社交网络用户隐私量化建模与实证
2018-07-04梅真瑋吕廷杰
白 磊, 梅真瑋, 陈 霞, 吕廷杰
(北京邮电大学 经济管理学院, 北京 100876)
随着互联网的迅速发展,在线社交网络得到了进一步的蓬勃发展.在线社交网络平台,以其开放性、共享性和连通性等特点,成为人们进行网络社交活动的重要场所.出于社交的目标,社交网络用户在与其他用户产生联系的过程中自觉或不自觉间暴露了一定的个人隐私信息,如姓名、联系方式、社交关系、照片、地理位置、言论信息等.由于网络的开放性也使得这些用户的隐私信息更容易被获取、整理和非法使用,进而致使用户遭受一定的损失和伤害.电信诈骗事件频发就有很大一部分源于用户个人隐私信息泄露所致.随着人们对隐私观念逐步提升,对在线社交网络用户的隐私信息的保护问题也成为学术界和业界近年来关注的热点.
对社交网络的研究,理论方面格拉诺维特的弱关系理论、林楠的强关系理论、博特的结构洞理论[1]等相关理论基本成熟.在社交网络用户行为的研究方面,理论和实证研究也都较深入.研究主要通过对用户在在线社交网路中的发布信息、互动等行为,从统计和人类行为动力学的视角,进行分析研究.Wang[2]以新浪微博为研究对象,对用户行为和用户间关系数据进行分析,发现用户的关注数、粉丝数、微博数呈高度正相关.Wu等[3]对天涯网络社区上用户的回复进行了统计分析,发现用户发表评论的时间间隔分布符合幂率分布,具有胖尾特性.于洪等[4]以新浪微博作为研究对象,研究微博网络环境中的信息传播特点和传播节点影响力的关系.
对社交网络用户隐私方面的研究还存在较大的空间.目前国内外的研究主要有基于隐私数据的挖掘保护、隐私影响因素的研究、隐私信息传播和隐私建模研究等方向.Babbitt等[5]提出了基于保护规则的隐私保护分析模型.Hull等[6]通过构建基于上下文数据的框架模型,并根据用户设定的规则,在规定时间将规定数据分配给不同用户.Iachello等[7]则根据用户的使用经验以及规律,对于用户常见的一些隐私,进行设定权限、分配隐私等操作,效率虽然高,但是有一定局限性.Zeng等[8]通过建立用户隐私信息传播的框架模型,基于信息传播过程中被泄露的概率建立了用户隐私量化的理论模型框架,但主要停留在理论框架阶段,对具体使用场景的适用性未做深入分析.刘向宇等[9]对社交网络数据隐私保护研究现状分析中也指出目前社会网络隐私保护主要集中于数据挖掘、K-匿名、数据扰乱、推演控制等方法.李征仁[10]以移动互联网为研究对象,通过结构方程模型、社会网络分析和数据挖掘模型,研究用户隐私关注的影响因素及用户隐私信息的扩散的时间和范围规律.沈洪洲等[11]通过实验和访谈的方法对人人网、朋友网的隐私控制功能的可用性研究,指出两者在保护用户隐私方面需要改进的不足之处.葛伟平[12]对隐私保护数据挖掘方法上进行了分析,给出一种全局关联规则的隐私保护挖掘算法,并介绍了一种基于数据变换前后相关属性取值数量的差异程度来表示隐私保护程度.石硕[13]通过分析相关文献,结合TPB模型和隐私计算理论,使用隐私忧虑和感知收益揭示用户隐私披露行为,提出了社交网络上个人信息披露行为的理论研究模型.Gao等[14]运用随机抽样问卷调查的方法,制定相关因素量表,研究了隐私关注度、感知公平和感知投诉效益对我国互联网用户网络隐私保护行为的影响,表明隐私关注度对拒绝提供个人信息、伪造个人信息和投诉行为都有显著正向影响.Jiang等[15]提出了网络隐私关注和行为意向影响因素的概念模型.张志杰等[16]从LBS服务用户接受模型的角度进行研究,通过问卷调查和结构方程的方法,实证证明用户隐私因素对LBS业务使用意向的显著影响作用.王斌等[17]综合考虑用户个体和所处系统中心对网络用户隐私的影响,从动态隐私保护的视角提出一种基于所处环境的面向普适计算的用户的隐私量化模型,针对不同的隐私状态级别,采取不同的信息保护策略实现对用户隐私信息的保护.Zhu等[18]通过使用人类行为动力学和统计物理的方法研究用户的网络行为与用户隐私量值的关系,并用微博和人人网用户数据进行了实证分析.李凤华等[19]在分析隐私保护研究现状的基础上,提出隐私计算概念,对隐私计算的内涵进行界定,并提出从隐私信息的全生命周期讨论隐私计算的研究范畴,但主要停留于理论阶段,未做具体的隐私计算实证.
本研究建立了一种新的隐私量化模型,将用户的隐私状况抽象为一种向量,影响隐私属性的各影响因子为隐私向量的不同维度,通过隐私向量的取值定量化的表示用户的隐私保护程度.考虑到不同因子对隐私的影响力不同,提出采用基于相关系数的CRITIC方法来确定相应的权重.实证方面,基于新浪微博用户的真实数据,通过隐私量化模型得到相应用户的隐私量值.在此基础上对隐私量值与用户的基本属性及行为信息进行了对比分析,也从侧面验证了隐私保护状况与用户相关行为表现之间的关系.
1 量化分析模型建立
1.1用户隐私量化模型本研究采用向量化的方式,通过构建用户隐私向量来表示用户的隐私关注和隐私保护情况,以该隐私向量的取值来刻画用户隐私量值的大小,从而实现用户隐私量化.考虑到用户对不同隐私因子的重视程度不同,各隐私影响因子具有不同的权重,通过计算该隐私向量来实现隐私向量做量化刻画.由于在已有的研究中对用户隐私量值的计算主要通过直接进行各因子的权重简单叠加来实现[18],认为各影响因子属于同一维度且相互独立,而忽略了各影响因子之间的相互影响.本研究将隐私向量作为空间中的向量指标,通过考虑各影响因子之间的相互关系确定其在隐私量值中的影响大小,以隐私向量的长度(二范数)来表示用户的隐私量值的大小.
