一种多特征融合的场景分类方法
2018-07-04李志欣李艳红张灿龙
李志欣,李艳红,张灿龙
(广西师范大学 广西多源信息挖掘与安全重点实验室,广西 桂林 541004)(广西区域多源信息集成与智能处理协同创新中心,广西 桂林 541004)
1 引 言
图像场景分类,顾名思义就是自动判别一个语义类别集中的某一幅图像属于哪个场景类(如卧室、厨房和客厅).图像场景分类技术的研究一直以来备受人们关注.根据描述图像方法的不同,目前图像分类方法大致可以分为:基于全局特征的描述方法、基于局部特征的描述方法和基于特征融合的描述方法.
在早期,场景分类主要是利用底层全局特征,例如:颜色、Gabor纹理、形状等,由于它们实现简单且计算不复杂,因此得到广泛使用.杨昭等[1]针对全局GIST特征网格划分粗粒度问题,提出一种基于密集网格划分的局部GIST特征,利用空间金字塔结构加入空间信息,并引入RGB颜色空间信息,采用视觉词袋(bag of visual words,BoW)设计模型来完成场景分类.文献[2]提出一种改进的小波金字塔能量分布特征,同图像的PHOG特征动态组合,利用SVM分类器对图像进行分类.但是,由于全局特征是对整幅图像的一个整体描述,它并没有注意各部分特征之间的局部细节对象,因此会造成对具有局部目标的图像场景分类精度下降.
由于图像的局部特征能够很好的描述图像细节信息,因此广受研究者的青睐.基于BoW方法缺少考虑场景中局部特征的空间信息,Lazebnik等人[3]采用空间金字塔(Spatial Pyramid matching,SPM)模型将图像划分为不同层次的子图,不同层次赋予不同的权值,把不同层次上的图像特征点进行匹配,从而获取图像的空间分布信息.Yang等人[4]在SPM的基础上,提出ScSPM(Sparse Coding SPM)利用稀疏编码特征,对金字塔每一层的图像子块分别进行稀疏编码,最后将每一层的子块按照从左到右、从上到下的顺序级联成图像的稀疏向量表示,在一定程度上提高分类精度.文献[5]使用局部约束线性编码(Locality-constrained Linear Coding,LLC)在保证稀疏性的同时,强调局部约束,以进一步提高稀疏编码中图像局部特征的表示精度.虽然这些方法在一定范围内表现出很好的分类性能,但是它们都是基于图像的底层特征,为了获得更好的性能,研究者提出了基于中层语义信息来表述场景.在BoW模型基础上运用概率生成模型来发现图像的潜在语义特性.现在常用的概率生成模型有概率潜在语义分析(probabilistic latent semantic analysis,PLSA)模型[6]和潜在狄利克雷分布(latent Dirichlet allocation,LDA)模型[7].然而大多数LDA算法由于弱监督,一般只能获取无关的生成规则,而无法获得感兴趣的语义规则[8].Ergul等人[9]提出基于SPM-PLSA模型的图像场景分类算法,首先提取图像在金字塔各层的特征,然后在各层上运用PLSA来发掘潜在语义信息.Object Bank[10]是一种中层语义表示模型,它用Object作为特征,计算图像对不同特征的响应,并根据其响应情况进行分类.总体而言,上述几种方法都是先生成底层特征,然后结合分类器实现图像场景分类.
由于图像中包含的物体信息非常丰富,彼此之间的空间分布错综复杂,基于单一特征的描述方法分类效果不佳.所以,如何恰当、有效的利用已有数据,融合图像底层特征,已经成为一个新的研究热点.文献[11]利用局部SIFT特征结合图像灰度特征跟Gabor特征,分别得到各自的视觉特征字典,通过字典来协同表示图像.文献[12]融合全局结构特征和纹理特征,并联合局部光谱信息,采用BOW模型实现高分辨率遥感图像分类.文献[13]利用WHGO(weighted histograms gradient orientation)特征代替SIFT特征,并与纹理特征相结合,利用非线性SVM分类器学习到结构跟纹理特征的权值,在一定程度上提高了分类准确性.贾世杰等[14]将具有互补特性PHOG特征和PHOW特征相结合,改进最近邻分类算法,实现商品图像在线实时快速分类.许庆勇等[15]将图像的颜色、纹理和形状特征融合,利用构建好的4层深度置信网络(Deep Belief Network,DBN)分类器进行训练并分类,解决单一特征分类算法准确率不高的问题.文献[16]的模型结合全局特征和局部区域特征,通过对无序特征词袋添加一个简单的空间约束提高识别性能.文献[17]组合多个特征和共同空间的空间邻居,并最小化上下文相关的能量,利用不同类型的上下文关系提高识别精度,并在较大的数据集中取得很好的性能.
