一种异构集成学习的儿科疾病诊断方法研究
2018-07-05霍东雪尚振宏李润鑫昆明理工大学信息工程与自动化学院云南昆明650500
霍东雪 刘 辉 尚振宏 李润鑫(昆明理工大学信息工程与自动化学院 云南 昆明 650500)
0 引 言
由于我国人口众多,城镇化加剧,医疗资源匮乏,每千人所占有的医生比例不足27名。近年来,医患关系日趋紧张,导致医疗纠纷愈演愈烈。
信息技术的迅猛发展为医疗行业带来了新的机会。当前,种类繁多的医疗技术已广泛地应用于药物挖掘、医学影像、医疗诊断等各个领域[1]。随着科学技术的进步,机器学习在医疗诊断领域中的应用将会越来越广泛、越来越重要。机器学习中的集成学习算法则是提高分类器准确率的一种有效途径,已经在很多领域显示出它优于单个分类器的良好性能,不仅仅包括准确率等,同时还体现在其泛化能力上[2]。文献[3-5]中展示分别采用异质或者同质的集成方式达到实验目的,结果表明运用集成学习的策略能够优于单个弱学习算法分类模型。然而,其中有关儿科疾病推理方面的研究却少之又少,因此本文将异构模式的集成学习应用于儿科医疗诊断领域,具体来说,即把医院诊断的每一份病历作为模型输入的一个样本,样本中的特征便来自于病历中的主诉、现病史与体格检查中的内容。对上述内容进行特征提取和数据预处理。样本中的目标疾病会有多个,并且有先后次序的关系,这是因为医生在诊断时往往根据其确定程度对初步诊断的多个疾病进行排序。如果暂不考虑疾病确诊的顺序,就可以将该诊断问题作为机器学习中的多标签分类问题,即每一份病历拥有多类疾病标签。
基于以上思想,本文采用多标签分类的SVM[6]、决策树[7]、逻辑回归[8]和随机森林[9]算法,对于预先分割的训练集与测试集,运用上述模型,分别进行训练,并根据预测的疾病结果,采用模型融合的方法进行集成。实验的结果表明,该方法能够较为准确地预测出小儿患者未知样本的疾病,提高集成模型的预测准确率。
1 Bagging 算法工作原理及流程
1.1 工作原理
Bagging算法于1996年被提出来之后,其正确性以及应用价值得到了迅速的提升,符合集成算法有关数学建模方面的要求,已在很多方面得到了具体而又广泛的应用。其原理一般可以简述为多个函数的线性融合,适用于对某些准确率相对较差的算法的提升。经过该算法的一系列处理之后,往往能够得到一个对准确率有着大幅度提升的新集成学习算法。简而言之,根据一个弱学习算法和指定的训练集(x1,y1),(x2,y2),…,(xr,yr),在符合集合条件的多次训练之后,可以得到对应的函数值的某一序列,最终的评估函数则由以上函数值进行数学上的处理后形成[10]。
弱学习算法是指那些独立的且精度不要求很高的分类算法。Bagging算法首先提高了各个弱分类器融合后的泛化能力。泛化能力体现了分类器对新事物的适应能力,泛化能力越强,其对新事物的适应能力相对就越强,其次提升了模型的准确率等评价指标[11]。由此可见,使用Bagging算法解决儿科疾病诊断问题是一种切之有效的方法。
文中采用Bagging算法中的异构集成学习方法,它是通过融合多个不同类型算法的弱分类器形成。这是因为相异算法本身具有一定的差异性,融合后会导致生成的分类决策边界不同,也就是它们在决策时会犯不一样的错误,将其融合后往往能够得到更加清晰的边界,从而可以减少整体的分类错误,实现更好的预测结果。
1.2 模型融合算法
模型融合是指集成模型最终的预测结果由训练的N个不同算法模型共同决策,并按照某种原则直至达到最佳的预测效果。其一般思路是在N组结果值中,穿插有不同算法的预测结果,这就确保了结果的多样性。此种方式是将不同算法的结果进行融合,因为不同算法的结果着眼点不同,能够满足多标签分类中真实的多个结果。
在多标签分类中,对于其样本所有类标签,示例如y1,y2,…,yt,其中t为类标签个数,在测试集的各组预测结果中,首先对N个算法模型进行分类,判断哪些模型对某一类预测较为准确,表示其更能较好地学习到某一类所属的特征,从而建立模型与类之间一对多的映射关系。如果与真实结果相比,该模型有一半以上的数量都能准确地预测出某一类,则把它称为该类的可信模型。对于一份未知病历所对应的特征集,如果能够找到某一类疾病由其可信模型预测得到,说明该特征集有极大可能所属某一类疾病,那么就把该类疾病添加到最终的预测结果中。反之,对于某些暂无可信模型的类别,或只出现一次的类别,表明算法中的N个模型都较少地学习到该类与特征之间对应的映射关系,就暂按多数原则进行选取。