假设用户j的隐私向量为Pj=(f1,f2,…,fn),fn表示与用户隐私有关的量值因子,则用户j的隐私量值Pj可以表示为
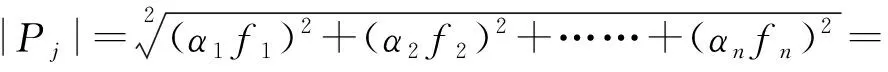
(1)
αi表示用户对隐私影响因子fi的重视程度,即其权重的大小.
1.2确定隐私影响因子权重已有的研究主要通过信息熵理论等[18]方法确定相关因子权重的大小,在计算复杂度高的同时忽略了因子之间相互的影响作用,对此本研究采用考虑不同因子之间的相互关系的基于相关系数法的CRITIC[20]决策方法来确定各因子的权重.
1.2.1相关系数法 相关系数法的基本思路是通过各因子之间的相关系数来度量各因子重复信息的大小,是一种消除重复信息对综合评价结果影响的客观附权方法,具有显著的理论和现实意义.从相关系数的数值上看,若2个因子之间的相关系数越接近于1,则他们的信息重复越严重,等于1,则完全重复;反之,若2个因子间的相关系数越接近0,则他们的重新信息越少,等于0,则无任何重复.各因子之间重合的信息越少,则能够越全面的刻画整体信息.多因子评价决策模型中因子往往不止2个,因而借助相关系数矩阵来合理确定因子的权重.具体计算步骤如下.
Step1计算相关系数矩阵.首先将原始数据标准化,假设原始数据包含m个因子,则其相关系数矩阵
Step2按列求和.计算第j列(1-rij)的和,可得到反映第j个因子与其他因子信息重复程度的行向量为
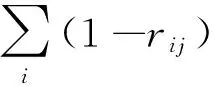
Step3计算因子权重.将上述向量做归一化处理,可得一组权向量,则可得各因子权重大小
(2)
此外考虑到在多因子评价中某项因子在所有被评价对象上的观测值可能存在较大的差异,变异程度越大,则说明该因子在被评价公式执行时达到平均水平的难度越大,表明它越能够区分各评价对象在该方面的性能,则该因子应赋予较大的权重,反之则较小.
同时考虑因子变异性和因子间冲突性的2个重要因素.本研究采用由文献[20]提出的客观赋权方法.因子变异性用标准差体现,以表明一个因子各评价方案之间取值差距的大小,标准差越大,表明各方案之间取值差距越大;而评价因子间冲突性则以因子间的相关性为基础进行考虑,即2个因子间具有较强的正相关将表明2个因子的冲突性较低.
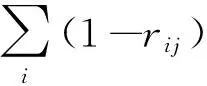
(3)
其中Ij越大表示第j个因子所包含的信息量越大,即该因子的相对重要性越大,所以赋权重也相应越大.第j个因子的权重
(4)
综上,隐私量化公式(1)中因子αi即可通过计算Wj实现,进而实现用户隐私量化.
2 数据获取及数据集介绍
在新浪微博的社交网络平台中,用户之间主要存在关注、粉丝和好友3种关系形态.关注和粉丝属于单向关系,A用户关注B用户,则A成为B的粉丝,A能够单方面接收到来自用户B发布的所有的微博信息,但B不会接收A发布的信息;好友关系即用户A和用户B互相关注,发布的信息双方互相能够接收到,具有较强的互动属性,属于社交网络中的一种强关系的体现.
本研究通过编写JAVA网络爬虫程序,利用新浪微博开放授权的API数据接口,以一个初始用户为起点,以滚雪球的网状数据采集方式,获取到其所处的社交网络环境的用户和相应微博数据.考虑到数据规模情况,主要获取了初始节点周围3层好友关系网络的数据,即初始用户本身、该用户好友、该用户好友的好友.这种获取方式也在一定程度上杜绝了非活跃用户的情况.历时3个月获取到来自新浪微博的32 386条用户基本数据及2 000余万条相关的微博的数据.用户基本数据具体包含如下属性.
1) 基本信息:用户ID、用户等级、微博数、粉丝数、关注数、好友数、粉丝列表、关注列表、好友列表(ID)、收藏数、账户注册时间.
2) 隐私属性:隐私设置情况、与地理位置行为有关的微博行为数(签到数、包含地理信息的微博数、包含地理位置的照片数).
具体与隐私有关的设置的数据,由于数据获取权限及平台方数据的限制,主要取得3项主要设置信息:
1) 信息行为:是否允许所有人给我发私信(m);
2) 评论行为:是否允许所有人评论我的微博(c);
3) 地理位置信息:是否允许获取我的地理位置相关的信息(g).
在具体获取数据方面,由于相应设置用户目前仅可选择允许或禁止,属于布尔型数据,则定义1为设置允许,0为设置禁止.
3 新浪微博用户隐私定量化分析
在新浪微博用户数据中取m(私信)、c(评论)、g(地理信息)3项设置为隐私量化评价指标,通过这3项指标具体反映用户对隐私信息的保护情况.采用隐私量化模型的方法可以得到新浪微用户j的隐私向量为
Pj=(mj,cj,gj).
(5)
向量Pj代表用户j在隐私方面的保护情况,mj是用户j对其他用户发私信行为的隐私保护情况;cj表示用户j对其他用户评论行为的隐私保护情况;gj表示用户对地理位置信息的保护情况.通过对3项影响因子在隐私量值的权重进行分析研究,进而对隐私向量取模实现用户j隐私的定量化分析.具体分析步骤如下.
Step1数据预处理.由于获取的用户中可能存在一定的僵尸用户,即非活跃的、在微博环境中不产生价值的用户.本研究中的僵尸用户的评判标准有以下2条:1) 无关注、无粉丝、无微博;2) 账户创建时间大于3个月,且发布的微博数低于10条且好友数低于10且粉丝数低于5.经数据处理所剔除僵尸用户约占总数据比为0.1%,获得有价值的用户数32 333个.
