海量文本进行处理,实现文本信息的压缩表示,产生简洁、精炼的内容,可以更好地帮助用户浏览和吸收互联网上的海量信息,降低用户信息负载,提高用户知识提取的效率。近年来,自动文本摘要技术在科技、情报、金融等领域的应用不断扩展和深入,是现今信息检索和自然语言处理领域的研究热点之一。
当前,文本自动摘要技术可大致分为两类——抽取式和生成式。抽取式方法的本质是对已有的句子进行排序和选择,通过提取文档中已存在的关键词和句子形成摘要;生成式方法则是通过建立抽象的语义表示,利用自然语言生成技术形成摘要[1]。传统的文本自动摘要技术多采用抽取式方法。例如,基于图排序的LexRank方法[2]对文本中的句子建立拓扑图结构,并从中抽取出关键句子作为摘要;基于动态主题建模的Web论坛文档摘要方法[3]建立动态主题模型,计算各句子权重得到文档的摘要;基于知识的文本摘要系统[4]建立知识库对知识进行表示处理从而生成摘要。
近几年,深度学习的迅速发展为生成式摘要提供了另一种可行的模型框架。基于循环神经网络(recurrent neural network,RNN)的sequence-to-sequence(seq2seq)[5]的文本生成模型已应用在自然语言处理的各种领域,包括机器翻译[6-7]、语音识别[8]等。该模型构建在编码器(encoder)—解码器(decoder)的框架上,在两段文本序列之间架设一条文本表示学习和语言生成模型的桥梁,是目前最流行的自动摘要方法之一。早期将RNN这种网络结构应用在文本自动摘要领域的Rush等人和Nallapati等人,提出了基于RNN编码器—解码器框架的生成式文本自动摘要模型[9-10],并在实验结果上使摘要的准确率显著提高。Hu等人提出的RNN方法[11]为中文LCSTS数据集[11]提供了对比的基准。最近,Copynet方法[12]提出了复制机制(copying mechanism)以解决文本生成模型中的词表溢出(out of vocabulary,OOV)问题;而MRT方法[13]则将评价指标包含在优化目标内,大大地提高了该模型结果的准确率。
研究发现,基于RNN seq2seq的生成式文本摘要方法一般只适用于处理短文本,对稍长的输入序列的处理能力十分有限。其原因在于,过长的文本输入序列会导致编码器端无法准确地提取输入文本的语义信息,产生长距离依赖问题,最终导致模型无法收敛。此外,该模型还需占用大量的计算资源,时间开销较大。我们还注意到,应用RNN编码器—解码器框架在中文数据集LCSTS上达到领先水平的Copynet和MRT方法,对输入文本长度的处理能力也只有100~150个字。但是,在实际的自然语言处理应用中,针对短文本进行摘要的意义有限,而用户更加关注长文本摘要的能力,以帮助其提高阅读和汲取信息的效率。因此,现有的生成式文本摘要模型还无法在实际中得到良好的应用。
针对长文本自动摘要的问题,本文提出了一种两阶段的自动摘要方法TP-AS(two-phase automatic summarization),包含关键句抽取和摘要生成两阶段。在关键句抽取阶段中,在基于图模型[14]的文本排序方法LexRank之上,提出一种改进的混合文本相似度计算方法。具体地,将句子向量(sentence vector)[15]和文本编辑距离(edit distance)[16-17]结合,共同用于图模型中句子间的相似度计算,进而筛选出关键句子。在摘要生成阶段,在RNN编码器—解码器框架下,设计添加了注意力(attention)[6-7]和指针(pointer)[18]处理机制以提高摘要生成的效率和准确度。具体地,在编码器端,利用注意力机制为目标词生成带注意力偏差的动态变化语义向量,使得模型可以学习输出序列到输入序列的一个软对齐(soft alignment)[6-7];在解码器端,运用指针机制解决摘要生成中出现的OOV问题。为验证模型有效性,采集了新浪新闻的财经板块*http: //finance.sina.com.cn/的中文文本数据,利用历史数据构建了200个词的专有词表,并利用ROUGE[19]评价指标和其他自动摘要方法进行对比。实验结果表明,TP-AS方法在长文本摘要任务上的性能超越了现有方法,具备实用潜力。
