基于标签分组和码分多址的帧时隙ALOHA算法*
2018-07-13王红军王伦文
何 烜,王红军,王伦文
(国防科技大学电子对抗学院,合肥 230037)
0 引言
射频识别(Radio Frequency Identification,RFID)技术作为物联网感知层的核心技术之一,是一种通过电磁波自动识别目标的技术[1]。其基本原理是利用天线间的近场耦合或反向调制耦合的方式来传递信息,以实现对目标物体的认证。与传统的识别技术相比,射频识别技术具有操作简单、穿透性强和自动化程度高等优点,在物流、门禁、工业生产、智能仓库以及车联网等领域得到广泛应用。
在实际应用中,经常会有大量标签等待识别,当读写器发出请求命令后,标签就会立刻响应该读写器,标签碰撞问题不可避免。很多学者对标签防碰撞问题展开了研究,主流算法分为两大类:基于二进制树的搜索算法和时隙ALOHA算法[2]。基于二进制树的搜索算法是利用曼彻斯特的编码特性去识别标签ID的碰撞位,然后通过不断确定碰撞位从而可以识别此标签。但是读写器修改多次碰撞位只能识别一个标签,则该算法吞吐率较低,识别时间长,性能较差,难以对大量标签进行识别。动态二进制树搜索(Dynamic Binary Search,DBS)算法[3]、自调整混合树(Adjustive Hybrid Tree,AHT)算法[4]对该算法进行了改进,改进算法在识别效率上有一定的提升,但依然存在识别时间长的问题。
时隙ALOHA算法是让标签在不同时隙内响应,当某个时隙内只有一个标签响应时,则读写器可成功识别此标签。然而当标签数量很多时,多个标签会在同一时隙中响应,则会出现碰撞,读写器就无法成功识别。针对此算法的改进算法有很多,如帧时隙 ALOHA(Frame Slotted ALOHA,FSA)算法[5]、基于标签分组的帧时隙ALOHA(Grouped Frame Slotted ALOHA,GFSA)算法[6]、动态帧时隙 ALOHA(Dynamic Frame Slotted ALOHA,DFSA)算法[7]及基于FSA或者DFSA算法的改进算法[8-9]等。文献[8]对DFSA算法进行改进,提出分组动态帧时隙ALOHA(Grouped Dynamic Frame Slotted ALOHA,GDFSA)算法,该算法将标签分组方法应用到DFSA算法中,但是其吞吐率没有超过DFSA最大吞吐率36.8%这一范围;文献[9]将二叉树算法和FSA算法结合起来,在碰撞时隙中利用二叉树算法进行识别,其不足在于读写器在利用二叉树算法对碰撞时隙里的标签识别时,会影响下一时隙内的标签识别。