此外由于对上述3项隐私设置量值的获取数据静态的用户当前的设置数据,并未包含用户的历时变更情况.本研究利用用户地理位置有关的信息行为对用户的地理隐私设置情况进行修正.将有历史地理位置信息行为的用户的地理位置设置情况数值修正为1.在私信和评论方面的行为数据因子的限制暂不做处理,也希望未来的学者可以考虑到相应的因素.
Step2通过这32 333条用户数据,针对上述3项的隐私设置因子,可以得到一个R3×32 333的多因子评价矩阵.通过实际数据分析发现3个隐私设置因子间的相关性如表1所示.
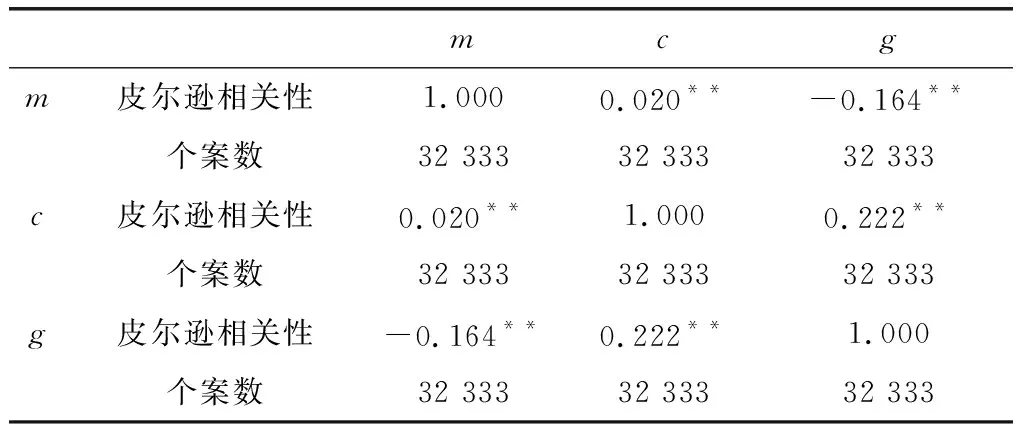
表 1 因子相关性
注:** 在 0.01 级别(双尾),相关性显著.
从相关系数的角度看,3项隐私因子之间相关性较差,说明相互之间信息重合程度低,3项因子组合能够更多的表达隐私信息.采用CRITIC客观赋权的方法,确定3项隐私因子在用户的隐私量值中的影响权重如表2所示.

表 2 新浪微博用户隐私影响因子权重
如表2所示,用户对接收私信的重视程度最大,具体表现为不愿意遭到陌生人的打扰;地理位置信息次之,主要出于地理信息安全问题泄露的考虑;评论行为的影响则相对较低,主要受限于用户间需要互动的影响.隐私影响因素的权重数值上符合实际情况.
Step3对用户的隐私向量取模,确定用户的隐私量值
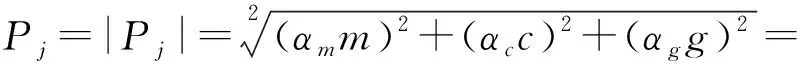
(6)
数值的高低表现了用户对隐私保护情况的高低.数值上隐私量值越高,表示该用户越开放其隐私信息,对隐私信息的保护情况越差,从而对隐私关注的程度越低;反之隐私量值越低,表示该用户的隐私信息越封闭,对隐私信息的保护意识越高,对高隐私关注的程度越高.通过真实的新浪用户数据进行隐私量化分析,具体隐私数据分布情况如表3所示.
从数据占比上看,高隐私群体和低隐私群体的总体分布占比为6.6%,属于合理的区间,表明社交网络中严格关注隐私信息和完全不关注隐私信息的
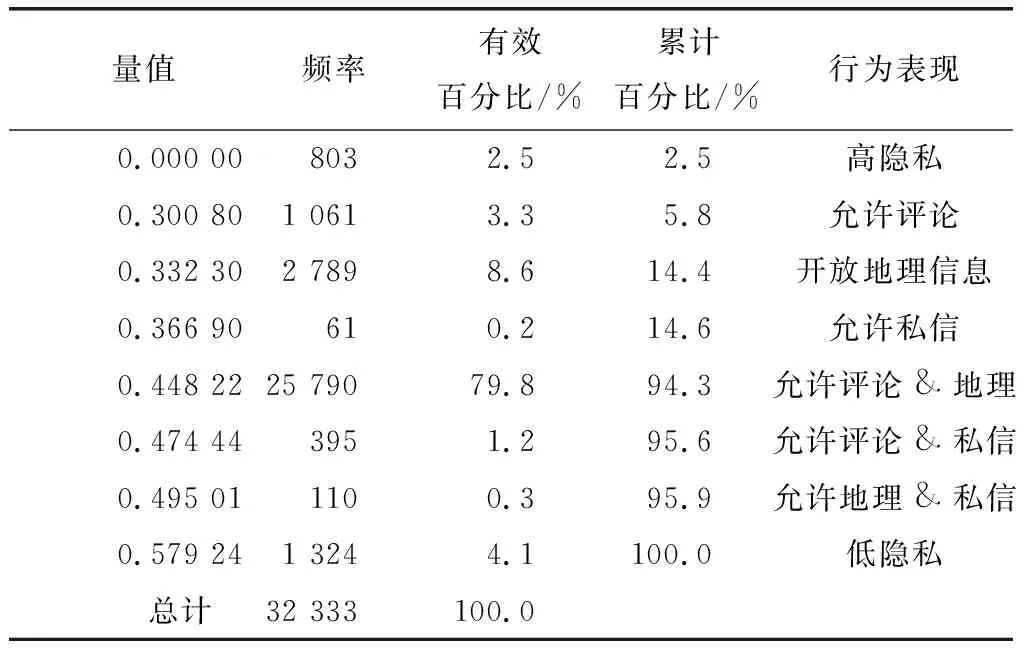
表 3 隐私量值分布
用户在总体用户中属于少数群体,其中低隐私群体相对略高.在用户隐私量值分布最明显的区间为允许其他用户评论且公开地理信息,占比为79.8%,几乎覆盖绝大部分用户,也符合在微博社交网络环境中,用户为满足自己表达和互动的需求,绝大部分用户愿意别人来评论他的信息,及公开自己的地理位置信息.在私信、评论、地理信息3项隐私信息公开中,单独公开私信有关的行为信息的用户比例最小,总体占比为1.7%,与用户隐私权重的占比也有一个较明显的反馈,表明较多的用户注重信息的保护,不愿意被其他用户打扰.单独开放评论或地理信息的用户占比分别为3.3%、8.6%,出于与其他用户互动或展示自己地理位置信息的需求,选择开放相应的隐私设置.
