基于弹幕情感分析和聚类算法的视频用户群体分类*
2018-07-05王思尧赵钦佩李江峰饶卫雄
洪 庆,王思尧,赵钦佩,李江峰,饶卫雄
(同济大学软件学院,上海 200092)
1 引言
近年来,随着数字媒体技术的快速发展,弹幕系统在网络视频中的使用规模一直呈上升趋势。这种实时评论的数据能够以滑动字幕的方式直接显示在视频界面上,有助于加深观众对视频内容的理解,也可以促进相同类型视频的观众之间的交流。弹幕视频系统源自于日本视频网站niconico动画(http://www.nicovideo.jp/),经国内视频网站AcFun(http://www.acfun.cn/)和哔哩哔哩(https://www.bilibili.com/)引进后逐渐流行,现在在一些主流视频网站如腾讯视频(https://v.qq.com/)和乐视视频(http://www.letv.com/)中也被采用。因大量评论同时出现时的效果像是射击游戏中的弹幕,故网友称之为弹幕。
与传统评论不同的是,弹幕评论可以在发送后直接显示在视频界面上,并且在之后其他观众观看到该时间点的视频情节时也会显示出来,即观众可以实时发布自己对视频内容的看法,并且能够看到其他观众在看到相同视频片段时的感受,促进了视频网站用户之间的交流,增强了观众即时互动效果。
一方面,相对于传统评论来说,弹幕文本的实时性和简洁性更有利于表达视频用户的真实观点和对于视频情节及时的评价。针对弹幕文本的分类可以将描述不同角色、视频片段、故事情节等方面的弹幕分离出来,从而可以进行基于视频内容的信息挖掘,比如视频精彩片段集锦的提取,视频中场景的分类等。另一方面,针对不同用户群体发送弹幕文本用词习惯、表达的情绪的不同,可以以此为基础将用户群体进行分类,并根据分类结果更精确地向用户推荐适合的网络视频或者广告产品。
本文主要对网络视频中出现的时间序列相关的弹幕数据进行分析和处理,在清洗冗余弹幕之后提取出具有实际意义的弹幕文本,并通过情感分析手段对弹幕用户所发表的弹幕进行情感计算(乐、好、怒、哀、惧、恶、惊)。由于每个弹幕数据都包含了视频时间信息,因此我们提取了情感指数在时间上的分布作为该用户的特征,然后利用聚类算法对这些用户进行情感分类。具体来说,本文的贡献包括以下方面:
(1)以近年出现的网络视频弹幕为研究对象,了解弹幕数据的特征,知道数据的字段含义,掌握弹幕数据的基本处理方法。通过构建网络视频弹幕常用词词典和选择停用词,对弹幕数据进行预处理,清除冗余弹幕。
(2)对弹幕用户进行情感分析。利用情感分析技术从网络视频用户所发弹幕中提取情感信息。通过处理短文本中的情感词汇获取每一条弹幕可能的情感倾向,从而获取观众在视频不同时间的态度与情感,并以此作为用户特征来进行后续分类。
(3)提出基于七维情感指数的k-means聚类算法,改进了聚类算法中的距离计算方式,并通过聚类评价指标来对类的个数k进行估算。
我们通过实验结果及其分析介绍了对弹幕数据的预处理方法,并就用户分类结果进行了分析。
2 相关工作
随着社交网络的盛行和互联网的蓬勃发展,传统的文本逐渐向“简短”“口语化”方向发展,由此产生了短文本的概念。最近几年随着自然语言处理技术的流行和广泛运用,国内外针对短文本的研究也一直在进行。一些基于Twitter和Facebook等社交媒体的短文本研究也逐渐变得成熟。许多相关方向的学者对此非常重视,并做了一些研究。
Song等人[1]指出Twitter内容分类是一项有挑战性的工作,因为用户发送的tweets词语稀疏并且用词不规范。Wijeratne等人[2]提出了一种基于关键词消除的方法来过滤Twitter的噪声数据。Wang等人[3]提出了一种基于图的标签情感分类方法,将用户发Twitter时用于表示发送内容主题的标签(Hashtag)分为三类。通过这些标签的相关性,对它们建立图的联系,然后对Twitter文本的主题情感进行分类。Sakaki等人[4]提出了一种基于关键词特性、单词数量和上下文信息的分类系统来监测目标事件,将每一个Twitter用户当作一个传感器,由于日本的地震发生次数较多,并且全国范围内有大量的Twitter用户,这个系统可以监测出93%三级及以上的地震。同时,通过信息过滤可以快速估计事件发生的地理位置。这种实时的事件监测方法可以迅速地从大量的社交信息中提取出关键信息,从而达到信息实时共享的目的。Kouloumpis等人[5]对Twitter数据的情感分析作出了概括性的总结。
另外,在实时数据方面,Bollen等人[6]研究了Twitter情感和社会经济现象之间的联系。Wang等人[7]设计了一个系统,通过Twitter的实时数据来分析2012年美国总统选举。Hays等人[8]设计了一种基于Unix的多线程系统来获取和控制实时数据。Lee等人[9]提出了基于实时数据的入侵事件监测,通过对数据的实时分析来判断是否发生了入侵事件。Witten等人[10]对数据挖掘需要使用到的实践性的机器学习工具和技术进行了研究。Fan等人[11]通过对大数据的挖掘,分析数据现在的状态,并通过算法和相应改进对未来的情况进行预测,从而更加充分地挖掘出数据的价值。在医疗领域,Lee等人[12]应用Twitter数据对疾病进行实时监测,并且由此建立了流感和癌症的模型演示,从而为医疗健康发展提供很有价值的信息。
从本质上来看,弹幕文本是基于时间序列的短文本,每一条弹幕都对应于相应的网络视频里的一个时间点。由于弹幕出现的时间较短,弹幕系统最近几年才开始被中国的一些视频网站所采用,目前,针对弹幕数据的研究还比较少。詹雪美[13]通过对弹幕视频区别于传统视频的特点出发,讨论了弹幕视频网站的产生、发展与意义。郑飏飏等人[14]利用网络弹幕数据句子级别的情感分析方法,建立了基于情感词典的分析模型,并通过对弹幕文本进行分词及计算单词情感值来绘制可视化曲线,以获取用户在观看网络视频时发送的弹幕数据中的情感分布。Xian等人[15]提出了一种视频情节边界检测的方法来识别和抽取视频情节的高潮部分。
由目前学者们的研究成果可见,虽然基于时间序列的短文本的研究较为成熟,但是这种短文本大多是基于社交媒体的内容,主要与发送者个人为中心,以发送者的视角、经历和分享内容为素材进行研究;而弹幕系统里的基于时间序列的短文本则是以视频为中心,一个视频的所有弹幕都是以这个视频为中心,观看该视频的用户根据视频内容发布评论,包括观看感受、剧情评价、吐槽等内容。这样的实时数据更有利于我们实时分析该视频的内容及用户的真实反馈;同时,通过分析观看相同视频情节的用户发送的弹幕特征,我们可以对用户进行分类,发现他们对不同情节的不同反应和态度。
