土壤碱解氮含量可见/近红外光谱预测模型优化
2018-07-11汪六三鲁翠萍王儒敬郭红燕汪玉冰林志丹宋良图
汪六三,鲁翠萍,王儒敬,黄 伟,郭红燕,汪玉冰,林志丹,王 键,蒋 庆,宋良图
(1.中国科学院合肥智能机械研究所,安徽合肥 230031; 2.合肥电子工程学院,安徽合肥 230037)
1 引 言
氮素是作物最重要的营养元素,对绝大部分作物来说,生长所需的氮素90%以上来源于土壤[1]。分析测定土壤中各种形态的氮含量,对了解土壤氮的供给水平和指导施肥具有重要意义;在精准农业生产中,土壤不同形态氮素水平的测定是精准施肥或平衡施肥的重要依据。土壤碱解氮是土壤氮素的重要指标之一,碱解氮含量的高低能反映出近期土壤氮素丰缺。
传统土壤碱解氮的测定是基于湿化学法[2],操作复杂、测量时间长、成本高,难以满足快速检测土壤碱解氮含量的需求。可见/近红外光谱技术具有快速、无损、无污染等特点,它可以在短时间内分析大量土壤样品,实现土壤参数的快速测量,在土壤养分检测中得到大量应用[3-9]。通常可见/近红外光谱包括百千个波长变量,而这些变量中含有与待测属性无关的冗余噪声[10]。因此,建模前有必要对波长变量进行选择。这样可以剔除不相关的变量,简化模型,更重要的是可以提高校正模型的预测能力。常用的变量选择方法包括:无信息变量消除法(Uninformative variable elimination,UVE)[11]、遗 传 算 法 (Genetic algorithms,GA)[12]、连续投影算法(Successive projections algorithm,SPA)[13]、竞争性自适应重加权算法(Competitiveadaptivereweightedsampling,CARS)[14]、随机蛙跳(Random frog,RF) 等[15]。刘燕德等[16]以江西脐橙果园土壤为研究对象,通过遗传算法、连续投影算法、竞争性自适应加权算法筛选出有机质敏感波段,结果显示竞争性自适应加权算法更加有效。贾生尧等[17]利用变量投影重要性(Variable importance in the projection,VIP)、无信息变量消除法选择波长变量,并分别用递归偏最小二乘回归法(Recursive partial least squares regression,RPLS)、偏最小二乘回归法(Partial least squares regression,PLS)建立土壤全氮和有机质含量预测模型,结果表明VIP-RPLS对土壤全氮和有机质含量具有更高的预测精度。高洪智等[18]将连续投影算法与贡献值结合筛选土壤总氮的特征波长,所建模型的预测精度优于全谱偏最小二乘回归结果。林志丹等[19]针对土壤有机质含量预测,使用连续投影算法和遗传算法进行波长优选,主成分回归构建预测模型。结果显示连续投影算法和遗传算法都能够有效减少参与建模的波长数且提高模型预测精度。
本文以宁夏吴忠地区75个水稻土样为研究对象,利用可见/近红外光谱技术采集土壤样品光谱,比较不同预处理方法和原始光谱对预测模型的效果,探讨GA、SPA、CARS、RF 4种波长选择算法对土壤碱解氮含量预测模型的影响,为土壤碱解氮含量快速获取和仪器开发提供技术支持。
2 材料与方法
2.1 样本采集、制备和划分