上述几种方法都采用多特征融合的方式来描述图像特征,由于多特征集成了各个特征的优势,所以,在分类准确性上要优于单一特征.但是在多特征融合时,以上方法只是将多个特征简单的线性组合,并没有考虑对特征进行降维,而图像是由像素表达的,其本身具有稀疏性.通过对图像进行稀疏处理,得到的图像编码能更好的描述图像特性.因此,本文提出一种多特征融合的图像场景分类方法,该方法将图像的GIST特征[18]、SIFT特征[19]稀疏向量表示和PHOG特征[20]采用直接串联的方法进行特征融合.最后将融合特征与类标签信息一起输入到线性SVM进行分类.本文方法将三者组合起来描述图像,能够提供更丰富的信息,特征之间能够达到优势互补,进一步提高分类准确性.在几个常用数据集的实验结果表明,与现有几种模型相比,本文方法具有较好的分类性能.
2 相关技术
2.1 LLC稀疏表示
高维数据的稀疏表示是一种无监督学习方法,近几年已经成为图像处理和计算机视觉领域的研究热点之一.它采用一组“超完备”基向量来表示样本数据.在图像处理领域中,图像的稀疏表示是在SPM框架上,将图像各个区域内池化后的向量级联起来,从而表示一幅图像的过程.本文采用LLC对SIFT特征进行编码,LLC的编码满足下式约束:
(1)
公式(1)可以按照加号的前后分成两部分:加号前的项最小化是为了减少量化误差,学习字典B并确认投影系数;加号后的项则是做出假设约束.其中X=[x1,x2,…,xN]∈RD×N,是一个包含N个D维局部特征的矩阵,xi为待编码的向量B=[b1,b2,…,bM]∈RD×M,是一个包含M个视觉词汇的词典,经过K-means算法所得.LLC编码把所有X映射到B定义的编码空间,ui为经过LLC得到的编码.λ为正则项,用来平衡加号前后两项,并确保ui的稀疏性.‖di·ui‖是向量元素di和ui维度的相乘,体现了编码的局部性.di为不同编码的权重,用于衡量编码中每个元素ui同词典B中相应列的关系.di可用下式计算:
(2)
其中:dist(xi,B)=[dist(ai,b1),…,dist(ai,bM)]T,dist(ai,bj)是局部特征ai到视觉词汇bj的欧氏距离.每个元素代表向量xi与词典B中每列向量的欧氏距离,σ为可调整的参数,用于控制di的大小,即控制局部衰减性速度.
为了取得更优的分类准确率,编码规则要求相似的描述符生成相似的编码,按照这样的规定,局部规则项‖di·ui‖2将发挥更重要的作用.综上所述,LLC稀疏表示的优点主要有:
1)更优的重构.在向量量化编码过程中,每一个描述符仅仅通过码本中的单个基元(即基向量)表示.由于大量的量化误差,对于相似的描述符,向量量化编码可能导致不同的表示,因此非线性内核需要投影来弥补此类信息损失.
2)局部平滑稀疏.类似于LLC,ScSPM通过使用多个基元减少重建误差.然而正则化项L1范式在ScSPM中并不能保证平滑性.而LLC编码中,每个描述符是由多个基元更准确地表示.因此,LLC编码能够通过共享基元捕获相似描述符之间的相关性.
