一种基于深度学习的性能分析框架设计与实现*
2018-07-05冯赟龙何王全
冯赟龙,刘 勇,何王全
(江南计算技术研究所, 江苏 无锡 214083)
1 引言
随着高性能计算机技术的快速发展,越来越多的科研工作者能够使用高性能计算机进行研究。然而,高性能计算机体系结构进化得越来越复杂:更多的计算核心、更复杂的并行层次和存储层次,应用优化的门槛逐渐提高,让对相应体系结构不熟悉的普通用户望而却步,迫切需要一种能够让普通用户使用的智能化性能分析工具。
智能化的程序性能分析方法正在成为一个研究趋势,原因主要有两个:(1)应用优化的迫切需求,现有性能分析工具大多数都极度依赖于用户的性能分析经验知识,它们越来越难以支撑用户的性能优化工作;(2)人工智能技术的进步,为性能分析的智能化提供了有力的技术支撑。
机器学习作为重要的人工智能技术实现方法,已经被学者们用于智能化程序性能分析的研究[1]。深度学习是机器学习的一种实现技术,它在诸多领域均取得了重要成果,但并未出现在程序性能分析领域。本文提出了一种基于深度学习的程序性能智能分析框架,并在神威太湖之光[2]超级计算机上进行了实现,取得了良好的效果。它是深度学习技术在程序性能分析领域的一次探索和有益尝试,可为相关的研究带来一些启示。
2 相关工作研究
2.1 程序性能分析
高性能计算应用的性能分析工具根据所支持的功能分为三类:(1)采集类,主要提供基本的性能数据采集功能,如FPMPI(Fast Profiling library for MPI)[3]、mpiP[4]和PAPI(Performance API)[5]等;(2)可视化类,实现丰富的图表帮助分析,如Vampir[6]和CUBE(Cube Uniform Behavioral Encoding)[7]等;(3)集成类,集成多种层次的数据采集和可视化分析功能,如Vtune[8]、Scalasca[9]、HPCToolkit[10]和TAU(Tuning and Analysis Utilities)[11]等。这些工具在性能数据的采集方面已经有插装、采样、抽样等大量成熟技术,但对所采集数据的分析技术却相对较弱,需要用户掌握大量的体系结构和性能分析经验知识。随着处理器从单核到多核再到众核的不断发展进化,芯片体系结构的日益复杂导致用户使用性能分析工具的门槛不断抬高。
除了长期研究积淀形成的上述成熟工具外,还有大量的研究工作。Urlinger等人[12]提出一种基于预设性能问题自动搜索的方法,通过设置性能指标门限以及搜索策略,然后计算得到指标的严重程度和指标存在问题的可信程度,自动搜索程序中的性能问题和瓶颈。该方法能够实现分布式自动在线分析并且可以扩展至数千规模的处理器,它主要被用来解决工具的可扩展性问题。虽然它能够实现一定程度的自动化分析,但是参数设置仍然依赖用户的经验知识。Yoo等人[1]提出的使用硬件事件自动诊断性能问题方法ADP(Automated Diagnosis of Performance pathologies using hardware events),通过CFS(Correlation-based Feature Selection)方法自动选择关键硬件性能事件集构建决策树模型。