基于Hadoop平台的聚类K-means算法的研究
2018-07-10汪一百
汪一百
(长沙医学院,湖南 长沙 410219)
1 前言
随着通信技术的迅速发展,如何从海量、复杂、多样的网络数据中挖掘出有价值的信息,是当前IT行业面临的难题。数据挖掘技术是利用统计学理论和人工智能技术的一门综合性学科,其中聚类分析、遗传算法及神经网络等算法已经被广泛应用在大型数据集上。Hadoop平台整合了数据仓储、云计算管理、数据库等一系列平台,是当前学术界和工业界研究云计算的标准平台,运行传统的数据挖掘算法在该平台上,可以有效提高数据挖掘的效率,对于云计算的研究具有积极的作用。
2 Hadoop平台
2.1 Hadoop架构
Hadoop从2005年作为Apache Lucene的子项目开始,经过十几年发展,形成了可以在存储大数据集群上进行分布式计算、开源的框架,具有高可靠性、高效性、高扩展性及高容错性的优点。
Hadoop架构在不断完善更新,其子项目的数量不断增加,但最核心的是编程模型mapReduce和负责文件存储系统HDFS机制。Hadoop架构如图1所示。
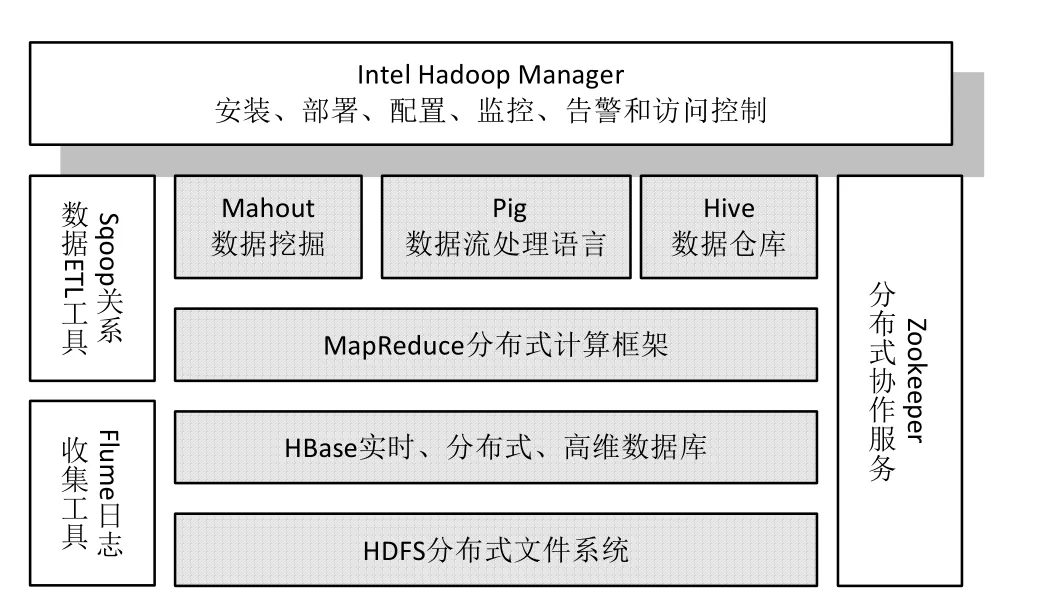
图1 Hadoop架构
(1)编程模型MapReduce
编程模型MapReduce是将映射(map)和规约(Reduce)有效地结合在一起,其作用是划分任务,汇聚结果。具体的过程是:首先将输入Hadoop平台的数据按照用户自己的需求划分为等长的数据块,将划分的数据块分配一个map,然后重新对数据进行整理,最后将多任务的结果进行汇总,得出分析结果。
(2)HDFS机制
传统的文件存储系统无法满足当前海量数据信息的存储工作,采用跨设备的分布式文件系统HDFS机制可以将数据有效地存储在不同的工作单元上。HDFS集群由多个数据节点和一个名称节点组成,其中数据节点主要负责文件系统客户端的读写请求,名称节点主要负责文件系统的命名空间及客户端对文件的访问。
2.2 Hadoop平台的搭建
本实验搭建的Hadoop平台硬件主要由三台电脑、一个名称节点和三个数据节点组成,电脑的配置如表1所示:
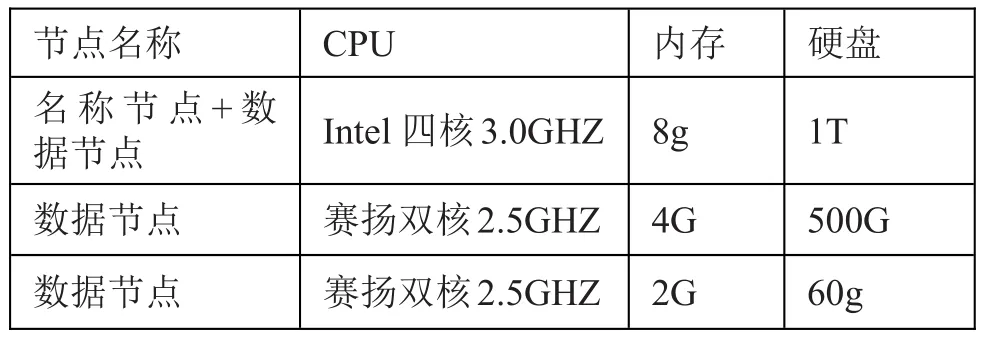
表1 平台的硬件环境配置
平台的软件环境采用的操作系统是Ubuntu 11.10,并在此操作系统上安装Hadoop2.7.5,JDK1.7和Mahout0.8等版本的软件。
搭建的集群主要由三台电脑,其IP地址的分配如下:
名称节点192.168.1.33
数据节点192.168.1.33
数据节点192.168.1.66
数据节点192.168.1.88
3 K-means算法
3.1 Hadoop平台下算法设计思想
1967年,MacQueen J.提出了基于距离的聚类K-Means算法,该算法具有较高的效率,在工业和科学领域有较强的影响力。
在Hadoop平台上,K-Means算法的设计思想如下:
(1)将数据集群划分为N个数据块,分布式存储在各个节点上;
(2)通过函数map()对每个数据块进行处理;
(3)计算所有节点到质心的距离,把具体节点的结果附给最近的聚类,输出该节点新的坐标和聚类号;
(4)在Reduce端对上步的结果通过函数reduce()重新计算质心,输出新的质心及新的聚类号;
(5)比较前后输出的结果,如果两者不同,则重新执行(3)和(4),否则,表示聚类已经完成。
3.2 算法描述
K-means算法是一个反复不断的直至准则函数收敛的聚类算法。
(1)从数据集D中明确所需聚类的数目K,随机选择K个对象作为中心;