Step4用户隐私量值与用户基本属性的相关性分析.
由于已有的研究成果在计算得出隐私量值后并未对隐私量值与用户基本属性、用户行为数据等方面进行相互验证和解释说明,本研究将通过对隐私量值的分布情况与用户基本属性进行相关性分析及拟合,从实证角度解释和验证所得隐私量值分布的合理性和所采用隐私量化模型的有效性.具体工作如表4所示.
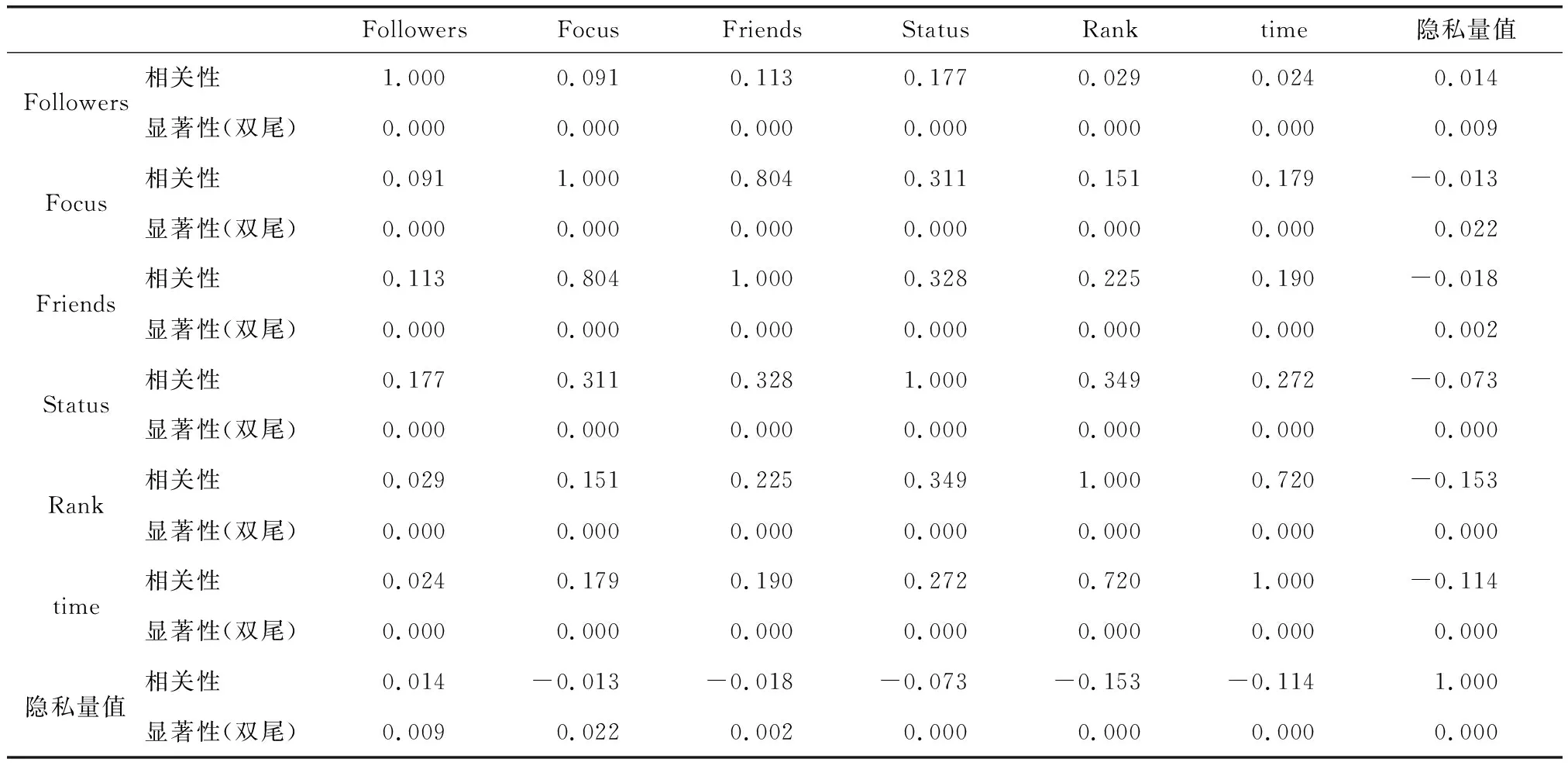
表 4 隐私量值与用户基本属性的相关性
注:单元格包含零阶(皮尔逊)相关性.
总体数据上看用户的隐私量值与用户的基本属性之间相关系数均低于0.2.从相关系数表中也能看出用户的关注数和用户的好友数呈明显的相关,用户的等级和时间呈明显相关.
1) 隐私量值与注册时长.通过隐私量值与用户的注册时长可获取到其相关皮尔逊系数为0.114,对其做二项式相关性拟合,可以发现:尽管从相关性的角度看,隐私量值和注册时长之间不存在明显的相关性分布趋势,但从二项式拟合注册时长的发展趋势和隐私量值的变化角度,呈现出注册时间越短、隐私量值越低的趋势.图1中也可以明显发现公开评论和地理信息用户的注册时长明显较其他隐私值的用户注册时长低,一定程度上反映了注册时间短、隐私保护意识低的状态.而有明确的选择只公开私信的用户的平均注册时长最长,反映了此类用户明确的隐私保护意识行为;同时公开评论和私信两项设置的用户的平均注册时长也相对较长一些,也在一定程度上反映了用户注册时长越长,对隐私保护的选择意识会有相应的提高.