本文的主要贡献包括以下三个方面。
(1) 针对长文本自动摘要的挑战,提出了一种两阶段方法TP-AS,综合了抽取式和生成式方法的优势;在笔者浅薄的学识范围中,TP-AS是唯一采用两阶段策略来解决文本自动摘要问题的方法。
(2) 在关键句抽取阶段,设计了一种混合语义层面和字符层面的文本相似度计算方法;在摘要生成阶段,将注意力机制和指针机制集成到RNN模型中,提升了摘要质量。
(3) 针对金融领域的真实应用,采集和整理了一个大规模长文本数据集;在其上,开展了实验评测,横向比较分析了六种主流文本摘要方法;结果显示TP-AS在ROUGE指标上优于其他现有方法。
本文组织结构如下,第一部分为文本自动摘要的背景知识和相关工作;第二部分详细介绍我们提出的两阶段文本摘要方法TP-AS;第三部分介绍实验准备,并对实验结果进行对比分析;第四部分总结全文,给出进一步工作方向。
2 模型与方法
本节介绍设计的两阶段方法,首先概述方法框架,其次详述两阶段涉及的主要模型结构。
2.1 TP-AS方法框架
如前所述,抽取式的自动摘要方法得到的摘要语句通顺,且在语法上几乎不需要修改,但是抽取出来的关键句子含有大量的冗余信息,并且句子连贯性不强,可读性较差;另一方面,生成式的自动摘要方法,对于长文本无法准确提取其语义信息,可能导致模型无法收敛,难以处理长文本,实际运用的场景有限。鉴于此,考虑一种结合上述两种方法优势的两阶段方法,互补地提高整体摘要性能。
模型的具体框架由图1所示,由两个阶段组成。
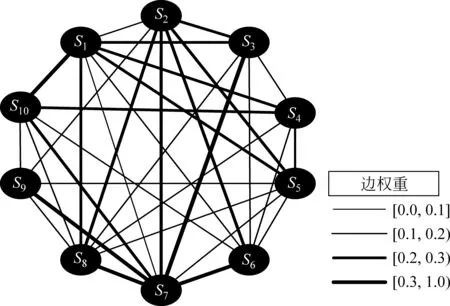
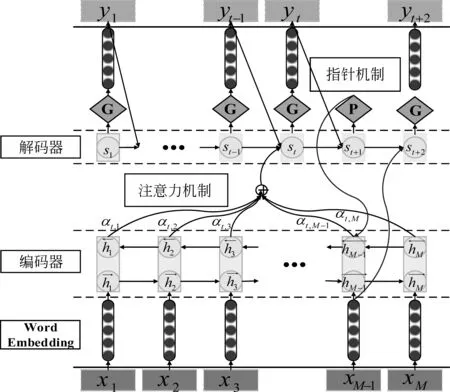
(1) 关键句抽取: 假设输入的文章d={s1,…,sL}中包含L个句子,第一阶段问题解决如何从中抽取出关键的句子,即从d中抽取K个关键句子(K (2) 摘要生成: 把抽取得到的文本序列x输入文本自动生成模型,输出一段较短的文本序列y={y1,…,yN},其中N (1) 其中,θ表示模型参数,y 在关键句抽取阶段,结合图模型,提出一种混合文本相似度计算方法,据此对句子进行排序和抽取,其模型结构如图2所示。具体地,首先利用图模型将文本转化为拓扑图结构,图中的每一个节点Si表示一个句子,用相连的边的权值大小来表示节点所对应句子之间的语义相似度,在图中用节点之间连线的粗细程度表示。然后,利用PageRank[20]算法迭代计算,得到每个节点(句子)的重要度打分。最后,按照得分高低输出句子,并按照其在原文中的出现顺序重新排列,得到可以描述原始信息的关键句。 (1) 相似度计算 相似度的计算准确与否,会直接影响关键句子的重要度打分。传统方法采用TF-IDF方法,但是TF-IDF无法计算词之间的语义相似度,只是对字符序列的重合度的简单统计。因此,考虑提出一种基于文本编辑距离和句子向量相结合的方法来计算句子之间的相似度,前者表示了句子在字符层面上的相似度,而后者描述了句子在语义级别的相似度。 文本编辑距离,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数;许可的编辑操作包括: ①将一个字符替换成另一个字符; ②插入一个字符; ③删除一个字符。直觉上,编辑距离越小,两个字符串的相似度越大。 图2 关键句抽取模型结构 句子向量则由词的分布式表示(distributed representations)[21]计算得到。与词向量的训练框架类似,将句子表示为一个特征向量,再将句子向量和词向量拼接,去预测上下文中的下一个词。句子向量可以被视为另一个词,相当于存储器,用于存储文本中句子主题或者上下文中词向量遗失的信息。在预测阶段,需要对新的句子进行推理,计算得到它的句子向量,经过训练得到的句子向量可以作为句子的特征表示。因此,通过计算两个句子向量之间的余弦函数值可得到两个句子之间的相似度,即余弦相似度;余弦函数值越大,则相似度越大。 