针对上述算法的缺陷与不足,本文提出基于标签分组和码分多址的帧时隙ALOHA(Frame Slotted ALOHA based on TagGroupingand CDMA,G-CD-FSA)算法。该算法将标签分组算法与码分多址技术高效的应用到帧时隙ALOHA算法中,具有良好的性能。本文先对算法中的核心方法进行阐述,再对算法进行理论分析,最后进行仿真对比实验并对实验结果进行分析。
1 算法描述和实现
算法首先通过标签分组控制标签响应的数量,即使标签数量很多,只要进行合理分组,标签之间的碰撞概率也会降低许多;然后将帧时隙ALOHA算法与码分多址技术有效融合,可以使读写器具备在同一时隙中处理多个标签的能力。
1.1 标签分组准则
在对标签进行分组之前,首先对标签数量进行估计,数量估计的目的是为了对标签进行合理分组。可以采用Vogt算法[10]实现标签数量估计。估计方法是读写器发送一个帧长为L的试探帧,读写器范围内的标签进行响应。此时,时隙会呈现3种状态:碰撞时隙、成功识别时隙和空闲时隙。读写器将帧中的碰撞时隙、成功识别时隙与空闲时隙的个数与理论期望值作比较,当误差最小时,就可以确定标签数量。具体实现公式如下:
其中,a0、a1、ak分别为空闲时隙、成功识别时隙和碰撞时隙的理论期望值,c0、c1、ck为实际测量值。理论期望值可以进行如式(2)确定。设帧长为L,因为N个标签中有m个标签响应同一时隙的概率服从二项分布,则:
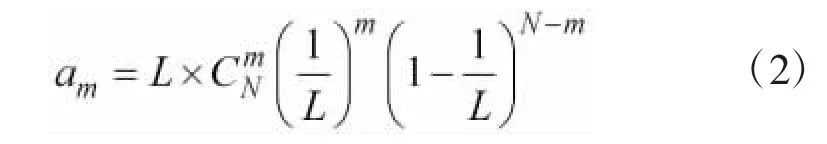
当m=0时表示空闲时隙,m=1时表示成功识别时隙,其余为碰撞时隙,可以表示为:

可根据式(1)~式(3)估计出标签数量。因为帧长L确定,只有N为未知变量,取误差最小时的N,就是标签的估计数量。
标签数量已知后,可以对不同数量的标签进行合理分组。分组原则如下:以吞吐率为标准,当分组后的吞吐率大于分组前的吞吐率,则进行分组,否则不分组。
设N为标签数量,L为固定帧长,s为扩频码的个数,吞吐率Ps可以表示为:
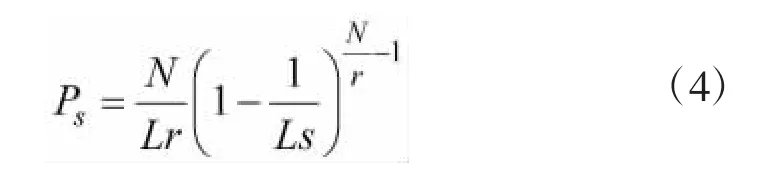
设分为r1组的吞吐率大于分为r2组的吞吐率,则将大量标签分为r1组。设r1>r2,比较过程如下式:
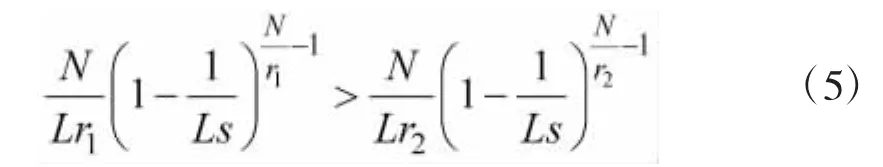
可化简为:
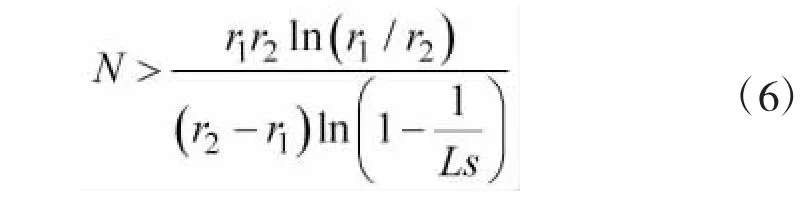
根据式(6),可以确定不同分组数下的标签数量区间。由上文分析可知,标签数量可以估计出来,则可以反推该标签数量下合适的分组数,从而可以确定分组数。
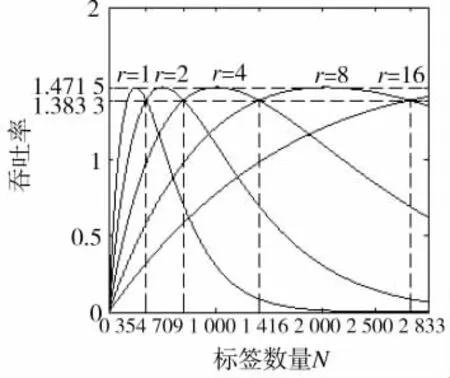
图1 不同分组数下的吞吐率
图1表示本文算法不同分组数下的吞吐率,从而可以分析不同分组数下所对应的合适的标签数量区间。实验参数设置为:标签数量N=3 000,帧长L=64,扩频码个数 s=4,r分别取 1、2、4、8、16 等。
从图1可以看出,不同分组数下的吞吐率曲线的交点即是临界标签数量,当N≤354时,则不分组,当354<N≤709时,则平均分为两组,依此类推。如表1所示,表1对图2进行了总结归纳。临界标签数量也可以通过式(6)计算出来,从而验证了理论推导的正确性。

表1 不同标签数量范围下的分组情况
1.2 帧时隙ALOHA算法与码分多址技术有效融合
经过合理分组后,读写器利用帧时隙ALOHA算法对每组标签进行识别,帧时隙ALOHA算法是时分多址防碰撞算法,其原理为:读写器发送一个请求帧,设帧长为L,标签收到读写器的命令后,在(0,L-1)之间随机选择一个数,随机数为0的标签在0号时隙立即响应,响应结束后,随机数为1的标签在1号时隙响应,依次进行。然而标签选择的数具有随机性,则可能会出现多个标签在同一时隙响应,使用该算法就无法识别。可将码分多址技术融合到该算法中,利用不同的扩频码对标签ID进行调制,当多个标签在同一时隙响应时,读写器利用扩频码的正交性识别不同的标签,这样可以识别更多的标签。如图2所示。

图2 标签响应示意图
设扩频码的个数为4,图2中0-L-1表示帧的时隙号,1、3、5、0表示在不同时隙内响应的标签数量,S、I、C表示成功识别时隙、空闲时隙和碰撞时隙。在1号时隙只有1个标签响应,则被成功(success)识别;在4号时隙没有标签响应,则该时隙为空闲(idle)时隙,在2号和3号时隙中,分别有3个和5个标签响应,则出现碰撞(collision),只能通过码分多址技术来进行区分。由于标签尺寸和存储量小等原因,要使扩频码在射频识别系统中易于实现,一般只使用数量有限的扩频码[11]。使用数量有限的扩频码,不仅对标签的硬件电路改动小,而且可以降低读写器的计算复杂度。然而码分多址技术并不一定能全部识别碰撞时隙内的标签,当碰撞时隙内的部分标签同时使用了相同的扩频码进行调制,即在时域和码域同时发生碰撞,此种情况下,读写器无法进行全部识别,只能识别该时隙内使用不同扩频码调制的标签,未被成功识别的标签只能在下一帧中继续响应读写器。