3 弹幕数据及其预处理
3.1 弹幕数据来源及获取
鉴于国内视频网站AcFun和哔哩哔哩是最早引进弹幕系统的网站,弹幕系统较为成熟,且有大量用户使用其观看视频,其中,网站上视频每天播放量超过一亿,弹幕总量超过14亿,因此本文选择了哔哩哔哩视频网站的弹幕数据作为本课题的数据来源,通过多种不同类型的视频的弹幕文本进行实验。
在数据的获取方面,通过Python引用的requests模块,将每次观看某视频时网络请求所返回的数据(弹幕文本及相关内容)保存到本地中。由于每次请求最多可以返回8 000条弹幕文本数据,因此通过哔哩哔哩网站开放的一个相关接口取得能够请求的最大次数,再经过遍历得到每个视频可取的所有弹幕。
3.2 弹幕数据特点
当大量弹幕出现在屏幕上的时候,密集程度很大,在动态播放视频的时候,它们大多在屏幕上从右往左飘过,像是飞行的子弹,如图1所示。

Figure 1 An example of barrage comments图1 弹幕数据示例
哔哩哔哩视频网站目前活跃用户超过1.5亿,从哔哩哔哩网站下载的弹幕数据中,每条弹幕包含8个参数,这些参数构成了一条弹幕的所有属性,这8个参数分别是:
(1)弹幕出现时间(以距离视频开始的秒数为单位);
(2)弹幕的模式(包含滚动弹幕、顶端弹幕、高级弹幕等);
(3)弹幕的字号大小;
(4)弹幕的字体颜色;
(5)弹幕的发布时间(Unix格式的时间戳);
(6)弹幕池;
(7)加密后的弹幕发送者的ID;
(8)弹幕在弹幕数据库中的rowID(查看“历史弹幕”的时候使用)。

Figure 2 Part of the barrage comments of “The Garden of Words”图2 动画电影《言叶之庭》中的部分弹幕
图2为动画电影《言叶之庭》中的6条弹幕,本文使用的弹幕文本数据源均为该格式。由图2可知,这些弹幕是按照XML文本格式存储的,其中〈d〉标签里的内容是弹幕文本,即弹幕内容,〈d〉标签的p属性是该弹幕的其他特征。下面以图2的第一条弹幕数据对其格式进行具体说明,如表1所示。

Table 1 Description of parameters based on examples表1 结合弹幕实例对参数的说明
3.3 弹幕问题数据的预处理
由于视频用户的多样性和弹幕系统支持的语言的多样性,不同用户发送的弹幕内容风格完全不一样。有的用户发送的弹幕内容偏口语化,有的用户偏好发送网络流行词,有的用户偶尔发送表情或者由文字与符号组成的用于表示心情的图案(以下简称颜文字)。因此,在分析弹幕文本的时候需要分情况考虑,这样才能更好地理解用户发送的弹幕所要表达的含义。同时,有的用户只发送一两条弹幕,而这一两条弹幕中仅有的几个词不能体现出该用户发送弹幕的特点,反而造成了数据稀疏的问题。
问题数据的存在很有可能会影响弹幕数据的完整性和合理性,从而影响弹幕分析的结果。因此,对弹幕数据进行预处理是必须的。本文通过判断Python的字符类型来判断用户发送的文本内容的格式,从而有针对性地进行处理。
经过思考和多次尝试,针对不同的问题确认了相应的处理方法,具体的处理方法如表2所示。

Table 2 Processing of dirty data表2 问题数据的处理方法
4 基于弹幕的情感分析
4.1 弹幕情感分析的目的
随着网络视频的流行和网络视频用户的快速增多,用户在网络视频上留下的弹幕很可能被其他用户当作对视频内容的参考。而且,弹幕视频的流行与“吐槽”文化快速发展之间的关系不可分割,它能让人与人之间针对同类视频进行交流和互动。
目前来说,在情感分析领域很少有以弹幕文本数据为对象的研究。而事实上,随着弹幕系统的发展和日益丰富,弹幕文本数据所表达出的情感趋势和观点会更具有参考性,这些情感信息在用户选择视频的时候可以作为参考内容,满足用户对于视频类型、情节内容的视频检索需求。
因此,情感分析在弹幕文本数据的基础上是很有价值的研究需求,对于网络视频的选择和视频内容的判断都有一定意义。
4.2 网络弹幕常用词词典的建立
随着互联网的发展和数字媒体的流行,使用网络媒体的人越来越多。与此同时,由于社会实践或者具有影响力的“名人”效应,一些本没有意义的词汇被赋予了某些特殊含义,如“蓝瘦”一词,就是因为一段网络视频的出现,里面的人发音不标准,将“难受”读作“蓝瘦”而被广大网友用来表示自己难受的心情;一些本来具有意义的词汇被当作其他的含义使用,如“高能”一词,在文学中指才能过人,在化学中指(对象)具备很高的能量,影视中指内容拥有高度的表现力,而随着时代的变迁,在现代社会中“高能”一词常常被用来指对社会做出突出贡献的人。在网络视频中,常搭配作“前方高能”一起使用,表示视频即将到来的情节有亮点,含有调侃意味。这是因为在科幻电影中,当战舰遇到敌方发射光束攻击时检测器所检测到的粒子反应出现偏高的情况被称为高能反应现象。
在常用的分词程序中,使用普通的词典不能将这些词汇识别出来,从而不能够对句子进行有效的分词,也就会影响最终对文本语义及情感分析的结果。因此,需要建立一个网络视频弹幕常用词词典,用来对弹幕数据中经常出现的非常用词进行识别,通过分词程序将之分成单个的词,从而为后续的文本分析和情感分析做准备。
在网络弹幕常用词词典的建立过程中,词汇的选择是非常重要的。也就是说,需要有一定的建立原则,才能更好地覆盖弹幕视频用户的网络用语习惯。具体的词典建立原则主要如表3所示。

Table 3 Construction standards of barrage comments dictionary表3 网络弹幕常用词词典的建立原则
由表3可知,网络弹幕常用词主要来源于两方面。一方面是近几年的网络流行语,如“神马”“蓝瘦”“香菇”等;另一方面是在弹幕系统中具有特殊含义的词汇,如“前方高能”“前排打卡”“泪目”等。通过收集与分析这些词汇,将结合起来的词汇集合成相关词典。
4.3 弹幕文本分词原则
我们使用“结巴”中文分词的精确模式对弹幕文本进行分词,并且对词汇进行情感分析。在统计词频的时候发现有很多无明确含义的词在所有词的出现频率中占比非常高,比如“有”“的”“然后”等。国内研究文本分析的学者也对这个问题进行了一些研究和讨论。王素格等人[16]通过实验指出停用词表对文本情感分类的影响与特征选择和权重计算不尽相同,选用除去形容词、动词和副词外的其余词语作为文本分析时的停用词表,与不使用停用词表相比,情感分类的结果相差较大。熊文新等人[17]总结了停用词过滤在信息检索用户查询语句中的使用情况。
