基于小波包与长短时记忆融合的铁路旅客流量预测模型①
2018-07-18成强
成 强
(重庆交通大学 信息科学与工程学院, 重庆 400074)
随着政企分开以及中国铁路总公司的成立, 铁路系统已经迎来改革发展“新常态”. 客运经营作为铁路改革的重头戏, 重点就是要加强对于短期市场变化的应对能力, 及时获取相关客运需求信息, 实时调整客运服务机构, 而这就要求我们提高对于短期客运量的预测精度.
短期客运量预测是以月度或者日度客运量变化为预测对象, 研究短期内客运量的波动情况. 由于短期客运量受多种随机因素影响, 相比长期客运量具有明显的非线性、随机性和波动性[1], 这在一定程度上增加了预测难度. 在类似客运量时间序列预测方面, 小波分析和神经网络相结合的方法收到广泛关注, 而深度学习[2]的飞速发展又为客运量时间序列的预测提供了新的研究思路和方法.
深度学习的概念由Hinton等于2006年提出. 深度学习神经网络提供了高维数据空间和低维嵌套结构的双向映射, 有效解决了大多数非线性降维方法所不具备的逆向映射问题. 杨祎玥等[3]将小波分解和循环神经网络RNN应用在时间序列的预测中, 探索了水文时间序列的预测精度. 但是小波分解仅仅将低频特性持续分解, 而且循环神经网络RNN存在梯度消失和梯度爆发的缺点; 然而小波包分析 (Wavelet Packet Analysis,WPA)不仅对低频部分进行分解, 而且还对高频部分进行分解, 且长短时记忆神经网络LSTM[4]是在RNN的基础上的改进模型, 可以有效处理梯度消失和梯度爆发的问题.
因此, 本文利用长短时记忆神经网络LSTM的时间序列预测能力, 结合小波包分析方法, 建立了一个基于小波包分析的长短时记忆神经网络的铁路客运量时间序列预测模型.
1 小波包分析
1.1 小波包的定义
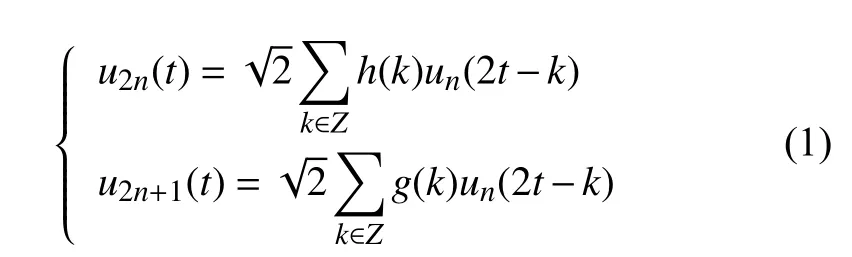
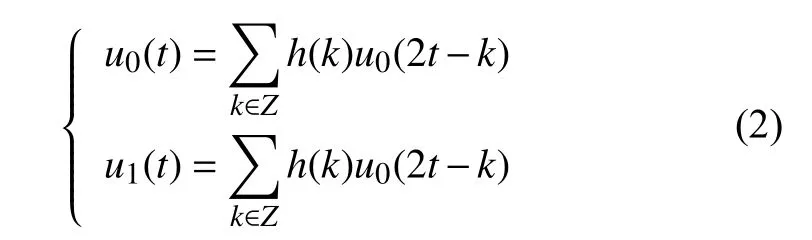

1.2 小波包对时间序列的分解特性


图1 小波包对时间序列的分解
1.3 小波包算法
为了小波包简单地说就是一个函数簇, 它定义为正交尺度函数确定的函数簇. 设则可表示为(其中是尺度参数,、l是平移参数,是频率参数, 且

小波包分解算法:

由 即:

2 深度循环神经网络
深度循环神经网络 (Deep Recurrent Neural Network,DRNN)本质上是一种通常意义上的深度神经网络(多层感知机), 其特点是每层都有时间反馈循环, 并且层之间是叠加构成的. 每次神经网络的更新, 新信息通过层次传递, 每层神经网络也获得了时间性上下文信息.
然而传统的DRNN模型, 在训练过程中, 梯度下降更加倾向于按照序列结尾处的权值的正确方向进行更新. 也就是说, 越远的序列输入的对权值的正确变化所能起到的“影响”越小, 所以训练的结果就是往往出现偏向于新的信息, 即不太能有较长的记忆功能.
由此引出本文将要介绍的LSTM (Long Short-Term Memory, 长短时记忆)递归神经网络, 该算法使用LSTM结构替换了一般的递归神经网络的隐藏层节点, LSTM 结构增加了输入门 (Input gate)、输出门(Output gate)、遗忘门 (Forget gate)和一个内部单元(Cell). 其中LSTM结构如图2所示.
输入门: 表示是否允许输入层的信息进入到该隐藏层节点. 门开的则允许输入层输出信号进入, 门关则不允许信号进入, 记为. 输出门: 表示是否将当前节点的输出值输出到下一层. 门开的则允许该隐藏层节点的信号输出, 门关则不允许信号输出, 记为. 遗忘门:表示是否保留当前隐藏层节点存储的历史信息. 门开的则保留当前隐藏层节点存储的历史信息, 门关则不保留当前隐藏层节点存储的历史信息, 记为表示t时刻存储的信息值,表示时刻存储的信息值,在模型中t时刻的输出值将作为时刻的输入进行预测, 输出层与DRNN的输出层一致. 基于长短时记忆结构的递归神经网络模型结构如图3所示.