但是,它忽略了硬件事件间复杂的影响关系,如图1所示,其中A、B两条线大致可将GLDPC(Global LoaD Per Cycle,指每cycle从主存加载数据的事件记数)与IPC(Instructions Per Cycle)的关系划分为三段:无明显关系、负相关趋势和负相关关系。直线A的左边为无明显关系,表示GLDPC的变化与IPC不存在明显的关系;直线A、B之间为负相关趋势,随着GLDPC的增大,IPC呈现出减少趋势;负相关关系指GLDPC与IPC存在一个确定的一次函数关系,即图1中所示直线C在直线B右边的线段,说明程序中GLD访问为主要开销。实际中还要再考虑其他指标影响,关系将会更加复杂。

Figure 1 Example of the complex relationship between hardware performance events图1 硬件性能事件的复杂关系示例
2.2 深度学习
深度学习使得机器学习能够实现众多应用,并扩展了人工智能的领域范围,它是2006年由Hinton教授提出的一种深层机器学习方法,具有较强的从样本中提取特征以及对特征进行转换的能力,学习能力强,是近几年国内外的研究热点[13]。深度学习明确突出了特征学习的重要性,也就是说,通过逐层特征变换,将原空间的特征变换到新的空间,使分类或预测更加容易。深度学习的常用模型有自动编码器、稀疏编码、深度置信网等。这些模型目前使用和应用都比较广泛,在图像分类、语音识别、目标识别、自然语言处理等多个领域均取得了成功应用。
深度学习模型的训练过程分为两步:预训练和调优。第一步:从底层开始,一层一层地往顶层训练,采用无标签数据或标签数据训练第一层;在学习到第n-1层后,将第n-1层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数;第二步:基于第一步得到的各层参数进一步优化整个多层模型的参数,这一步是有监督的训练过程。

Figure 3 Framework of program performance analysis based on deep learning图3 基于深度学习的程序性能分析框架
3 基于深度学习的性能分析方法
3.1 性能分析问题抽象
定位具体性能问题的过程,可抽象为一个分类问题。记一条性能数据为X,它包含多个资源类性能指标Xi(i=1,2,…,m),将所有性能问题(C)划分为若干性能问题类别(C1,C2,…,Cn),其中:
X=(X1,X2,…,Xm)
(1)
C=C1∪C2∪…∪Cn
(2)
Ci∩Cj=∅(i,j=1,2,…,n)
(3)
则从采集的性能数据分析性能问题的过程可描述为一个确定X所属分类Ci的问题。
3.2 基于深度学习的性能分析方法