图 1 隐私量值与平均注册时长分布
2) 隐私量值与粉丝数.隐私量值与粉丝数分布如图2所示.
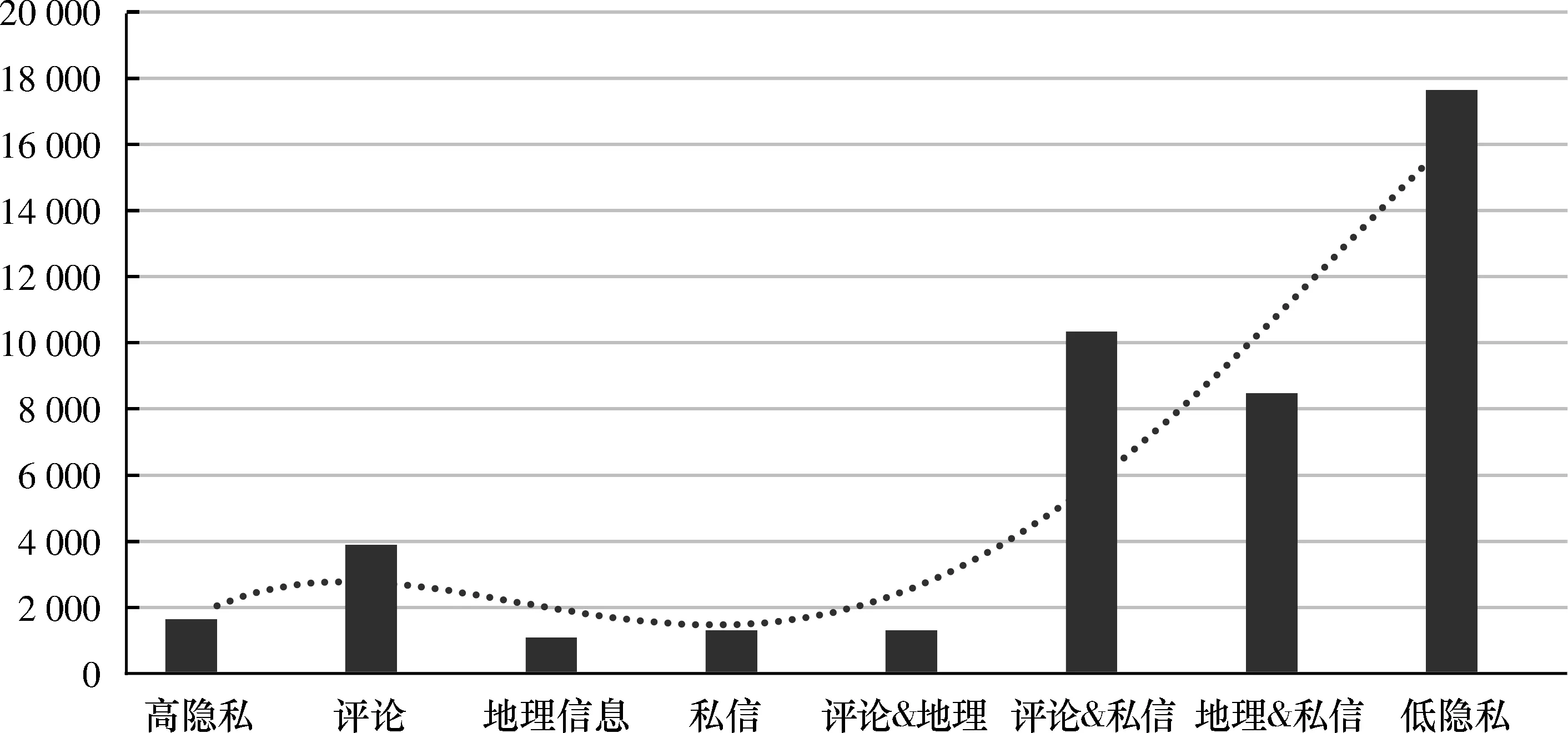
图 2 隐私量值与粉丝数分布
对不同隐私量值群体平均粉丝数做相关性分析,并对不同隐私量值下平均粉丝数分布情况做多项式拟合,发现随着用户隐私量值的提升即隐私关注度降低,用户的粉丝数呈明显的增加趋势,即隐私保护意识越低,粉丝数越大.高隐私关注的用户群体,在开放评论设置后,粉丝数有明显的提升,地理因素对粉丝的影响方面效果略差于私信设置,在开放私信设置后,粉丝数明显提升.将评论设置替换为地理设置后由于缺乏互动相应粉丝数有所下降.
3) 隐私量值与关注数和好友数.从总体二项拟合趋势看(图3),隐私保护情况越差的用户关注数越大.对用户而言有选择的开放评论设置,可以产生更多的社交行为,这类用户关注的用户数也相应较多;当开放地理信息后,出于保护地理信息的考虑,用户的关注水平有所降低;而开放私信与评论起同等作用,希望有较多的互动,关注的用户相对增加.低隐私群体的关注数总体也是最高的,基本符合预期.
隐私量值与用户的好友数变化,整体不太显著,但能够看出随着隐私权限的开放,用户的好友数逐渐增加,其中由评论和私信引起的互动因素的影响较明显,地理信息开放与好友数的变化呈微负向相关,可能与用户对地理信息的隐私保护观念有关.对比关注数和好友数的拟合图(图4),也能反映前文提到的好友数与关注数的明显相关性.
4) 隐私量值与用户发布的微博数.隐私量值与用户微博数略微呈现正相关趋势(图5),隐私量值越低微博数相对越多.在隐私设置中开放评论和地理信息而关闭私信的用户平均微博数明显较低,主要原因可能在于用户明确的关闭私信设置表明有一定的隐私关注意识,且开放了地理信息后发布微博的行为考虑到隐私的问题也有所降低.允许评论和私信的设置开放后,用户的互动积极性提高,因而微博数也较高.