2.2 最大池化
在图像处理中,池化是指把特征向量集映射为单个向量的过程.max-pooling是池化方式的一种.max-pooling函数的定义如下:
Z=F(U)
(3)
其中,U是描述符集X利用公式(1)稀疏编码之后的结果.假设码本B是提前训练好的,U=[u1,u2,…,uM]T,z=[z1,z2,…,zM],M为图像特征描述符的个数,zj是z的第j个元素,uij表示矩阵U的第i行第j列的元素.每个ui就是一个特征描述符的稀疏编码.最大池化技术是根据人脑视觉皮层V1区中生物学方面来建立的,经过稀疏编码的自然图像,综合了图像空间局部性、空间方向性、信息选择性的特点,因此比直方图统计的平均池化具有更好的鲁棒性.
3 场景分类框架和方法
3.1 系统框架
在图像场景分类中,全局特征主要描述一幅场景的整体轮廓,而局部特征则重点描述图像局部形状、光照条件等因素,两类特征之间有不同的优势.由于底层特征分类效果比较差,而图像特征的优劣直接影响分类的精度.因此,为了提高图像的分类准确率,本文在LLC稀疏表示的基础上加入了多种底层特征,提出了一种基于多特征融合的场景分类方法.图1为本文方法的分类框架图,该方法主要分为两个阶段:训练阶段和测试阶段.

图1 场景分类框架图Fig.1 Scene classification framework
训练阶段步骤如下:
1)首先分别提取训练图像的GIST特征、SIFT特征和PHOG特征.
2)对样本图像的SIFT特征进行LLC编码,得到样本图像SIFT特征稀疏编码;然后基于空间金字塔匹配模型进行最大池化,得到样本图像的SIFT特征稀疏向量表示.
3)将样本图像的GIST特征、SIFT特征稀疏向量表示和PHOG特征进行串行融合,形成样本图像最终的特征表示.并将样本图像最终的特征表示和类标签信息一起输入到线性SVM进行训练.
测试阶段步骤如下:
1)首先分别提取待分类图像的GIST特征、SIFT特征、PHOG特征.
2)对待分类图像的SIFT特征进行LLC编码,得到待分类图像SIFT特征稀疏编码;然后基于空间金字塔匹配模型进行最大池化,得到待分类图像的SIFT特征稀疏向量表示.
3)将待分类图像的GIST特征、SIFT特征稀疏向量表示和PHOG特征进行串行融合,形成待分类图像最终的特征表示.并将待分类图像最终的特征表示输入到已训练好的线性SVM进行判别,得到最终的分类结果.
3.2 特征提取阶段
3.2.1 生成GIST特征
依据Oliva和Torralba的说法,本文将图像划分为4×4的规则网格,用4尺度8方向共32个Gabor滤波器处理每一小块图像.再将经过处理后的每一小块图像所得到的块图像GIST特征进行级联形成全局GIST特征,这样就得到一个32×16大小的特征向量组.此一维特征向量组即为全局GIST特征向量,该特征是一个512维的特征向量组.
3.2.2 生成SIFT特征
以特征点为中心计算4×4小块上8个方向的梯度方向直方图,将采样点与特征点的相对方向通过高斯滤波后归入8个方向的直方图,通过计算每个梯度方向的累加值,即可形成一个种子点.在实际应用中,SIFT特征描述符最好的分类结果是用4×4直方图阵列来实现,每个阵列有8个方向,进而形成128维的SIFT特征描述符.因此,本文实验SIFT特征的每个关键点的维数为4×4×8=128维的特征向量.
3.2.3 生成PHOG特征
金字塔梯度方向直方图(Pyramid Histogram of Oriented Gradients,PHOG)是由Bosch等人提出,PHOG描述符是一种对图像空间形状的描述符,不仅描述了图像的整体形状,而且还描述了图像的局部形状.
PHOG的形状描述是用直方图来表示的.首先得到图像的部分或全部轮廓;然后计算轮廓点处的梯度模和梯度方向;再将梯度方向转换成以度为单位,范围为[0,180°]或[0,360°],并分成K个区间;最后累加各区间上梯度模的值作为该区间的权值,得到梯度方向直方图.为了表示图像的空间信息,将一幅图像逐级划分成小尺度,假设图像级数为L,L取值根据实际需要而定.如果L=0,那么图像没有被划分;当L=1时,图像被划分为4个子块;当L=2时,图像被划分为16块;当L=…,以此类推,级数划分的越细,图像子块数越多,最后将各个层次上面的梯度方向直方图级联,便得到最终的直方图,PHOG特征维数共有K∑1∈L4L维,其中K为区间的个数,L为划分的层数.本文方法中,梯度方向取值360°,区间取值为40,分为三层空间.所以,本文提取的PHOG特征的维度为3400.
