一种面向识别的无监督特征学习算法*
2018-07-05夏海蛟谭毅华
夏海蛟,谭毅华
(1.华中科技大学自动化学院,湖北 武汉 430074;2.多谱信息处理技术国家级重点实验室,湖北 武汉 430074)
1 引言
近年来,随着深度人工神经网络在模式识别和机器学习领域的众多比赛中获得成功[1,2],其无监督特征提取的能力受到广泛关注。深度学习在目标和行为识别中出现新进展[3],在目标检测、图像分割和视频跟踪等任务中涌现出大量的模型,其网络结构的层数越来越多,相应的实验性能也更优越[4,5],相当多的研究专注深度学习的加速及其应用。目前,深度学习在国内受到学术界和工业界的广泛重视[6]。然而,深度网络的训练和参数调整是技巧性的工作[7],需要大量的样本,而且随着深度的增加,模型复杂度的提高,应用模型提取特征和识别时的计算复杂度也很高,这在一定程度上影响了深度学习在一些对速度要求很高或有标记数据有限的应用场合中的推广。
深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,层层逼近,以发现数据的分布式特征表示。文献[8]中,Bengio等人介绍,有人为深度置信网(Deep Belief Net)引入贪心逐层无监督学习算法,认为深度结构相比浅层结构和单隐含层神经网络更有效。Hinton[9]指出,高维数据通过训练多层神经网络转换成低维编码以重建高维输入向量,提出梯度下降法,微调自编码网络(Autoencoder)的权重,从而为深度网络的构建建立了可行性基础。文献[10]认为池化能实现图像转换的不变性、更加紧凑的表达和对噪声和杂乱更好的鲁棒性。同时,应用池化的CNN(Convolutional Neural Network)在ImageNet分类任务上的效果非常成功,大量的图像识别方案均基于此框架构建[2]。目前的特征学习算法要求谨慎地选择多个超参数,如学习速率、动力、稀疏惩罚和权重衰减等等,这为构建理想的特征抽取网络带来了困难[7]。文献[7,11]发现,当选择K-means聚类算法形成视觉词典后,从无标签数据中提取特征,在多个数据集下测试,结果表明,其识别准确率胜过采用高斯混合模型GMM(Gaussian Mixture Model)、稀疏自编码(Sparse Autoencoder)和稀疏受限玻尔兹曼机(Sparse Restricted Boltzmann Machine)等方法。因此,聚类算法作为学习无监督特征的基础具有一定的价值。
文献[12]发现,对基于视觉词典抽取的特征,进一步使用一个好的前馈非线性编码器进行编码,比将更多的资源用在训练上能取得更好的效果。这也给出了提示,选择更好的编码器有助于提升无监督特征学习的性能。文献[13]也提出单个独立单元处理具有局限性,多个局部空间的组合包含神经网络中高层的语义信息。这也是K-means聚类后可以取得较好的特征表达的原因,但这种空间信息的利用仍然存在一定的冗余。文献[14]利用正交匹配追踪OMP(Orthogonal Matching Pursuit)算法在分解的每一步对所选择的全部原子进行正交化处理,使得在精度要求相同的情况下,OMP算法的收敛速度更快,是一种十分有效的去除冗余的方法。
综合上述思想、问题和方法的优缺点,特征挖掘的层次化问题并未给出详细的讨论。因此,在文献[9]的基础上,本文通过引入OMP算法和采用有效的编码器来提升单层网络的网络性能。另外,利用K-means算法简单快速的特点,构造用于抽取多级特征的视觉词典,形成与输入图像进行卷积的滤波器集合,然后在抽取的第一级特征上进行平均值池化操作,实现特征降维,同时使特征具备图像变换的不变性。接着,在第一级特征的基础上,抽取第二级的特征,进行空间金字塔池化操作[15],放入2范数软间隔支撑向量机L2-SVM分类器中,训练出分类器参数;采用交叉验证的方式,识别测试样本。
2 无监督特征学习
无监督特征学习的一般流程是:先从一组无标签数据中学习视觉词典,然后用学习到的视觉词典提取数据的特征。K-means无监督特征学习,就是利用K-means聚类算法从大量的无标签样本中学习出视觉词典,然后提取特征。
2.1 基于K-means聚类的特征学习
在大量的图像块上,采用K-means聚类算法生成视觉词典,选择性地采用OMP算法对生成的视觉词典正交化,然后权值编码,得到图像的特征,如图1所示。