一般来说,停用词表有两种获取方式:一是通用停用词表;二是专用停用词表。通用停用词表一般是由一些研究人员专门统计、收集大量停用词,并将其制作成词典文件。通用停用词表具有词汇量大、词汇范围全的特点,但是它也在一定程度上限制了识别停用词的速度;专用停用词表则是基于统计的自动学习方法,先是从语料库中统计出高频停用词,然后构建停用词表,之后再由专人进行核查[18]。
详细的原则及说明如表4所示。
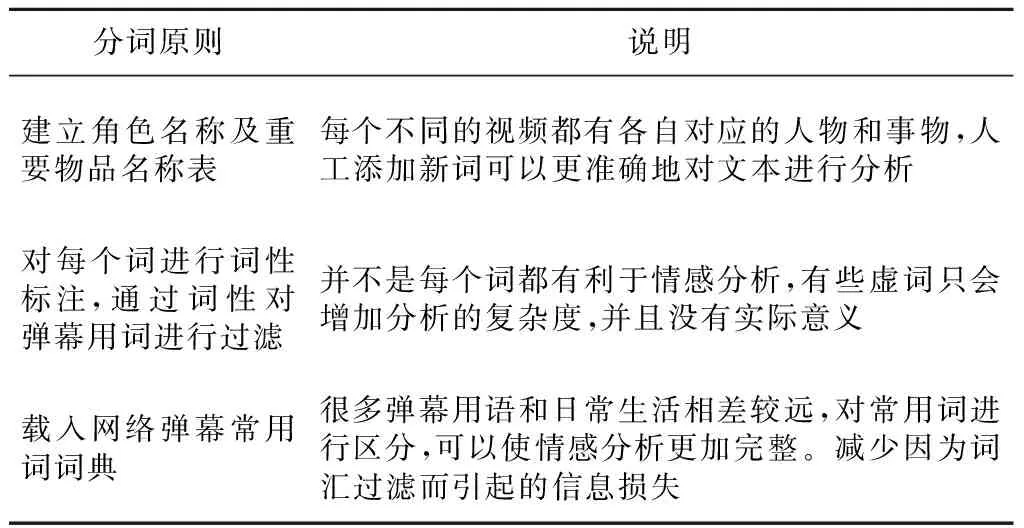
Table 4 Word segmentation principles表4 分词原则
4.4 情感分析的主要步骤
4.4.1 建立弹幕数据情感分析模型
由于情感分析对情感词典的依赖性很强,为了针对网络弹幕数据进行更有针对性的情感分析,本文采用了常见的情感词典库和网络弹幕用词词典库结合的方式,通过将含有情感倾向的词汇本身、词汇情感倾向、词性种类、情感强度等进行计算和统计,得到每个句子的情感状况。然后结合弹幕时间点的参数,将相同或相近时间段的弹幕数据分别进行统计,最后展现和分析结果。详细流程如下所示:
(1)选择含有弹幕数据的视频,并获取该视频的所有弹幕数据;
(2)使用分词工具对弹幕文本进行分词处理,词性标注,按照分词原则保留剩下的词汇;
(3)通过使用情感词典,将每条弹幕评论数据分词后的词汇与情感词典进行匹配,识别情感词,计算情感值,并对每条弹幕评论数据进行标注和统计;
(4)结合弹幕数据的时间序列,对该视频的所有弹幕所表现出来的整体情感趋势和局部情感数据进行统计、分析和可视化处理;
(5)重复(2),但是在处理弹幕文本的时候,删除部分噪音弹幕,再进行后续步骤的处理,将得到的结果与之前所有弹幕进行处理得到的结果作比较,观察两次分析的情感趋势和极值点的位置是否相同。
4.4.2 构建情感词典
本文的情感词典构建素材,都是来自于大连理工大学信息检索研究室的中文情感词汇本体库(http://ir.dlut.edu.cn/),徐琳宏等人[19]针对情感词汇的构造作了研究和说明。这是一个从多个角度描述中文词汇或者短语的词汇库,其中包括的部分有词性种类、情感类别、情感强度以及情感极性等多方面信息。
该情感词汇本体库将词汇情感分为7大类,再细分为21小类,为了便于对弹幕文本进行情感数据的分析和统计,本文将主要考虑这7个大类情感,分别是乐、好、怒、哀、惧、恶、惊。其中,前两个情感属于正向情感,后面的属于负向情感。
通过对动漫剧集《全职高手》第一集进行处理,得到这一集的弹幕数据中包含的情感词。将各个情感类别出现的情感词进行统计,得到该视频中属于这7个大类的情感词。部分数据如表5所示。

Table 5 Sentiment category表5 情感类别表
4.4.3 计算弹幕情感值
每条弹幕的情感值是这条弹幕里所有具有情感倾向的词语的情感值之和。例如,一条弹幕为“我很喜欢这条狗”,则计算这条弹幕返回的情感值为[0,2,0,0,0,0,0]。可以看出,弹幕返回的情感值是一个含有7个元素的列表,列表中每个元素代表一个维度的情感值,按照乐、好、怒、哀、惧、恶、惊的顺序。例如,第一个元素0表示该句弹幕中“乐”的情感值为0;第二个元素2表示该句弹幕中“好”的情感值为2。其中,“喜欢”一词可以表示值为1的“好”的情感,而它前面的“很”作为程度副词,加强了“喜欢”的情感值,故乘以2倍,情感值为2。后面的几个0依此类推,表示在这条弹幕中,其他五个维度的情感值均为0。
在分析弹幕情感的时候,可以考虑分为二维和多维的情感分布。在之前介绍的7类情感类别中,乐、好、惊可以作为正向情感,其余4类作为负向情感,通过将所有弹幕的正向情感值和负向情感值绘成曲线,对比观察该视频不同阶段用户对于视频内容的情感倾向。
与此同时,可以作出7维情感图,从多个角度来分析弹幕用户对于视频内容的观感和评价。制作7维情感图的步骤主要如下:
首先,对分词后的弹幕进行7个角度的情感值计算,将之存储在7维列表中;然后,将每一段时间(如30 s)7种情感的值求平均数;再将这些数据分别绘出,其中,没有相应情感值的弹幕不作记录。
通过对情感类型进行细分,可以更加详细地描述弹幕用户在视频各个阶段的情感动态,方便对弹幕和视频进行分析。
5 弹幕用户的分类
通过每个用户发表的所有弹幕数据的情感分析,7维的情感分布可以代表该用户的情感特征。本文提出基于情感的自动k-means聚类算法来进行用户自动分类。在聚类算法中,有两个需要解决的难题,包括数据间的距离计算以及如何自动确定类的个数。为了使得该基于情感的k-means能自动分类,我们引入了聚类评价准则。由于聚类的对象是用户的7维情感分布,我们提出在聚类算法中应用动态时间规整DTW(Dynamic Time Warping)算法来计算距离。
算法1基于情感的自动k-means算法
输入:用户情感数据DN*T。
输出:各个用户属于某个类的标签P。
调用基于情感的k-means(m),得到WB(m);
end
根据WB(m)拐点,自动确定类的个数k;
调用基于情感的k-means(k)得到P。
算法2是基于情感分布的自动k-means聚类算法伪代码。
算法2基于情感的k-means算法
输入:用户情感数据DN*T,聚类个数k。
输出:P,WB(k)。
随机生成k个点,作为初始的中心点;
while(算法未收敛)
对N个点:计算每个点到k个中心点的DTW距离,最近距离的中心点即为属于那一类;
对于k个中心点:
(1)找出所有属于自己这一类的数据点;
(2)把自己的坐标修改为这些数据点的中心点坐标;
if(新的中心点与旧的中心点坐标相同)
break
end
end
计算类内距离SSW(k),类间距离SSB(k),得到WB(k);
算法的输入数据DN*T是由N个用户、视频时间长度T组成的数组,其中每个用户在每个时间刻度由7维情感数据来代表。我们首先根据聚类评价准则来寻找最优类的数目k,确定k后获得具体的聚类结果。
5.1 距离计算
动态时间规整DTW算法是一种结合时间规整和间距测量计算的算法。它通过将部分时间间隔伸长或缩短,使其与另一时间序列的长度相对应,从而用来计算两个时间序列的最短距离,该距离即可表示它们的相似度,该算法在语音识别领域使用较多。
具体的计算如图3所示,其中,对于时间序列Q和C,它们的长度分别是n和p,如果n不等于p,就可以通过动态规划将它们对齐。
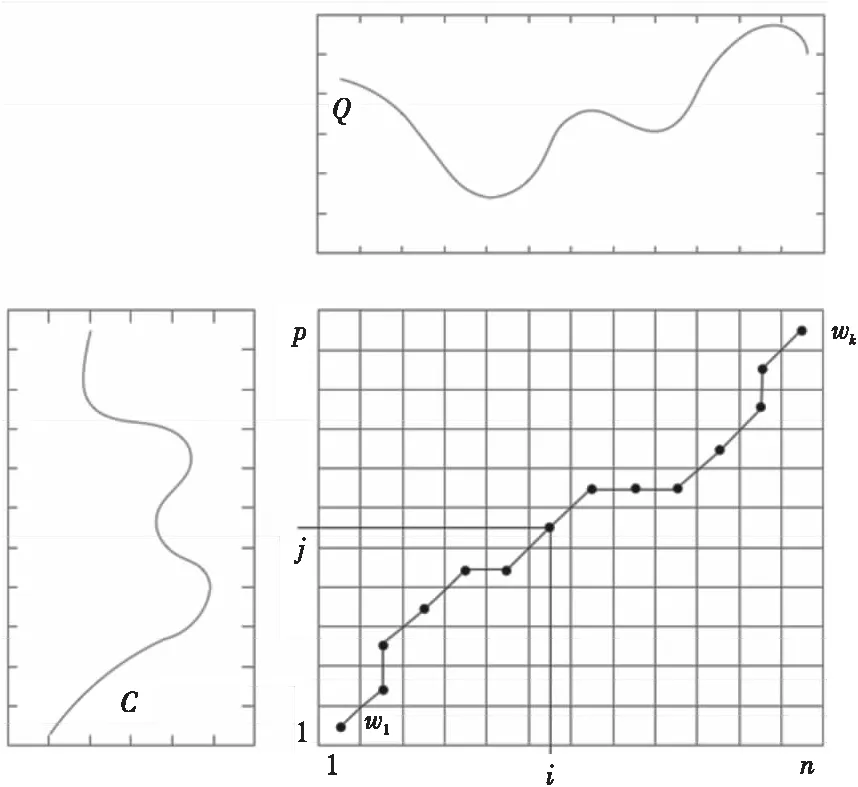
