一种粒度可伸缩的物理寻址模式
2018-07-10张云舟
张 陌, 张云舟, 谢 刚, 张 刚
(1. 太原理工大学 信息工程学院, 山西 太原 030024; 2. 三亚中科遥感研究中心, 海南 三亚 572029;3. 太原科技大学, 山西 太原 030027)
个人存储装备PSE(Personal Storage Equipment)与个人计算机一同问世, 起初特指计算机内存和外部存储装置, 这里指主机文件系统可直接访问的任何存储系统. 在存储容量和访问速度两个方面, 大数据处理对PSE的要求极为苛刻[1]. 云存储管理大批低造价、 小规模、 低性能的存储资源, 低成本提供大规模、 高性能的存储服务[2], 利用Map/Reduce将一个庞大的访问分解成众多微小读写, 通过并行处理获得资源越多访问速度越快的优势[3]. 但云存储不是一个装备, 而是部署在网络上的服务体系, 它在网络带宽、 安全和可移动上先天不足[4]. 目前云存储的映射/规约机制尚未覆盖存储阵列内部, PSE内部的上百硬盘不具备资源越多访问速度越快的特点, 将Map/Reduce迁移到PSE内部使其覆盖每一个硬盘, 是一项极富创新的挑战[5].
文件系统的一个逻辑单元包括若干连续物理扇区[6], 例如Linux的逻辑块为2~8个扇区[7], Windows的簇最多64扇区. 逻辑单元和物理扇区的地址转换消耗大量内存和计算负载, 制约着大数据的访问效率. 如果PSE物理寻址粒度与文件系统逻辑单元尺寸相同则无需地址转换, 但后果是: PSE的物理寻址粒度必须支持现场定制, 以便适配加载不同文件系统. 为此本文提出超扇区SS(Super Sector)的概念, 设计了矩型阵列RA(Rectangle Array)硬盘组结构实现可伸缩的物理寻址粒度, 形成一个基本RA阵列的PSE样机. 基于SS, 云存储的Map/Reduce可以迁移到RA阵列实现为一种硬件, 多个RA阵列堆叠连接, 在扩容的同时可实现提速, 是一种用于大数据处理的粒度可伸缩的物理寻址模式[8].
1 超扇区
目前大数据的存储规模可达PB级, 扇区作为物理寻址粒度已不合时宜, 尺寸可伸缩的物理寻址粒度有利于扩展. 本节讨论超扇区SS的解决方案.
1.1 RA阵列
传统PSE基于级联扩展芯片, 是树型阵列架构[9], 其叶子节点是单独硬盘[10], 或是1行×p列的RAID阵列, 如图 1 所示[11].

图 1 树型结构的磁盘级联扩展Fig.1 Tree-type architecture of disks extension
这种级联树型阵列不支持多个扇区的点对多点并行读写, 只能依据物理扇区地址先建立一个访问路由, 然后执行一个扇区流的点对单点顺序读写. 一种类似云存储的访问模式是建立逻辑空间到物理扇区的映射规约机制, 部署多个独立引擎并行读写一个逻辑单元的连续n个扇区. 为此图 1 的级联树型结构必须抛弃, 采用一种q行p列的矩型RA阵列, 如图 2 所示. RA阵列有p个通道, 每通道有q个磁盘, 可部署q×p个读写引擎并行读写多个扇区.