3.3 SIFT特征稀疏向量表示
从训练图像集中随机选取若干图像,并提取SIFT特征,形成SIFT特征向量集L=[l1,l2,…,lN].其中li∈R128,N为SIFT特征向量的个数.L=[l1,l2,…,lN]即对应式(1)中的训练向量集X=[x1,x2,…,xN].利用迭代方法求解SIFT特征向量集L=[l1,l2,…,lN]的视觉词汇库Q∈R128×k,K表示视觉词汇库的大小,Q对应式(1)中的过完备字典B.
利用字典B对每幅图像的SIFT特征描述子L=[l1,l2,…,lN]进行LLC编码,从而获得每幅图像的编码矩阵H=[h1,h2,…,hs]T.其中hi是每个特征描述子的编码,s是描述子的个数.将图像分成3层,第0层将整幅图像作为一个区域,对应编码矩阵H,对H的每一列应用最大池化技术,得到向量y0.紧接着,第1层将整幅图像均匀划分为4个区域.按从左往右、从上到下对应的编码矩阵分别为H00、H01、H10、H11,同样对每个编码矩阵按列运用最大池化技术,得到向量y1,y2,y3,y4.同样地,第2层将整幅图像均匀划分为16个区域,最大池化后得到y5,y6,…,y20.将y0,y1,…,y20按第0层权值为1/4,第1层权值为1/4,第2层权值为1/2,加权后级联起来,得到图像SIFT特征的稀疏向量表示.

图2 SIFT稀疏向量表示Fig.2 SIFT sparse vector representation
3.4 特征融合
特征融合是指将两个或者多个特征向量按照某种规则组合成新的特征向量.具体特征融合方法包括串行融合方法和并行融合方法.假设三个特征空间A、B和C中有三个特征向量,α∈A,β∈B,λ∈C.串行特征融合方法就是将α、β和λ串成一个特征向量η,其公式为:

(4)
并行融合的方法是将α、β和λ三个特征向量合并成一个复合的η特征向量,其公式为:
η=α+iβ+jλ
(5)
其中i,j均为虚数单位,当α、β和λ的维数不一致时,低维的特征需要补0,三个特征才能并行融合.
本文采用的是串行融合,所以由式(4)可知,若GIST特征为n维,SIFT特征向量为m维,PHOG特征为z维.那么串行组合的特征量η为(n+m+z)维.因此串行融合而成的向量集构成(n+m+z)维的融合特征空间.
3.5 多类线性SVM
(6)
通过一对多的策略得到L个二元线性SVM,主要是为了解决如公式(7)所示的无约束凸优化问题.
(7)

由于标准的hinge loss函数是不可微的,它阻碍了基于梯度优化方法的使用.所以采用下面公式(8)所示的可分辨的二次hinge loss函数来优化基于梯度的方法.
(8)
4 实验结果与分析
4.1 实验数据集
本文方法将在图像场景分类的四个小规模数据集,包括三种经典数据集:OT数据集[21]、FP数据集[4]、LSP数据集[12],以及Caltech-101数据集[22]上分别测试其分类精度.同时,还对所提出的方法在中等规模的数据集上进行了评估,包括Caltech-256数据集[5]和MIT67数据集[23].

