Software Reliability Growth Model for Imperfect Debugging Process Considering Testing-Effort and Testing Coverage
2018-07-11ZangSicongPiDechang
Zang Sicong,Pi Dechang
College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 211106,P.R.China
Abstract:Because of the inevitable debugging lag,imperfect debugging process is used to replace perfect debugging process in the analysis of software reliability growth model.Considering neither testing-effort nor testing coverage can describe software reliability for imperfect debugging completely,by hybridizing testing-effort with testing coverage under imperfect debugging,this paper proposes a new model named GMW-LO-ID.Under the assumption that the number of faults is proportional to the current number of detected faults,this model combines generalized modified Weibull(GMW)testing-effort function with logistic(LO)testing coverage function,and inherits GMW’s amazing flexibility and LO’s high fitting precision.Furthermore,the fitting accuracy and predictive power are verified by two series of experiments and we can draw a conclusion that our model fits the actual failure data better and predicts the software future behavior better than other ten traditional models,which only consider one or two points of testing-effort,testing coverage and imperfect debugging.
Key words:software reliability;testing-effort;testing coverage;imperfect debugging(ID);non-homogeneous Poisson process(NHPP)
0 Introduction
With the rapid development of software engineering,software reliability,one of the most important text indexes used for ensuring the reliability of software products during and after software development,is of great concern.During the last thirty years,large numbers of software reliability growth models(SRGMs)are proposed to track the reliability growth trend of the software testing process[1-3].SRGMs can be used for defects detection,failure rate calculation and failure prediction.Especially,due to the understandable and simple formula,non-homogeneous Poisson process(NHPP)SRGMs are most widely-used.
During the software reliability analysis,large amounts of manpower and CPU hours,which are called testing-effort(TE),are consumed.Obviously,the consumption rate of TE cannot be a constant and it may change the shape of software reliability growth curve.Testing-effort function(TEF),such as logistic(LO)TEF[4],was established for quantitatively describing the distribution of testing resources.Zhang et al.[5]added finite queuing model into generalized modified Weibull(GMW)TEF with respect to the testingeffort in failure detection process(FDP)and failure correction process(FCP).Lin[6]proposed a software reliability modeling framework used to gauge the influence of test phase transitions and got a significant effect on fault detection.Pachauri et al.[7]used genetic algorithm(GA)and multi-attribute utility theory(MAUT)to keep fault detection rate as a constant.
Moreover,just like TE,testing coverage(TC)can also help programmers detect defects.Cai[8]found that there would be some correlations between TC and software reliability.Thus,testing coverage function(TCF)was established for quantitatively describing TC’s transformation,such as LO TCF[9].Li et al.[10]proposed an ISLO-SRGM combining inflected S-shaped TEF with LO TCF and yielded a wonderful fitting.Chatterjee and Singh[11]incorporated a logistic-exponential TCF with imperfect debugging and the new model’s prediction was very close to actual software faults.
Furthermore,a detected fault cannot be corrected immediately and the time required to correct a detected fault is usually called debugging lag/delay[1].One or several new faults may appear during the fault correcting.In other words,the number of faults is not a constant and it will grow during the detection,which is called the imperfect debugging(ID).Peng[1]and Zhang[12]both built their SRGMs under ID,and the new models had better descriptive and predictive power than the others.Wang et al.[13]proposed a SRGM under ID considering log-logistic distribution fault content function and achieved good performance.
In a word,the introduction of TE,TC and ID,not only makes the SRGMs reliable,but also improves the defect detection rate.However,little research has been conducted to SRGMs combining ID with both TE and TC.Thus,it is desired to put forward an ID dependent SRGM considering both TE and TC to better fit the actual data.
To address this problem,a new SRGM model named GMW-LO-ID is proposed in this paper.In contrast to most of the existing models,our model not only combines the GMW TEF and LO TCF,but also assumes that the current number of faults is dynamic.The fitting accuracy and predictive power are improved by means of considering TE and TC under ID.
1 The Proposed GMW-LO-ID Model
In this section,a new model named GMWLO-ID,which considers both TE and TC under ID,is proposed in this section.GMW-LO-ID considers testing resources’allocation,code coverage analysis and debugging lag.Moreover,it has GMW TEF’s great flexibility and LO TCF’s highly fitting precision.
The NHPP SRGMs considering ID are formulated based on these following assumptions[10,11,12]:
(1)The faults detected process follows the NHPP process;
(2)The current failure is caused by the rest faults in software;
(3)During time interval[t,t+Δt],the mean value of detected number of faults from the current TE is proportional to the rest number of faults.In addition,the ratio between them is called the current fault detection rate r(t)and it can be calculated by
where C′(t)denotes coverage rate;
(4)Whenever a fault is detected,it can be corrected immediately;
(5)The micro updating of code coverage function C(t)can be neglected when new faults appear.
Based on these assumptions above,GMW TEF,LO TCF and the form of ID are introduced in the following.
GMW TEF is based on generalized modified Weibull distribution,and the cumulative TE[7]is given by

