基于地理位置的跨领域渔业科学数据推荐算法研究
2018-07-12蒋庆朝陈孟婕王立华
蒋庆朝,徐 硕,陈孟婕,王立华
(中国水产科学研究院渔业工程研究所,北京 100141)
随着互联网和信息技术的发展,信息量逐渐从匮乏转为过载。如何从海量信息中找到用户需要的信息成为了一个重要的研究课题。传统的解决方法是利用搜索引擎,但由于信息的多样化和复杂化,难以准确找到合适的关键词描述需求。学术界和工业界开始采用推荐系统解决这一难题。推荐系统作为个性化信息服务系统,可借助用户建模技术对用户的长期信息需求进行描述,并根据用户模型通过一定的智能推荐策略实现有针对性的个性化信息定制[1]。相对于搜索引擎,推荐系统不但不需要用户提出明确要求,而且还能发现用户潜在兴趣。因此,推荐系统快速成为研究领域的热点问题[2]。
当前,各大电子商务网站都拥有独立的推荐系统[3-4],但是对于科学数据类网站,例如渔业领域的科学数据平台,并没有成形的推荐系统。在数据总量达到50 GB,资源总数几十万条的情况下,仅仅依靠数据检索已经难以满足用户对数据服务的需求。渔业科学数据服务的主动性较差,无法给用户提供良好的体验。需要通过构建专业的推荐系统,为用户推荐可能感兴趣的数据和挖掘潜在的兴趣点,以提高数据服务性。目前,应用最广的推荐方法是基于协同过滤的推荐[5-7]和基于内容的推荐算法[8]。随着机器学习的发展,以深度学习和神经网络为基础的基于模型的推荐算法也成为了研究热点[9]。由于渔业科学数据的特殊性以及平台用户偏好信息不足,用户与数据之间的关联程度较低,传统的推荐方法在渔业科学数据领域中难以取得较好效果。通过对平台中的渔业科学数据进行分析,可以看出不论是遥感、环境数据,还是鱼类、湖泊数据,都具有非常明显的地理位置特征,即具体的位置或者分布[10]。渔业用户对于科学数据的需求可以转化为与地理位置之间的关系。
针对目前研究现状,考虑如何在用户—物品领域之外[11-12],引入地理位置信息,利用数据中的位置属性,提高渔业科学数据推荐准确率,并为农业科学数据资源推荐方法研究提供参考。
1 基于地理位置推荐
1.1 研究方法
提出了一种结合用户所在地理位置进行推荐的方法。数据来自国家农业科学数据中心渔业数据分中心平台2017年的日志记录。通过平台数据库获得用户数据,选择100位用户作为试验数据。该数据库不仅包含了平台中所有的渔业科学数据,还记录了用户的访问信息数据。
主要采集渔业科学数据平台数据库的用户访问和IP访问数据,以及Web日志数据。其中,用户访问表包含用户的ID、访问时间、访问记录等信息,IP访问表结构包含访问IP、访问时间、访问记录等信息。这两个表格分别是系统注册用户的历史记录和以访问IP为基础的历史记录。Web日志数据主要包含访问时间、客户端IP、客户端执行的操作以及Cookie等信息。通过对日志进行清洗,提取用户ID和链接,作为对比方法的数据集。采集2017年1—10月的数据,进行数据抽取转为训练数据。采集11—12月的数据,作为测试数据。
根据采集的数据,可以构建用户的物品评分矩阵,其中用户的访问次数作为具体评分来判断用户对这项数据的偏好程度。地理位置则是根据用户的IP,通过API接口,转为物理地址。从地址解析API获得的返回结果是Json格式的数据,包含访问者的国家、区域、省、市等信息。提取其中的国家和省市信息拼接成新的字符串,作为矩阵的地理纬度信息。然后以同一城市对某物品的访问次数作为评分,构建地理位置—物品的数据评分矩阵。通过矩阵分解得到反映用户兴趣分布的评分矩阵,然后为用户推荐评分较高的项[13]。