在宁夏吴忠市叶盛贡米种植基地2号地(954亩)采集土壤样品75个。土样的采样范围为北纬38°07'23.65″~ 北纬 38°07'39.64″,东经106°11'27.66″~ 东经 106°12'03.28″;采集的土壤去除杂物后,让其自然风干。风干后的土壤样品先经过人工碾磨,然后过筛。根据分析项目的要求,过60目数的筛子。每个样品分两份,一份用于实验室化学分析,另一份用于光谱分析,用自封袋对土样进行密封保存,并统一编号。土壤样本共75个,使用SPXY(Sample set partitioning based on joint x-y distance)方法对样本按4∶1进行划分,其中建模集60个,预测集15个样本,如表1所示。
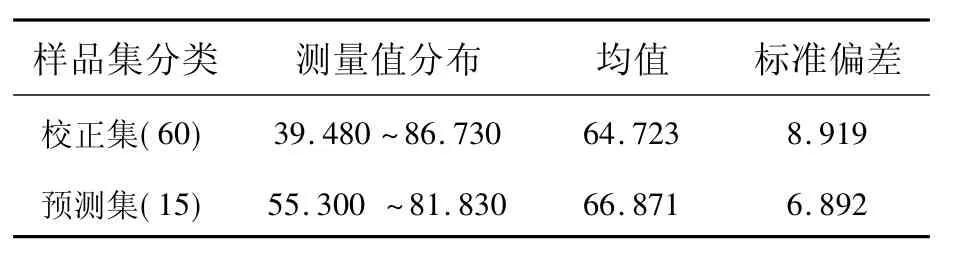
表1 土壤样品碱解氮测量值分布Tab.1 Measurement distribution of soil available nitrogen mg·kg-1
2.2 土壤样本光谱采集
本实验采用美国Veris公司的可见/近红外光谱土壤检测系统。该系统将光源和漫反射收集集成于一个犁头内。犁头底部固定有蓝宝石窗片。这种窗片在近红外波段透过率大约为90%且足够耐用,能够承受与土壤的连续接触。系统使用卤素灯照射土壤,漫反射光通过光纤传导进入光谱仪。置于犁头内的光学快门每隔5 min自动获取暗光谱。光谱仪每秒大约采集20个光谱,同时通过USB接口传输给电脑保存。采集程序使用 Labview(National Instruments,Austin,TX,USA)编写。光纤传导漫反射光进入两个分立的光谱仪。一个光谱仪(Ocean optics,USB4000)使用硅CCD作为探测器测量342~1 050 nm波段光强,光谱分辨率为3 nm;另一个光谱仪(Hamamatsu,C9914GB)使用InGaAs阵列探测器测量1 000~2 221.5 nm波段光强,光谱分辨率为8 nm。犁头安装于一个支架上,支架上安装有光谱仪、控制器等光谱采集与控制处理系统。整个系统包含两种测量模式——田间动态测量模式和实验室静态测量模式。本研究中,我们将犁头从支架上拆卸下来,在实验室条件下采集土壤光谱。
为了使光源保持稳定,卤素灯光源至少预热20 min左右。将过筛的土壤样品装入样品杯,用样品杯盖将样品杯内的样品压实压平。样品杯贴近探头窗口,采集土壤样本光谱,转动样品杯,每个样品重复扫描3次,求其平均光谱曲线。
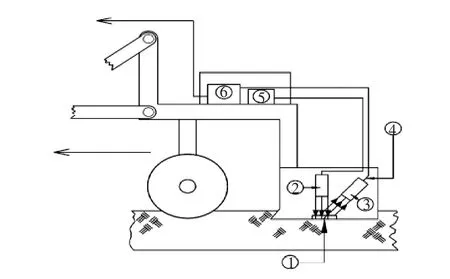
图1 可见/近红外土壤属性测定仪结构示意图。其中:①蓝宝石窗;②卤素灯;③漫反射光收集探头;④光纤;⑤光谱仪;⑥电源。
2.3 光谱预处理
样本表面不均引起的散射现象、装样量不一致引起的光程差、暗电流和仪器随机噪声引起的光谱曲线不重复现象和基线漂移现象,以及样本不同成分自检相互干扰引起的背景因素和多重共线性等无用信息对光谱曲线均有影响[20]。为了达到较好的预测效果,通常需要对光谱数据进行预处理。本研究分别对土壤样本光谱数据进行了Savitzky Golay平滑(SG smoothing)、多元散射校正(Multiple scatter correction,MSC)、标准正态变量变换(Standard normal variate,SNV)等预处理,并对各种预处理效果和原始光谱数据效果进行了比较,具体见下文。光谱预处理使用Uncrambler X 10.4(CAMO,Norway)和 Matlab2012b(Math-Works,USA)软件。