where a denotes the total effort expenditure;m andθare shape parameters;βis a scale parameter andλis an accelerating factor.
LO TCF is presented in Eq.(3)as
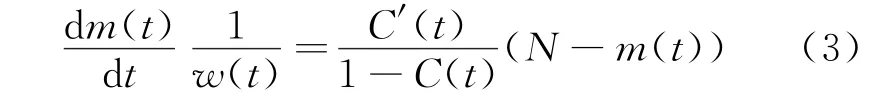
where N denotes the total number of faults;m(t)denotes the mean value function of detected faults during time interval[t,t+Δt];C(t)=reveals the final coverage;αdenotes the parameter of coverage rate.
The parameters of TEF and TCF can be esti-mated by means of least square estimation(LSE)[5,10].Two reasons why we do not utilize maximum likelihood estimation(MLE)are listed in the following.On the one hand,after we transform Eq.(3)into

How to describe the dynamic function N(t)is the key point in SRGMs considering ID.In this paper,we assume that the current number of faults is proportional to the number of detected faults[14],i.e.

whereδdenotes a proportionality coefficient.
By combining these three parts together,the proposed model GMW-LO-ID is presented in the following

where m(t)denotes the mean value function of detected faults during time interval[t,t+Δt];w(t)reveals the function of TE consumption rate,and it can be calculated as the derivative of cumulative TE,i.e.
After solving the differential equation with the boundary condition of m(0)=0,W(0)=0 and the assumption ofδ≠1,we get GMW-LO-ID shown as

GMW-LO-ID has great flexibility.By assigning the scale parameters and shape parameters in Eq.(6),it will degenerate to other simple kinds of SRGMs considering TE,TC and ID.For example,whenλ=0,θ=1,m=2 we get the Rayleigh-LO-ID shown in Eq.(7).

Obviously,GMW-LO-ID has nine parameters.Thus,we can hardly estimate them together.Li[10]mentioned a similar method of parameter estimation:Estimate the parameters related to TEF first and calculate the rest parameters with the estimated ones.Hereon,we get our method of parameter estimation:
(1)Estimate the five parameters relating to TEF,i.e.parametersα,β,m,λ,θ,by TE datasets;
(2)After the substitution of five parameters in step(1)into Eq.(7),there will be only one general NHPP SRGM parameter N,two parameters A andαrelated to TCF and a proportionality coefficientδin the formula.Using LSE to estimate the rest four parameters can obtain an accurate estimation set easily.
2 Experiments and Analysis
In this section,the fitting accuracy and predictive power of our proposed model are validated in constrast to ten SRGMs under two classical datasets.LSE is used to estimate their parameters.
2.1 Dataset description
In this paper,two datasets are used for verification that our GMW-LO-ID model has a better descriptive and predictive power than other models.The first dataset is from the System T1 data of the Rome Air Development Center(RADC)[1].This dataset,which contains running time,testing-effort(computer time)and number of detected faults,is widely used in the latest studies,such as Zhang[5]and Peng[1].The second dataset is from the PL/I application program test data.Its structure is similar to the first dataset and was used by Pachauri[7],Chatterjee[11].As both of the datasets are widely used in the latest researches,the comparison between our proposed model and the others can be easily arranged.
2.2 Experimental preparation
In order to find a better descriptive model,five criteria are used to measure the fitting effects,as shown in Table 1.

Table 1 Criteria for model comparisons
To MSE,variation and RMSPE,the smaller the criterion is,the better the model performs.In addition,a better performance achieves when RSquare and bias is more close to constant 1 and 0,respectively.
Moreover,ten SRGMs considering TE,TC or both are introduced for the model comparison.Goel-Okumoto is introduced as a representation of the traditional SRGM without considering TE and TC.Seven SRGMs,such as inflected S-shaped and GMW[5],are introduced as the representations of models considering TE only.Besides,IS-LO[10]is introduced as the SRGM considering both TE and TC.SRGM-GTEFID[12]is the representation of SRGM considering TE under ID.Furthermore,if an SRGM considers more than two parts of TE,TC and ID,it definitely contains more parameters,which may have better fitting and predictive power.
2.3 Comparison of fitting power
Ten SRGMs considering TE,TC or both are introduced to validate the fitting performance of GMW-LO-ID in this section.Table 2 and Table 3 show the estimated parameters and fitting results of all eleven models for DS1 and DS2,respectively.