Figure 1 Feature extraction图1 特征提取
2.2 OMP算法
为了减少空间信息的冗余,将K-means生成的视觉词典作为初值,放入OMP算法[12]中,对视觉词典进行正交化。正交化前和正交化后的视觉词典如图2所示。

Figure 2 Visual dictionary图2 视觉词典
2.3 编码器
得到视觉词典后,进而提取样本特征,即图1的权值编码过程。这里考虑两种编码器:软编码器[7]和软阈值编码器[12]。
在软编码器的权值编码过程中,权值向量z由图像块x到每个视觉单词的投影构成,每个权值系数zk的计算过程如式(1)所示。
zk=‖x-D(k)‖2
(1)
其中,zk表示权值向量z的第k个元素,D(k)表示视觉词典的第k个视觉单词。
文献[12]表明,对权值向量进一步使用式(2)的变换可增强特征的辨识表达能力。
fk=max{0,μ(z)-zk}
(2)
其中,μ(z)表示权值向量z中所有元素的平均值,fk、zk表示特征向量f和权值向量z中的第k个元素。通过式(2),特征向量中约一半的元素置为0,保证了特征向量的稀疏性。
而软阈值编码器如式(3)所示。
fj=max{0,D(j)Tx-α}
fj+d=max{0,-D(j)Tx-α}
(3)
其中,D(j)表示视觉词典中的第j个视觉单词,d表示视觉词典中视觉单词的个数,α为固定阈值,fj和fj+d分别表示特征向量f的第j维和第j+d维元素。
3 单级计算结构识别方法
3.1 图像特征抽取的单级计算结构
首先,对图像预处理后,学习出视觉词典。训练阶段,提取特征并池化,经过数据标准化后,得到特征矢量。单级计算结构模型见图3。相比于文献[7],在单级计算结构的编码过程中,采用软阈值编码器代替软编码器。
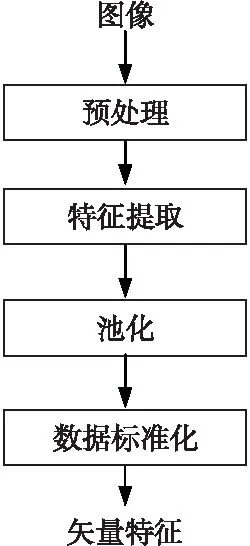
Figure 3 Single-stage computational structure图3 单级计算结构
3.2 预处理
学习时,将向量还原成原始大小的图像,随机选取感受野大小的图像块。在所有图像上循环采集,直到达到期望数量t。每个图像块为属于RN空间的向量,其中N=w×w×k,k为图像的通道数。构造一个含t个图像块的数据集,X={x(1),…,x(t)},这里x(i)∈RN,i为图像块的编号。
为了增强每张图像的亮度和对比度,在白化之前,先对每个图像块进行亮度和对比度的归一化。如式(4)所示,每个图像块x(i)上每个像素的灰度值,减去灰度的均值,然后除以标准差。另外,为了避免分母为0和抑制噪声,给方差增加一个小的常数。对于[0,255]的灰度图,一般给方差加10。
(4)
其中,mean(x(i))表示图像块灰度的均值,var(x(i))表示图像块的方差。
因为K-means趋向于学习低频类边缘的特征[7],但是由于邻域像素的相关性会很强,而不是分散开聚类中心以更均匀地展开数据,因而这样的特征不会有很好的识别效果。因此,先用白化来去除数据的相关性,以驱使K-means在正交方向上分配更多的聚类中心。
实现白化的一个比较简单的方法是ZCA(Zero-phase Component Analysis)白化。先计算数据点的均值,对数据点的协方差矩阵进行特征值分解,然后对数据点进行白化。计算公式如下:
(5)