Figure 3 Regulation of two time series图3 两个时间序列的规整
为此构造一个n*p的矩阵网格,矩阵元素(i,j)表示qi和cj两个点的距离d(qi,cj),寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。我们把这条路径定义为规整路径,并用W来表示,W的第k个元素定义为wk=(i,j)k,于是,W的计算公式如下所示:
W=w1+w2+w3+…+wk
(1)
这条路径的选择需要满足以下几个条件:
(1)边界条件:w1=(1,1)和=wk(n,p)。一个时间序列的先后次序不可能改变,因此所选的路径必定是从左下角出发,在右上角结束。
(2)连续性:如果wk-1= (a′,b′),那么路径的下一个点wk=(a,b)需要满足 (a-a′) ≤1和(b-b′) ≤1,以保证Q和C中的每个坐标都在W中出现。
(3)单调性:如果wk-1= (a′,b′),那么路径的下一个点wk=(a,b)需要满足0≤(a-a′)和0≤(b-b′),以保证图中W的点随时间单调。
这样,每个点就只有三个路径方向,我们需要的路径是能够让规整代价最小的路径。
定义累加距离为y(i,j),它表示当前格点距离d(i,j),也就是点qi和cj的欧氏距离与可以到达该点的最小的邻近元素的累积距离之和,计算公式如下所示:
y(i,j)=d(qi,cj)+
min{y(i-1,j-1),y(i-1,j),y(i,j-1)}
(2)
通过以上规整计算,就可以得到n*p矩阵左下角到右上角的最小代价路径,即为序列Q与C的DTW距离。
5.2 聚类评价指标
由于聚类算法是一种无监督的方法,我们需要聚类评价指标来对类的个数进行确定,也需要通过聚类评价指标来对聚类的结果进行评估。一般来说,评价的原则主要有类内距离和类间距离两种。
5.2.1 类内距离
类内距离是指聚类后一个类内元素之间的距离,一般有两种方式度量,分别是平均距离法和组内平方和误差法。
平均距离法首先要计算出所有元素两两之间的距离,然后得到它们的平均值,这个平均值作为类内距离。公式如下:
(3)
其中,i表示类的序号,表示第i个类的类内距离,Ci表示第i个类,N表示元素的数量,x、y表示第i个类中的两个元素,在这里指的是两个用户,d(x,y)表示元素x和元素y之间的DTW距离。
组内平方和误差法SSW(Sum of Squares Within)也是首先计算每个类中各个元素与其他元素之间的距离,然后取所有距离的平方和,这个平方和就被当作这个类的类内距离。公式(4)介绍了计算类内距离的组内平方和误差法的计算公式:
(4)
其中,m表示元素的序号,n表示元素的数量,xm表示第m个元素,Pm表示中心点的序号,CPm表示中心点。
5.2.2 类间距离
类间距离是指聚类后两个类之间的距离,一般有以下几种方式度量,分别是最短距离法、最长距离法、平均距离法、中心点距离法和组间平方和误差法。
最短距离法Dsl首先计算一个类中各个元素与另一个类中所有元素之间的距离,然后取其中的最小距离,这个最小距离就被当作这个类的类内距离。下面公式介绍了计算类内距离的最短距离法的计算方法:
Dsl(Ci,Cj)=minx,y{d(x,y)|x∈Ci,y∈Cj}
(5)
其中,i表示类的序号,Ci表示第i个类,Cj表示第j个类,x、y分别表示Ci和Cj中的两个元素,d(x,y)表示x、y这两个元素的距离。
最长距离法Dcl也是首先计算一个类中各个元素与另一个类中所有元素之间的距离,然后取其中的最大距离,这个最大距离就被当作这个类的类内距离。下面公式介绍了类内距离的最长距离法的计算方法:
Dcl(Ci,Cj)=maxx,y{d(x,y)|x∈Ci,y∈Cj}
(6)
其中,i表示类的序号,Ci表示第i个类,Cj表示第j个类,x、y分别表示Ci和Cj中的两个元素,d(x,y)表示x、y这两个元素的距离。
平均距离法Davg也是首先计算一个类中各个元素与另一个类中所有元素之间的距离,然后取所有距离的平均值,这个平均值就被当作这个类的类内距离。下面公式介绍了计算类内距离的平均距离法的计算公式:
(7)
其中,i表示类的序号,Ci表示第i个类,Cj表示第j个类,x、y分别表示Ci和Cj中的两个元素,d(x,y)表示x、y这两个元素的距离。
中心点距离法Dcentroids采用每个类的中心点作为计算的元素,用两个类的中心点之间的距离来表示它们的类间距离。公式如下:
Dcentroids(Ci,Cj)=d(ri,rj)
(8)
其中,i表示类的序号,Ci表示第i个类,Cj表示第j个类,ri表示第i个类的中心点,rj表示第j个类的中心点,d(ri,rj)表示第i个类和第j个类的中心点的距离。
组间平方和误差法SSB(Sum of Squares Between)先计算出每个类的中心点和所有类的中心点,用它们的距离的平方和累加得到类间距离。公式如下:
(9)

可以看出,组间平方和误差法和平均距离法比较类似,它们都采用了类内所有元素的距离。组间平方和误差法采用每个类的中心点和所有类的总中心点的距离,当作该类中所有元素与总中心点距离的平均值,从而计算距离平方的和;平均距离法采用的是所有元素的距离和的平均值,可以减小因为类内某些元素分布不均造成的计算误差。
5.2.3 结合评价
由于聚类结果没有统一标准的评价方式,因此国内外一些学者针对聚类结果的衡量标准做了很多研究。Zhao等人[20]提出了一种基于平方和的指标WB-index,该指标具有更容易寻找类的个数的特点,因此在本文中,我们运用该指标确定类的个数。
WB-index结合类内距离的评价标准组内平方和误差、类间距离的评价标准组件平方和误差和聚类个数,通过检测曲线拐点来确定最小的聚类数量。
一般来说,拐点是可能选择最优聚类数量的地方,但是在评价聚类效果的时候,没有明确的理论或者研究结论可以定位拐点。这方面的研究也不够完善。曲线中的最大值和最小值是最直接的拐点,但是有一些指标是单调递减或者单调递增的,也就是说没有明显的拐点,即没有最佳聚类数量。另一些评价聚类效果的指标随着聚类数量的增加,会出现曲线拐点,即可以找到最佳聚类数量。
当检测指标的曲线出现拐点时,其所对应的横坐标数值很大概率是最优的类的数目,如图4所示。其中,横坐标表示类的个数,纵坐标表示的是采用的聚类评价指标的值,K点为曲线的拐点,N1是K点对应的聚类数量。在K点之前,指标数值一直在增加,在K点时到达极大值,K点之后指标数值开始减小。因此,K点所对应的聚类数量N1即可作为聚类时选择的类型数量。