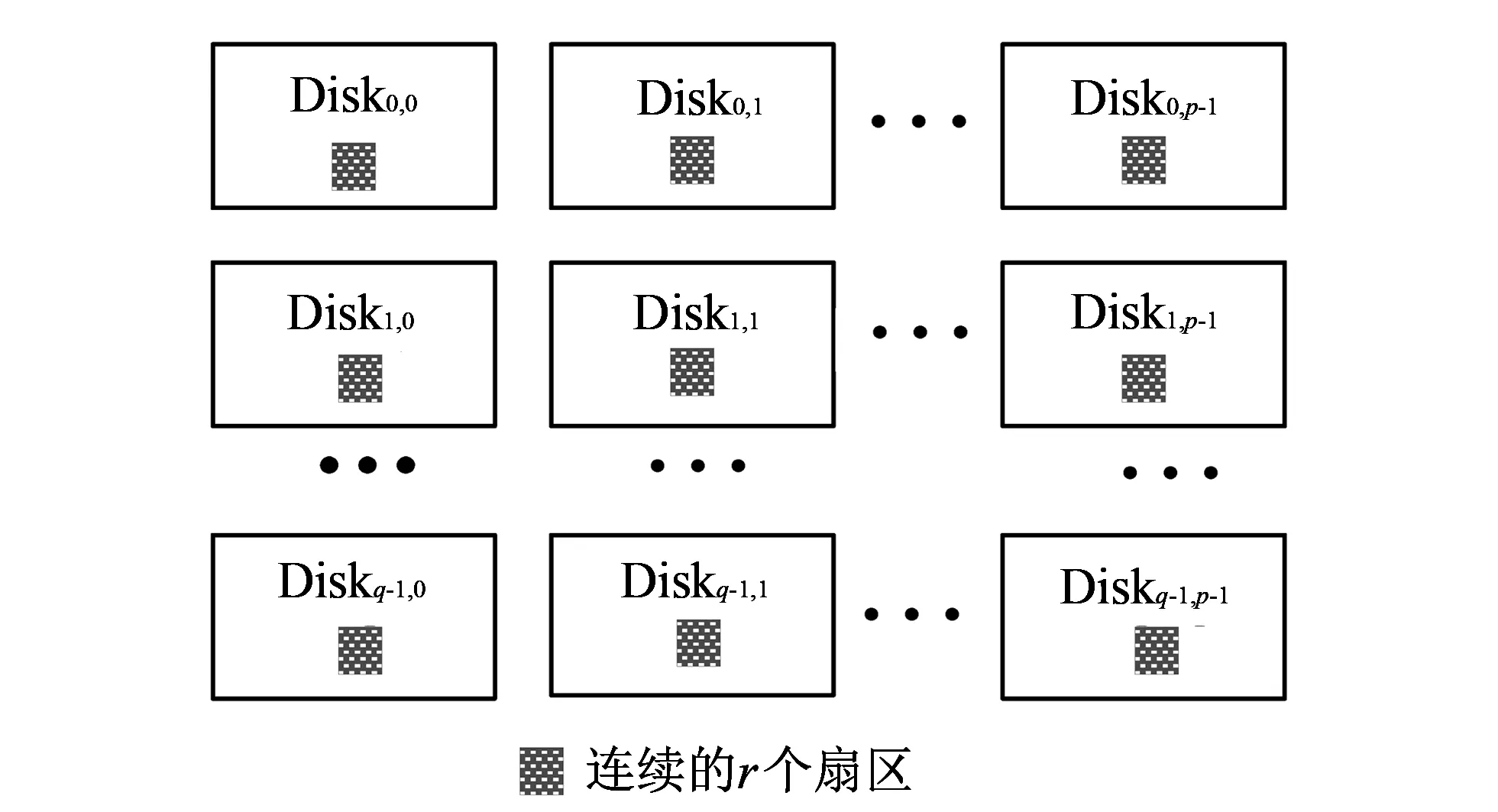
图 2 q×p矩型阵列结构Fig.2 Rectangle-type architecture of q×p disks array
在图 2 的RA阵列的q×p个硬盘中, 起始地址相同的r(r≥1)个连续扇区组成了一个尺寸为n个扇区的存储区域, 这里
n=r×p×q.(1)
1.2 超扇区SS
本文将式(1)规定的存储区域定义为一个超扇区SS, RA阵列Disk00磁盘的r个扇区的起始地址作为SS的地址, 其内部任何一个扇区损坏则该SS损坏. 这种超扇区建立在文件系统初始化之前, 是一种物理存储单元. 通过调整参数r,p和q, 可使SS尺寸与文件系统逻辑单元相同, 由此获得可伸缩的物理寻址粒度.