将帧时隙ALOHA算法与码分多址技术结合起来,可以很好地解决处于碰撞时隙中的标签识别问题,从而提高算法吞吐率。
1.3 算法步骤
综合标签分组原则、帧时隙ALOHA算法和码分多址技术等关键方法的分析,可将算法步骤进行如下总结:1)读写器先发送试探性的帧,对标签数量进行估计。估计出标签数量后,再根据标签数量所在的区间范围,确定分组数,进行合理分组。2)读写器发送帧长为L的请求帧,则只有一组标签进行响应。这一组之内的每个标签在(0,L-1)随机选择一个数加载自身的时隙计数器,只有自己的随机数和时隙号相同才去响应读写器,响应时将经过扩频码调制后的信号发送给读写器,否则处于等待状态。3)读写器从0号时隙到L-1号时隙依次识别,并进行判断,如果某一时隙中只有一个标签响应,则直接读取标签的ID;如果某一时隙内没有标签响应,则跳过此时隙,进行下一时隙的识别;如果某一时隙内有多个标签响应,则出现碰撞。4)利用码分多址技术对碰撞时隙内的标签进行区分,只有使用不同扩频码的标签才能被惟一确定,然后读取这些标签的ID,使用相同扩频码的标签则不能被识别。5)被成功识别的标签则处于静默状态,即不再响应读写器。未被成功识别的标签则在下一帧中继续响应读写器。当一组标签全部被识别后,再进行下一组标签的识别,直到标签全部被识别为止。
2 算法性能分析
吞吐率越大表明该算法在一定帧长中所处理的标签数量就越多,则该防碰撞算法的性能就越好,因此,本节仅对本文算法吞吐率进行推导,从理论上对算法的性能进行分析。
假设有N个标签,标签被分为r组,分组过程服从均匀分布,那么每组的标签数量为k=N/r,读写器发送的帧长为L,则k个标签中有m个标签在同一时隙的概率为:
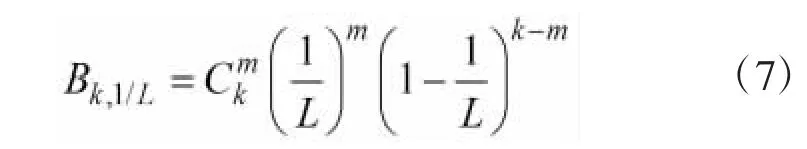
不同的标签采用不同的扩频码也服从均匀分布,设扩频码的数量为s个,则同一时隙中,第i个标签使用第j个扩频码进行调制的概率为:
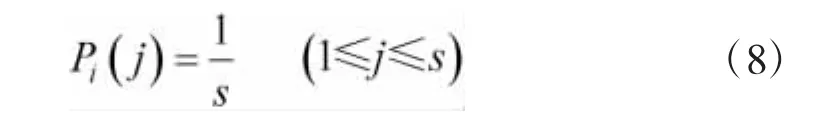
如果有m个标签选择同一时隙,因为m个标签使用的扩频码具有随机性,则只能用均值c来代替[12]。则在同一时隙里被成功识别的均值c为:
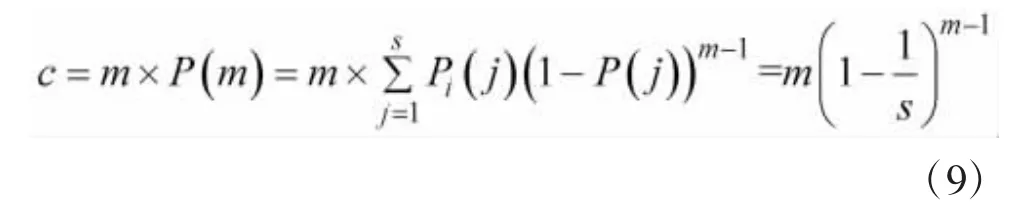