由此看出,一方面,编辑距离可以较好地描述句子字符层面相似度;另一方面,句子向量方法更倾向于语义级别的相似度计算。因此,结合上述两种相似度,得到最终的相似度计算方法。 给定两个句子Si和Sj,句子中任意一个词为wk,V(Si)和(V(Sj)分别代表其句子向量,则两个句子之间的相似度sim(Si,Sj)由式(2)计算得出。 α×cosine(V(Si),V(Sj))+(1-α)×Lev(Si,Sj) (2) 其中,α代表计算相似度时语义层面相似度的权重大小,Lev(Si,Sj)表示两个句子的编辑距离大小,cosine(V(Si),V(Sj))表示两个句子向量之间的余弦相似度。 (2) 打分策略 打分策略的算法在谷歌公司PageRank算法的启发下,利用投票的原理让每一个节点为它的邻居节点投赞成票,票的权重取决于节点本身的票数。本文打分策略的算法借鉴了PageRank的做法,采用矩阵迭代收敛的方式解决。在此算法中,由节点及节点间的链接关系可构成一个无向的网络图。假如构成的图结构为G=(V,E),由节点集合V和边的集合E组成,对于一个给定节点,In(Vi)代表其入度,Out(Vi)代表其出度,Wij代表Vi和Vj节点之间的边的权重,在这里Wij的大小根据两个句子Si和Sj间的相似度sim(Si,Sj)来计算。根据PageRank算法,图结构中节点的得分可以定义为式(3)。 (3) 其中,d的取值范围是0~1,代表了阻尼系数,其意义是迭代到达任意节点,继续向下迭代的概率,通常取0.85。一般经过20~30次该算法就可以达到收敛,最终根据节点权重值大小就可以为每一个节点打分。 在摘要生成阶段,将抽取的关键句输入到RNN 编码器—解码器模型中,得到最终的摘要文本,其模型结构如图3所示。 图3 摘要生成模型结构(含注意力机制和指针机制) 在一个RNN编码器—解码器框架中,输入源序列x={x1,…,xM}被编码器端转换成一个固定长度的向量c;即, ht=f(xt,ht-1);c=φ(h1,…,hM) (4) 解码器端主要用于解码语义向量c,按照时序生成一段文本序列,具体过程表示如式(5)、式(6)所示。 其中,st代表在t时刻RNN的状态,yt代表在t时刻生成的目标词,而yt-1表示已经生成的历史文本序列。由式(6)可知,生成目标词的概率与当前RNN状态的输出、已经生成的目标序列和编码器端的语义向量三者有关。解码器端的文本生成模型的实质是对词表进行分类,通过优化损失函数,可以在解码器端生成输出向量。该向量代表将要生成的词yt的特征,向量经过一个softmax函数后,概率最高的特征所对应的词表中的词就是要输出的结果。 (1) 注意力机制 seq2seq虽然相比传统的n-gram统计模型更具非线性刻画能力,但其也有自身的缺点。主要缺点主要有两个: 第一是长程记忆能力有限,如果输入句子序列非常长,那么由于梯度更新中衰减较大,导致序列头部的参数无法得到有效更新。第二是序列转换过程中的无法对齐,从输入序列到目标序列过程中,解码器的输入始终是一段固定的特征向量,并不是按照位置的检索。 所以,在上述模型基础上,本文引入注意力机制,旨在解码器端生成目标序列时可以选择性地读取语义向量的信息。注意力机制针对目标序列中不同词的语义向量使用不同的权重进行筛选,为目标序列生成带注意力偏差的动态变化语义向量,使得模型可以学习目标序列到输入序列的一个软对齐(soft alignment)[6-7],最终达到优化模型的目的。 由于语义向量c的确定将直接决定解码器每一时刻的输入特征,那么,c一定与解码器的特征有关。同时c对解码器不同位置的特征具有筛选功能,而具体筛选哪些语义向量进行读取,是应该由编码器和解码器的自身状态共同决定的。筛选的过程需要对编码器的特征进行加权,加权因子可以通过解码器的状态与编码器的状态进行匹配而得到。具体来说,首先,我们需要对解码器当前的状态与编码器的所有位置的状态的匹配度进行打分,由网络自己学习得到权重向量Zα。然后,由于我们想得到的是归一化以后的权重因子,因此在得到权重向量之后,我们需要对它进行归一化,从最大似然概率的角度出发,我们采用的是softmax归一化函数。