RA阵列p个通道可进一步表示成m组子通道, 第i个子通道组的物理通道数目为pi(i=0,…,m-1), 那么
p=p0+p1+…+pm-1.(2)
划分m个子通道组有利于堆叠连接多个基本RA阵列, 进一步扩大SS尺寸的伸缩范围, 组成规模更大的PSE. 也可设置专门通道存放校验信息或设置镜像通道组.q×p个引擎可以并行读写一个SS的n个扇区, 每个引擎读写r个扇区. 这里读写引擎是主机端模式,q×p个磁盘是设备端. 此外, RA阵列作为一个PSE以设备端模式工作, 须为SS建立一种消息结构, 记作逻辑寻址结构LAS(Logical Addressing Structure). 基于LAS定义主机访问RA阵列的通信协议, 实现主机访问RA阵列的设备驱动.
2 硬件实现Map/Reduce
与传统PSE的树形结构相比, RA阵列的q×p个引擎并行读写, 有利于硬件实现映射规约机制, 本节讨论实现方案.
2.1 整体方案
选用一片Xilinx的XC7K325T作阵列控制器RAC(RA Controller)[12], 用多片Marvell的端口复用芯片88SM9705作存储扩展[13], 设计了一个q×p磁盘的基本RA阵列, 其整体方案如图 3 所示.

图 3 基本RA阵列原理图Fig.3 Schedule of a basic RA
K7-325内部资源包括PCIe 2.0硬核, PCIe 3.0软核以及16条12.5 G的高速GTX通道, 其中8条GTX建立一个40 G带宽的PCIe 2.0×8总线, 另外8条GTX各自接入一个Marvell的PM芯片88SM9705, 其内嵌的64MB高速缓存可无阻塞实施1-to-5的SATA3.0端口扩展, 总计提供最多40个6G带宽的SATA3.0盘位.
2.2 RAC内部模块
图 3 的RAC内部包括报文处理器MP(Message Processer)、 超扇区控制器SSC(SS Controller)和通道管理器CM(Channel Manager). 其中MP负责解析PCIe通道的LAS报文, 以及将访问结果封装成LAS消息提交到PCIe通道.
由于SS的尺寸与文件系统逻辑单元一致, 无需地址转换SSC可直接读写RA阵列, 其流程: 先将SS的n=r×p×q个扇区映射到p个通道, 每通道读写r×q个扇区; 再由各个通道的读写引擎CM将r×q个扇区依次读写到q个磁盘, 每磁盘访问r个连续扇区, 这样硬件实现的映射规约机制与云存储的MapReduce相当. 通道管理器CM负责生成访问SATA磁盘的FIS并提交给PM芯片, 由9705实施物理扇区的读写.
2.3 RA阵列的设备驱动
文件系统设备驱动由HD(High Driver)和LD(Low Driver)两部分组成. 其中HD负责生成逻辑空间的块IO流, 而LD负责将逻辑空间的一个块IO映射为物理扇区IO的流[14]. 由于SS既是文件系统的逻辑单元也是RA阵列的物理单元, RAC内部的CM负责扇区IO读写, 所以RA阵列只需HD驱动, 其任务: ① 定义访问SS的消息格式LAS, 实现报文处理模块MP; ② 在通道管理器CM中实现低端驱动LD.
LAS报文格式是文件系统访问RA阵列的通信协议, 本质上是超扇区版本的FIS协议, 相对比较简单. 需要在初始化之前确定LAS的逻辑寻址粒度缺省值, 即一个SS拥有的扇区数. 对于本例RA阵列的8个通道, Linux的逻辑块为8扇区, 参数可初始化为r=q=1. 而Windows的簇为64扇区, 参数初始化为r=2, 4或8, 而q=4, 2或1. 针对初始化参数的各种组合设计VHDL程序, 初始化时根据需要选择相应目标代码装入K7-325, 生成不同的RAC硬件.