3.3 映射方式及特征表示
使用视觉词典将N维的图像块映射到K维空间。对于一个n×n×d的图像,采用大小为ω×ω,步长为s的滑动窗,计算滑动过程中每个子块的特征,生成((n-ω)/s+1)×((n-ω)/s+1) ×K的特征图。
3.4 池化
为了获得局部旋转和平移的不变性,同时降低特征维数,对第一级特征图,使用大小为p×p,步长为s的平均值池化(如图4所示),平均值池化公式如下:

avg(i:s:i+p-1,j:s:j+p-1,:)
(6)
其中,i表示行坐标,j表示列坐标。
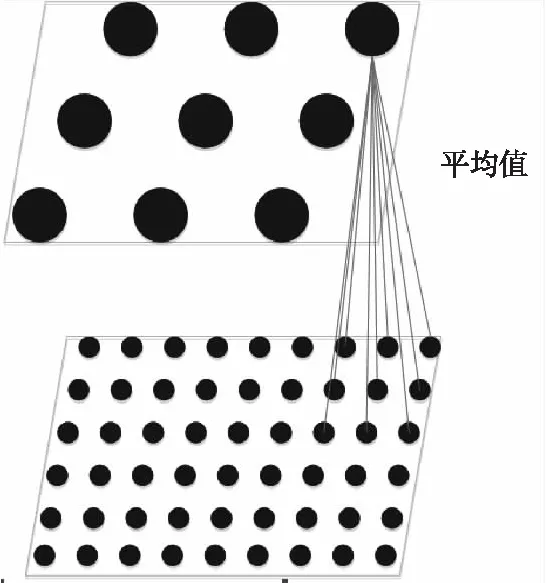
Figure 4 Average pooling图4 平均值池化
对第二级特征图,进行尺度为[1,2,3]的空间金字塔最大值池化,即将特征图分别等分成1份、4份和9份(如图5所示),每份取最大值拼接起来,作为特征图的最终表达,计算过程如式(7)所示。

Figure 5 Partitions of the feature map图5 特征图分块
(7)
其中,C={C1,C2,…,C13,C14},C1表示一张特征图,C2,C3,C4,C5表示特征图分成4等份,C6,C7,…,C13,C14表示特征图平均分成9等份。
3.5 数据标准化
在每一级结束之前,先将数据标准化。数据标准化类似于亮度和对比度归一化,只是数据标准化针对矩阵中图像的每一维做操作,标准化过程如式(8)所示。
(8)
其中,X为特征矩阵,mean(X)为特征矩阵的列均值,var(X)为特征矩阵的方差。为避免分母为0,给标准差加一个常数0.01。
3.6 L2-SVM分类
数据标准化后,随同正确标记的标签,进入L2-SVM分类器训练,得到分类器参数。
4 图像特征抽取的两级计算结构
在图像上利用图3所示的单级计算结构进行第一级提取,提取出的特征作为输入进行第二级提取,然后用提取出来的特征矢量训练L2-SVM分类器,得出图像的分类结果,计算识别率。
构建的两级计算结构在第一级中采用平均值池化,第二级采用空间金字塔池化,在结构上不同于先前K-means构建的结构。两级计算结构如图6所示,两级计算结构的视觉词典如图7所示。

Figure 6 Two-stage computational structure图6 两级计算结构

Figure 7 Two-stage visual dictionary图7 两级视觉词典
构建两级计算结构的难点在于,在大样本数据集上,第一级的特征图通道数多,图像块维数高,计算量大,第二级的特征图通道数多,输出特征矢量维数高,对计算机硬件有要求。以两级模型为例,大样本数据集中包含50 000幅图像,第一级特征图通道数为200个,第二级中图像块维数为7 200维,第二级输出特征图通道数为800,特征矢量为11 200维,矩阵大小为50000×11200,对计算机内存有一定的要求,内存至少需要8 GB,在大样本数据集上应用存在困难,因此建立自选数据集进行测试。
5 实验及结果
5.1 数据来源
5.1.1 自选数据集
数据集中部分图像来自谷歌地图,部分来自航空图像。在同一场景抠取1 000个建筑物、1 000个非建筑物作为学习和训练的数据集,截取481个建筑物和481个非建筑物作为测试数据集。为了检验网络的泛化能力,在不同场景截取230个建筑物和230个非建筑物。部分样本如图8所示,图8中建筑物和非建筑物图像各20个,前两行为建筑物,后两行为非建筑物。

Figure 8 Building and non-building samples图8 建筑物和非建筑物样本
5.1.2 CIFAR-10[16]
CIFAR-10数据集由60 000幅大小为32×32的彩色图像组成,分成10类,每类6 000幅,有50 000幅训练图像和10 000幅测试图像。数据集分成5个训练批次和1个测试批次,每个批次含10 000幅图像。测试批次在每一类中随机选取1 000幅,训练批次以随机的次序包含余下的图像,但是有些训练批次中,一类包含的图像多过另一类。训练批次在每一类上包含5 000幅图像。
图9是数据集中图像的类别,每一类随机选取10幅。