基于深度学习的性能分析方法重点关注性能的分类模型,根据大量的性能数据,经过深度学习的训练,将多种性能指标归为几种典型类型,并指导程序员把握最主要的性能问题。该方法需要大量的数据作为训练的输入数据,我们使用处理器周期数进行标准化后的性能监控单元PMU(Performance Monitoring Unit)事件计数指标PI/Cycle,其中PI可以是任何一个PMU事件计数,Cy-cle为处理器周期。 现阶段有许多应用广泛的分类技术,如决策树、贝叶斯分类器等,这些浅层机器学习技术,在性能数据集比较完备的情况下能够达到非常好的效果,但目前硬件平台PMU等资源限制,使我们难以获得完备的性能数据集。而无论数据集是否完备,基于深度学习技术只需通过强大的学习能力对大量性能数据样本进行学习,即可挖掘到各性能指标间的复杂数据关系,建立起更为准确的分析模型。当前虽然已有利用机器学习进行程序性能分析的研究,但仅用到了浅层机器学习方法,本文方法的创新在于引入深度学习技术。如图2所示,左侧输入经过标准化后的性能数据指标,经过隐含层(Hidden Layers)的训练,右侧输出性能问题类别概率,概率最大的类即为性能问题类别。
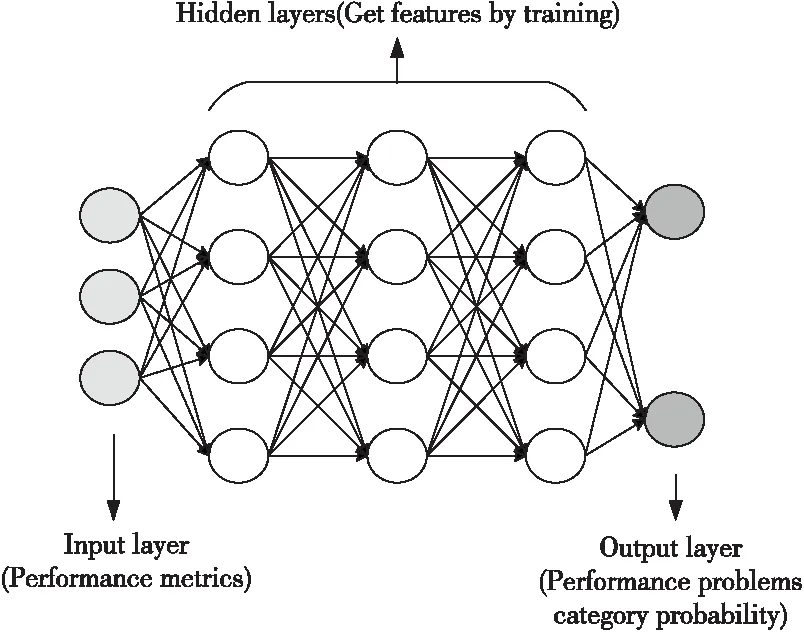
Figure 2 Program performance classification based on deep learning图2 基于深度学习的程序性能分类
4 基于深度学习的性能分析框架设计与实现
性能分析框架主要包括性能数据采集、基于深度学习的性能问题分类模型训练、性能数据分类和统计展示等四个部分,如图3所示。基于深度学习的性能问题分类模型训练采用大量作业的性能数据进行迭代训练,获得比较准确的性能问题分类,当训练收敛后,对于新采集的性能数据,可以进行性能问题的诊断,并对多进程的性能问题进行统计分析。
4.1 性能数据采集
采集不同的性能指标能够确定不同的性能问题类型。理论上若能采集所有的性能指标,那么可以分析出任何潜在性能问题,但考虑到性能指标采集时产生的程序扰动和软硬件开销,以及硬件资源本身的限制,显然选取其中若干重要的指标进行采集才是切实可行的方案。
深度学习技术依赖大量的数据进行学习,需要保证所采集数据的准确性,否则将会影响模型的效果。获取PMU事件计数指标的开销小,对程序本身的执行几乎不会造成明显的干扰,所获得的性能数据能够准确地反映程序的性能指标。PMU事件计数可通过系统提供的API以及相关工具接口获得。
4.2 基于深度学习的性能问题分类模型
4.2.1 稀疏编码模型简介
稀疏编码模型可以自动从无标注数据中学习,给出比原始数据更好的特征描述,实际运用时使用稀疏编码器发现的特征取代原始数据,往往能带来更好的结果。本文使用深度学习的稀疏编码模型进行实验研究。
稀疏编码模型由若干层自动编码器AE(Auto Encoder)堆叠而成,一个典型的AE结构如图4所示,输出层y与输入层x具有相同的规模结构,从输入层x到隐含层h的过程记为函数f,从隐含层h到输出层y的过程记为函数g,则:
h=f(x)=Sf(Wx+p)
(4)
y=g(h)=Sg(WTh+q)
(5)
其中Sf、Sg一般取为sigmod函数;W为输入层与隐含层之间的权值矩阵,WT表示隐含层与输出层之间的权值矩阵,p和q分别表示隐含层与输出层的偏置向量,为后续表示方便,记θ=(W,WT,p,q)。
