基于协同过滤的图书推荐系统构建研究
2018-07-12刘剑桥
刘剑桥
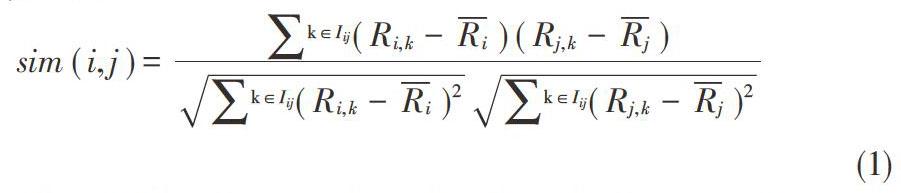
摘要:在当今社会环境下,图书的种类和数量急速增加,读者想要准确、快速地找到自己感兴趣的图书越来越困难。随着信息技术的快速发展,高校图书馆开始借助于数据挖掘技术为读者提供更好的服务,图书推荐系统应运而生。该文将对基于协同过滤的图书推荐系统构建进行研究,主要从图书推荐系统的体系结构、功能结构和核心的协同过滤推荐算法进行研究,为将来实际开发基于协同过滤的图书推荐系统提供理论基础和技术支持。
关键词:图书;数据挖掘;推荐系统;协同过滤
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)14-0186-02
Abstract: In today's social environment, the number and type of books are increasing rapidly. It is more and more difficult for readers to find the books they are interested in accurately and quickly. With the rapid development of information technology, university libraries began to use data mining technology to provide readers with better services. Book recommendation system came into being. This paper will study the construction of book recommendation system based on collaborative filtering, mainly from the architecture, function structure and collaborative filtering recommendation algorithm of the book recommendation system, and provide theoretical basis and technical support for the actual development of book recommendation system based on collaborative filtering in the future.
Key words: books; data mining; recommendation system; collaborative filtering
1 背景
在当今社会环境下,图书的种类和数量急速增加,读者想要准确、快速地找到自己感兴趣的图书越来越困难。读者检索图书,检索结果可能成千上万,读者需要花费很大的时间和精力去寻找自己想要的图书;另外,读者的需求也各种各样,不同专业、不同爱好的读者对图书的需求不同,传统的图书检索系统不能满足读者的个性化需求。随着信息技术的快速发展,高校图书馆开始借助于数据挖掘技术为读者提供更好的服务,图书推荐系统应运而生。
图书推荐系统就是利用读者信息、图书信息和读者的历史借阅信息来预测读者可能感兴趣的图书,产生图书推荐结果,为读者提供个性化的服务[1-2]。个性化推荐算法主要有协同过滤推荐算法、基于内容的推荐算法、基于图结构的推荐算法和基于数据挖掘的推荐算法。协同过滤推荐算法的基本假设是:为读者推荐感兴趣的内容可通过找到与该读者偏好相似的其他读者,将他们感兴趣的内容推荐给该读者[3]。协同过滤技术是目前推荐系统中研究最多、应用的最广泛,同时也是推荐效率比较高的一种个性化推荐技术。
该文将对基于协同过滤的图书推荐系统构建进行研究,主要从图书推荐系统的体系结构、功能结构和核心的协同过滤推荐算法进行研究,为将来实际开发基于协同过滤的图书推荐系统提供理论基础和技术支持。本系统的实施将帮助读者提高检索效率,快速找到自己感兴趣的图书,满足读者对图书个性化的需求。
2 图书推荐系统的体系结构