2.4 基本RA阵列的堆叠扩展
在阵列控制器RAC内部有一个地址寄存器, 用来指定RA阵列在逻辑存储空间的起始和终止地址. 以Linux的EXT4为例, 逻辑块尺寸为8扇区[15], 1EB的逻辑空间寻址248个逻辑块[16]. 这里定义连续230个块为1个逻辑节点N(Node, 4TB). RA地址寄存器包括1个18位的起始节点地址, 即在EXT4逻辑存储空间, 该RA阵列起始块地址的高18位, 指向该RA阵列的首个节点. 还包括1个8位的节点偏移, 指向该RA阵列的最后一个节点. 在LAS消息格式中有一个目的地址字段, 其值若超出此地址寄存器限定的范围, 该LAS消息将被忽略, RAC不予处理. 初始化时分别计算并设置各个基本RA阵列的起始和终止地址, 运行时RAC的消息处理模块解析来自PCIe的LAS报文, 提取LAS中目的地址字段, 并与本地RAC地址寄存器比较, 判断是否忽略该消息, 仅处理目的地址命中的访问.
通过设置各自内部地址寄存器, 图3的多个基本RA阵列可堆叠连接构成规模更大的PSE[8]. 这与以太网的IP地址极为相似, 属于一种云存储的访问模式[5].
3 结果与讨论
测试基于Linux系统进行, 1个RA阵列有40个1TB的SATA3.0硬盘即10个4TB的逻辑节点, 其样机已经测试通过.
3.1 设计方案与测试结果
CMi表示第i个通道管理器, 它接收来自SSC的一个以r×q扇区为单元的数据流, 生成并输出相应的FIS流. SATA3.0的FIS协议支持端口复用器PM[17], 依靠FIS流可以在CM与PM芯片之间交换数据和控制信息, 其原理见图 4.
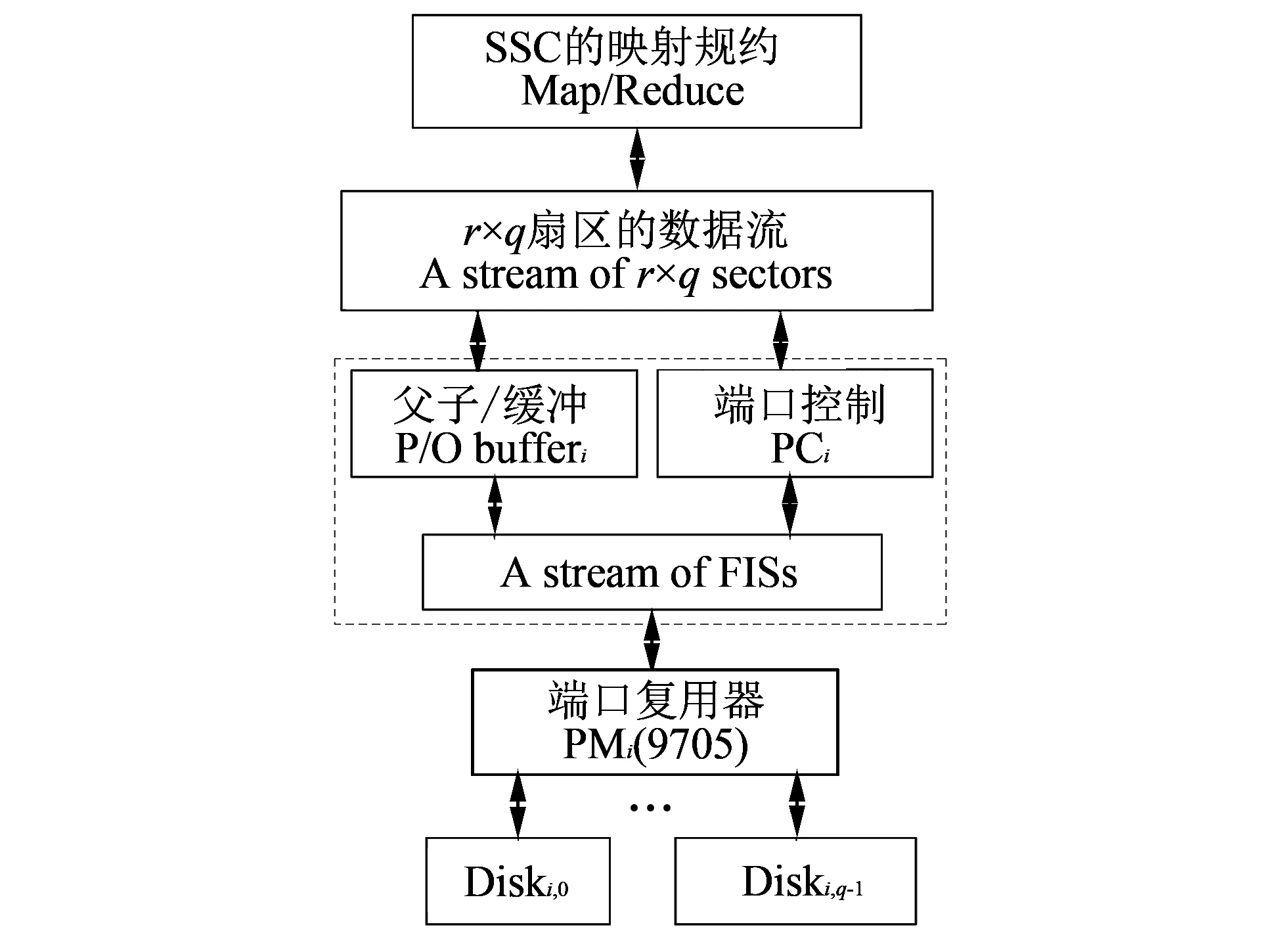
图 4 CM内部模块Fig.4 CM internal modules
图 4 的虚框是通道管理器CM, 其中父子缓冲区P/O是一个乒乓缓存, 以扇区为单元与外部交换数据, 原理见图 5.