Figure 9 Classes and randomly-selected samples图9 类别和随机样本
5.1.3 VOC2012[17]
VOC2012数据集由含8 331幅彩色图像的训练集和含8 351幅彩色图像的测试集组成。训练集包含15 002个样本,测试集包含15 092个样本。所有的样本分成20类,每类包含的图像数目各不相同。图10是数据集中图像的类别和样本。

Figure 10 Classes and samples图10 类别和样本
5.2 评价指标
将分类出来的标签与正确的标签做比较,然后用总数减去不正确的标签数目后除以总数,得到正确的识别率,作为评价指标,如式(9)所示。
(9)
其中,Acc表示准确率,T表示正确分类的标签数,F表示错误分类的标签数。
在自选数据集上,除了正确的识别率外,另加上精度作为评价指标。如式(10)和式(11)所示,精度是被分为正确的建筑物(或非建筑物)个数占建筑物(或非建筑物)总数的比例。
(10)
(11)
其中,PreT为建筑物精度,PreN为非建筑物精度,TP表示建筑物正确分类的数目,FP表示建筑物错误分类的数目,TN表示非建筑物正确分类的数目,FN表示非建筑物错误分类的数目。
5.3 结构细节
实验平台硬件处理器为Intel(R) Core(TM) i5-6400 CPU @ 2.71 GHz,内存为8.00 GB。实验在CIFAR-10、自选数据集和VOC2012上分别进行。
5.3.1 CIFAR-10
单级计算结构在32×32大小的三通道自然图像上,采集400 000个大小为6×6的感受野图像块,经过预处理后,使用K-means算法学习出含有1 600个视觉单词的视觉词典。
在训练图像上,同样使用6×6大小,步长为1的滑动窗采样,经过预处理后,进行软编码,将108维空间映射到1 600维空间中,将映射后大小为27×27×1600的特征图分成四个象限,对每个象限求和得到6 400维的特征。将50 000幅图像放入L2-SVM分类器中训练,得到分类器参数。最后,用10 000幅图像测试。
为了检验不同的编码对实验效果的影响,采用软阈值编码代替软编码,得到新的测试效果。
将视觉词典理解为以视觉单词为基的空间,那么将空间正交化能提高特征表达的准确性,而K-means算法采用的是统计学原理,并不能保证基空间的正交性。因此,在运用K-means算法后,以K-means算法结果作为初值,再进行OMP运算,形成新的K-O结构,得到一组实验结果。
同时,为了分析实验效果的优劣,算法与稀疏编码SC(Sparse Coding)算法[12]以及当前热门的CNN算法进行比较。利用卷积神经网络工作台CNNWB(Convolutional Neural Network Work Bench)代码,得到一组数据,如表1所示,最后的数据结果表明,使用软编码器的结构,准确率为77.35%,而使用软阈值编码器的结构,准确率达到78.69%,加上OMP后,准确率上升到79.25%,高于SC算法和CNN算法的分类准确率,但是低于NIN网络的分类准确率。表1中Triangle代表软编码,T代表软阈值编码。
5.3.2 自选数据集
将图像归一化成大小为32×32的三通道图像,第一级采集400 000个大小为6×6的图像块,预处理后,学习出含100个视觉单词的视觉词典。训练数据使用软阈值编码得到大小为27×27×200的特征图,采用大小为3×3,步长为3的局部平均值池化,得到9×9×200的特征图,数据标准化后得到第一级输出,作为第二级的输入。在第二级计算时,感受野大小不变,采集100 000个图像块,学习出含400个视觉单词的视觉词典,使用软阈值编码器进行第二级卷积特征提取,得出的特征图大小为4×4×800,进行尺度为[1,2,3]的空间金字塔最大值池化,得到14×800=11200维的向量,数据标准化后进入线性分类器L2-SVM训练。测试阶段,进行两级特征提取,使用L2-SVM分类器分类,采用正确的识别率和精度作为评价指标。