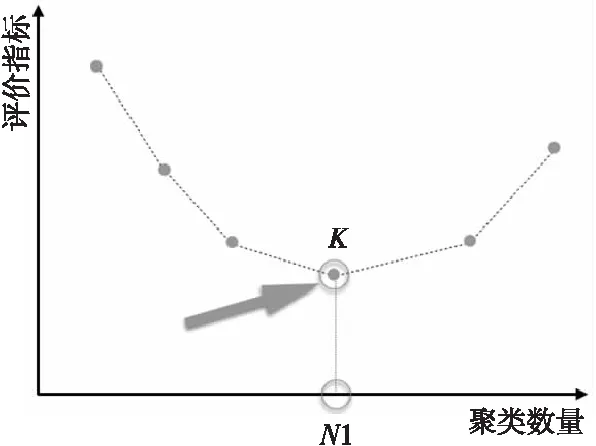
Figure 4 Curve point detection图4 曲线拐点检测
SSW聚类评价方式常被用于衡量类内元素的紧凑度,SSB聚类评价方式常被用于衡量类与类之间的分离度。基于平方和的指标,即WB-index常会在聚类数量增加的时候出现拐点,其公式如下所示:
(10)
其中,k表示聚类的数量,SSW表示组内平方和误差,SSB表示组间平方和误差。
6 实验结果分析及应用
本文中数据全部来源于哔哩哔哩视频网站。视频弹幕数据主要包括弹幕文本内容、弹幕出现时间、弹幕发布时间和加密后的用户id。所有的数据预处理及分析算法都是用Python实现的。
6.1 数据预分析
以电视剧《青云志》第七集为例,将视频每20 s的弹幕数量进行统计,并绘出整个视频的弹幕数量分布图,如图5所示。
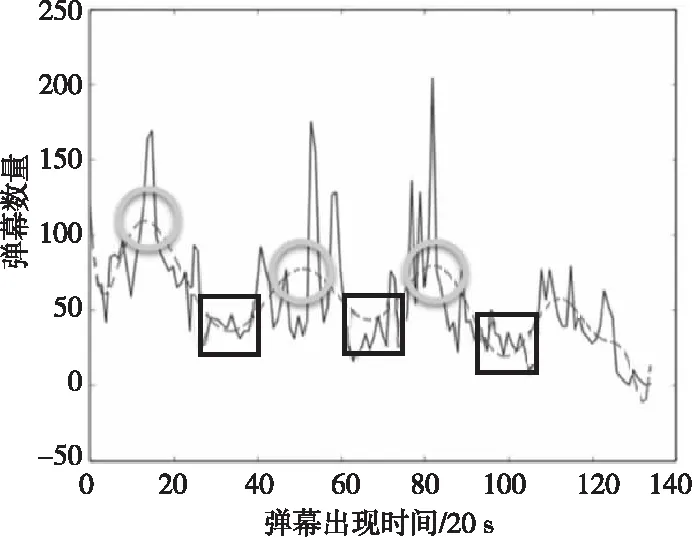
Figure 5 Distribution of the number of barrage comments and time图5 弹幕数量-时间分布图
图5中,实线表示每20 s的弹幕总数,虚线是通过最小二乘法对实线的拟合,可以用来表示实线的整体趋势。由图5中可以看出,弹幕数量随着视频播放的进行变化趋势较为明显。在视频一开始,弹幕数量比较多,随后慢慢减少,这是因为很多视频观众喜欢在视频一开始的时候发送大量“问候”用语,如“前排打卡”“重新来看”等弹幕。这些弹幕虽然经常出现,但是并不能够表达用户对于视频的真实感受。这样的弹幕就会成为噪音弹幕,从而影响弹幕文本分析的结论。
从图5还可以看到,每隔一段时间,弹幕数量就会出现峰值和谷值。如时间为5 min(图中x轴为15)、18 min(图中x轴为54)、27 min(图中x轴为81)时,即圆圈内均为该视频弹幕数量的峰值点,说明这些地方的情节引起了观众的共鸣,因此观众发送弹幕表达自己的所见所思所感。通过观看视频,发现第一处是时下很受欢迎的两个少年歌手在打闹的情节;第二处是一位得道高人给男主角传授功法的情节,此时很多人在吐槽他的选择;第三处是剧中神兽灵尊出现的情节,引起了众多观众对特效的评论。因此,弹幕数量是可以大致反映情节对观众的吸引力的。
相对而言,时间在11 min(图中x轴为33),21~22 min(图中x轴为65左右),33~34 min(图中x轴为100)时,即方框内均为该视频弹幕数量的谷值点,说明这些地方的情节观众不太愿意发送弹幕评论,是因为这里的故事情节平淡无奇,没有什么可“吐槽”或评论的特点。
本视频共有7 634条弹幕,2 628个单独用户,人均弹幕发送量2.9条。为了降低噪音弹幕对分析的干扰,对视频的每个用户发送的弹幕数量进行统计,结果如图6所示。
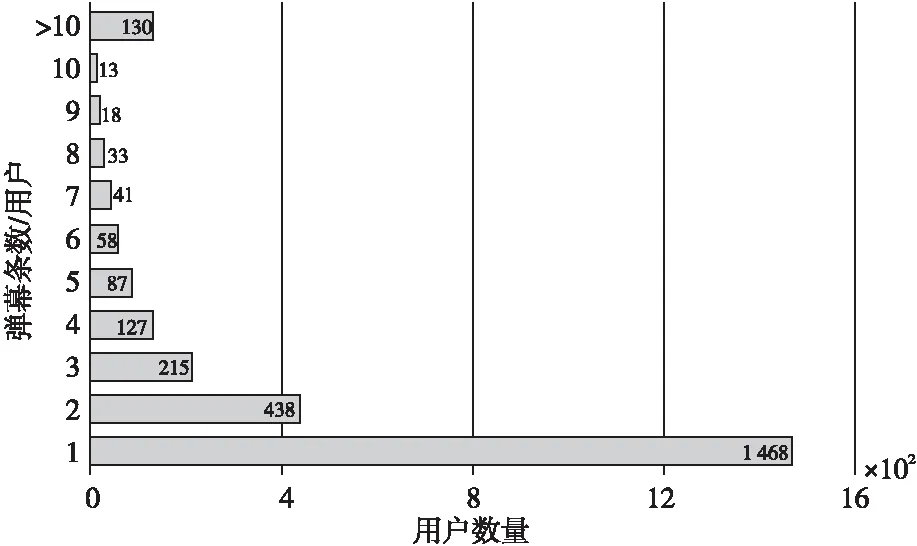
Figure 6 Statistical chart of the number of barrage comments per user and the number of users图6 每个用户发送的弹幕条数-用户数量统计图
由图6可以看出,仅发送1条弹幕的用户数量有1 468位,远超仅发送2条弹幕的用户数量两倍有余,而随着每个用户发送弹幕条数的增多,用户数量也成单调递减状态,弹幕发送数量超过10条的用户共有130人。
为了更清楚地分析每个用户发送弹幕数量的比例关系,将不同情况下用户数量所占比例绘制成饼图,如图7所示。
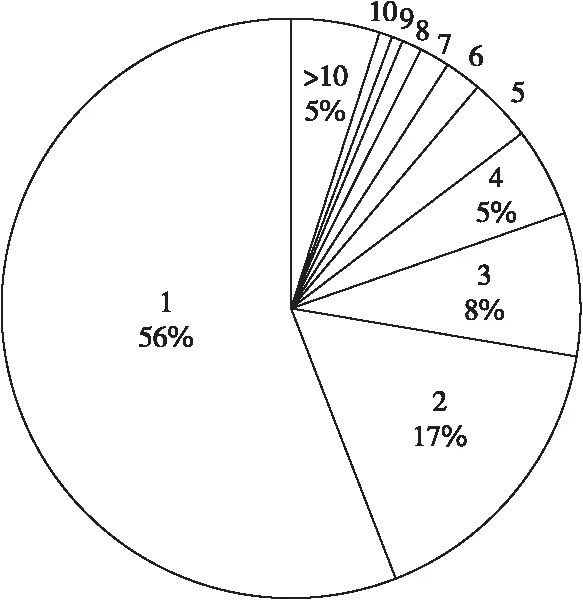
Figure 7 Pie chart of the number of users sending different numbers of barrage comments图7 发送不同弹幕条数的用户数量统计饼图
由图7饼图可以很清晰地看出,仅发送1条弹幕的用户占用户总数的一半以上,仅发送2条弹幕的用户占用户总数的接近五分之一。现在,删去发送弹幕数量少于3条的用户发送的弹幕,再对弹幕数量与视频时间的函数关系进行统计,结果如图8所示。

Figure 8 Distribution of the number of barrage comments after filtering and time图8 噪音弹幕过滤后的弹幕数量-时间分布图

Figure 9 Time distribution of the number of noisy and original barrage comments图9 噪音弹幕数量/原始弹幕数量-时间分布图
将图8与图5对比可以发现,在各个时间段,视频弹幕的数量都相应减少,而弹幕数量随着视频时间的变化趋势还是与过滤弹幕前几乎一样。为了更好地看清楚噪音弹幕在各个时间段的分布,将噪音弹幕数量/原始弹幕数量和视频时间之间的关系输出出来,结果如图9所示。纵坐标采用的参数是噪音弹幕数量的比重niIndex,它是噪音弹幕数量noiseBNum和原始弹幕数量initialBNum的比值,公式如下:
(11)
其中,噪音弹幕是指发送弹幕条数少于3条的用户发送的弹幕,原始弹幕是指未经过滤的视频弹幕。它们的比值反映了噪音弹幕在视频不同时间段的所有弹幕中所占的比重情况。
从图9中两个视频虚线的趋势可以看出,噪音弹幕在视频开始和视频结束的时候有两个很明显的峰值,点P1和点P2。它们的值都接近或超过0.5,也就是说,在视频开始(0 s)和视频结束(43~44 min)时,观众发出的弹幕有接近或超过一半的都是噪音弹幕。这与之前关于弹幕用户喜欢在视频开始和结束时发送“前排打卡”“完结撒花”“进度条撑住”等弹幕的假设相符合。
将《青云志》第七集视频与第一集视频对比可以发现,第七集视频的中间部分噪音弹幕的比重维持在0.2~0.4,而第一集视频从开始到10 min(图中x轴为30),噪音弹幕比例一直在下降,之后维持在0.2~0.3,由此可见,噪音弹幕比不仅与视频的时间分布有关,还与视频的内容有关。有理由推测,第一集视频的中间情节比第七集更加吸引用户发表评论。
6.2 情感分析
在对弹幕文本进行情感分析的过程中,需要注意的地方主要有两个:一是弹幕文本的选择,即对哪些弹幕文本进行情感分析,删除哪些弹幕文本;二是每条弹幕中需要分析的词语的选择,有些词语没有实际意义或者没有情感趋向,需要在情感分析的过程中将其过滤,保留具有情感倾向的词语。