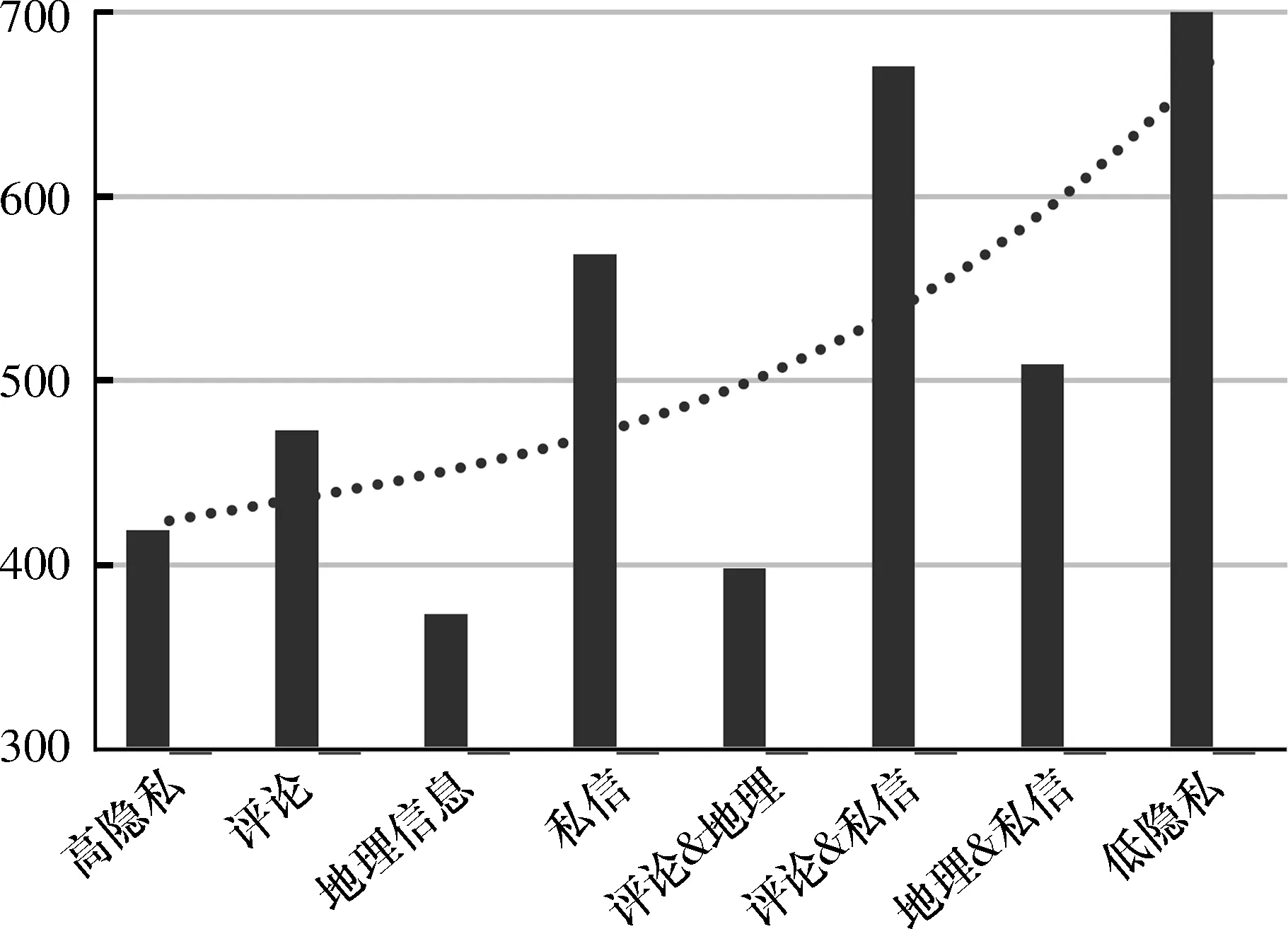
图 3 隐私量值与用户关注数
图4隐私量值与好友数
Fig.4Privacyvaluesandthenumberoffriends
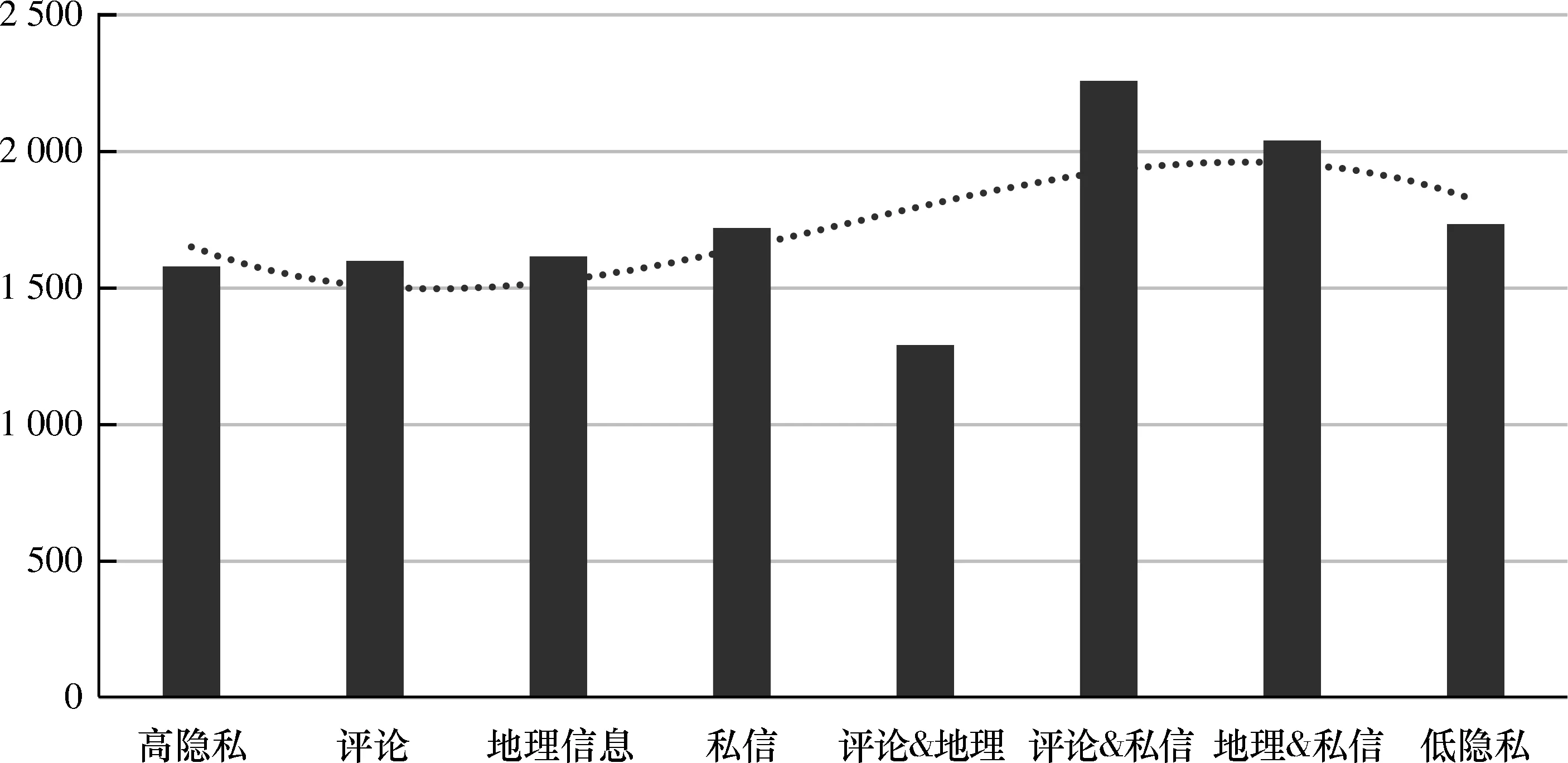
图 5 隐私量值与微博数
5) 性别因素.如图6所示,从性别上看,获取的用户数据中女性与男性的比例为57.7比42.3,女性用户相对较多.女性的平均隐私量值为0.424 8,男性的平均隐私量为0.432 2,差异不明显.从数据分布比例来看,女性在地理信息权限开放的比例较男性高,反映为女性用户会有较多的地理位置信息表露的行为,同时又通过关闭私信和评论来避免别人的打扰来保护隐私.而在地理信息表露的基础上评论设置开放的比例也明显较男性低,也在一定程度上反映女性用户在社交网络中对隐私保护的意识较男性相对高一些.
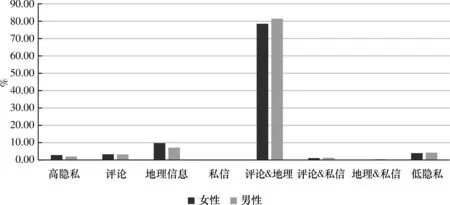
图6不同性别隐私保护情况
Fig.6Privacyprotectionofdifferentgender
6) 微博认证情况.如图7所示,认证用户群体的隐私量值的均值为0.434,总体上高于普通用户的平均水平,隐私保护程度相对开放.总体用户数据中5.42%的用户为认证用户,认证用户中有较多为的是企业账号.从隐私量值看10.3%的认证用户属于低隐私群体,明显多于非认证用户;开放评论及开放评论与私信设置的用户明显较普通用户的数据占比大,与地理信息有关的行为的保护程度也较普通用户高,符合认证账号强互动和信息发布的要求.
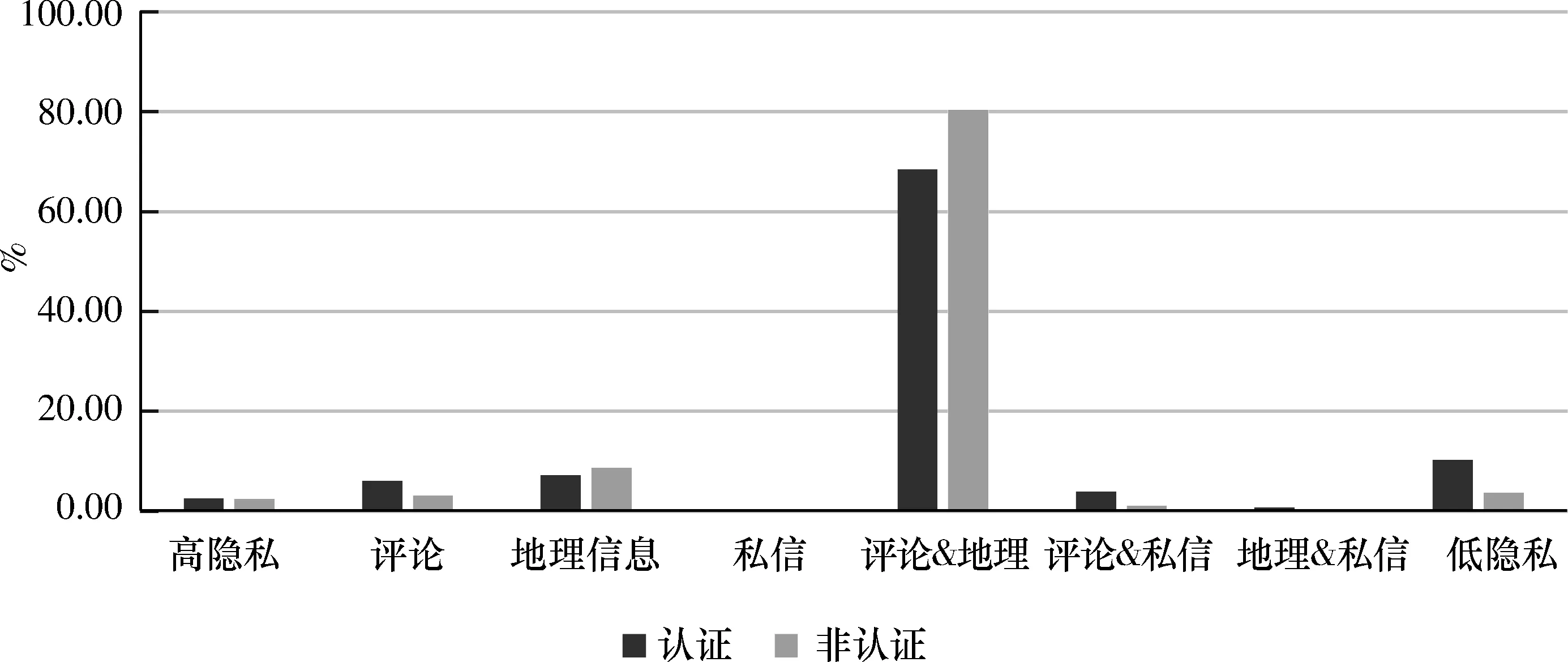
图 7 不同认证情况隐私量值分布
4 结论与展望
随着互联网的飞速发展,给人们的社交活动带来了更好的体验,但同时也为社交网络用户的隐私保护提出了更多的考验.如何更好保护用户隐私成为摆在社交平台方、监管方和社交网络用户面前的一个重要的问题.本文从用户隐私保护情况入手,建立用户隐私向量,通过考虑各因子影响大小对用户隐私进行了量化描述,并通过新浪微博用户数据进行实证分析,对用户隐私量值与用户相关属性进行了相关分析,从另一方面验证和解释模型的可行性以及揭示用户的相应网络行为和用户隐私量值之间的关系.研究发现,由于新浪微博属于一个信息发布和传播的平台,大部分的用户倾向于传播信息,因而用户对评论的隐私保护情况相对较弱,而用户的私信行为和包含地理位置信息的行为则受用户的隐私关注情况影响明显.同时用户的隐私量值与用户的好友数、关注数、微博数及性别和认证情况也有一定的相关性.从实用的角度,如果平台服务方能提供更全面的隐私保护机制将极大地增加用户对微博的使用体验,如增加信息发布环境选项、信息接收来源选项、数据分享对象选项等.同时作为微博用户在使用过程中及时的变更隐私信息保护提醒也具有较大的隐私保护意义.本文通过向量化的方式建立隐私量化模型,为在线社交网络用户隐私保护提供了一定的建议,在研究思路上也为未来的研究者提供了新的参考.但由于所获取数据广度和深度有限,包括在研究方法的选取上可能存在诸多未及深入的地方,希望未来的研究者能够有更加深入的研究.