Table 1 Recognition results of CIFAR-10表1 CIFAR-10上的识别率
为了检验效果,分别采用软编码器和软阈值编码器,将数据集用于K-means、OMP、 SC、K-O、随机采集图像块方法RP(Random Patches)[12]、K-means与OMP视觉词典合并的网络、K-means与OMP的并行网络上,得到各自正确的识别率。另外,在MatConvNet[19]平台上,将Lenet[20]和NIN[18]网络应用于数据集上,得到两组正确的识别率。实验结果如表2和表3所示,其中Triangle代表软编码,T代表软阈值编码。
如表2所示,在同一场景下,K-means-2layers(T)结构的识别率为97.82%,与单级计算结构K-means(T)相当,高于其他大多数的结构;在不同场景下,K-means-2layers(T)结构的识别率为90.43%,高于单级计算结构的88.70%,仅低于RP(Triangle)结构和SC(Triangle)结构,但高于同样采用T编码器的RP(T)和SC(T)结构,表现出较好的泛化能力;在混合场景下,K-means-2layers(T)结构的识别率为95.43%,高于多数结构。在三种情形下,两级计算结构的识别率高于Lenet结构和NIN结构的。
如表3所示,在同一场景下,建筑物与非建筑物的识别精度相当;在不同场景下,非建筑物的识别精度高达99.57%,明显高于建筑物的识别精度;最终,非建筑物的识别精度在混合场景下高于建筑物的识别精度。