因为不同数量的标签响应同一时隙时,被成功识别出其中某个标签或几个标签都存在一定概率,从概率角度分析,则在标签分组和码分多址条件下的吞吐率Sc应是不同数量的标签响应情况的总和为:
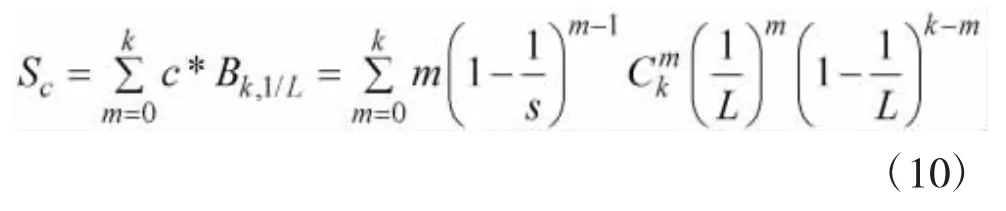

求Sc对t的偏导,则其另外一种表达式为:
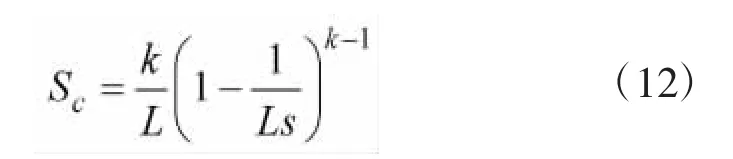
式(12)和式(4)一样,从而严格证明了本文算法的吞吐率。为求吞吐率的最大值,可令其对k的导数为0:

可得:
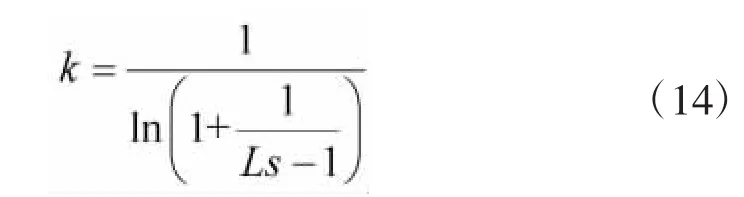

当满足式(15)时,可以得到最大吞吐率。将式(15)代入式(12),则吞吐率最大值为:
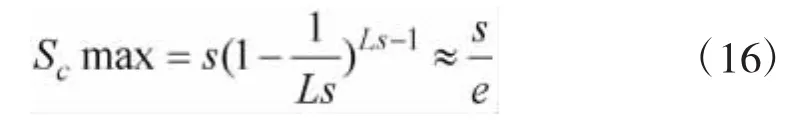
由式(16)可以得知:本文算法吞吐率的最大值为s/e。从理论分析可知,由于将码分多址技术和FSA算法有效融合,本文算法的最大吞吐率是FSA算法的s倍。此外,本文算法还利用标签分组技术对大量标签进行合理分组,当标签数量较多时,吞吐率不会随着标签数量的增多而急剧下降,依然保持较高的吞吐率。
3 仿真实验和分析
在本次仿真实验中,主要对以下两个方面进行仿真:1)吞吐率。如果该算法的吞吐率越大,则其性能越好。2)所需总时隙数量和碰撞时隙数量。在实际情况中,成功识别时隙、碰撞时隙和空闲时隙所消耗的时间是不同的,其中碰撞时隙消耗的时间最长,其次是成功识别时隙,最后是空闲时隙。当某种算法所需的总时隙数量少,而且碰撞时隙数量也少,则代表该算法的识别时间短,则性能越好。本文主要进行了2组仿真实验,来探讨本文算法的效果。第1组实验将本文算法与其他算法进行吞吐率的比较;第2组实验是识别相等数量的标签,本文算法与其他算法所需要的总时隙数量和碰撞时隙数量进行比较。实验采用Matlab2013仿真软件,进行了1 000次的仿真实验。
3.1 不同算法的吞吐率比较
主要对分组帧时隙ALOHA(GFSA)算法、动态帧时隙ALOHA(DFSA)算法、分组动态帧时隙ALOHA(GDFSA)算法、基于码分多址的帧时隙ALOHA(CD-FSA)算法和本文算法进行了仿真实验分析。参数设置如表2所示,其中DFSA算法和GDFSA算法中帧长的动态调整是根据Schoute算法[13]调整的。实验结果如图3所示。
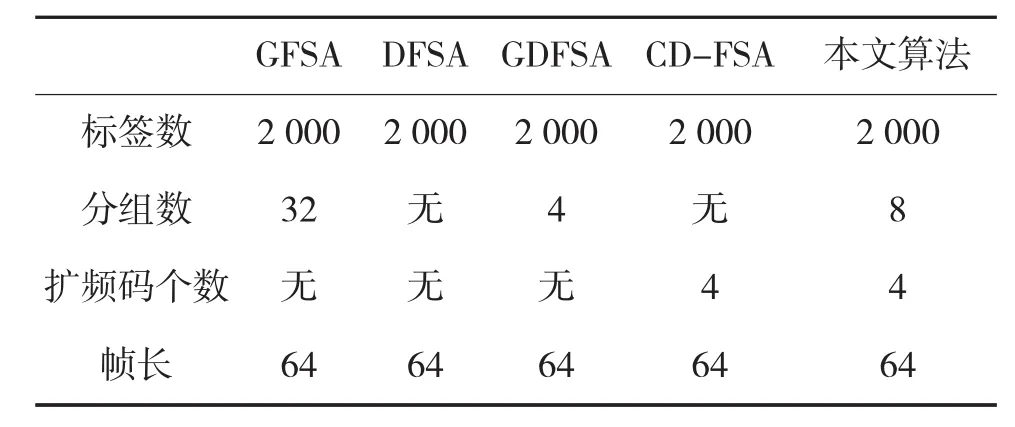
表2 各算法参数设置