假设输入层输入的数据样本表示为x=(x1,x2,…,xn),A为包含N个数据样本的训练集,则预训练AE的过程实质上就是利用A对其参数θ的训练过程,解码目标是使y和x尽可能接近,其接近程度使用重构误差函数L(x,y)来刻画,其定义为:
(6)
则训练集A的损失函数为:
(7)
对其进行极小化即可得到该层AE的参数θ。

Figure 4 AE structure图4 自动编码器结构
然而实际中,如果直接对损失函数作极小化,有时候很可能得到一个恒等函数。为了避免这种情况,可以对损失函数进行稀疏性限制,实现时通常采用一种基于相对熵的方法,损失函数如下:
(8)
其中,β为稀疏性惩罚项的权重系数;ρ为稀疏性参数,ηj表示输入为xi时隐藏层上第j号神经元在训练集A上的平均激活度。稀疏性惩罚项KL(ρ||ηj)的表达式为:
(9)
从KL(ρ||ηj)表达式可以看出,它随着ρ与ηj差值的增大而逐渐减小,当二者相等时取最小值0,因此可以通过最小化损失函数使得ρ与ηj尽量接近。
4.2.2 性能问题类别
依靠专家经验,可以根据性能指标直接确定性能问题类别,但主观性强,我们使用一种相对客观的方法,通过机器学习的聚类技术确定性能问题类别。
首先,使用聚类发现数据中的非随机簇数k,并使用差距统计(Gap Statistic)[14]方法进行簇的有效性评估,通过选取满足:
Gap(k)-(Gap(k+1)-sd(k+1))≥0
(10)
的最小k值确定最优簇数,也就是需要划分的性能问题类别数。然后,根据每个簇内数据的特征赋予性能问题类别实际意义,如果不能很好地解释每个簇就要考虑次优的划分方法,直到找到能被赋予实际意义的划分。
4.2.3 模型训练
模型训练主要依靠经验和实验尝试。深度学习虽然在许多应用中都取得了比较好的效果,但是其模型的训练却缺乏坚实的理论基础,针对特定问题需要多少层的神经网络,每层网络需要多少个神经元,都只有一些经验方法,因此应参考相关经验进行实验,根据模型的分类效果调整参数,逐步确定较优的模型参数。
4.3 神威太湖之光上的实现
我们在神威太湖之光超级计算机上实现了基于深度学习的性能问题分类模型,使用R[15]作为编程语言,R语言对统计计算和作图方面有很好的支持,近几年在数据挖掘、大数据等领域有广泛的应用。在实现过程中,我们使用了R语言的cluster[16]库(版本2.0.5)和deepnet[17]库(版本0.2)进行编程。

Figure 5 Radar figure of the performance data图5 性能数据雷达图
4.3.1 性能指标和数据
神威太湖之光是一个基于国产申威众核处理器的异构平台,目前提供了作业级性能监测工具、性能分析API等性能分析支持,能够采集作业和指定代码段的PMU数据。通过PMU获取的数据可被单位化成8个指标协助用户进行性能分析,如表1所示。
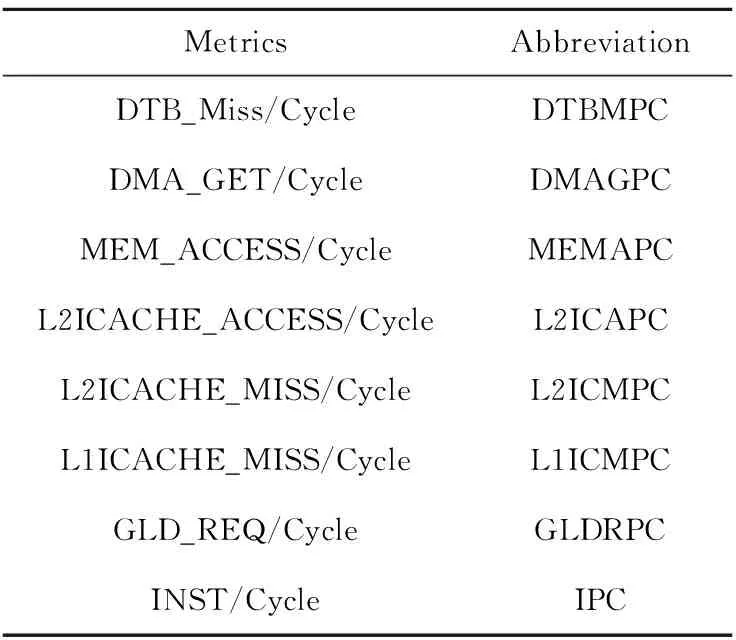
Table 1 Metrics and their abbreviations表1 性能指标及其简写