图3 三种经典数据集的部分示例图像(其中带有MIT前缀的是OT数据集)Fig.3 Partial sample image of three classic datasets (where the OT data set with MIT prefix)
三种经典数据集部分示例图,如图3所示.OT数据集包含8类场景:coast、forest、highway、insidecity、mountain、opencountry、street、tallbuilding,总共2688幅图像.FP数据集是在OT数据集中增加了suburb、bedroom、livingroom、kitchen、office五类场景,一共包含13类场景,3895幅图像;LSP数据集在FP数据集上进行了扩充,增加了store和industrial场景,总共包含15类场景,4485幅图像.三种经典数据集中每一类场景均包含200到400幅图像,图像的平均大小约为300×250像素.Caltech-101数据集包含102类9144幅图像,例如动物、车辆、飞机等.每类包含图像数目31~800幅不等,平均尺寸为300×300像素.Caltech-256数据集是由Griffin等人在Caltech-101数据集上扩充组成的,总共256类30607幅图像.每类的图像从80到827不等,它在物体尺寸、位置等方面比Caltech-101呈现出更高的可变性.MIT67包含67类室内场景,总共15620幅图像.
4.2 实验环境与参数设置
本文实验运行环境为Visual Studio 2010和MATLAB 2012a,硬件配置为一台Intel Xeon X5670处理器,48G内存的计算机.

图4 Caltech-101数据集部分示例图像Fig.4 Caltech-101 dataset part of the sample image
实验过程中,所有图像均转化成灰度图像.对每一个数据集重复进行10轮实验,每一轮随机划分训练集和测试集,对于不同的数据集,划分的训练集跟测试集有所不同,在下面会有具体说明.最终的分类精度由10轮结果的均值表示.对于每一类数据集,提取图像的SIFT特征和PHOG特征时,图像尺寸调整在300×300以内.而提取GIST特征时,图像的尺寸调整为256×256.SIFT特征通过LLC编码时视觉词典大小为1024,视觉字典使用K-means算法直接聚类生成,SIFT特征稀疏编码、池化过程中knn的大小为5.

图5 Caltech-256数据集部分示例图像Fig.5 Caltech-256 dataset part of the sample image

图6 MIT67数据集部分示例图像Fig.6 MIT67 dataset part of the sample image
4.3 小规模数据集上实验结果对比
4.3.1 本文方法与经典算法性能对比
为了验证多特征融合方法的可行性,将本文方法与经典场景分类方法在四种小规模的数据集上进行对比.对比方法包括Lazebink[3]的空间金字塔(SPM),Ergul等人[8]的SPM和PLSA模型结合(SPM-PLSA),Yang等人[4]的ScSPM模型以及Wang等人[5]的局部约束线性编码(LLC),中级语义的潜在主题模型LDA[8],Object Bank[10]的扩展模型.上述大多数方法不能使用在大规模数据集中,所以我们分开比较小规模数据集和中等规模数据集.
实验结果如表1至表4所示.在三种经典数据集上,每类随机选取100幅图像作为训练集,其余图像作为测试集.
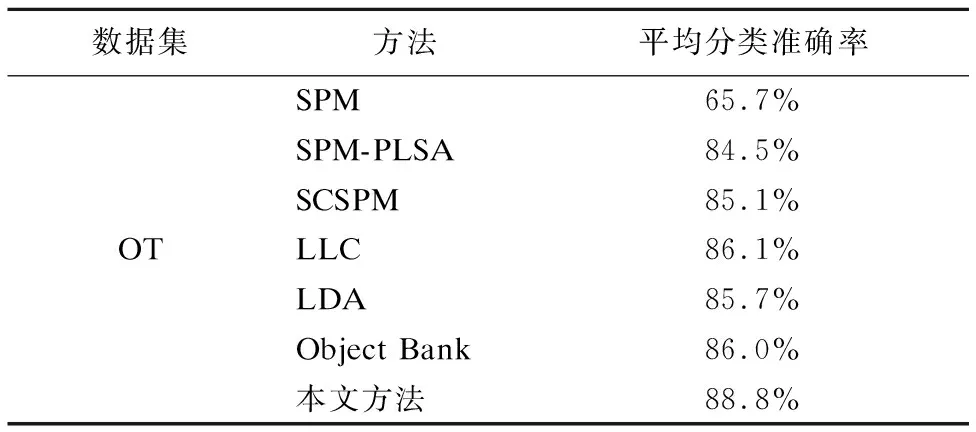
表1 OT数据集上不同算法平均分类准确率对比Table 1 Comparison of mean classification accuracy of different algorithms on OT data set
Caltech-101数据集上每类训练图像是30幅,剩余为测试图像.从表1-4中可以看出,在同等参数设置下,本文方法在OT数据集上分类准确率达到88.8%,在FP场景图像上分类准确率达到86.4%,在LSP场景图像上分类准确率达到82.8%,在Caltech-101场景图像上分类准确率达到74.9%,与其他6种方法相比,分类性能均有所提高.实验结果也验证了特征融合分类模型的有效性与稳定性.并且随着数据集的扩大,整体的分类性能在降低.即OT数据集的分类性能要优于FP数据集,FP数据集的分类性能则优于LSP数据集.LSP数据集的分类性能则优于Caltech-101数据集.