[1] 郭龙飞. 社交网络用户隐私关注动态影响因素及行为规律研究[D]. 北京:北京邮电大学,2013.
[2] WANG X G. Empirical analysis on behavior characteristics and relation characteristics of micro-blog users take“sina micro-blog” for example[J]. Library and Information Service,2010,54(14):66-70.
[3] WU Y, ZHOU C, CHEN M, et al. Human comment dynamics in on-line social systems[J]. Physica A:Statistical Mechanics and Its Applications,2010,389(24):5832-5837.
[4] 于洪,杨显. 微博中节点影响力度量与传播路径模式研究[J]. 通信学报,2012,33(S1):96-102.
[5] BABBITT R, WONG J, CHANG C. Towards the modeling of personal privacy in ubiquitous computing environments[C]//Computer Software and Applications Conference,2007. COMPSAC 2007. DOI:10.1109/compsac.2007.224.
[6] HULL R, KUMAR B, LIEUWEN D, et al. Enabling context-aware and privacy-conscious user data sharing[C]//Mobile Data Management,2004. Proceedings. 2004 IEEE International Conference on. DOI:10.1109/mdm.2004.1263065.
[7] IACHELLO G, TRUONG K N, ABOWD G D, et al. Prototyping and sampling experience to evaluate ubiquitous computing privacy in the real world[C]//Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. DOI:10.1145/1124772.1124923.