当前通过该工具已经产生了大量的PMU数据样本,这些数据是许多用户的课题多次运行时产生的,包含了应用优化过程中不同版本的性能数据,有较好的随机性和代表性。经过人工分析,认为这8个性能指标已经能够识别出现频繁的几类性能问题,采用这8个性能指标作为模型训练的输入是可行的。
4.3.2 性能问题类别
我们随机抽取500条原始的性能数据用雷达图表示,如图5所示,各指标数值进行了取对数处理。其中每个小图代表一条性能数据,任意选取其中一个小图观察,均可以发现其他相似度很高的小图,说明性能数据中存在一定的规律,可以使用聚类技术来确定其中的簇,给出性能问题的类别。
基于差距统计标准评估簇数,结果如图6所示,横坐标表示簇的个数,纵坐标表示差距统计值,最优结果为第一个差距统计值大于0的簇个数。实验结果表明,将数据划分为6个性能问题类别是最理想的。
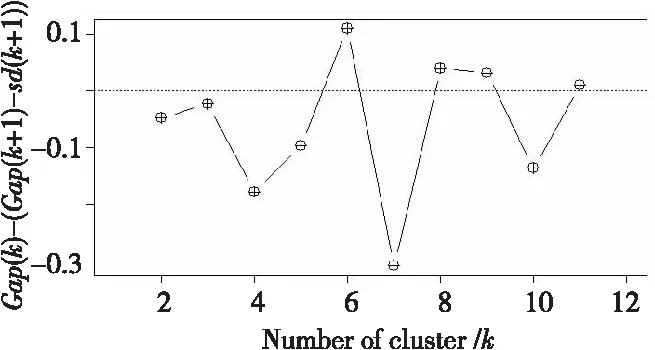
Figure 6 Gap statistics图6 差距统计结果
使用cluster库中clara[16]方法将性能数据聚为6类,其中的输入训练数据均为通过均值和方差标准化后的数据,负值表明数据相对较小,对其簇内典型数据进行分析,结果如图7所示,其中纵坐标的含义见表1。

Figure 7 Various metric values of the typical representation of the cluster of 6图7 簇数为6时簇内典型代表的各指标情况
第1个簇的IPC较大,并且其他指标均较小,说明该簇代表各方面的性能均衡,没有明显的性能瓶颈;第3个簇虽然各个指标也均较小,但其IPC较小,表明程序性能差但不是由于所选取的这些指标导致的,为其他类型,可以进一步优化指令序列提高IPC;第4个簇的DTBMPC指标明显偏大,说明DTB Miss对程序性能的影响很大;第6个簇的MEMAPC指标明显偏大,说明需要重点优化访存行为;第2个簇可发现其DMAGPC值偏大,说明DMA比较碎,可以尝试减少DMA次数,比如数据打包优化;第5个簇综合ICache的指标可发现其L2ICMPC大但是L2ICAPC却小,也就是说其L2ICache的Miss率较高。
根据上述分析结果,可以将神威太湖之光上的性能问题分为6类,如表2所示。
4.3.3 训练性能问题分类模型
深度学习总会在拟合上出现问题,只是程度不同而已:若训练集比验证集的分类正确率更高,表明可能出现了过拟合;若两个分类正确率都很低,表明可能出现了欠拟合。正则化是遏制过拟合训练数据的有效方法,最热门的正则化技术是dropout,它在训练期间随机跳过神经元,并强迫层内其他算法重拾这些神经元,简单而有效。对欠拟合问题,可以通过增加参数搜索网格的容量并进行更多、更长的训练调整。当模型性能长时间得不到提升时,结束当前学习,防止过学习的问题。

Table 2 Categories and description of performance problems表2 性能问题类别及描述