Table 2 Estimated parameters and fitting results of eleven SRGMs in DS1

Table 3 Estimated parameters and fitting results of eleven SRGMs in DS2
The numbers highlighted in bold are the best results of each column.And in the tables,Goel-Okumoto is a traditional SRGM without considering TE,which means there will be no W(t)or w(t).That is why the last three criteria(bias,variation and RMSPE)in Table 1 are missing and m(t)is used to fill the blank of W(t)instead.The F in W(t)of
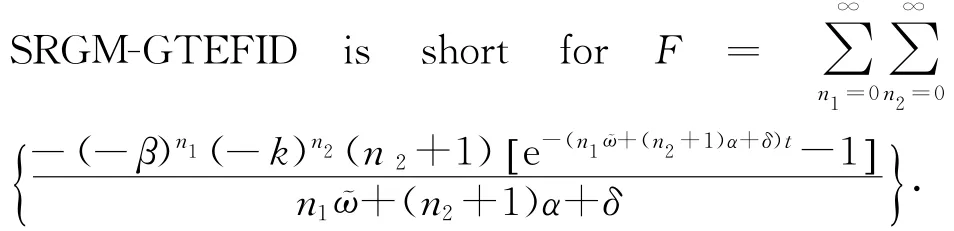
W(t)is utilized here as the substitution of full expression of SRGMs.Two reasons are shown in the following:On the one hand,all 11 SRGMs in Table 2 follow the NHPP process,which means all models are based on the structure ofThe main differences between 11 SRGMs are the formula of W(t).On the other hand,the full expressions of SRGMs are not intuitive.The 11 long formulas may make Table 2 chaotic for understanding.Obviously,in both experiments,IS-LO and GMWLO-ID almost achieve all the best performance,which shows that SRGMs considering both TE and TC have better curve fitting effects than other SRGMs.
The best three,GMW-LO-ID,IS-LO and Weibull,are plotted in Fig.1 and Fig.2 to show the comparison between real and estimated results for each dataset,respectively.The subfigures in left plot the observed/estimated TE curves and the subfigures in right plot the cumulative failure curves.Obviously,all three SRGMs yield good fittings,but we can hardly tell which one has the best fitting power.Thus,we use relative error(RE)to analyze the transformation of fitting accuracy[12],and the results of fitting accuracy vs time are shown in Figs.3,4.
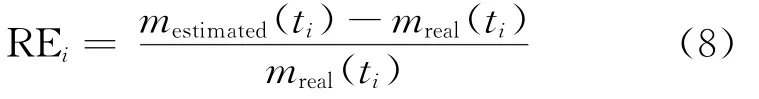
As shown in Fig.3 and Fig.4,GMW-LO-ID has the fastest convergence speed and gets close to the xaxis in the shortest time.Hereon,it has the best fitting power of all three SRGMs and can be used to describe the real testing-effort expenditure.

Fig.1 Observed/estimated TE and cumulative failure curves of three SRGMs vs time in DS1

Fig.2 Observed/estimated TE and cumulative failure curves of three SRGMs vs time in DS2

Fig.3 RE curves of three SRGMs in DS1

Fig.4 RE curves of three SRGMs in DS2
2.4 Comparison of predictive power
The predictive performance of the proposed model is validated in this section.In order to measure the predictive power of SRGMs,we divide the dataset into training set and testing set.Training set is used to estimate models’parameters and testing set is for validating the predictive power of models.In terms of the MSE in testing set,we can tell the differences between the predictive power of SRGMs.
To each group of the experiments,the training set contains 70%,80%or 90%of data,respectively.Table 4 and Table 5 respectively show the predictive results of all 11 models for DS1 and DS2.The numbers in bold are the best results of each column.
Table 4 shows that the best model for 80%and 90%of DS1 is the proposed model because it has the smallest MSE(46.855 2 and 6.712 1).