1.2 矩阵分解
跨领域的推荐方法有基于协同过滤、基于张量分解和基于迁移学习等算法。本研究使用的是联合矩阵分解的方法,这是一种基于模型的矩阵分解算法。矩阵分解就是预测评分矩阵中的缺失值,然后根据预测结果为用户推荐[14]。在分解过程中,将一个矩阵分解成两个或者多个矩阵的乘积。通过不断迭代训练使矩阵乘积越来越接近初始矩阵[15-16]。
对于用户,首先从其近期的浏览记录中抽取具体项作为物品集合V,集合V中包含n个不同的物品项。每个用户和物品集合V之间的关系可以表示成一个n维向量。在向量中,每个维度表示的是用户访问此项的次数。访问次数可以看成是用户对物品的评分或喜爱程度。对于用户集合U和物品集合V,可以表示成一个用户—物品矩阵Rm,n。
(1)
式中:rij(i=1,2,…,m;j=1,2,…,n)—第i个用户访问第j个物品的次数。Rm,n矩阵可以表示成用户因子矩阵Umk和物品因子矩阵Vkn的乘积形式,Rm,n=Umk·Vkn。实际分解矩阵时,要使Umk和Vkn的乘积能够尽可能接近初始矩阵Rm,n。
(2)
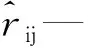
(3)
式中:eij—初始评分矩阵和预测评分矩阵之间的误差。
当所有损失之和最小时,Rm,n矩阵就成功分解为Umk和Vkn。损失函数的最小值,可以通过梯度下降法求解。首先需要获得损失函数的负梯度,然后按照负梯度的方向更新矩阵,更新公式分别为:
(4)
(5)
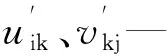
1.3 联合矩阵分解
上述算法是对用户-物品领域的单矩阵分解,当引入地理位置信息时,可以采用联合矩阵分解进行分析。通过分解相关联的矩阵,计算损失函数的最小值。不同于单矩阵分解,损失函数是各领域损失函数的加权和,且所有权值之和为1。
联合矩阵分解过程中,用户—物品领域,评分矩阵可以分解成用户特征矩阵U和物品特征矩阵V。位置—物品领域,评分矩阵可以分解成位置特征矩阵I和物品特征矩阵V。两个领域的V特征矩阵是等价的。则联合矩阵损失函数为:
e2=α‖RUV-UV‖2+(1-α)‖RIV-IV‖2
(6)
式中:e—损失函数;α—(用户—物品)矩阵损失函数的权重;RUV—(用户—物品)矩阵评分;RIV—(位置—物品)评分矩阵;‖RUV-UV‖2、‖RIV-IV‖2—分别是两个矩阵的损失函数。
按照梯度方向,更新矩阵。当损失函数小于阈值时,迭代结束,此时获得的就是关于用户、物品和位置的特征矩阵。相对于单矩阵分解出的用户和物品特征矩阵,使用联合矩阵分解获得的矩阵反映了地理位置因素的影响。因此,可以使用用户—物品矩阵还原评分矩阵,然后根据预测值的大小向用户推荐。
2 结果与分析
2.1 试验评价标准
以公式(6)构建的两个矩阵作为输入,使用联合矩阵分解算法,得到用户矩阵、物品矩阵和地理位置矩阵。重新以用户和物品矩阵组成评分矩阵,降序排列,分数较高的优先推荐给用户。计算中,采用的是预测准确率P和击中率R来评价推荐算法的性能,计算方法为:
(7)
(8)
式中:N—用户推荐物品的数量;M—用户一段时间内浏览物品的数量;Nr—成功推荐给用户的物品数量;P—预测准确率,即为推荐准确的数据与推荐的总数据比值,%;R—击中率,即推荐准确的数据在用户浏览数据中所占比值,%。在试验中,为每个用户推荐10条数据,N=10。
2.2 试验结果