在预训练阶段,我们直接使用15 000个有效作业的性能数据,每个作业包含若干进程,每个进程的性能数据可以作为一条输入。在该阶段,从中抽取了10万条无标签性能数据样本作为预训练集。初步训练使用较少的迭代次数,确定网络层数和每个隐含层内的节点数,如图8所示,可见隐含层数为3、每个隐含层节点数为30时能获得较好的分类性能。
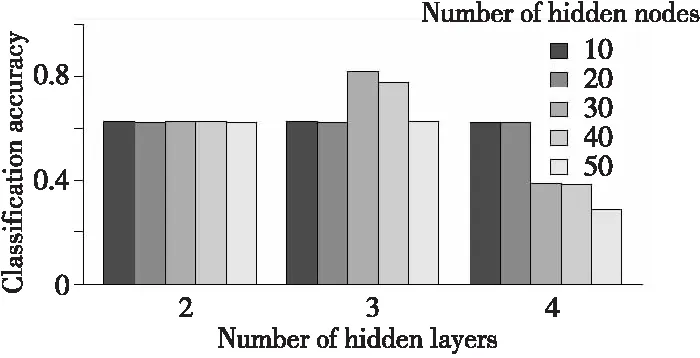
Figure 8 Effect of the number of hidden layers and nodes on classification accuracy图8 隐含层数和隐层节点数对分类正确率的影响
在微调阶段,选取其中部分数据根据体系结构和性能调优的经验知识打上分类标签生成的1 000个微调样本,对训练的成果进行微调,通过反复迭代进行模型优化,模型在测试集上的分类正确率不断提升,目前已到达了94%(与标签数据对比),每当有提升时记录其分类正确率。如图9所示,可见所训练的模型能够以较高的正确率识别出性能问题。
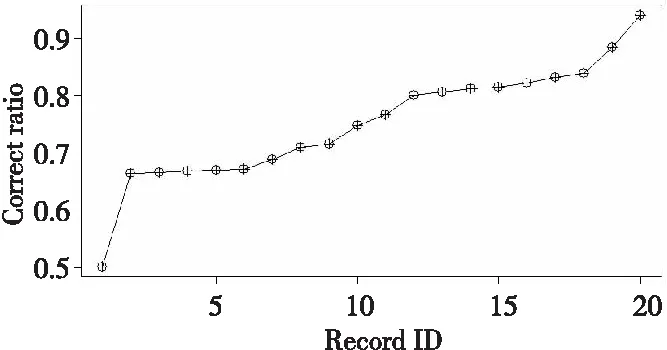
Figure 9 Changes in classification accuracy of the iterative model图9 迭代模型分类正确率变化图
本文提出的性能分析框架可以实现作业级和指定程序代码级的性能智能分析。作业级的性能分析通过集成作业管理部分功能,可实现透明的作业级性能数据采集和智能分析;指定程序代码级的性能分析通过在代码段的开始和结束位置插入性能API接口,由框架实现该代码段性能数据的采集和智能分析。相比于传统的性能分析工具,该框架能够直观地给出作业或代码段最主要的性能瓶颈问题,降低复杂系统性能调优的门槛,提高程序优化的进度。
5 实验结果与分析
为了验证基于深度学习的性能分析框架的正确性和有效性,我们利用国家超算无锡中心的神威太湖之光超级计算机系统进行了测试。神威太湖之光每个节点由一颗申威众核处理器构成(260核,1.45 GHz),配备32 GB内存,运行Linux操作系统,节点间采用56 Gbps的Infiniband FDR网络连接。测试中,最大使用了神威太湖之光计算机系统1 024 CPU的计算资源。
(1)FDTD课题。
FDTD课题是电磁领域的典型应用,采用时域有限差分方法求解麦克斯韦方程。课题采用高阶差分方法,基于区域分解并行,每个迭代步完成边缘通信和计算。
FDTD课题的分析过程和效果如表3所示。

Table 3 Analysis process of FDTD表3 FDTD分析过程和效果
采集的数据经模型分析输出为Mem类问题,程序员将课题中主要的三个只读的数组拷贝到片上高速存储器进行优化,性能提升45%;再次分析后显示为Mem类问题,程序员发现还有另外两个变量未利用片上高速存储器进行优化;优化后再次分析结果为Balance,至此核心段性能提升约711%。
(2)微孔道扩散过程MD模拟课题。
该课题是分子动力学应用,计算分子之间相互作用力。核心计算采用区域分解的方式,在计算过程中交换重叠边界上数据信息。
