一种基于记忆网络的多轮对话下的意图识别方法
2018-07-16杨成彪吕荣荣吴刚
文/杨成彪 吕荣荣 吴刚
1 引言
随着人们生活水平不断的提高。以智能对话机器人为代表的人工智能设备的出现立刻受到了大家的欢迎,当然成功的背后,这个市场并非看起来那么顺利,还有很多技术还未成熟。单轮对话下的任务处理还存在诸多的瓶颈,而多轮对话下需要克服的问题还没有引起广大研究人员的重视。
对话系统特指能完成类似人与人的沟通任务的计算机系统,最早被提出是在1950年,Alan Turing提出了著名的图灵测试,其目的是使用人机对话的方式检验机器是否具有智能。由于人类交流时酝酿语言的过程较短,句法结构比较简单,多用短句和省略形式,对话的内容很难在单轮对话中交代清楚,意图通常隐含在多轮对话中。这就需要有一种模型可以将这些对话的历史信息利用起来,本文我们提出了一种新的基于记忆网络的框架来解决多轮对话下意图识别问题。
2 相关研究

表1:训练数据的分类结果
在对话系统中有大量的研究是关于非精确条件下的意图理解,在实际应用场景中,无论是语音识别还是人的语言表述都是非精确的,这无形之中大大增加了对话系统应用的难度,机器人对用户的意图理解也就成为对话系统的核心环节。
早期的语义理解通常是基于规则(rulebased),但是由于输入语言的非精确性,错误率比较高。后来以数据驱动的基于统计学习的方法,例如基于统计机器翻译的语义理解,隐矢量状态模型,条件随机场,深度学习等,在意图理解的准确性上有了显著的提高。
多轮对话系统中意图识别的关键是对历史交互信息的存储和处理,记忆网络是一种神经网络模型,已被成功地应用于很多自然语言任务中了,例如问答系统,语言建模以及对话。记忆网络中的存储器部分可以嵌入长期记忆(例如,关于真实世界的常识)和短期上下文(例如,最近的几段对话)。短期上下文的记忆可以采用内部记忆方式和外部记忆方式。循环神经网络的记忆是内部记忆方式,其依靠RNNCell或者LSTMCell实现,但是记忆能力有限,一般最多记忆十几个时间步长。而外部的记忆方式可以任意增加加入模型的知识量,同时对模型本身做出最小限度的改变。通过在传统的模型中添加独立存储器,作为一种神经网络能够按需读写的知识库,来增强模型。该方法通过记忆网络和forget gate,引入历史信息实现多轮对话的意图识别。
3 模型
3.1 算法框架
多轮对话系统下的意图识别算法框架分为四个模块:编码模块、记忆模块、控制模块和分类模块,如图1所示。
Encoding即为编码模块,该模块用于将非量化的文本用实数向量映射到量化空间,编码器采用LSTM网络结构。Memory即为记忆模块,该模块采用外部存储方式存储历史信息,利用注意力机制从当前对话的历史信息中抽取与当前对话意图相关的信息。Forget gate即为控制模块,可以控制历史信息的引入。Classifier即为分类模块,多轮对话的意图识别问题应看成是多标签分类问题。
3.2 编码模块
采用了Word Embedding机制,将文本数据映射到一个低维度的实数向量,避免了高维度的输入导致LSTM模型产生维度灾难的问题。同时Word Embedding机制训练出的词向量具有同义词向量相似的特征,作为LSTM模型的输入可以大大提高分类器的性能。
3.3 记忆模块
为了存储当前对话的历史信息,需要将历史信息Xh的每轮对话Xhi通过LSTMmem编码为连续向量空间的向量。

当前对话Xc通过LSTMin编码为连续向量空间的向量。

在系统中,LSTMmem和LSTMin共享权重,一起用于编码历史信息和当前对话文本,这样更有利于序列信息的信息编码。
历史信息中有些与当前对话的意图相关,很多与当前对话的意图无关,无区别的引入将导致很多噪声的引入,这就需要引入注意力模型来判断。当前对话的u和历史信息中的mi的相关程度通过两个向量之间的内积表示,历史信息中每轮对话与当前对话的相关程度值的集合经过softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。公式如下:

其中softmax函数为:

3.4 控制模块
多轮对话系统中,对话意图识别有些情况中需要参考历史信息,而有些情况下仅仅依靠当前对话就可以判断出意图。对于能够直接判断出意图的对话,其引入历史信息相当于引入大量噪音。forget gate通过计算一个状态值来控制是否引入历史信息,公式如下:

通过sigmoid 函数产生一个0到1之间的值g,当g接近0,表示意图识别不需要参考历史信息;当g接近1,表示意图识别需要参考当前信息。
3.5 分类模块
多轮对话的意图识别问题应看成是多标签分类问题,深度学习在多标签问题的解决方法上,已取得优异的成绩。本系统参考BPMLL设计了一套符合本网络的分类器,将对话向量u和历史向量h结合进行分类。激活函数设置为sigmoid,使得预测概率限定在(0,1)之间,得到预测标签向量o,其维度为标签集合大小。公式如下:
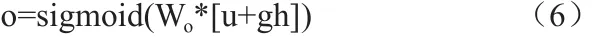
3.6 反向传播
该网络系统的目标函数采用binary cross entropy,n表示样本的总数,x表示样本,yi表示目标标签向量的第i维度,oi表示预测标签向量的第i维度,目标标签向量y和预测标签向量o是维度为标签集合大小的向量。公式如下所示:
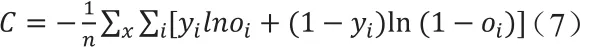
4 实验
本实验采用的数据集来自微软旗下Maluuba公司在2017年5月发布的多轮对话公开数据。该数据集包含1369个有关旅行规划的对话片段,共有20000多个对话轮次。
本文在该数据集上进行了三个模型的意图识别实验,Encoder-classifier和Memory-classifier两个模型作为本文设计的MemoryAndGate-classifier的对比实验。Encoder-classifier将上下文信息通过双层的LSTM模型编码后和当前对话的LSTM编码向量连接。Memory-classifier利用LSTM网络和外部记忆网络结合注意力机制编码上下文信息后和当前对话的LSTM编码向量连接。MemoryAndGate-classifier利用LSTM网络和外部记忆网络结合注意力机制编码上下文信息后通过forget gate判断是否和当前对话的LSTM编码向量连接。
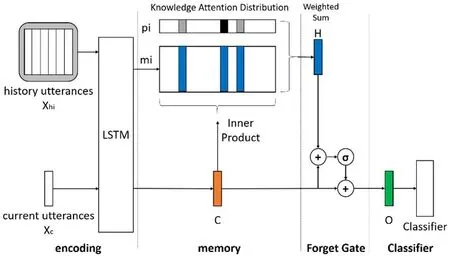
图1:算法框架图
实验在准确率和召回率两个评估测度上进行,表1是本文模型与对比方法的实验结果,实验结果表明针对多轮对话的意图识别,采用外部记忆网络结合注意力机制能够更好的利用上下文信息辅助识别当前对话的意图,Memory-classifier和MemoryAndGate-classifier在效果上分别比Encoder-classifier提高了6.8%和9.0%。
5 结语
本文针对多轮对话的意图识别设计基于记忆网络的深度学习模型,从本实验的解析结果中可以发现,改进后的模型在多轮对话的意图识别上效果有所提升。但模型仍然有一些问题需要继续研究,对上下文信息的抽取仅考虑了与意图相近的信息,没有考虑与意图有依赖关系的信息。后续可以通过改进注意力机制从上下文信息中抽取这部分信息,提升意图识别的效果。