最后,得到归一化因子后,直接将其与编码器的隐含状态相乘,即可得到解码器在每一步的上下文特征信息。 假设在生成第t个目标词yt的时刻,其输入端的语义向量为ct,如式(7)所示。 (7) 其中,hi代表从编码器输出的隐层状态,αti代表在生成目标词yt时输入序列第i个词xi对生成目标词的影响力的大小。αti的计算方法如式(8)所示。 αti=softmax(Zαtanh (Wαst -1+Uαhi)) (8) 其中,Zα代表权重向量,Wα和Uα分别代表权重矩阵。 (2) 指针机制 针对OOV问题,选择频率最高的一部分词来组成词表,不在词表中的词用UNK来代替。接着,利用指针机制来处理OOV问题。具体地,在解码器端设置一个指针开关,用来决定目标词yt是由RNN生成还是由输入文本相对应的词直接复制而来。解码器端的输出文本序列中若出现OOV的词,指针开关将为复制模式P,编码器端会产生一个指针,指向输入文本相对应的词,并复制过来作为目标词输出。否则指针开关为生成模式G,解码器端会输出一个向量,从词表中生成一个目标词。模型采用注意力分配矩阵来决定每一个指针指向输入文本的位置,利用偏置的线性激活函数sigmoid决定指针机制是否启用。 因此,假设在第i时刻,指针机制可表示为式(9)。 P(si)=σ(ZT(Whhi+WeE[oi -1]+Wcci+b)) (9) 其中,P(si)指开关打开为指针机制的概率,E[oi -1]指前一状态输入文本的词向量,ZT为权重向量,Wh、We和Wc为权重矩阵。 本节介绍实验方案,并对比和分析实验结果。 采用自行设计的主题爬虫真实采集的中文数据集为实验数据集,大小为2.5GB,其中包含1MB篇文章和相应的标题。该数据全部为金融领域的数据,主要包括新浪网2010~2016年的金融板块新闻文本,以证券、股票、基金、上市公司等系列数据为主。每一篇文章篇幅长度L均较大(500~1000),因此属于典型的长文本。若干数据示例如表1所示。 (1) 数据预处理 首先,根据金融领域历史数据中常见的人名、公司名及相应的专有名词,人工构建了200个词的专有词表,明显提高了分词的准确率,从一定程度上解决摘要生成过程中的OOV问题。接着,去除了结构化不规整的数据和篇幅过长(L>1 000)或者过短(L<200)的数据,剩余0.8MB条数据作为实验数据。根据对文本按照字符处理和按照词语处理把数据分成两种情况,在词语处理中使用的是结巴分词工具*https://pypi.python.org/pypi/jieba。在字和词的词表大小的设置上,分别选择了3 000个常用字和10 000个常用词,其中包括人工构建的专有词表。参照LCSTS数据集[11]的方法,将处理过后的数据按照98%、1.8%和0.2%的比例分为三部分,分别为训练集、验证集和测试集,测试集有1 600条数据,用于评测摘要的效果*该实验数据集将在后续公开,供下载使用。。 表1 文本数据示例 续表 在关键句抽取阶段,选择PageRank算法作为图结构上的迭代算法,阻尼系数d设置为0.85,抽取的关键句子个数设置为3,在计算句子相似度时,选择语义层面相似度权重为α=0.75,表示更注重语义层面的相似度大小。 在摘要生成阶段,程序构建于谷歌开发的tensorflow*https: //www.tensorflow.org/的模型框架上,并选择Bi-GRU作为RNN编码器端和解码器。经多次实验探索,最终将网络层数分别设置为5层和3层,有利于模型迅速收敛,提高训练速度。使用句子向量模型预先训练好的词向量作为编码器端的输入,词向量的维度为300维,训练时Batch-Size设置为64。在解码器端使用Beam-Search算法[5-6]解码,对于生成的向量在词表中迅速找到最优解,根据文献[5-6]中的最优结果设置,将Beam-Size设置为10。 关于生成摘要的评价方法,采用自动评价矩阵ROUGE,该方法可以计算机器摘要和标准摘要二者中重复单元的个数(n-gram)来评价机器摘要的质量。ROUGE-N是n-gram召回率,即在标准摘要和机器摘要里均出现的n-gram占标准摘要中所有n-gram的比例。