P/O含有2个512B的双端口RAM, 由扇区计数最低位及其取反信号crc_bit组合控制, 使得任何时刻一个RAM执行写入, 另一个读出. 地址计数器的8位由0顺序增加至FF再归0, 扇区计数器增1, 触发父子缓冲区的RAM交换读/写角色. 写入地址可与读出地址共享, 也可用一个随机数发生器实施写入地址乱序加扰. 保存随机数发生器的种子可正常读出数据, 而非正常离开系统的存储介质只能读出乱序数据. 调整随机数生成算法可避免雷同的乱序效果, 父/子缓冲的测试结果见图 6.

图 5 父代子代缓存Fig.5 Parent and offspring buffer

图 6 父/子缓存测试结果Fig.6 Test result of parent and offspring buffer
由图 6, 最初p_eni = 1数据写入父代缓冲区. 写满1个扇区后p_eni = 0, 父代缓冲区从写入操作转为读出, 而o_eni = 1激活子代缓冲区写使能, 后续数据写入子缓存. 读出操作与写入同步执行, 这里不再详述. 每个通道有2组P/O缓存, 分别部署在2个方向: PCIe→PM、 PM→PCIe.
端口控制器PC负责初始化PM芯片, 并与父/子缓冲区组合生成访问PM的FIS流, 充当低端驱动LD角色. 厂商提供了PM芯片9705的C驱动, 这里将其改写为VHDL代码并测试通过. 通过设置FIS的端口号, PC可以访问PM不同端口上的SATA设备. SATA3.0协议的读命令为25 h, 写命令为34h, 收到读写命令后设备回复一个DMA Acitve的FIS, 建立DMA通信后发送数据FIS. PC将发送缓存的2个扇区, 连续写入PM的2个不同端口的相同位置, 图 7 是逻辑分析仪抓取的测试结果. 可以看出, 每当设备完成一个写数据就会返回一个R_OK原语, 表示数据写入成功.
图 8 表示PC发送一个读命令FIS, 端口1提交的数据FIS, 其中第一个双字内容为0x00000146, 表示数据来自PM端口1.