1.3 算法流程

在本文中,首先采用“自助采样”的方法,其次利用模型融合的算法,以此对SVM、决策树、逻辑回归和随机森林算法进行分类,使其迭代产生对每个类别的可信模型,随后选取最终的模型结果。具体描述,如图1所示。

图1 异构集成学习算法的流程示意图
(1) 输入样本训练数据集;
(2) 训练N个相异算法的多标签分类模型(N≥2);
(3) 在所有测试样本中,针对N个模型预测结果的0/1多维行向量,分别与真实结果作对比,取得包含多个类别的可信模型;
(4) 对于测试集,如果能够找到某一类别由其可信模型预测得到,那么就把该类疾病加入到最终的预测结果中,最后分别对比模型的准确率、召回率与F1值。
2 集成学习训练模型构造
2.1 数据分析与样本集构造
本文收集了某三甲医院儿科患者的病历样本,病历的元组样式如图2所示。

图2 病历样本展示
文中采集到样本总量为1 990份病例,采用特征提取算法从所有病历样本中提取到儿科相关的161类病症(如腹痛、呕吐、腹泻、发热等)和其对应的77类疾病(如呼吸道感染、气管炎、急性扁桃体炎、发热等)的序列,发热、咳嗽等既属于病症又属于疾病。随后针对每一份病历,采取数据预处理操作,对于病症和疾病序列,分别生成161维特征向量和其对应的77维目标向量。其中,如果该病历中存在该病症即为1,否则为0。同样地,该病例中存在该疾病即为1,否则为0。
由于是对某医院近半年的儿科患者病历样本的采集,提取到的各个类别数量可能有所差异,所以会出现样本分布不均衡的现象。表1为从总体样本中任意抽取某20例标签的分布,其中化脓性腮腺炎、咯血等只出现一例,而支气管肺炎、急性扁桃体炎等则出现多次。因此,为了使训练集和测试集中的数据分布均衡,采用Bagging中的“自助法”(bootstrapping)方案对样本进行划分。

表1 总体中的部分样本分布
2.2 训练与预测模型构造
由于样本数据集属于多标签分类问题,因此采用scikit-learn工具包中处理多标签分类的One-VS-the-Rest策略[13]。
One-VS-the-Rest策略最初是为了解决多分类问题,对于训练集中的每一个类别训练一个二分类模型,如果有t个类别,则训练t个二分类模型。预测时,对每一个二分类模型预测一个类别。因此,对于一个未知样本,则需要用以上t个二分类模型全部进行预测,从而得出结果。
同样地,多标签分类也可以用以上思想实现,如果有t个类别,则对每一类标签训练一个二分类模型。预测时,分别使用以上t个二分类模型进行预测。
根据上述思想,本文采用不同算法策略,利用One-VS-the-Rest策略训练N个多标签分类模型,随后采取模型融合策略,根据样本真实值与各个分类器预测结果的误差,对分类器进行分类,分别得到各个类的可信模型,进而得出预测结果。
3 实验结果及分析
本文所收集到的样本集,总体共77类疾病,每个样本的目标结果可能有一种到四种疾病,采用自助抽样算法实现。D为1 990份原始样本集,D′为1 990份“自助采样”的训练集,其中大约有600份病历未出现在训练集D′中,即DD′,把它作为测试集。在对目标样本进行评估分析时,出于确保Bagging集成算法有效性的目的,采取支持向量机算法(SVM)、决策树算法(Decision Tree)、逻辑回归算法(Logical regression)和随机森林算法(Random Forest)为基分类器,建立集成模型,然后与其构成的单个分类器结果做横向对比。
算法的实现通过采用Python软件调用scikit-learn工具包编程与梯度下降法优化模型关键参数实现,随后采用One-VS-the-Rest的策略实现多标签问题的分类。