2.4 波长筛选
原始光谱数据量大,同时存在冗余噪声和大量共线信息,对光谱建模存在干扰,需要对波长进行筛选。本文对文中使用的遗传算法(GA)、连续投影算法(SPA)、竞争性自适应重加权算法(CARS)和随机蛙跳(RF)算法作一个简单介绍,具体的可以参见文献[12-15]。
遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟生物进化随机寻优求解的常用算法。它利用选择、交换和突变等算子的操作,随着不断的遗传迭代,使目标函数值较优的变量被保留,较差的变量被淘汰,最终达到最优结果。
连续投影算法是一种减少变量共线性问题的前向循环选择方法。利用向量的投影分析,该方法从一个波长开始,每次循环都计算它在未选入的波长上的投影,将投影向量最大的波长引入到波长组合。每一个新选入的波长,都与前一个线性关系最小。
竞争性自适应重加权算法是一种基于回归系数进行波长选择的方法。该方法模拟达尔文进化理论的“适者生存”原则,将每个波长看作一个体,对波长进行逐步淘汰,每次采样过程中利用自适应重加权采样技术和指数衰减函数结合的方法优选出PLS模型中回归系数绝对值大的波长点,去除PLS模型中回归系数值权重较小的波长,并计算变量子集RMSECV值,最后选择最小RMSECV子集作为最优变量子集。
随机蛙跳是一种迭代方式工作的波长选择方法。首先一个变量子集被随机选择,基于这个选择的变量子集按照一定的几率进行迭代,每迭代一次,变量子集更新一次。经过N次迭代后,每个变量选择的几率被计算出来。然后几率高的变量用来建立PLS模型,RMSECV最小的PLS模型对应的变量为最优变量。
本研究中,GA和SPA算法分别使用GAPLS工具箱、SPA工具箱实现[21];CARS和RF算法使用LibPLS工具箱[22]实现。GAPLS工具箱要求初始变量小于200。因此首先对光谱数据使用三点平均后波长数由380减为127,再使用GA进行波长筛选。
2.5 模型验证与评价
模型分别采用完全交互验证和外部验证对其性能进行评价,由决定系数(R2)、建模均方根误差(RMSECV)、预测均方根误差(RMSEP)和预测相对分析误差(RPD)来评价。在建模分析中,R2和RPD值高为好,同时RMSECV和RMSEP值低为好。当RPD值位于1.5~2之间表示所建立的模型对分析指标具有一定的预测能力,当位于2~2.5之间表示所建立的模型对分析指标定量预测是可行的,2.5~3之间表示所建立的模型具有较好的预测精度[3,23]。
3 结果与讨论
3.1 光谱数据预处理
75份土壤样品的可见/近红外光谱吸收图谱如图2所示,在1 400 nm和1 900 nm附近有明显的水分子吸收峰。
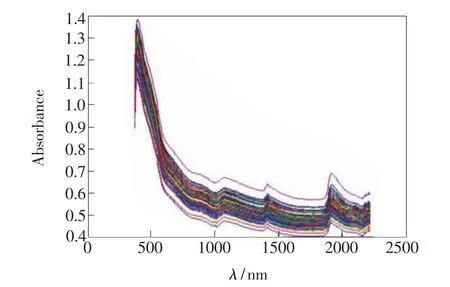
图2 75份土壤样品的可见/近红外光谱
去除340~366 nm噪声大的波段,选取366~2 221.5 nm波段光谱数据作为后续数据处理。对土壤光谱数据分别采用SG smoothing、SNV、MSC等预处理方法进行光谱预处理,分别建立PLS模型。本文建立的所有预测模型由决定系数(R2)、建模均方根误差(RMSECV)、均方根预测误差(RMSEP)和相对预测偏差(RPD)评价,其中R2和RPD值越大,RMSECV、RMSEP值越小,模型性能越好。