在对比试验中,选择4种算法与本文方法的性能进行比较。算法如下:1)基于用户的协同过滤方法,使用的试验数据是上文中构建的用户—物品评分矩阵;2)基于热点信息的推荐算法,以当前系统平台中访问量最多的渔业科学数据作为热点信息,推荐给用户;3)基于人口统计学的推荐,根据用户的注册信息发现相关用户,然后把相似用户浏览的数据推荐给目标用户;4)基于关联规则的推荐,通过web日志数据,挖掘出数据之间的关联规则,然后为用户推荐与浏览记录关联程度较高的科学数据。
计算结果如表1所示,可以看出,当推荐数量N=10时,本研究提出的基于地理位置的跨领域推荐相较于其他方法能够有效提升在渔业科学类数据推荐效果。
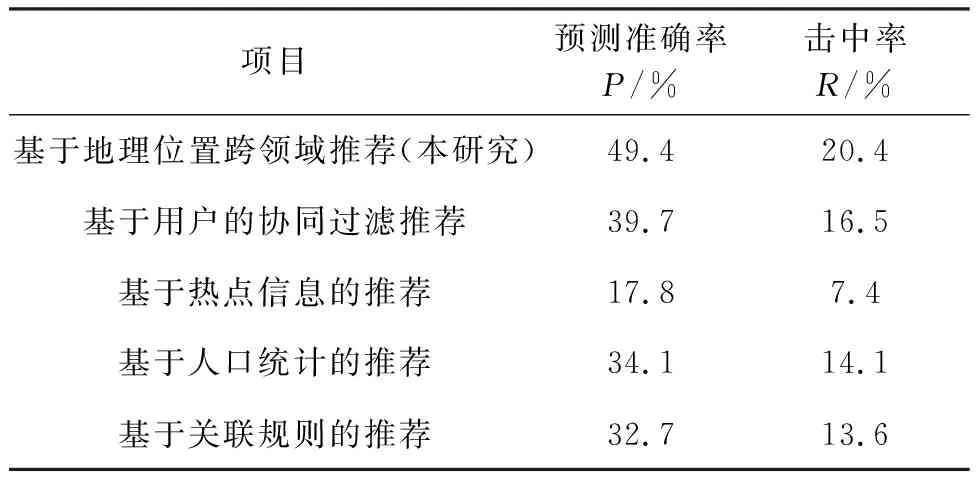
表1 跨领域推荐与传统推荐效果比较
通过变化推荐列表长度,从8增长到11,各个算法的预测准确率和击中率变化如图1、图2所示。

图1 预测准确率随推荐数量变化
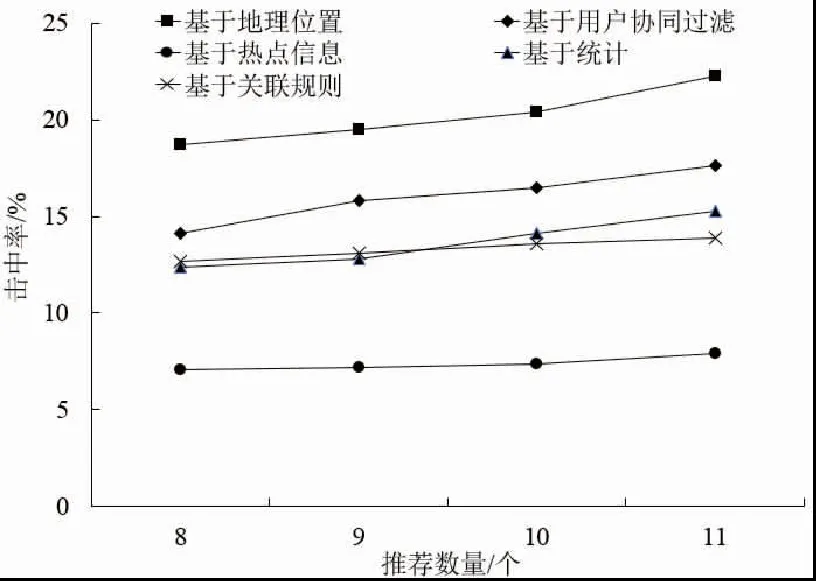
图2 击中率随推荐数量变化
可以看出,随着推荐长度的增加,推荐系统的预测准确性也在不断的降低,这是由于评分较高项在推荐列表中占的比重逐渐降低,且计算中采集的是1—10月的用户数据,预测的是11—12月的行为,没有实时更新训练数据。这些旧数据无法反映用户新的兴趣变化,降低了准确性。而击中率提高则是由于推荐命中数据量的增加。
2.3 结果与分析
从表1可以看出,基于热点信息的推荐效果最差,因为没有考虑用户的个性化需求,只统计系统访问量最多的渔业科学数据作为热点信息推荐给用户。而渔业科学数据与用户之间的关系散乱,难以实现较好的推荐结果,且对于部分用户会产生过量推荐的效果。基于人口统计学的推荐预测准确率和击中率不高的原因是推荐以用户的注册信息作为特征,不能保证兴趣点有较大范围的重合。基于关联规则的推荐效果较好,使用的对比方法参考肖慧等[19]。算法从散乱的科学数据中挖掘了一定的关联规则,反应了数据蕴含的潜在关系。随着推荐数量的增加,关联程度较低甚至没有关联的数据也被推荐给用户,使得算法的性能极速下降。当N=10时,算法的预测准确性和击中率都低于基于人口统计学的方法。基于用户的协同过滤算法计算了近期用户浏览记录的相似度,保证了兴趣相似度较高的用户之间的推荐,效果相对于其他方法较好。并且在吴颜等人的研究中[20],通过聚类和矩阵的降维,进一步缓解了矩阵稀疏性的影响,提高了推荐系统的预测准确率。本文算法则在传统单矩阵分解的基础上,考虑了渔业数据潜在的位置因素,即用户感兴趣的渔业数据会因为位置的变化而变化。相较于单纯的基于矩阵分解的协同过滤算法[21-23],充分发掘了数据内涵的地理位置信息。
本文方法在预测准确率和击中率上都高于其他4种算法,充分利用了数据中蕴含的地域特征,增加了可用推荐信息,在一定程度上减少了冷启动问题的影响,对信息较少、难以提取兴趣特征的用户也能有较好的推荐结果。相较于其他推荐算法,基于地理位置的跨领域推荐在渔业科学数据领域中具有明显优势。
3 结论
通过对跨领域推荐方法的设计和实现,提出了结合用户地理位置的推荐方法,综合利用了用户之间的兴趣相似性及渔业数据本身蕴含的地理位置信息。并对比了传统的推荐算法,分析了其优劣。计算结果表明,本文方法提高了在渔业科学数据领域里推荐结果的准确性,具有一定的研究意义。下一阶段会继续研究在移动端GPS定位下,以更加精细的地理信息为用户推荐渔业科学数据的方法。
□