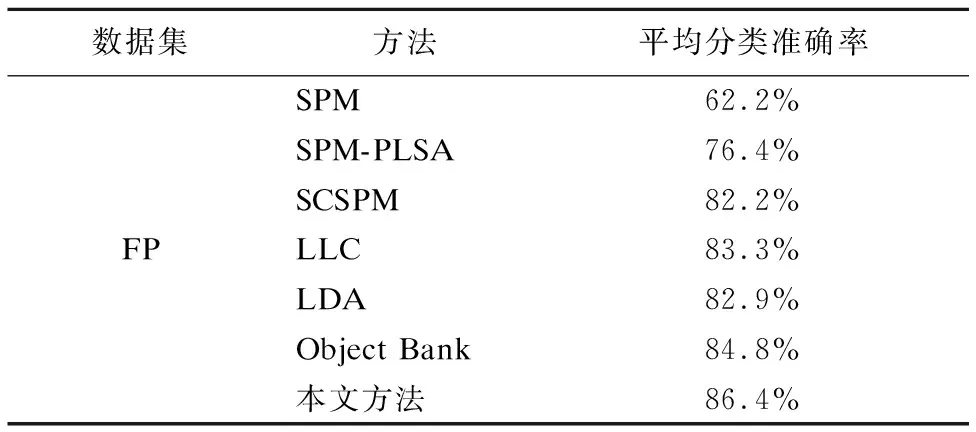
表2 FP数据集上不同算法平均分类准确率对比Table 2 Comparison of mean classification accuracy of different algorithms on FP data set
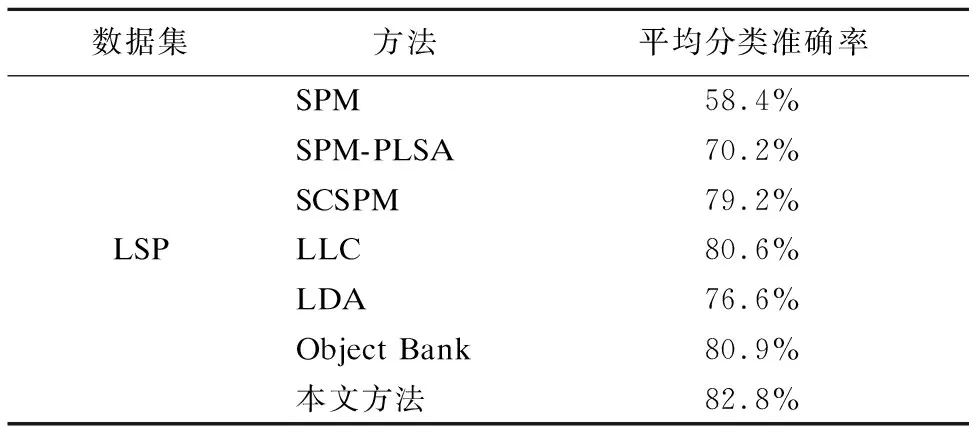
表3 LSP数据集上不同算法平均分类准确率对比Table 3 Comparison of mean classification accuracy of different algorithms on LSP data set
4.3.2 本文方法与多特征融合方法性能对比
为验证本文方法的有效性和新颖性,将它和现有的几种多特征融合场景分类方法进行比较,其中包括文献[13]、文献[14]、文献[15]、文献[16]和文献[17].三种经典数据集上,每类随机选取100幅图像作为训练集,其余图像作为测试集,在同等参数设置下的实验结果如表5到表7所示.