其计算如式(10)所示。 (10) 其中,n为n-gram的长度,Countmatch(n-gram)为n-gram同时在标准摘要S和机器摘要中出现的次数,而Count(n-gram)为n-gram在标准摘要S中出现的次数。评价中,采用了n=1和2的结果。 在真实数据集上,对RNN、RNN context、Copynet方法及MRT方法进行对比: (1) RNN方法[11]在编码器端和解码器端直接运用RNN,构建了一个标准的seq2seq学习框架,其结果作为实验评价的基准; (2) RNN context[11]是在RNN方法基础上,在编码器端加入了注意力机制的方法; (3) Copynet方法[12]在RNN context基础之上,添加了复制机制,试图解决文本生成方法中的OOV问题; (4) MRT方法[13]使用最小风险化方法进行训练,而不是传统的最大似然估计,其将评价指标包含在优化目标内,更加直接地对评价指标做优化; (5) 基于图模型的TextRank[24]方法,即直接从输入文本序列中抽取关键句子作为摘要的方法。 具体的对比实验结果如表2所示,其中Word表示按照词语处理,Char表示按照字符处理。 表2 实验结果 从表2中可以看出,TP-AS模型框架针对长文本表现出较好的处理能力,对比RNN(word)和MRT在ROUGE-1上的提升分别达20.4%和2.5%,而在ROUGE-2上的改进则达到19%和1.7%。由于RNN、RNN context、Copynet、MRT等方法均属于基于RNN seq2seq的文本生成模型,而RNN在处理长文本时,输入的文本序列过长会产生梯度消失或者梯度爆炸的现象,也会产生长距离依赖等问题,其编码器端无法准确地表达输入文本序列的语义信息,从而极大地影响模型的训练效果。即使截取开头或者结尾的一部分文本当作输入序列,虽然减少了序列长度,但是简单的截取开头和结尾会损失文本中的大量有用信息,所以输入序列和文本的标准摘要有差距,进而影响机器摘要生成的准确度。 图4考查了训练时间开销的Log-loss随着训练次数递减情况。从图4中可以明显看出TP-AS模型在迭代一万次左右的时候就已经几乎收敛,而其他的方法的Log-loss值波动较为明显,训练速度慢,模型收敛效果差。由于增加了金融领域的专有词表,大大提高了分词的准确率,并且使用了指针机制,良好地避免了出现OOV的情况,从而使得在词级别的机器摘要质量明显高于字符级别的质量。生成的机器摘要部分示例如表3所示。 图4 Log loss曲线 综上,在TP-AS方法框架下,先基于句子向量和编辑距离混合的语义相似度计算方法,应用图模型对句子排序抽取得到关键句,然后针对关键句进行摘要生成模型建模,不仅训练速度快于现有主流方法,自动摘要的效果亦优势明显。 表3 摘要结果示例 针对长文本数据给自动摘要带来的困难与挑战,研究提出了两阶段方法TP-AS框架。该方法集成了关键句抽取和文本生成法的优势,在处理长文本时性能提升效果显著。在真实金融领域的数据上,实验对比分析了主流方法,TP-AS方法在准确性达到了最好的效果。 下一步,我们计划从如下两个方面继续深入探索: (1) 在生成式方法中,基于RNN的seq2seq方法是一个纯数据驱动的RNN结构,需要大量的训练数据。但是,这在实际的自然语言处理应用中通常是无法满足的,因此考虑如何结合传统的自然语言处理技术,如语法分析、语义分析、句法分析等,来表达语义信息,从而可以达到利用少量训练数据构建文本自动生成模型的目标。 (2) 关系抽取和事件抽取可以迅速得到文本的主干信息,以便于迅速分析和抽取不同文档的关键句子,减少噪声信息的影响。因此,可考虑将信息抽取技术中的关系抽取和事件抽取的方法结合到TP-AS方法的关键句抽取阶段,从而将模型扩展应用到多文档多主题自动摘要任务上。2.2 阶段一: 关键句抽取
2.3 阶段二: 摘要生成
3 实验与结果
3.1 数据集与预处理


3.2 参数设定
3.3 评价方法
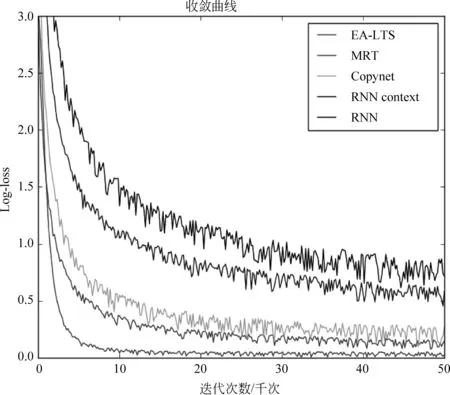
3.4 实验结果


4 结论与下一步工作