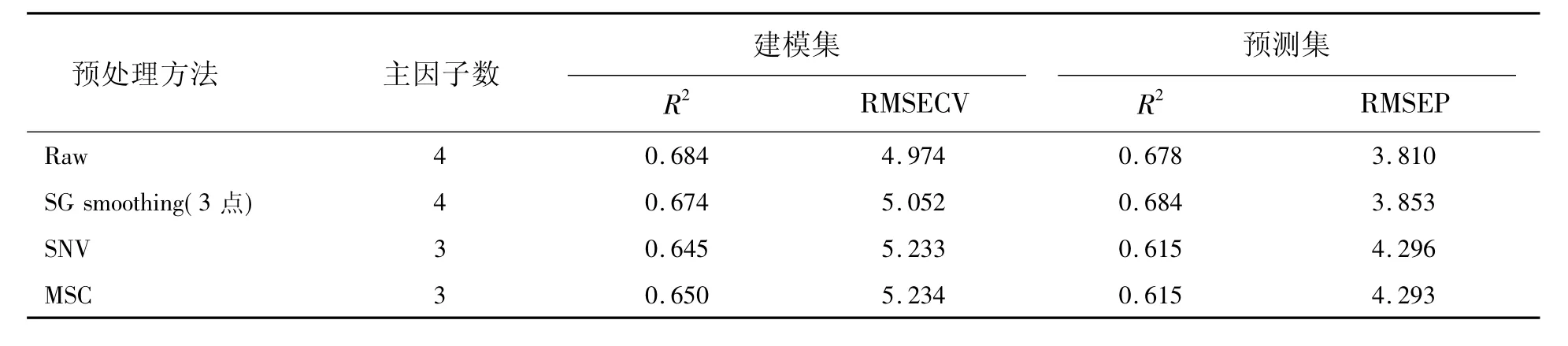
表2 不同预处理方法的PLS建模结果Tab.2 Results of PLSmodels obtained with different spectral pretreatmentmethods
表2给出了不同预处理方法PLS建模结果。本次实验发现采集的光谱不经过任何预处理效果最好,是由于光谱采集时仪器性能稳定,制备的样品过了60目筛,样品的颗粒度比较小和均匀。
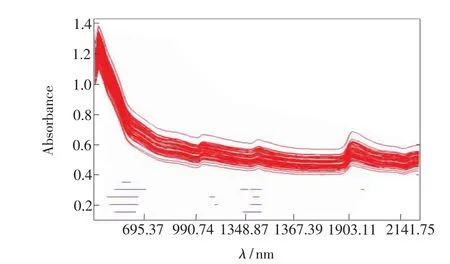
图3 土壤光谱和GA变量筛选结果
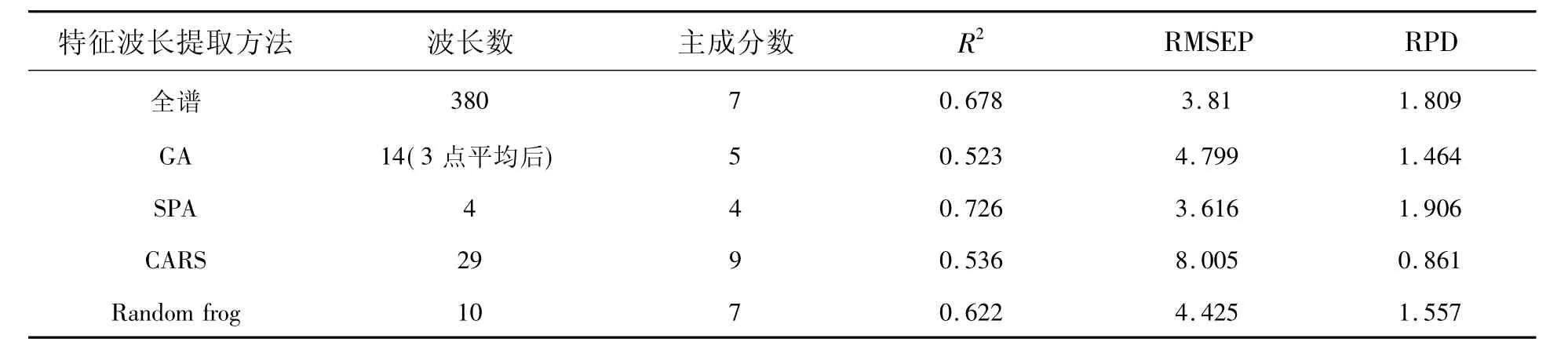
表3 不同波长筛选方法的PLS建模结果Tab.3 Results of PLSmodes obtained with differentwavelength selection
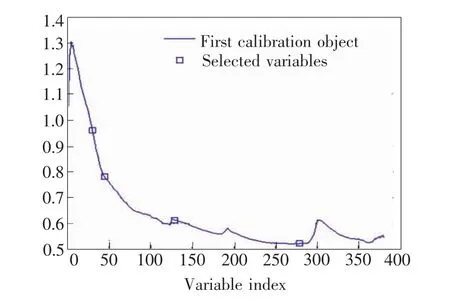
图4 SPA运行结果
3.2 波长筛选
图3显示了基于GA算法的波长筛选结果。GA算法操作过程中依赖于随机数发生器,每次运行的解是不同的,多次运行可以获得广泛可能的解,对GA算法进行了5次运行。图中上半部分为建模集样品可见/近红外光谱,图中下半部分横线为5次运行的波长筛选结果。从图中可以看出5次运行筛选的波长主要集中在400~700 nm、1 100~1 500 nm波段。基于选择的波长建立GA-PLS土壤碱解氮定量预测模型,5次预测结果的均值如表3所示。
图4表示使用SPA算法进行波长选择的结果。从图中可以看出选取了4个变量,对应波长为535.85,619.66,1 091.49,1 817.58 nm。基于这4个变量建立了SPA-PLS土壤碱解氮定量预测模型,预测结果如表3所示。虽然SPA-PLS模型参与建模的变量数仅获得4个变量,占原始变量的 1%,SPA-PLS模型的性能适当,R2为0.726,RPD值为1.906,结果表明PSA-PLS模型对土壤碱解氮有一定的预测能力。
图5表示运行一次CARS算法,随着采样数的增加,采样变量数(图5(a))、十折交叉验证RMSECV值(图5(b))、各变量回归系数(图5(c))的变化趋势。从图5中可以看出,CARS变量选择过程分两个阶段进行。第一阶段由于指数衰减函数的作用,采样的变量数减少速度很快,称为粗选;第二阶段采样的变量数减少速度减慢,称为细选。在1~25采样区间,RMSECV值随着采样数的增加减少快速,表明消除了与碱解氮无关变量;采样超过25后,随着采样次数的继续增加,RMSECV值又逐渐递增,表明光谱中与碱解氮相关的重要信息被剔除了。图中显示采样25时,RMSECV值最小(图5(c)中星号垂线标示)。因此,第25次蒙特卡罗采样获得的变量为预测土壤碱解氮含量的关键变量,共计29个特征波长,依次为455.18,484.26,501.56,530.17,558.47,597.58,608.65,679.35,778.83,789.03,995.24,999.74,1 013.12,1 075.28,1 080.7,1 091.49,1 096.86,1 323.96,1 328.95,1 769.18,1 890.49,1 898.91,1 907.31,1 977.34,1 981.38,1 985.42,2 168.37,2 198.73,2 221.53 nm。基于CARS算法获得的29个特征波长建立PLS模型对土壤碱解氮进行定量预测,预测性能如表3所示。