图2 LSTM 结构
3 预测模型结构
利用小波包分析方法对铁路旅客流量时间序列进行预处理, 进行多尺度小波包分解和单支重构, 可获得不同的高频和低频序列, 对预处理的数据进行相空间重构后作为LSTM模型的训练数据, 建立一个基于小波包分析的长短时记忆神经网络的铁路旅客客流量时间预测模型, 称为WPA-LSTM模型.
WPA-LSTM预测模型结构如图4所示.
首先将时间序列数据进行小波包分解和单支重构成多条序列, 然后分别输入LSTM模型进行预测, 最后将预测值叠加成最终预测值[7].
WPA-LSTM模型建立过程如下:
(1) 数据准备. 先选取历史旅客流量日数据, 对数据进行归一化处理, 并且保存其最大值和最小值.
(2) 小波分解和单支重构. 选择合适的小波包函数和分解初度, 对旅客流量时间序列进行多尺度小波包分解和单支重构, 获得该序列的近似系数和各细节系数, 然后对这些系数分别进行单支重构, 获得一条能够描述原始序列趋势变化的低频序列和保留不同信息的高频序列.
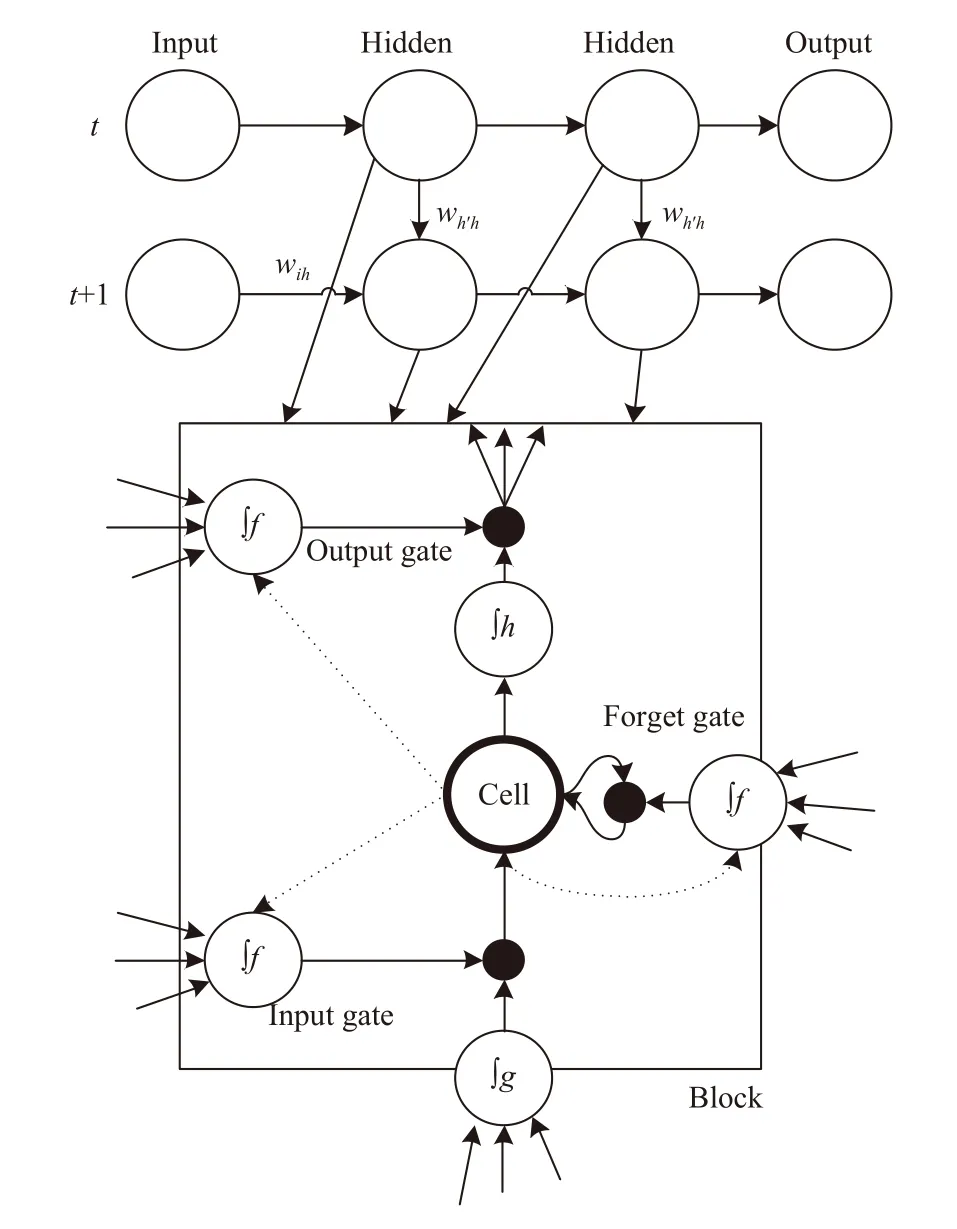
图3 基于长短时记忆结构的递归神经网络模型结构
(3) 相空间重构. 设置相空间重构的延迟数值, 分别对低频序列和各个高频序列进行相空间重构, 以此形成相应的训练数据和测试数据.
(4) LSTM模型训练. 设定LSTM的学习速率、网络层数和每层的节点数目, 利用相空间重构的多组训练数据分别对LSTM模型进行训练.
(5) 预测客流量. 用训练好的LSTM模型对子序列的测试样本进行预测, 并将各子序列的预测值进行叠加, 从而得到最终的预测值, 这样就实现了对铁路旅客流量时间序列的建模和预测.
4 实例分析
以某高铁上, S1到S2方向的2015年12月28日到2017年1月15日, 共计367天的日旅客流量数据为例, 来研究基于小波包分析的LSTM神经网络预测模型. 然后, 又利用了自回归积分滑动平均模型[8](ARIMA)和基于经验模态分解[9,10](EMD)的LSTM神经网络模型进行预测, 并将其预测结果与基于小波包分析的LSTM神经网络模型进行比较. 其中, 训练数据为2015年12月28日到2016年11月3日的295组经过相空间重构的数据, 测试数据为2016年11月4日到2017年1月15日, 共计72组数据.
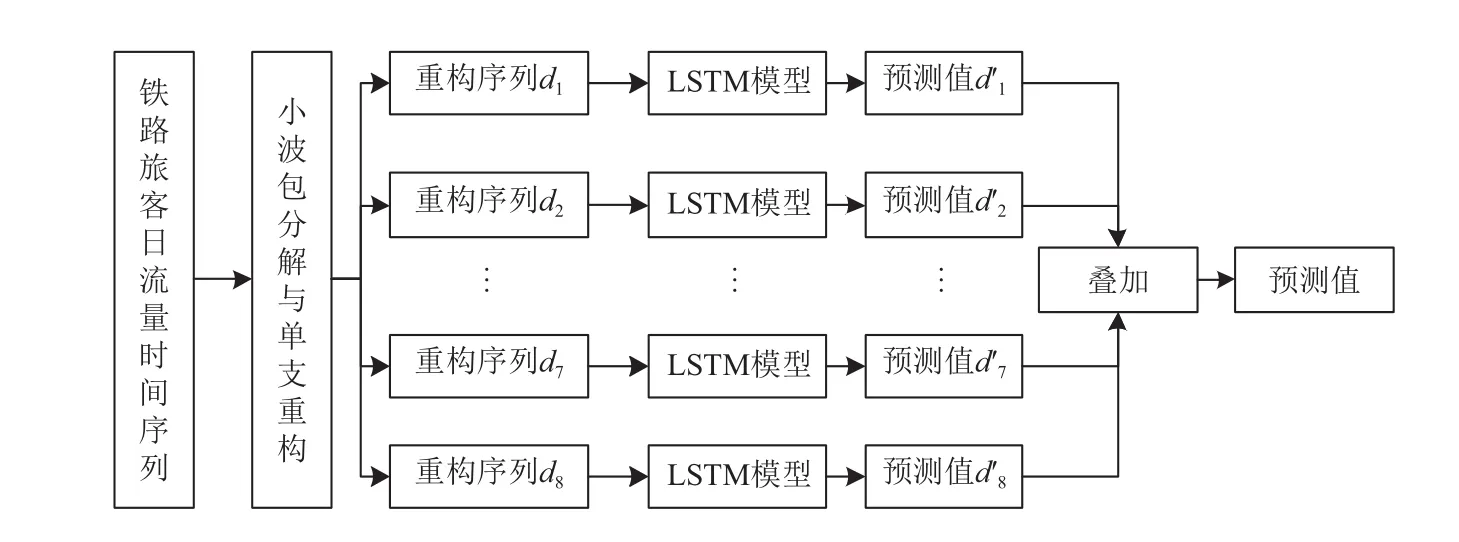
图4 WPA-LSTM 预测模型结构
4.1 小波包分解结果
首先, 对数据进行归一化处理, 以提高数据在训练过程中的收敛速度. 在这里使用Max-Min归一化方法,对于序列中的最大值和最小值对序列中所有元素有:

再挑选合适的小波包分解参数, 将原始信号合理的分解到恰当的多个频段上. 这里使用Daubechies小波1(db1), 对其进行小波包分解和单支重构, 其中单支重构后的情况如图5–图7所示.
其中, 第一条曲线为原始序列曲线, 另外八条为db1小波包分解并进行重构后的8个不同尺度的序列.这些序列能够捕捉到原始序列轻微的扰动, 将原始序列中突发性、局部性、隐藏性的信息保留在其中.
4.2 预测结果分析
各模型预测的结果如图8所示, 预测性能指标如表1所示.
通过对比拟合程度(R值)可知, WPA-LSTM模型最优, 其次是ARIMA模型, 最后是EMD-LSTM模型;通过对比归一化均方误差(NMSE)可知, WPALSTM模型最优, 其次是ARIMA模型, 最后是EMDLSTM模型; 通过对比平均绝对百分比误差(MAPE)可知, WPA-LSTM 模型最优, 其次是 ARIMA 模型, 最后是EMD-LSTM模型; 综合考虑上述三项指标, WPALSTM的预测精度最高.
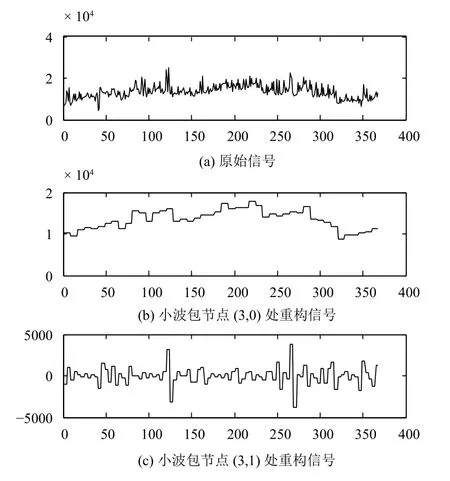
图5 旅客流量原始序列与db1分解后的信号对比图1
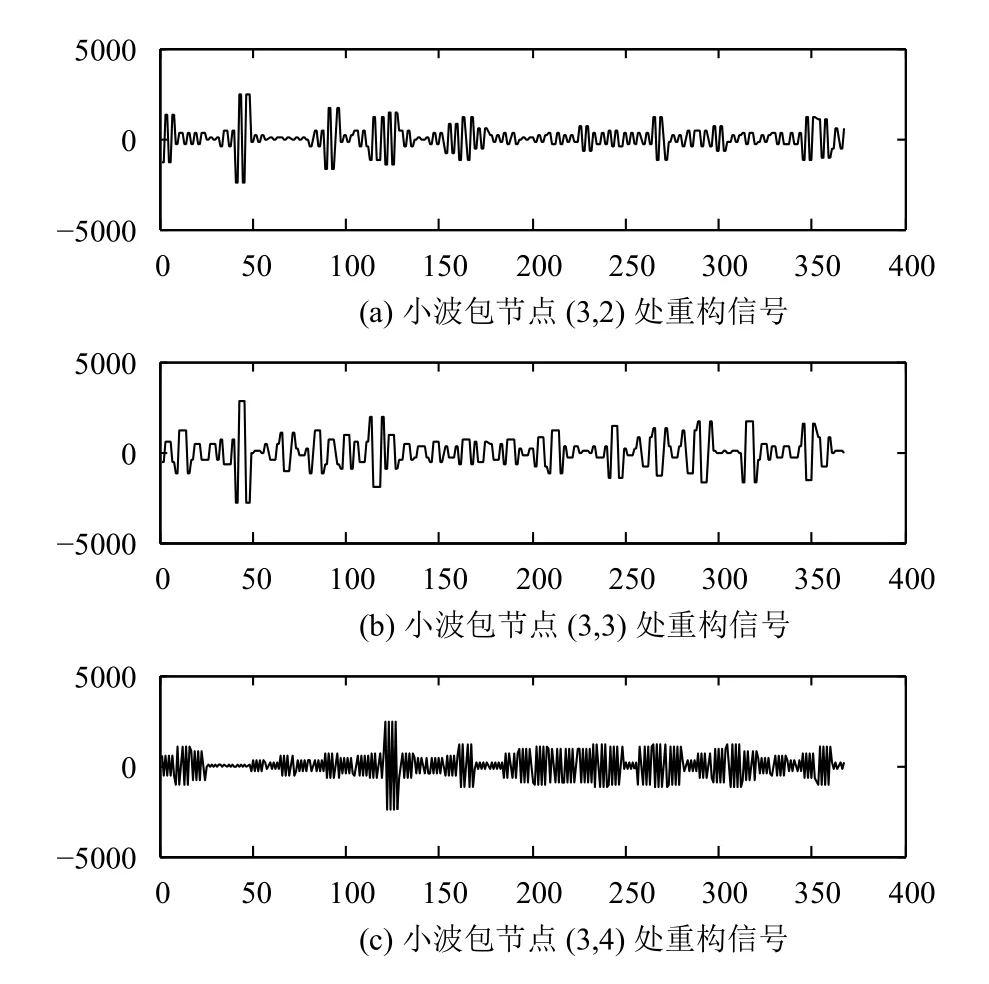
图6 旅客流量原始序列与db1分解后的信号对比图2