(2)通过中心与数据集中其他数据的距离对D进行分类;
(3)对准则函数(公式1)进行计算;

其中,E为所有数据的平方误差总和,mi为每个聚类块的平均值,p为数据对象。
(4)判断准则函数是否满足阈值,假如不满足,则直接跳转至步骤(2),否则,直接结束。
K-means算法的具体流程如图2所示:

图2 K-means算法流程
4 基于Hadoop平台上K-means算法的实现
4.1 算法实现
通过Hadoop平台进行K-means算法的实验,算法的各个步骤是相互独立的,通过把聚簇中心的数据缓存到平台的分布式文件系统中,可以大大减少算法的执行时间,进而提高系统的效率。
算法的核心代码如下所示:
Set
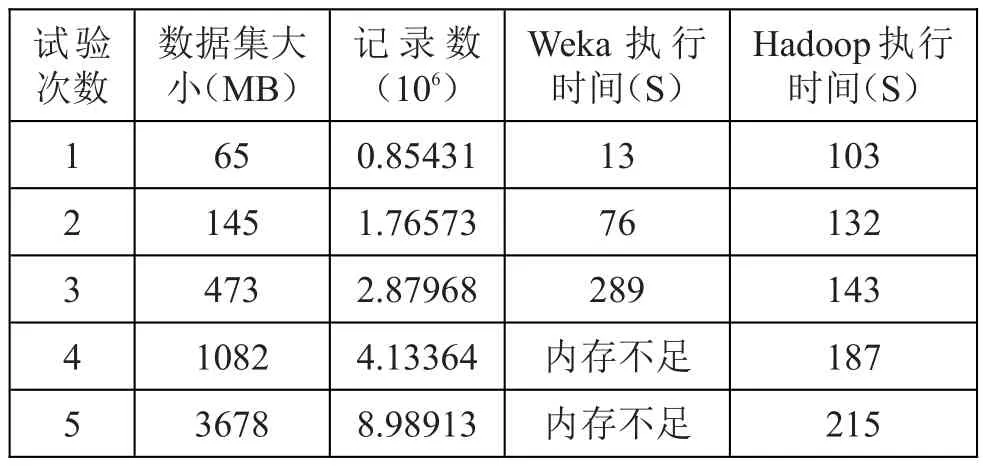
for(int m=0;m { Set //对聚类中心进行重新计算 for(int j=0;j { List int juli=dianshu.juli(); if(juli<3) { zhongxin.add(cluster.get(j).getZhongxin()); continue; } //计算各个数据与中心的距离 double x=0.0,y=0.0; for(int k1=0;k1 { x+=dianshu.get(k1).getX(); y+=dianshu.get(k1).getY(); } //得到新的中心点 Point th=new Point(-1,x/juli,y/juli,false); zhongxin.add(th); } if(Zjdian.containsAll(zhongxin)) break;//判断中心点是否发生变化 Zjdian=zhongxin; cluster=clustering(zhongxin,prepare(zhongxin)); for(int nz=0;nz cw+=cluster.get(nz).getCw(); } return cluster; 本实验分别采用开源数据挖掘工具Weka和Hadoop平台实现K-means算法,实验的结果如表2所示。 实验结果表明:当数据集较小时,Weka的执行时间相对较少,但随着数据规模的不断增大,Weka的执行效率下降,直至内存空间不足,而无法顺利地完成算法;而在Hadoop平台上,数据规模较小时,其运行的效率较低,随着数据规模的增加,运行的效率并没有明显下降。 表2 实验结果分析 在当今数据规模不断爆炸式增长的环境下,Hadoop平台良好的扩展性和加速比对实现K-means聚类算法具有较强的实际意义。 随着数据规模的不断扩大,单机的运算模式已经不能满足当前社会的计算需求。基于Hadoop平台的聚类算法研究表明,当数据规模越大,其系统的工作效率明显优于单机系统,这给我们处理海量的数据提供了良好的平台。本文由于篇幅所限,对于K-means算法的优化工作没有描述,在未来的工作中,将进一步研究。 [1]方新丽.浅议数据挖掘技术在计算机审计中的应用[J]. 电脑知识与技术,2013,9(15):3445-3446. [2]陈慧萍,林莉莉,王建东,等.Weka数据挖掘平台及其二次开发内[J].计算机工程与应用,2008,44(19):76-79. [3]周兵,冯中慧,王和兴.集群环境下的并行聚类算法之研究阳[J].计算机科学,2004,30(7):20-21. [4]郝水侠,许金超.云计算中相似驱动的并行任务划分方法[J].计算机科学与探索,2012,06(8):752-759.4.2 实验结果
5 结语