MD课题的分析过程和效果如表4所示。采集的数据经模型分析输出为Mem类问题,程序员将课题中的多个临时变量声明为局部变量,性能提升34%;再次分析显示依然为Mem类问题,程序员将其中多个数组拷贝片上高速存储器进行优化,性能提升73%;再次分析还是为Mem类问题,程序员发现拷贝数据方式不是最优,对数据进行动态拷贝优化;再次分析结果为Balance,至此核心段性能提升约218%。
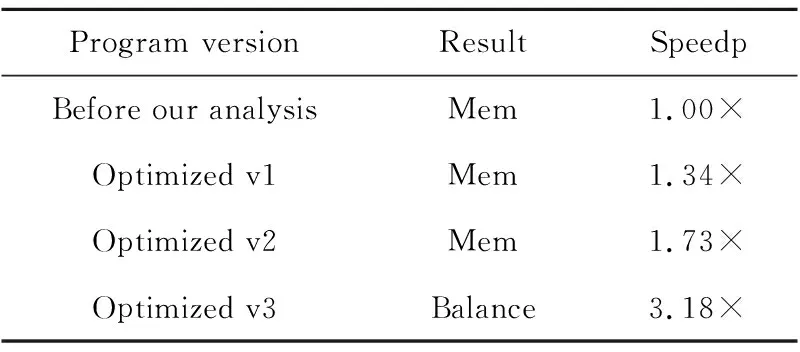
Table 4 Analysis process of MD表4 MD分析过程和效果
(3)解有限域上某类线性方程组。
课题的核心计算为一个次数达百万级别的并行循环,单次循环内主要完成如下工作:首先根据循环迭代变量的位置和原始数据构造一个线性方程组,然后求解该线性方程组并保留部分有价值的数据,其中构造线性方程组的过程存在数量众多的大跨度离散写操作。
如表5所示,核心段某版本,经分析为DTB类问题,程序员将其中数据进行排序优化;再次分析结果为Balance,至此核心段性能提升约67%。
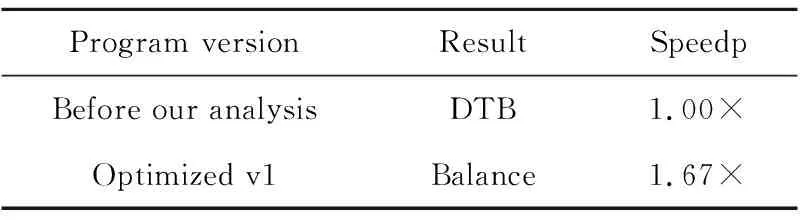
Table 5 Analysis process of solving equation表5 解某方程核心段分析过程
(4)CESM课题MICRO_MSG核心段。
CESM是地球系统模式应用课题,MICRO_MSG是重要的核心段,包含复杂的函数调用关系。
micro_mg核心段的分析过程和效果如表6所示。采集的数据经模型分析输出为ICache类问题,程序员根据核心段调用关系对函数顺序进行重排优化;再次分析结果为Balance,核心段性能提升约230%。

Table 6 Analysis process of micro_mg表6 micro_mg核心段分析过程
6 结束语
本文提出了一种基于深度学习的性能分析方法和框架。基于深度学习的性能分析方法使用簇评估和稀疏编码深度学习技术,在大量性能监测数据训练的基础上,将程序性能问题分为若干类,并给出优化方向性建议。我们在神威太湖之光上实现了程序性能分析框架的原型,能够根据性能监测数据,直观地指导程序员快速把握当前应用最为突出的性能瓶颈问题,在当前性能瓶颈解决后可进一步迭代,直到取得满意的性能结果。实验结果表明,该性能分析框架能有效提高应用优化的效率,降低用户调优代码的成本。
本文研究工作中得到了国家超算无锡中心的大力支持和无私帮助,在此表示衷心的感谢。基于深度学习的性能分析方法可以推广到其它多核和众核系统。下一步我们将继续完善和优化该方法和实现,采集更多的数据进行训练,进一步提高判断的准确性,为更多的应用提供智能化的性能优化服务。
[1] Yoo W,Larson K,Baugh L,et al.Adp:Automated diagnosis of performance pathologies using hardware events[C]∥Proc of the 12th ACM Sigmetrics/Performance,2012:283-294.