[8] ZENG Y, SUN Y, XING L, et al. Trust-aware privacy evaluation in online social networks[C]//Communications (ICC), 2014 IEEE International Conference on. DOI:10.1109/icc.2014.6883439.
[9] 刘向宇,王斌,杨晓春. 社会网络数据发布隐私保护技术综述[J]. 软件学报,2014,25(3):576-590.
[10] 李征仁. 移动互联网环境下用户隐私关注的影响因素及隐私信息扩散规律研究[D]. 北京:北京邮电大学,2014.
[11] 沈洪洲,宗乾进,袁勤俭,等. 我国社交网络隐私控制功能的可用性研究[J]. 计算机应用,2012,32(3):690-693.
[12] 葛伟平. 隐私保护的数据挖掘[D].上海:复旦大学,2005.
[13] 石硕. 社交网站用户隐私披露行为探究:隐私计算理论与TPB模型的整合[D]. 南京:南京大学,2011.
[14] GAO X, YANG K. Factors affecting internet users information privacy protection[J]. J Intelligence,2011,4:39-42.
[15] JIANG X, JI S B. Conceptual model of the factors influencing consumer online privacy concern and behavior intention[J]. Science-Technology and Management,2009,5:21.
[16] 张志杰,吕廷杰. 移动LBS用户接受模型的实证研究[J]. 北京邮电大学学报(社会科学版),2012,14(1):56-61.
[17] 王斌,段友祥. 面向普适计算的用户隐私量化方法研究[J]. 计算机工程与应用,2011,47(27):1-5.
[18] ZHU H Y, WU L R, LU J. Research on quantifying user privacy on social networking sites[J]. J Tsinghua University (Science and Technology),2015,54(3):402-406.
[19] 李凤华,李晖,贾焰,等. 隐私计算研究范畴及发展趋势[J]. 通信学报,2016,37(4):1-11.
[20] 林齐宁. 决策分析教程[M]. 北京:清华大学出版社,2013.