表4 Caltech-101数据集上不同算法分类准确率对比Table 4 Comparison of mean classification accuracy of different algorithms on caltech-101 data set

表5 OT数据集上多特征融合方法平均分类准确率对比Table 5 Comparison of mean classification accuracy of multi-feature fusion method on OT data set

表6 FP数据集上多特征融合方法平均分类准确率对比Table 6 Comparison of mean classification accuracy of multi-feature fusion method on FP data set

表7 LSP数据集上多特征融合方法平均分类准确率对比Table 7 Comparison of mean classification accuracy of multi-feature fusion method on LSP data set
从上面3个表格数据可以看出,在三个数据集上本文方法的分类准确率均优于其他五种方法.其中,在OT数据集上,比文献[14]高出7个百分点;在FP数据集上,比文献[16]高出13个百分点;在LSP数据集上,比文献[16]高出15个百分点.这是由于本文方法综合考虑了全局和局部特征,并进行了有效的稀疏,因而比其他多特征融合方法获得了更好的分类性能.
4.4 中等规模数据集上实验结果对比
为了进一步验证本文方法的性能,将本文方法与现有几种方法在中等规模的MIT67数据集和Caltech-256数据集进行评估.在Caltech-256数据集上,每类随机选取60幅图像作为训练集,其余图像作为测试集,在MIT67数据集数据集上,每类选取80幅图像作为训练集,在剩下的图像中随机选取20幅图像作为测试集,实验结果如表8和表9所示.

表8 MIT67数据集上不同方法平均分类准确率对比Table 8 Comparison of mean classification accuracy of different methods on MIT67 data set
除文献[17]外,本文方法的分类准确率比其余对比方法都要好.Object Bank方法和文献[16]属于中层语义信息表示对象,能够更好地利用外部数据量(例如ImageNet)来建模中层分类.本文方法使用稀疏编码方法来建模,没有利用外部数据,因此性能更加优越.由于中层语义方法对这些数据集进行训练的数量有限,作为参考我们还与基于稀疏编码框架的LLC方法作对比.虽然LLC同样使用了稀疏编码模型,但是多特征融合的方法要比单一特征的LLC编码模型性能更优越.由于中等规模数据集包含室内场景,所以基于部分的表示方法能取得更好的分类性能.随着类的数量越来越多,利用局部空间信息和多特征关系可以帮助发现一致模式并过滤噪声,而文献[17]利用不同类型的语境关系,所以在较大的数据集中分类精度始终要优于本文方法.

表9 Caltech-256数据集上不同方法平均分类准确率对比Table 9 Comparison of mean classification accuracy of different methods on caltech-256 data set
5 总结与展望
本文提出了一种多特征融合的图像场景分类方法,通过串行融合全局特征和局部特征,有效缓解了单一特征在描述图像时的局限性.在小规模数据集中,与现有几种多特征融合方法相比,具有较好的分类性能.在中等规模数据集上,利用多种特征关系,并结合稀疏编码对特征进行降维处理,整体分类性能要优于大多数分类方法.虽然在类别复杂的数据集上的分类效果不是很好,但是在类别较少的数据集上具有良好的分类性能,验证了特征融合分类模型的有效性与稳定性.然而,为了进一步提高场景分类的准确率,下一步可以考虑如何动态分配合理的权值,将各个特征进行加权融合,以及考虑单词之间的语义关系,并结合稀疏编码对图像特征进行深层次的学习.
:
[1] Yang Zhao,Gao Jun,Xie Zhao,et al.Scene categorization of local Gist feature match kernel [J].Journal of Image and Graphics (JIG),2013,18(3):264-270.
[2] Yuan Jie,Wei Bao-gang,Wang Li-dong.An image retrieval method synthesizing PHOG shape description and wavelet pyramid energy distribution [J].Acta Electronica Sinica,2011,39(9):2114-2119.
[3] Lazebnik S,Schmid C,Ponce J.Beyond bags of features:spatial pyramid matching for recognizing natural scene categories [C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2006:2169-2178.
[4] Yang J,Yu K,Gong Y,et al.Linear spatial pyramid matching using sparse coding for image classification [C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2009:1794-1801.