基于协同过滤的图书推荐系统采用多层分布式的体系结构,如图1所示,具体包括4个层次:表示层、Web服务层、应用服务层、数据库服务层[4]。
1)表示层:主要是系统外部人员与图书推荐系统的交互界面,负责对系统的信息输入、输出和显示。
2)Web 服务层:主要负责对图书推荐系统表示层传来的各种服务请求的处理和处理后的信息发布。
3)应用服务层:主要负责图书推荐系统中业务的事务处理和逻辑运算处理,根据具体业务提供不同的Web服务。
4)数据服务层:主要负责图书推荐系统中所涉及的各种数据的存放、数据组织与数据库的管理。
3 图书推荐系统的功能结构图
该文设计的图书推荐系统的主要功能模块有读者模块和管理员模块。读者模块主要包括热门图书排行、专业图书推荐和个性化图书推荐;管理员模块主要包括读者管理、图书管理和通知公告管理。功能结构图如图2所示。
1)热门图书推荐:根据图书的借阅信息,推荐读者借阅次数最多的图书排行。
2)专业图书推荐:根据读者的专业和图书的借阅信息,推荐读者专业方向借阅次数最多的图书排行。
3)个性化图书推荐:这一部分是图书推荐系统的重要核心部分,采用协同过滤推荐算法,根据图书的借阅信息,建立读者图书矩阵,计算讀者的相似度,找到相似的读者;假设相似的读者兴趣相同,生成图书推荐结果。
4)读者管理:增加读者、修改读者和删除读者。
5)图书管理:增加图书、修改图书和删除图书。
6)通知公告管理:增加通知公告、修改图书公告和删除图书公告。
4 基于协同过滤的图书推荐算法
协同过滤技术是目前推荐系统中研究最多、应用的最广泛,同时也是推荐效率比较高的一种个性化推荐技术[5-6]。协同过滤技术分为基于用户的协同过滤和基于项目的协同过滤,该文采用基于用户的协同过滤推荐方法。该方法假设读者可能喜欢和他具有相近爱好读者所喜欢的图书,该算法开始将读者的历史行为构建成读者图书矩阵,接着选定目标读者并计算每一位读者和目标读者的相似度,然后查找最近邻居集合,当得到该读者的邻居集合后,便可进行评分预测了,选取邻居常见的做法是选取与该读者最相似的前 K 个用户作为邻居,以这些邻居读者的评分信息来预测目标读者的评分情况,进而进行图书推荐。基于读者的协同过滤推荐的原理如图3所示。
用户和用户之间的相似度计算方法常用的有余弦相似度方法、修正的余弦相似度方法和Pearson相似度方法[7-8]。該文计算读者相似度的方法是Pearson相似度方法,计算公式如公式(1)所示。
其中,[Iij] 表示读者i和读者j共同评过分的项目集合,[Ri,k]表示读者i对图书k的评分, [Ri]和[Rj]分别表示读者i和读者j对图书的平均评分。
该文采用的基于协同过滤的图书推荐算法是:首先,读取读者的借阅信息,然后,建立读者图书矩阵,计算读者的相似度,最后,根据相似读者产生图书推荐结果。基于协同过滤的图书推荐算法的流程图如图4所示。
5 结束语
该文对基于协同过滤的图书推荐系统构建进行了研究,从系统的软件体系结构、系统的功能结构和基于协同过滤的图书推荐算法进行了具体的研究,为将来实现基于协同过滤的图书推荐系统提供理论基础和技术支持。
参考文献:
[1] 李春秋. 个性化图书推荐系统研究[J]. 河南科技, 2013(9): 2-2.
[2] 黄晓斌, 张海娟. 国外数字图书馆推荐系统评述[J]. 情报理论与实践, 2010, 33(8): 125-128.
[3] 奉国和, 梁晓婷. 协同过滤推荐研究综述[J]. 图书情报工作, 2011, 55(16): 126-130.
[4] 黄灿, 刘辉. 基于协同过滤的个性化图书推荐系统研究[J]. 信息技术, 2014(7): 25-28.
[5] 胡伟健, 滕飞, 李灵芳. 适应用户兴趣变化的改进型协同过滤算法[J]. 计算机应用, 2016, 36(8): 2087-2091.
[6] 张迎峰. 面向数字图书馆的个性化推荐算法研究[D]. 合肥: 中国科学技术大学, 2011.
[7] 杨阳, 向阳, 熊磊. 基于矩阵分解与用户近邻模型的协同过滤推荐算法[J]. 计算机应用, 2012, 32(2): 395-398.
[8] 房振伟, 徐海燕, 廖真. 基于协同过滤推荐算法的图书推荐研究[J]. 数字技术与应用, 2017(4): 147-147.