Table 4 Comparison results of the predictive power in DS1

Table 5 Comparison results of the predictive power in DS2
The other MSE can be 2.88 times(IS-LO’s 134.935 3 for 80%),even 39.82 times(Logistic’s 267.291 1 for 90%)larger than GMW-LO-ID’s.However,Logistic gets an amazing performance(8.268 6)for 70%of DS1 while the MSE of GMWLO-ID(356.329 5)is 43 times larger.Figs.5—7 are plotted to reveal the reason why Logistic performs so terrific in this situation.
Figs.5—7 show the predictive performance of Logistic and GMW-LO-ID for 70%,80%and 90%of DS1,respectively.The x-and y-axes denote the testing time and the cumulative number of detected faults,respectively.The circle and square dots are the training and testing sets.In addition,the blue solid curves represent the predictive performances of Logistic and the red dash ones represent the performances of our proposed model.We can summarize that if the training set is 80%or 90%of DS1,our model has a better performance.Furthermore,the result goes opposite if the training set is 70%of DS1.
Here follows the reason why Logistic performs so terrific in Fig.5.As can be seen in Fig.5,we cannot tell the tendency of DS1 just focusing on the training set because the increasing rate of DS1 only decreases in testing set.It is the reason that GMWLO-ID makes a mistake in judging the tendency of data,which leads to the huge MSE unfortunately.Besides,Logistic’s S-shape helps to decide the tendency of curve and gets a terrific result.Though the MSE of GMW-LO-ID is far larger than Logistic’s,it still performs better than other nine SRGMs.Thus,the proposed model has a better predictive power.However,when the training set is 80%or 90%of DS1,these time training sets contain the data part in which the increasing rate decreases.Our model recognizes it and achieves better predictive performance in Figs.6,7.
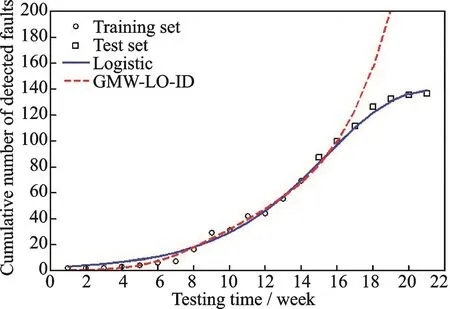
Fig.5 Logistic and GMW-LO-ID’s performances for 70%of DS1