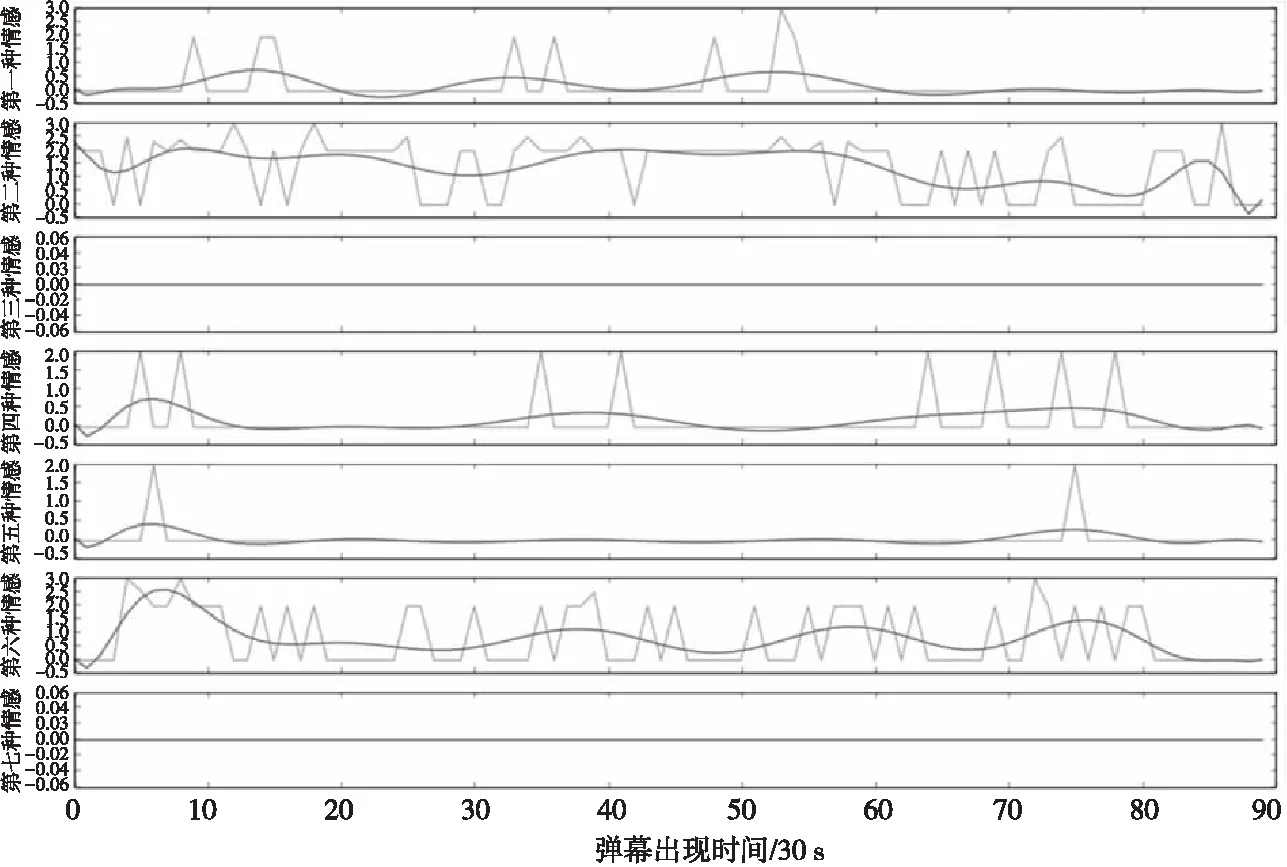
Figure 10 Time distribution of 7-dimension sentiment value图10 弹幕7维情感值的时间分布
基于以上考虑,以及对比和研究,本文决定采用去除噪音弹幕的方法来提升分析的准确度。在去除噪音弹幕之后,对弹幕分词后的词语进行判断,分析它们是否具有明显的情感倾向。通过将同一段时间内的所有弹幕的情感值取平均数,即可获得这段时间弹幕用户对于该段视频的情感倾向。
针对电影《言叶之庭》的弹幕数据,它共有32 323条弹幕。我们进行7维情感分析,即乐、好、怒、哀、惧、恶、惊,得到的结果如图10所示。
从图10的弹幕数据情感图可以看出,在不同的时间段(每30 s)的同一项情感的数值有较大差异。在相同的时间段,7种不同的情感类型的数据值也有较大差异。
如第一种情感“乐”,在视频的4~10 min(图中x轴为[8,20]),15~20 min(图中x轴为[30,40]),15~18 min(图中x轴为[45,54])等处,其值在2以上。说明这段时间的视频情节含有“乐”的内容,因此弹幕用户会选择在这里发送有关于“乐”的弹幕。而在视频的其余一些时间段,弹幕用户几乎没有发送过“乐”相关的弹幕,说明这段时间的视频情节没有什么内容吸引用户发送“乐”相关的弹幕。即可推测,这里的视频内容不够“乐”。
而与“乐”具有相近含义的“好”则表现出了一些不同的特点,它的分布区间更大,出现“好”相关的弹幕也较多。这是因为“喜欢”“表白”等词都属于“好”,在观看视频过程中,弹幕用户经常发表自己对演员角色的评价。比较常见的积极性评价一般为“喜欢”某演员或者某角色,并向他们“表白”等。
第三种情感“怒”和第七种情感“惊”均一直为0,也就是说,在这个视频中,没有用户发表有关这两种情感的弹幕内容。从实际内容来看,这个视频由于是一部40 min左右的电影《言叶之庭》,并且电影没有戏剧冲突十分强烈的情节,也没有出其不意的部分,更多的是以平铺直叙的方式展开叙述。因此,没有弹幕用户发表这两种情感的弹幕也是合理的。
其余几种情感也是各自分布不同,如第六种情感“恶”就几乎一直贯穿在视频中间,说明该视频的情节内容经常会让用户想发送“恶”相关的弹幕,而“恶”和“好”也是这7种情感中仅有的两种贯穿全剧的情感。
显然,每个不同的视频,情感的分布是会有差异的。但是,通过在其它类型的视频中运用相同的计算法则,发现出现较多的情感类型常为“好”和“恶”。其它类型的情感则根据视频的不同会有相应的分布变化。
例如,在视频《西游降魔篇》中,也是“好”和“恶”的相关弹幕最多。具体的情感分布如图11所示。对比图10,从分布比例上看,第五种情感的出现频率显然增大。也就是说“惧”相关的弹幕出现频率增大,有更多观众在观看这部视频的时候发送了具有“惧”含义的弹幕。试着将其中一部分弹幕输出出来,如表6所示。
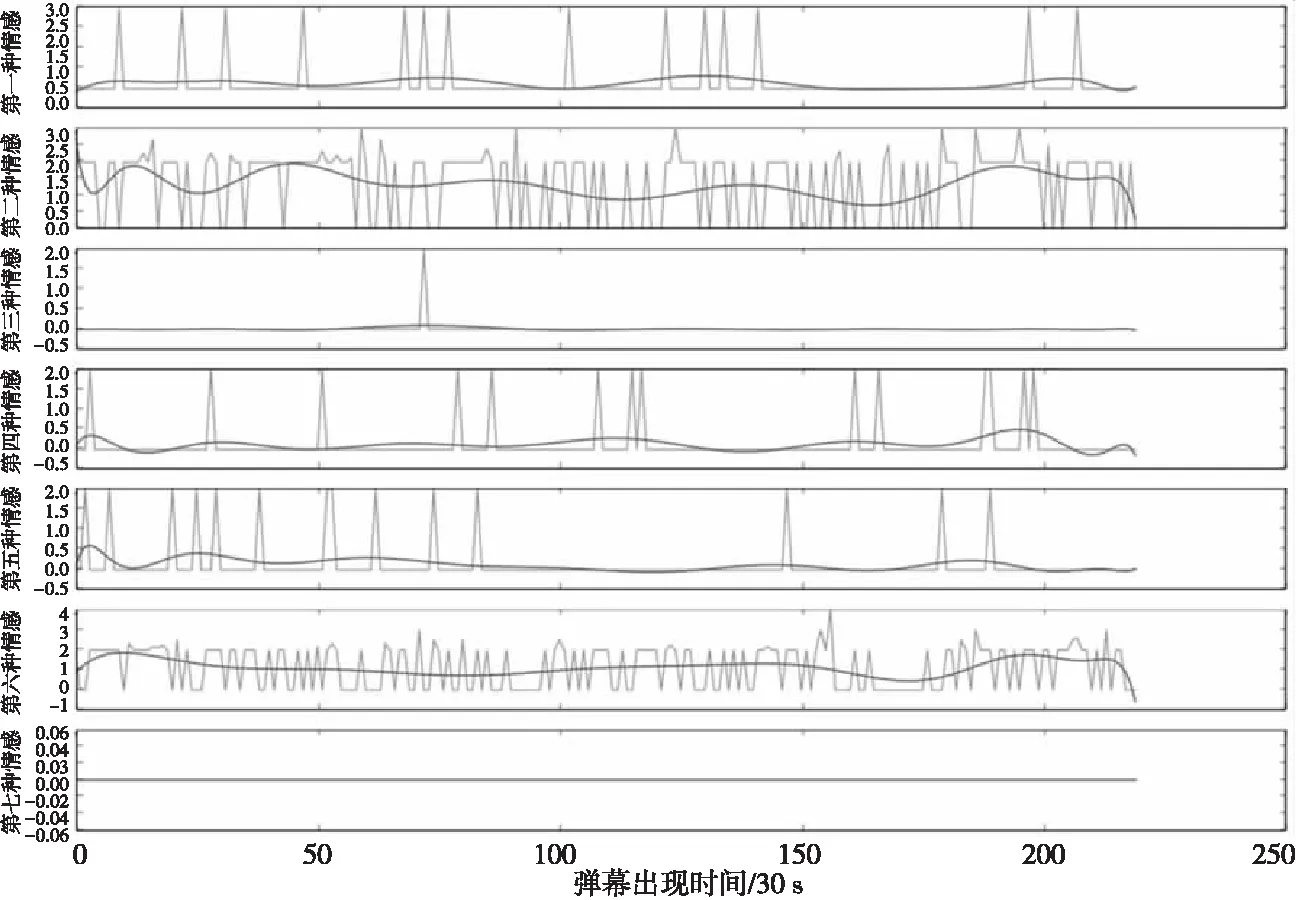
Figure 11 Time distribution of 7-dimensional sentiment value in “Journey to the West:Conquering the Demons”图11 《西游降魔篇》弹幕7维情感值的时间分布Table 6 Partial barrage comments that represent “scare” in “Journey to the West:Conquering the Demons”表6 《西游降魔篇》表示“惧”的部分弹幕

表示“惧”的弹幕(部分)猪刚鬣的脸好恐怖这段超可怕啊这段比鱼怪恐怖多了…这段挺吓人的,同志们注意了这一段恐怖爆了这段也超恐怖前面好吓人
从表6可以看出,用户普遍在表达对于视频内容的“惧”,有表示“恐怖”的,也有表示“吓人”的,因为这段视频中猪刚鬣恢复成原本的样貌,是头很可怕的猪,电影造型也非常恐怖。因此,很多观众表达了自己对于这个场景的“恐惧”,说明这部电影的“惧”的元素比《青云志》第七集的多。
经过这样的情感标注,可以对视频内容进行情感预测。例如,有些观众害怕“恐惧”的内容,则可以通过对弹幕的情感分析,在出现大规模“恐惧”弹幕之前提示相关用户,从而帮助用户更好地观看视频。
从相同的时间段来看,不同类型情感的数值差异更为明显。在图11的开始部分(x轴为[0,50])这一阶段,第一种情感“乐”和第二种情感“哀”分布都较为稀疏,说明这两种情感在这段时间的视频内容上分布较少。而第三种情感“怒”和第七种情感“惊”,它们不仅在视频开始的时间段没有情感值,在整个视频中也极少有相关弹幕。
由此说明,对于每段不同的情节,弹幕情感类型的分布会有较大差异,且差异随着视频内容的改变而相应变化。
6.3 用户情感类型分析
将弹幕用户发送的所有弹幕进行统计、归类,为了使弹幕数据可以更好地反映出用户的情感信息,将个人发送弹幕数据量少于3、5、10、15以及20条的分别删去,对剩下的用户进行情感值(只计算积极和消极情感)的计算和统计,结果如图12所示。
从图12中可以看出,随着个人弹幕发送数量的增加,用户情感值相对较小(正向和负向)的依次减少,剩下的用户发送的弹幕的情感值偏高。由此可以得出,用户发送的弹幕数量越多,含有情感倾向的趋势越明显,也就是说,发送的弹幕内容越多,越容易从中抽取出用户针对某个视频发送弹幕的个人情感倾向。还可以看出,一般来说用户的积极情感值显著高于消极情感值,将用户中消极情感值高于积极情感值的情感数据输出出来,并绘制成图,如图13所示。
从上面的分析我们可以得知,从弹幕中得到的情感指数可以反映一个用户的特征,比如正能量或负能量,这样的情感特征可以帮助我们去对用户进行分类。
6.4 用户分类
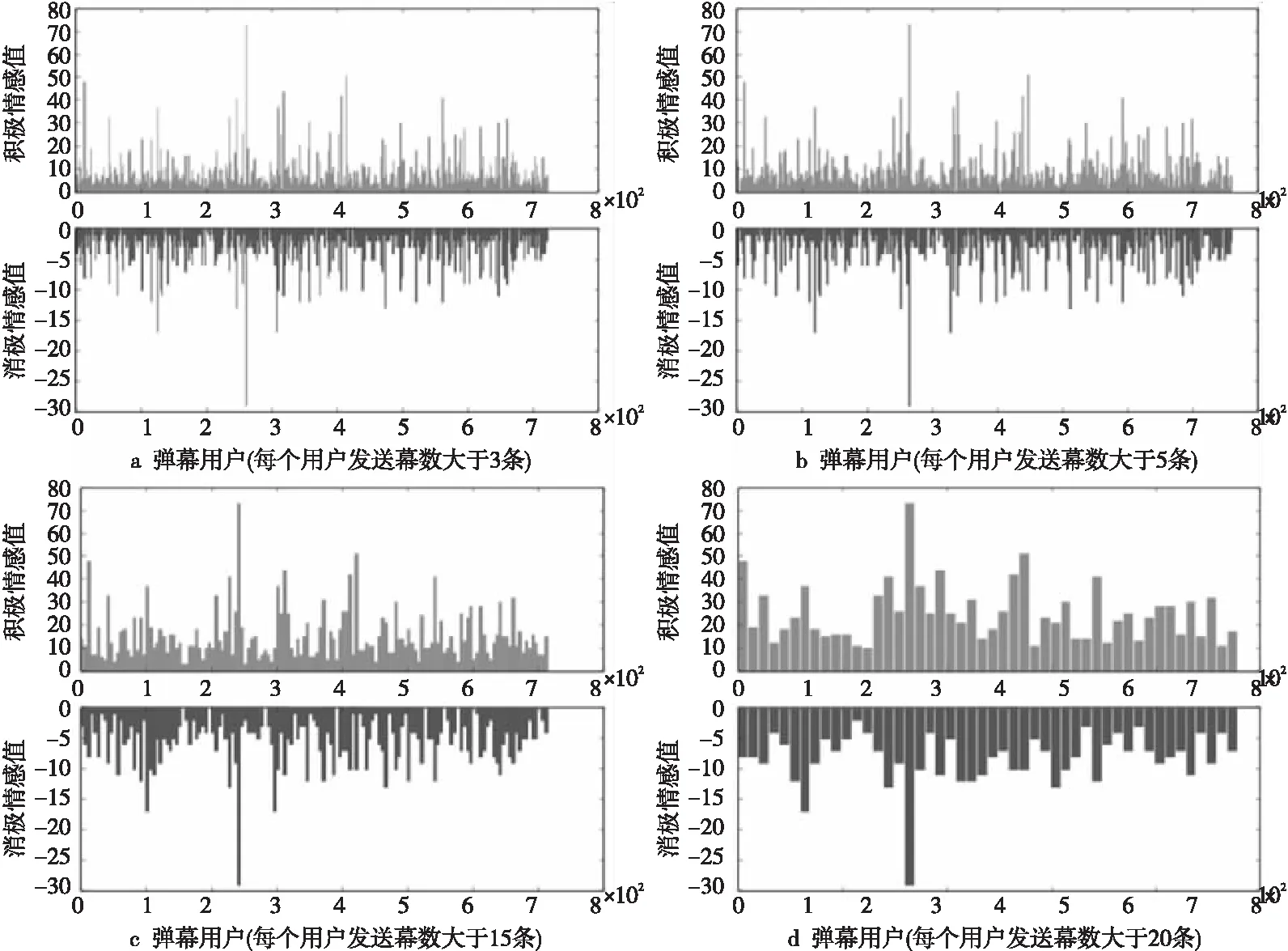
Figure 12 Sentiment value distribution of users图12 弹幕用户的情感值分布

Figure 13 Sentiment value of users who are more negative than positive图13 消极情感多于积极情感的用户的情感数据
首先,我们利用聚类评价指标来选取k-means算法中类的个数。图14表示SSW,SSB,SSW/SSB,WB-index与用户聚类个数k的关系,随着k值增大,采用的WB-index评价指标在降低的过程中多次出现拐点。因此,根据它衡量聚类个数时,可以认为拐点出现时的k值可作为合适的用户类别数。