图6表示基于Random frog算法运行10 000次结果的均值,由于Random frog算法每次运行的结果略有差异,所以需要多次运行并且结果取平均值。越重要的变量,被选择的概率越大。依据经验,以0.3为阈值,选择概率大于阈值的波长将被作为特征波长。因此,获得了13个超过点线(0.3)的波长(501.56,789.03,912,949.56,1 283.78,1 323.96,1 719.88,1 769.18,1 773.6,1 839.26,2 095.77,2 118.83 nm)作为特征波长,作为 Random frog算法运行10 000次后的结果。基于13个特征波长建立RF-PLS土壤碱解氮定量预测模型,预测结果如表3所示。
从表3可知,采用SPA提取的特征波长建立的PLS模型的效果最好,预测集的决定系数为0.726,均方根预测误差 3.616,相对分析误差为1.906。采用CARS选择的特征波长建立的模型预测效果最差,预测集的决定系数为0.536,均方根预测误差8.005,相对分析误差为0.861。比较基于GA、Random frog算法提取的特征波长建立的PLS模型可知,其预测能力均低于全谱PLS模型,可能是GA、Random frog选取的特征波长中包含无用信息,没有达到最优选作用。依据模型评价标准,SPA、GA和Random frog算法及全谱PLS模型均对土壤碱解氮具备一定的预测能力,相对于全谱PLS,SPA、GA和Random frog算法简化了模型;CARS算法模型未能体现其对土壤碱解氮的预测能力,分析可能是由于CARS算法在波长筛选过程中剔除了重要波长变量。

图5 CARS运行结果。(a)筛选过程中采样变量数的变化趋势;(b)10折交叉验证所得残差RMSECV;(c)各变量回归系数随着采样次数增加的变化趋势。
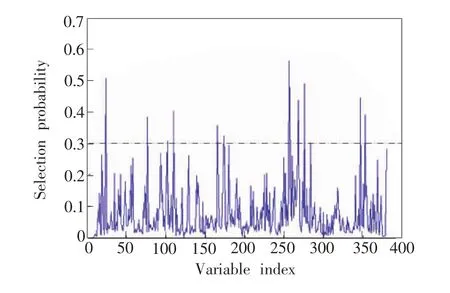
图6 Random frog选择波长的概率
4 结 论
利用可见/近红外光谱技术对土壤碱解氮含量进行了检测。用SG、MSC、SNV对原始光谱数据进行了预处理,基于全光谱建立了土壤碱解氮含量PLS预测模型,比较了不同预处理方法和原始光谱的预测效果。结果表明原始光谱数据建立的模型最优,分析是由于光谱采集时仪器性能稳定,样品的颗粒度比较小和均匀(过60目筛)。在原始光谱数据的基础上,采用GA算法、SPA算法、CARS算法和Random frog算法提取特征波长,并基于特征波长建立PLS预测模型。结果显示,与全谱PLS模型相比,SPA算法建立的预测模型效果最好,GA算法、CARS算法和Random frog算法建立的模型的预测效果均低于全谱PLS模型,说明SPA算法对于土壤碱解氮是一种有效的波长筛选方法。本文的研究为土壤碱解氮含量的快速检测和仪器开发奠定了基础。