Fig.6 Logistic and GMW-LO-ID’s performances for 80%of DS1
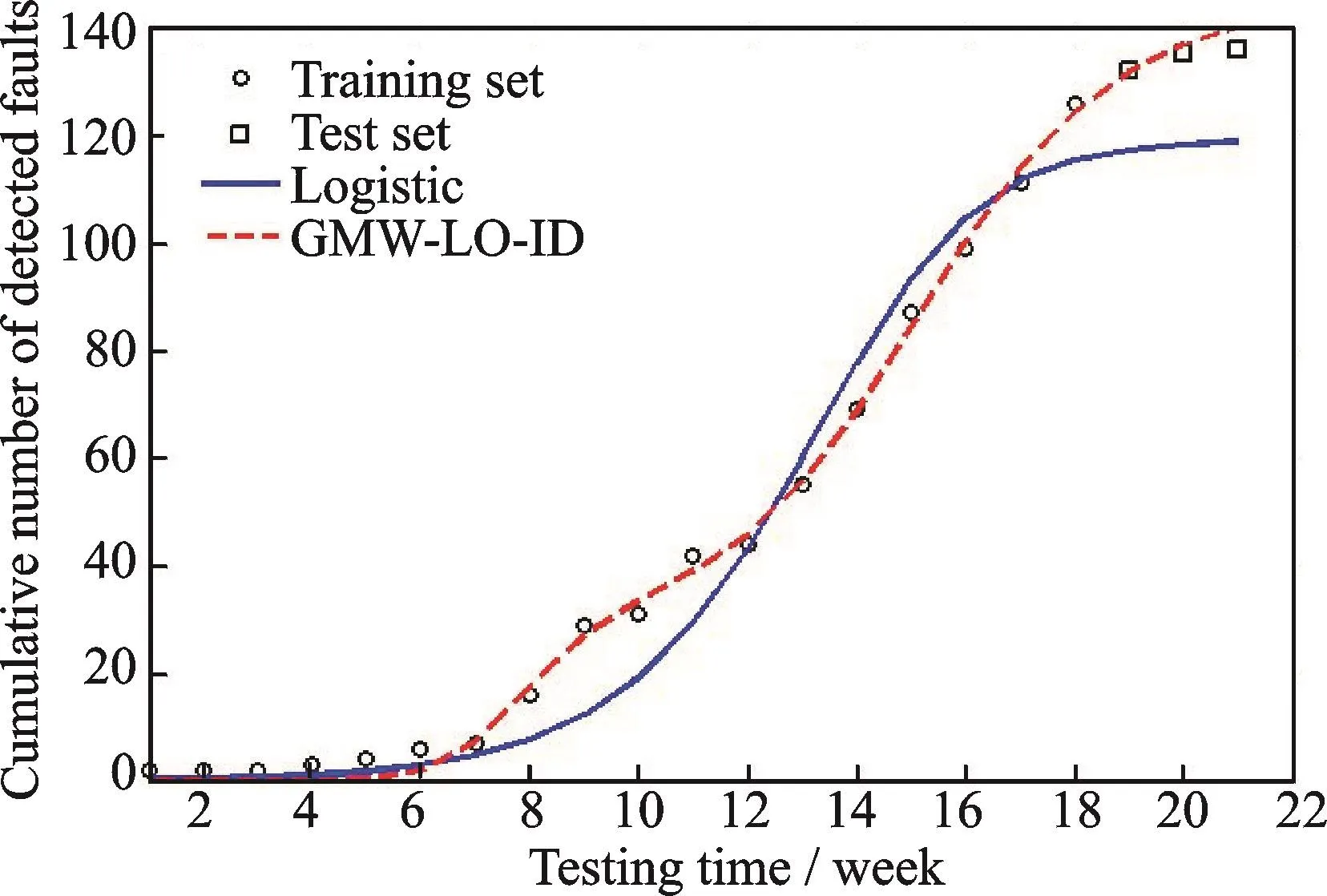
Fig.7 Logistic and GMW-LO-ID’s performances for 90%of DS1
As for DS2,Table 5 shows that the best SRGM for 70%and 90%of DS2 is the proposed model because it has the smallest MSE(165.937 7 and 60.566 1).The other MSE can be 5.67 times(Weibull’s 940.586 2 for 70%),even 9.92 times(Goel-Okumoto’s 601.079 5 for 90%)larger than GMW-LO-ID’s.The reason why Logistic(62.322 0)performs better than the proposed model(234.587 6)for 80%of DS2 is the same just mentioned above and it still performs better than other nine SRGMs as well.
In a word,the proposed model has a better predictive power and can effectively predict software failure behavior.
3 Conclusions
As the dynamic allocation of testing resources,the raise of code coverage rate and the existence of debugging lag will affect software reliability growth curve.By incorporating TE and TC into traditional SRGMs,we use debugging lag to update the constant number of faults with a dynamic variety.Under the assumption that the number of faults is proportional to the current number of detected faults,we propose a new model named GMW-LO-ID combining GMW TEF with LO TCF.LSE is utilized to figure out the estimated values of parameters involved.
After analyzing the experimental results based on MSE,RE and other four kinds of criteria in two testing datasets,we can draw a conclusion that GMW-LO-ID fits the real failure data better and has a better predictive power than other ten SRGMs only considering one or two points of TE,TC and ID.Meanwhile,due to the assignment of some scale parameters and shape parameters,it is more flexible than most of the SRGMs and it can degenerate to other simple kinds of SRGMs,such as Rayleigh-LOID.Consequently,this hybrid model brings us a good performance.
It will be worthwhile to do further research on extending or finding new TEF,TCF and other forms of ID.Moreover,trying to find a more accuracy method of parameter estimation may be another study direction.
Acknowledgements
This work was supported by the National Natural Science Foundation of China(No.U1433116)and the Aviation Science Foundation of China(No.20145752033).
杂志排行

Transactions of Nanjing University of Aeronautics and Astronautics的其它文章
- Arnoldi Projection Fractional Tikhonov for Large Scale Ill-Posed Problems
- SEM-Based Method for Performance Evaluation of Wired LANs
- High-Order Discontinuous Galerkin Solution of Compressible Flows with a Hybrid Lattice Boltzmann Flux
- Experiment on a Double-Foot Stepping Piezoelectric Linear Motor
- Structural and Piezoelectric Properties of Sr0.6Ba0.4Nb2O6Micro-rods Synthesized by Molten-Salt Method
- A Real-Valued 2D DOA Estimation Algorithm of Noncircular Signal via Euler Transformation and Rotational Invariance Property