由图14可以看出,随着k值的增大,表示类内距离和类间距离的衡量参数都呈增大趋势,其中,SSW/SSB值在短暂波动后趋于稳定上升。而按照WB-index衡量指标来看,随着k值的增大,虽然其值呈上升趋势,但是上升过程中出现了多个谷值点,如主题数量为7、9、14等的时候,这些拐点为我们提供了确定k值的可选范围。
在k为7的时候,WB-index第一次出现拐点,这个点意味着7比附近的k值(如6、8等)更合适作为聚类个数的选取。接下来,我们以7个类型为基础,对用户进行聚类。7个用户类数量分布如图15所示。由图15可以看出,类0、2、4含有较少的用户,均在70个左右;类5含有最多的用户,共有1 010个用户;类2含有的弹幕条数仅次于类型5,为607个;其他类的用户个数都在400左右。
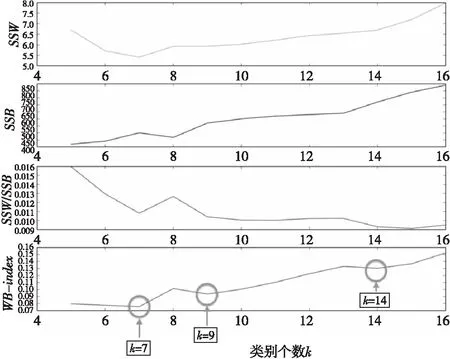
Figure 14 Relationship between clustering measurement index and k图14 聚类相关衡量指标与k值的关系

Figure 15 User distribution of each category when k=7图15 k=7时,各个类的用户数量分布图
分析各个类型的用户发送的弹幕的内容,将第一类随机取出两个用户发送的所有弹幕进行观察,这些弹幕如图16所示。

Figure 16 Comparison among all barrage comments sent by two users图16 两个用户发送的所有弹幕对比
由图16可以看出用户15cc0dec(以下简称用户1)与用户cdc9677a(以下简称用户2)发送的弹幕情感数值和相应时间。
实线框内的弹幕时间约在200~300 s内发送,且弹幕情感数据的值(7维情感都考虑的值)在DTW算法拉伸后较为相近;同样,在虚线框内的弹幕是1 100~1 800 s发送的,相似度看起来不是很高,在有情感值的弹幕中,只有虚线框内的最后一条弹幕情感数据完全一样;而实线框内的2 100~2 500 s内的弹幕则相似度较高,一方面弹幕情感值较为接近,另一方面它们的发送时间也较为连续,经过DTW对时间序列进行动态规整后,距离更加接近。
因此,通过以上的实验结果可以看出,在对弹幕数据进行情感分析的过程中,噪音弹幕多集中在视频的首尾部分。通过去除噪音弹幕可以更好地分析用户发送弹幕的情感以及视频情节对观众情感产生的影响。在根据用户情感对用户进行聚类的过程中,考虑到视频时间序列的拉伸和用户通过弹幕表达的对视频情节的情感状态,聚在一类的用户在观看视频时的确有相似的情感偏好,他们会在相同的时间节点上产生相同的情感。由此可见,通过弹幕情感数据对用户进行聚类可以较好地将同一类用户聚在一起,一方面可以分析这些用户发送弹幕的爱好和用词特征;另一方面,也能够据此对同类用户进行更加精准的视频推荐,分析他们对特定类型的视频是否具有相同的爱好。这些也可以作为视频推荐或者“知音”推荐等的依据。
7 结束语
弹幕数据的分析工作目前来说较少,本文主要对弹幕数据的获取、预处理以及深层次的分析方法进行了详细介绍,提出了基于弹幕数据情感分析的用户分类算法。该算法引入用户的情感指标,并以此指标作为用户特征进行无监督的分类。我们改进了传统k-means算法,使之能自动确定类的数目,并引入DTW来计算用户情感分布之间的距离。实验结果表明,我们的分析方法能很好地进行弹幕数据分析,并对弹幕用户进行分类标签。
在本文的基础上,未来还有其他可继续研究的方向。例如,可以通过弹幕的发布时间(如2017年5月30号)来研究视频从发布在网络上开始,用户的关注度、情感数据以及弹幕评论的内容是否会随着时间推移而显现特别的规律。同时,可以通过算法研究检测异常点,通过弹幕异常点的监测,分析相关视频的演职人员是否有了新的动态,从而造成了用户发送弹幕频率或状态出现了很大的变化等。
在这个大数据愈发流行的时代,对于数据的收集、处理和分析也显得愈加重要。弹幕这种新型的文本数据为我们在这个领域的研究提供了一个新的方向,同时这也是新的挑战。
[1] Song G,Ye Y,Du X,et al.Short text classification:A survey[J].Journal of Multimedia,2014,9(5):635-643.
[2] Wijeratne S, Heravi B R. Keyword sense disambiguation based approach for noise filtering in Twitter[C]∥Proc of the 1st Insight Student Conference,2014:1.
[3] Wang X, Wei F,Liu X,et al.Topic sentiment analysis in Twitter:A graph-based hashtag sentiment classification approach[C]∥Proc of ACM International Conference on Information and Knowledge,2011:1031-1040.
[4] Sakaki T,Okazaki M,Matsuo Y.Earthquake shakes Twitter users:Real-time event detection by social sensors[C]∥Proc of International World Wide Web Conference,2010:851-860.
[5] Kouloumpis E,Wilson T,Moore J D.Twitter sentiment analysis:The good the bad and the omg![C]∥Proc of International Conference on Weblogs Social Media,2011:164.
[6] Bollen J,Mao H,Pepe A.Modeling public mood and emotion:Twitter sentiment and socio-economic phenomena[C]∥Proc of ICWSM,2011:450-453.