Table 2 Recognition results of self-selection dataset表2 自选数据集识别率
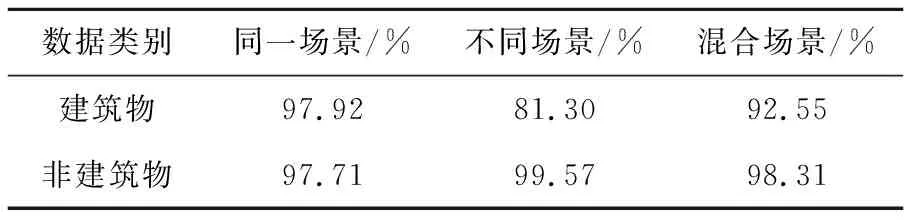
Table 3 Precision results of self-selection dataset表3 自选数据集精度
深度学习网络的识别率在中等数据集上未能表现出明显优势原因可能是:数据集规模不够,导致网络无法充分地收敛。训练参数如表4所示,表中学习率前30次为0.5,到40次为0.1,最后5次为0.02。
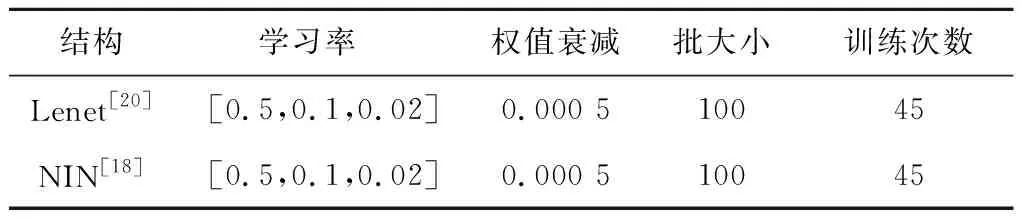
Table 4 Training parameters of deep learning表4 深度学习训练参数
5.3.3 VOC2012[17]
K-means单级计算结构在15 002个样本上进行训练,然后在15 092个样本上测试,得出准确率。同时,将单级计算结构中的软阈值编码代替软编码,得到新的结果。另外,将K-mean单级计算结构与K-O结构、SC算法、Lenet算法和NIN算法进行比较,结果如表5所示。
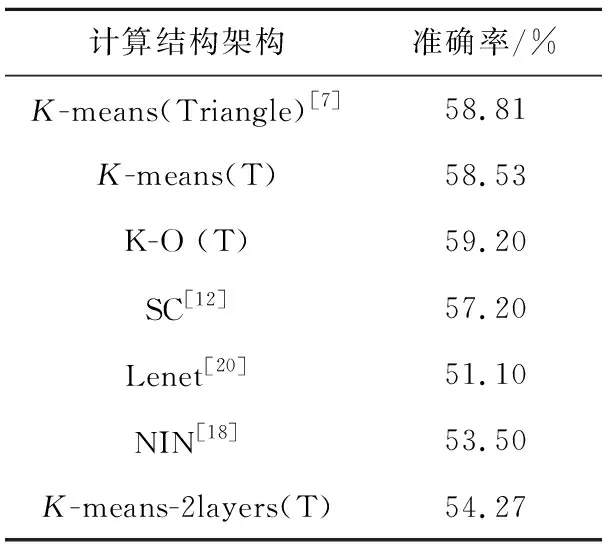
Table 5 Recognition results of VOC2012表5 VOC2012结果
由表5可以看出,对于VOC2012数据集来说,单级计算结构更换编码器对准确率影响不大,但是加入OMP算法后网络准确率由58.81%上升到59.20%,高于Lenet和NIN结构。
VOC2012数据集上两级计算结构的平均准确率超过Lenet和NIN结构,但未能超过单级计算结构的原因是:在视觉词典原子数目固定的情况下,样本数目的缺少,使得采样空间不能充分地表达图像,导致平均准确率下降。
6 结束语
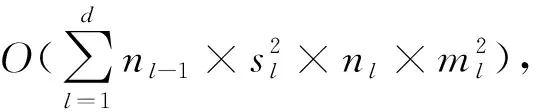
[1] Schmidhuber J. Deep learning in neural networks:An overview[J].Neural Networks,2015,61:85-117.
[2] Krizhevsky A,Sutskever I,Hinton G E.Imagenet classification with deep convolutional neural networks[C]∥Proc of Advances in Neural Information Processing Systems,2012:1097-1105.
[3] Zheng Yin,Chen Quan-qi,Zhang Yu-jin.Deep learning and its new progress in object and behavior recognition [J].Journal of Image and Graphics,2014,19(2):175-184.(in Chinese)
[4] Szegedy C, Liu W,Jia Y,et al.Going deeper with convolutions[C]∥Proc of the IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
[5] He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[C]∥Proc of the IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778.
[6] Yu Kai,Jia Lei,Chen Yu-qiang,et al.Deep learning:Yesterday,today,and tomorrow [J].Journal of Computer Research and Development,2013,50(9):1799-1804.(in Chinese)
[7] Coates A,Ng A Y.Learning feature representations withk-means[M]∥Neural Networks:Tricks of the Trade.Heidelberg:Springer,2012:561-580.
[8] Bengio Y,Lamblin P,Popovici D,et al.Greedy layer-wise training of deep networks[C]∥Proc of Advances in Neural Information Processing Systems,2007,19:153-160.
[9] Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.
[10] Boureau Y L, Ponce J,LeCun Y.A theoretical analysis of feature pooling in visual recognition[C]∥Proc of the 27th International Conference on Machine Learning (ICML-10),2010:111-118.
[11] Coates A,Lee H,Ng A Y.An analysis of single-layer networks in unsupervised feature learning[C]∥Proc of International Conference on Artificial Intelligence and Statistics, 2011:215-223.
[12] Coates A, Ng A Y. The importance of encoding versus training with sparse coding and vector quantization[C]∥Proc of the 28th International Conference on Machine Learning,2011:921-928.
[13] Szegedy C,Zaremba W,Sutskever I,et al.Intriguing properties of neural networks[C]∥Proc of International Confer-
ence on Learning Representations,2014:6199.
[14] Pati Y C,Rezaiifar R,Krishnaprasad P S.Orthogonal matching pursuit:Recursive function approximation with applications to wavelet decomposition[C]∥Proc of the 27th Annual Asilomar Conference on Signals,Systems and Computers,1993:40-44.
[15] Bo L,Ren X,Fox D.Unsupervised feature learning for RGB-D based object recognition[C]∥Proc of Experimental Robotics,2013:387-402.
[16] Krizhevsky A, Nair V, Hinton G.The CIFAR-10 dataset [DB /OL].[2013-11-14].http://www.cs.toronto.edu/~kriz/cifar.html.
[17] Everingham M,Van Gool L,Williams C K I,et al.The PASCAL visual object classes (VOC) challenge[J].International Journal of Computer Vision,2010,88(2):303-338.
[18] Lin M,Chen Q,Yan S.Network in network[C]∥Proc of International Conference on Learning Representations,2014:4400.
[19] Vedaldi A,Lenc K.Matconvnet:Convolutional neural networks for Matlab[C]∥Proc of the 23rd ACM International Conference on Multimedia,2015:689-692.
[20] LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[21] He K,Sun J.Convolutional neural networks at constrained time cost[C]∥Proc of the IEEE Conference on Computer Vision and Pattern Recognition,2015:5353-5360.
附中文参考文献:
[3] 郑胤,陈权崎,章毓晋.深度学习及其在目标和行为识别中的新进展[J].中国图象图形学报,2014,19(2):175-184.
[6] 余凯,贾磊,陈雨强,等.深度学习的昨天,今天和明天[J].计算机研究与发展,2013,50(9):1799-1804.