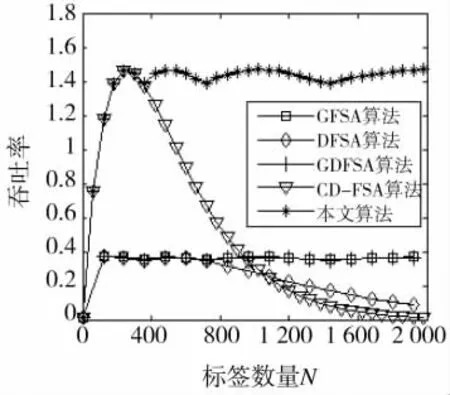
图3 不同算法吞吐率比较
从图3中可以看出,本文算法一直保持较高的吞吐率。本文算法与CD-FSA算法相比较,本文算法有标签分组的过程,通过合理分组,控制了标签响应的数量,碰撞变少,那么在相同扩频码数量下准确识别的标签数量就会增加,所以依然保持很高的吞吐率。而CD-FSA算法没有这一过程,当标签数量很大时,其吞吐率迅速下滑,所以当标签数量为2 000时,该算法吞吐率趋于0。本文算法与GDFSA算法相比,本文算法结合了码分多址技术,所以吞吐率保持在s/e附近,而GDFSA算法只能保持在36.8%附近。综上所述,本文算法在吞吐率方面优于其他算法。
3.2 所需总时隙数量和碰撞时隙数量仿真比较
由于CD-FSA算法在标签数量为2 000时,吞吐率趋于0,性能很差,难以全部识别,所以在本次实验中不再对其进行实验分析。本次实验将本文算法和GFSA算法、DFSA算法和GDFSA算法进行比较,实验环境与实验1相同,参数设置与表2相同,来探讨各个算法所需的总时隙数量和碰撞时隙数量,实验结果如图4和图5所示。
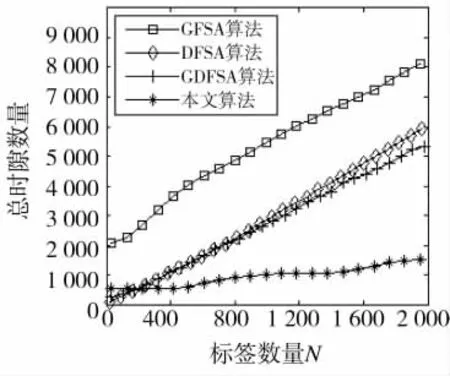
图4 不同算法所需的总时隙数量
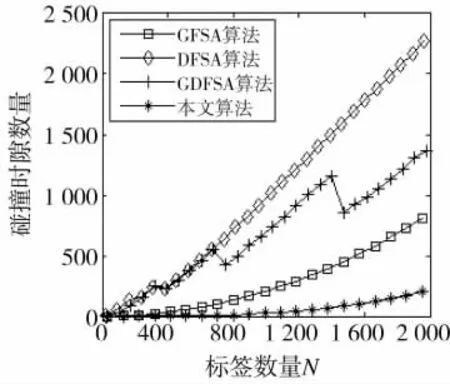
图5 不同算法下碰撞时隙数量比较
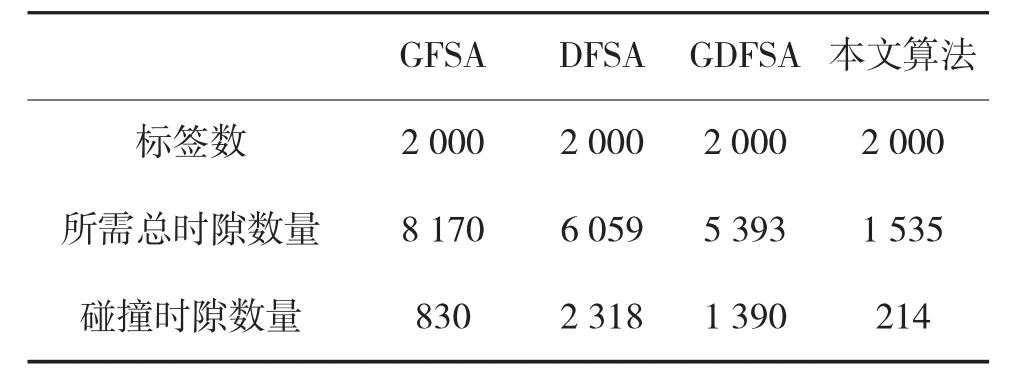
表3 N=2 000时所需时隙数量比较
如图4和图5所示,随着标签数量的增大,各个算法所需的总时隙数量和碰撞时隙数量也在增大,然而本文算法增大的速度慢,主要因为本文算法控制了标签的响应数量,而且应用了码分多址技术,在碰撞时隙内也可识别标签,所以本文算法在所需总时隙数量和碰撞时隙数量上都明显优于其他算法。表3是标签数量为2 000时,各个算法所需的总时隙数量和碰撞时隙数量比较。从表中可以看出,本文算法识别所需的总时隙数量少,而且碰撞数量也很少,从而验证了本文算法的优势。
4 结论
本文提出了一种新型的射频识别防碰撞算法,即基于标签分组和码分多址的帧时隙ALOHA算法,通过对大量标签进行合理分组,再将帧时隙ALOHA算法与码分多址技术有效融合,这样不但可以对大量标签进行识别,而且可以对碰撞时隙内的标签进行识别。理论分析和仿真实验都表明:本文算法具有较高的吞吐率,而且所需总时隙数量和碰撞时隙数量少,即识别时间短,优于其他ALOHA算法,具有一定的实际应用价值。