[7] Wang H,Can D,Kazemzadeh A,et al.A system for real-time Twitter sentiment analysis of 2012 U.S. presidential election cycle[C]∥Proc of the ACL 2012 System Demonstrations.Association for Computational Linguistics,2012:115-120.
[8] Hays A V,Richmond B J,Optican L M A. A Unix-based multiple process system for real-time data acquisition and control[C]∥Proc of Wescon Conference,1982:1-10.
[9] Lee W, Stolfo S J,Chan P K,et al.Real time data mining-based intrusion detection[C]∥Proc of DARPA Information Survivability Conference & Exposition II,2001:89-100.
[10] Witten I H, Frank E,Hall M A,et al.Data mining:Practical machine learning tools and techniques[M].San Francisco:Morgan Kaufmann,2016.
[11] Fan W,Bifet A.Mining big data:Current status,and forecast to the future[J].ACM SIGKDD Explorations Newsletter,2013,14(2):1-5.
[12] Lee K,Agrawal A,Choudhary A.Real-time disease surveillance using Twitter data:Demonstration on flu and cancer[C]∥Proc of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2013:1474-1477.
[13] Zhan Xue-mei.Development of barrage of video website in China[J].Popular Science & Technology,2014,16(10):232-233.(in Chinese)
[14] Zheng Yang-yang, Xu Jian,Xiao Zhuo.Utilization of sentiment analysis and visualization in online video bullet-screen comments[J].New Technology of Library and Information Service,2015,31(11):82-90.(in Chinese)
[15] Xian Y,Li J,Zhang C,et al.Video highlight shot extraction with time-sync comment[C]∥Proc of International Workshop on Hot Topics in Planet-Scale Mobile Computing and Online Social Networking,2015:31-36.
[16] Wang Su-ge, Wei Ying-jie.The Influence of stoplist on the Chinese text sentiment categorization[J].Journal of the China Society for Scientific and Technical Information,2008,27(2):175-179.(in Chinese)
[17] Xiong Wen-xin,Song Rou.Removal of stop word in users’ request for information retrieval[J].Computer Engineering,2007,33(6):195-197.(in Chinese)
[18] Hua Bo-lin. Stop-word processing technique in knowledge extraction[J].New Technology of Library and Information Service,2007,2(8):48-51.(in Chinese)
[19] Xu Lin-hong,Lin Hong-fei,Pan Yu,et al.Constructing the affective lexicon ontology[J].Journal of the China Society for Scientific and Technical Information,2008,27(2):180-185.(in Chinese)
[20] Zhao Q,Fränti P.WB-index:A sum-of-squares based index for cluster validity[J].Data & Knowledge Engineering,2014,92(7):77-89.
附中文参考文献:
[13] 詹雪美.浅析弹幕视频网站在我国的发展[J].大众科技,2014,16(10):232-233.
[14] 郑飏飏,徐健,肖卓.情感分析及可视化方法在网络视频弹幕数据分析中的应用[J].现代图书情报技术,2015,31(11):82-90.
[16] 王素格,魏英杰.停用词表对中文文本情感分类的影响[J].情报学报,2008,27(2):175-179.
[17] 熊文新,宋柔.信息检索用户查询语句的停用词过滤[J].计算机工程,2007,33(6):195-197.
[18] 化柏林.知识抽取中的停用词处理技术[J].现代图书情报技术,2007,2(8):48-51.
[19] 徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J].情报学报,2008,27(2):180-185.