图7 旅客流量原始序列与db1分解后的信号对比图3
4.3 误差分析
首先, 进行分日期的绝对预测误差对比, 如图9所示. 可以看出, ARIMA模型在对2017年元旦附近,特别是2016年12月30日这一天和2017年1月2日这一天的预测误差较大, 最大值为7000人; EMDLSTM模型也是在2017年12月30日这一天的预测误差最大, 最大值甚至达到了7800人, 而且EMDLSTM模型的绝对误差明显多数高于其他两个模型;而WPA-LSTM模型的绝对误差相对稳定, 在预测时段内没有特别剧烈的变化, 分布相对较平稳.
5 结论与展望
将基于小波包分析和长短时记忆神经网络融合的深度学习预测模型用于铁路旅客日流量的预测中, 实验结果证明, 比利用季节性模型ARIMA和基于经验模态分解的长短时记忆神经网络预测模型有着更好的逼近能力和容错性, 有效降低了预报误差, 提高了模型的预测精度, 具有较强的预报和泛化能力.

图8 各模型预测结果对比

图9 预测值绝对误差对比
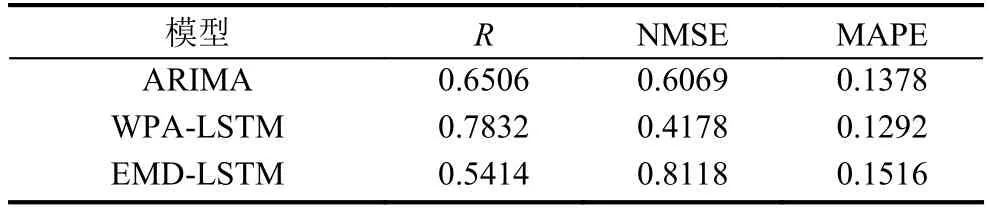
表1 各模型的预测性能指标

表2 各模型误差分布 (单位: %)