[2] Fu H,Liao J,Yang J,et al.The Sunway Taihulight supercomputer:System and applications[J].Science in China Series F:Information Sciences,2016,59(7):072001.
[3] FPMPI Team. Fast profiling library for MPI[EB/OL].[2017-11-28].http:∥www.mcs.anl.gov/research/projects/fpmpi/WWW/index.html.
[4] Chris C,Jeffery V.Mpip:Lightweight,Scalable MPI profiling[EB/OL].[2017-08-30].http:∥mpip.sourceforge.net.
[5] PAPI Team.PAPI[EB/OL].[2017-08-06].http:∥icl.cs.utk.edu/papi.
[6] Popescu M,Hotrabhsvananda B,Moore M.VAMPIR:An automatic fall detection system using a vertical PIR sensor array[C]∥Proc of International Conference on Pervasive Computing,2012:163-166.
[7] Scalasca Team.Cube 4.x series[EB/OL].[2017-04-15].http:∥www.scalasca.org/software/cube-4.x/download.html.
[8] Intel Corporation. Intel vtune amplifier 2017[EB/OL].[2017-09-08].https:∥software.intel.com/en-us/intel-vtune-amplifier-xe.
[9] Scalasca Team.Scalasca[EB/OL].[2017-11-28].http:∥www.scalasca.org.
[10] Adhianto L,Banerjee S,Fagan M,et al.Hpctoolkit tools for performance analysis of optimized parallel programs[J].Concurrency and Computation:Practice and Experience,2010,22(6):685-701.
[11] Malony A D,Shende S.The TAU parallel performance system[J].International Journal of High Performance Computing Application,2006,20(2):287-311.
[12] Urlinger K,Gerndt M,Kereku E.Periscope:Advanced techniques for performance analysis[C]∥Proc of Parallel Computing:Current & Future Issuesof High-End Computing,2005:15-26.
[13] Yu Kai, Jia Lei,Chen Yu-qiang.Deep learning:Yesterday,today,and tomorrow[J].Journal of Computer Research and Development,2013,50(9):1799-1804.(in Chinese)
[14] Broberg P,Kohl M,Harrington J.Gap statistic for estimating the number of clusters[EB/OL].[2017-03-01].http:∥cran.r-project.org/web/packages/clusGap/index.html.
[15] R Development Core Team.The R project for statistical computing[EB/OL].[2017-03-24].http:∥www.r-project.org.
[16] Maechler M, Rousseeuw P, Struyf A. Cluster:Finding groups in data[EB/OL].[2017-03-02].http:∥cran.r-project.org/web/packages/cluster/index.html.
[17] Xiao R.Deep learning toolkit in R[EB/OL].[2017-03-02].http:∥cran.r-project.org/web/packages/deepnet/index.html.
附中文参考文献:
[13] 余凯,贾磊,陈雨强.深度学习的昨天,今天和明天[J].计算机研究与发展,2013,50(9):1799-1804.