图 7 和图 8 的测试结果说明通道管理器CM可以正常实现SATA3.0的端口复用访问功能. RA阵列的8个通道完全相同, 这里不再一一叙述.
这样组成40盘位的RA阵列, 其RAC参数初始化为r=q=1. RAC的报文处理器MP从LAS消息中提取出1个超扇区SS的IO访问请求, 由超扇区控制器SSC映射为8个扇区IO的访问请求, 分别交付到8个通道处理. 反过来也一样, SSC将8个通道读取的扇区数据汇聚(规约)成超扇区SS, 再由MP经PCIe总线交付主机.

图 7 写PM的不同硬盘Fig.7 Writing different hard disks of PM

图 8 PC读取PM端口1的数据FISFig.8 PC readout a data FIS of port 1
3.2 讨 论
与图1传统阵列使用单独读写引擎的顺序访问模式不同, 本文的RA阵列每个通道都部署了独立的读写引擎, 同时读写p个通道可实现p倍提速. 本例中的RA阵列有8个6G带宽的SATA3.0通道, 理论上汇聚带宽可达48G, 此即云存储“资源越多速度越快”的特点.
额外增加一个校验通道容易实现各种RAID算法. 引入超扇区的附带好处是可大大缓解过度集中访问个别存储介质的风险, 使系统负载均衡算法更加简单. 端口复用芯片PM内部拥有64MB缓冲区, 平滑了RA阵列不同存储介质之间的电气特性差异, 同步读写访问. 但应使每个通道的存储介质容量相同, 否则富余容量无法组成超扇区造成空间浪费.
Windows逻辑寻址单元为64扇区, 设置RAC初始化参数r=8可使上述RA阵列支持Windows环境. 也可利用RA阵列的可堆叠特性建立一个堆叠控制器RASC(RA Stacked Controller), 堆叠多个RA阵列形成一个更高汇聚带宽的大数据PSE. 例如, 定义超扇区SS尺寸为64扇区, 并建立相应的堆叠控制器RASC, 它相当于一个PCIe总线的智能交换阵列. 该RASC接入端为PCIe 3.0×32(320G), 另有8个设备堆叠端口, 每端口部署一个PCIe 2.0×8总线用来连接上节描述的基本RA阵列. 由于每个基本RA阵列拥有8个6G带宽的SATA3.0通道, 该RASC总计拥有64个SATA3.0通道. RASC内部硬件实现云存储的Map/Reduce机制, 负责将1个Windows簇的64个扇区, 分别映射到8个子通道组的64个SATA3.0通道, 从而将320G带宽卸载到64个6G的SATA3.0通道, 形成一个带宽320G的大数据PSE.
4 结 论
为消除逻辑存储空间和物理存储空间寻址粒度差异, 本文提出超扇区SS的概念, 设计了基于SS访问的矩型阵列结构RA, 硬件实现了逻辑存储空间与物理扇区的映射规约, 使云存储的Mapreduce覆盖阵列的每个硬盘, 扩容的同时实现访问提速.
利用FPGA和SATA端口复用芯片设计实现了RA阵列, 基于Linux测试了样机, 结果表明RA阵列可实现端口的带宽卸载和汇聚. 该RA样机不依赖网络, 可由主机通过文件系统直接读写访问, 是一种个人存储装备PSE, 其3个优势胜过同类产品:
1) 拥有云存储的Map/Reduce机制, 资源越多访问速度越快.
2) 支持堆叠连接便于扩容.
3) 由主机直接访问, 尤其适合军事、 安全、 金融以及超算设备, 特别地, PSE亦可作为云存储资源节点.
尚需解决的问题是: ① 实现RASC堆叠控制器, 提升PSE的带宽卸载/汇聚能力; ② 修改文件系统代码实现软件定义存储, 适配PSE大容量、 高速度和可堆叠特征.
特别指出, PSE对存储介质无特殊要求, 可用SSD甚至DDR存储器获得更高的系统性能.