[5] Wang J,Yang J,Yu K,et al.Locality-constrained linear coding for image classification [C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2010:3360-3367.
[6] Li Zhi-xin,Shi Zhong-zhi,Zhao Wei-zhong,et al.Learning semantic concepts from image database with hybrid generative/discriminative approach [J].Engineering Applications of Artificial Intelligence (EAAI),2013,26(9):2143-2152.
[7] Tang Ying-jun.Image scene classification model based on Dirichlet allocation with double inferences [J].Journal of Chinese Computer Systems (JCCS),2015,36(11):2578-2582.
[8] Rasiwasia N,Vasconcelos N.Latent Dirichlet allocation models for image classification [J].IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI),2013,35(11):2665-2679.
[9] Ergul E,Arica N.Scene classification using spatial pyramid of latent topics [C].Proceedings of the 20th International Conference on Pattern Recognition (ICPR),2010:3603-3606.
[10] Zhang L,Zhen X,Shao L.Learning object-to-class kernels for scene classification [J].IEEE Transactions on Image Processing (TIP),2014,23(8):3241-3253.
[11] Zou J,Li W,Chen C,et al.Scene classification using local and global features with collaborative representation fusion [J].Information Sciences,2016,348:209-226.
[12] Zhu Q,Zhong Y,Zhao B,et al.Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery [J].IEEE Geoscience and Remote Sensing Letters,2016,13(6):747-751.
[13] Zhou L,Dewen H U,Zhou Z T.Scene recognition combining structural and textural features [J].Science China:Information Sciences,2013,56(7):1-14.
[14] Jia Shi-jie,Kong Xiang-wei,Fu Hai-yan,et al.Auto classification of product images based on complementary features and class description [J].Journal of Electronics and Information Technology,2010,32(10):2294-2300.
[15] Xu Qing-yong,Jiang Shun-liang,Huang Wei,et al.Image classification algorithm for deep belief network based on multi-feature fusion [J].Computer Engineering,2015,41(11):245-252.
[16] Li H,Wang F,Zhang S.Global and local features based topic model for scene recognition [C].Proceedings of IEEE International Conference on Systems,Man,and Cybernetics (SMC),2011:532-537.
[17] Song X,Jiang S,Herranz L.Joint multi-feature spatial context for scene recognition in the semantic manifold [C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2015:1312-1320.
[18] Oliva A,Torralba A.Building the gist of a scene:the role of global image features in recognition [J].Progress in Brain Research,2006,155(2):23-36.
[19] Lowe D G.Distinctive image features from scale-invariant keypoints [J].International Journal of Computer Vision (IJCV),2004,60(2):91-110.
[20] Bosch A,Zisserman A,Munoz X.Representing shape with a spatial pyramid kernel [C].Proceedings of the 6th ACM International Conference on Image and Video Retrieval (CIVR),2007:401-408.
[21] Oliva A,Torralba A.Modeling the shape of the scene:a holistic representation of the spatial envelope [J].International Journal of Computer Vision (IJCV),2001,42(3):145-175.
[22] Li Fei-fei,Fergus R,Perona P.Learning generative visual models from few training examples:an incremental Bayesian approach tested on 101 object categories [C].In:Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPRW),2004:59-70.
[23] Quattoni A,Torralba A.Recognizing indoor scenes [C].In:Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2009:413-420.
附中文参考文献:
[1] 杨 昭,高 隽,谢 昭,等.局部Gist特征匹配核的场景分类[J].中国图象图形学报,2013,18(3):264-270.
[2] 袁 杰,魏宝刚,王李冬.一种综合PHOG形状和小波金字塔能量分布特征的图像检索方法[J].电子学报,2011,39(9):2114-2119.
[7] 唐颖军.基于二次推导狄里克雷分布的图像场景分类模型[J].小型微型计算机系统,2015,36(11):2578-2582.
[14] 贾世杰,孔祥维,付海燕,等.基于互补特征和类描述的商品图像自动分类[J].电子与信息学报,2010,32(10):2294-2300.
[15] 许庆勇,江顺亮,黄 伟,等.基于多特征融合的深度置信网络图像分类算法[J].计算机工程,2015,41(11):245-252.