由于目前将疾病的诊断视为机器学习中的多分类标签,因此采用式(1)、式(2)、式(3)中的三个指标[14]来评估模型。假设D′为多标签数据集,|D′|为D′对象总数,标记为(xi,Yi),其中i=1…|D′|,Yi表示真实样本值,|Yi|记为Yi样本总数,H为多标签分类器,Zi=H(xi)表示对样本特征xi预测的结果集合,|Zi|记为Zi的预测结果总数。
正确率:
(1)
召回率:
(2)
F值:
(3)
为进行充分比较,实验采用“自助法”划分训练集和测试集的方法,对集成模型结果与单个SVM、决策树、逻辑回归、随机森林分别进行比较,计算式(1)、式(2)、式(3),得出各模型的实验对比结果如图3所示。
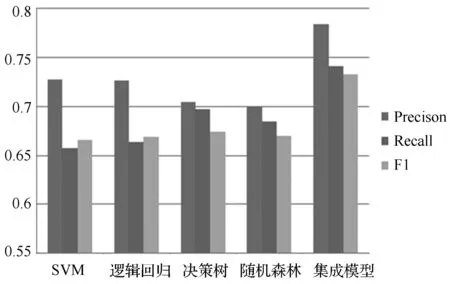
图3 模型对比结果展示
由图3很直观地看出:集成模型与单个分类器相比,准确率、召回率和F1均有不同程度的提高,其中,在单一分类器中,SVM预测准确率最高,为72.79%,召回率和F1决策树相对较高,分别为69.75%和67.38%,通过模型融合后,准确率、召回率和F1值,为0.784 4、0.741 5和0.732 5,分别与SVM、决策树相比,大约增长了6%、5%和6%。可以看出集成模型的准确率等效果较为明显。
4 结 语
本文不同于传统的单标签分类算法,采取一种多标签异构集成的模型分类方法。模型依据集成学习的基本思想,较为显著地提高了准确率等指标。通过算例表明,本方法能够有效地提高预测的准确率,降低计算误差,取得比单一模型更好的预测效果等。对于下一步的工作,需要根据未知样本结果,如一到四个目标疾病,通过化验、X光等方面的检查,获得详细数据来进一步明确儿童所患某种疾病。
[1] 范宏. 贝叶斯在医疗诊断系统中的应用研究[D]. 电子科技大学, 2013.
[2] 张翔,周明全,耿国华,等.Bagging算法在中文文本分类中的应用[J].计算机工程与应用,2009,45(5):135- 137,179.
[3] 高峰, 代美玲, 祁瑾. 基于Bootstrap-异质SVM集成学习的肺结节分类方法[J]. 天津大学学报(自然科学与工程技术版), 2017, 50(3):321- 327.
[4] 何鸣, 李国正, 袁捷. 医学诊断中集成学习技术的研究[J]. 计算机工程与应用, 2006, 42(28):218- 220,224.
[5] 虞凡, 杨利英, 覃征. 异构集成学习中的观察学习机制研究[J]. 广西师范大学学报(自然科学版), 2006, 24(4):54- 57.
[6] 刘端阳, 邱卫杰. 基于SVM期望间隔的多标签分类的主动学习[J]. 计算机科学, 2011, 38(4):230- 232,266.
[7] 晋爱莲, 耿丽娜, 薄芳芳. 多标签决策树分类在数字医学图像分类中的应用[J]. 中国数字医学, 2013, 8(3):90- 92.
[8] 董纯洁. 基于实例与逻辑回归的多标签分类模型[D]南京大学,2013.
[9] 瞿合祚, 刘恒, 李晓明,等. 基于多标签随机森林的电能质量复合扰动分类方法[J]. 电力系统保护与控制, 2017, 45(11):1- 7.
[10] Breiman L. Bagging predictors[J]. Machine Learning, 1996, 24(2):123- 140.
[11] 何鸣, 李国正, 袁捷,等. 基于主成份分析的Bagging集成学习方法[J]. 上海大学学报(自然科学版), 2006, 12(4):415- 418,427.
[12] 周志华. 机器学习[M]. 北京:清华大学出版社, 2016:24- 28.
[13] http://scikit-learn.org/stable/modules/multiclass.html.
[14] Tsoumakas G, Katakis I, Taniar D. Multi-Label Classification: An Overview[J]. International Journal of Data Warehousing & Mining, 2008, 3(3):1- 13.
