面向短文本的跨领域情感分类算法
2018-07-04李鼎宇胡学钢
李鼎宇,胡学钢
(合肥工业大学 计算机与信息学院,合肥 230009)
1 引 言
短文本[15-18]数据的最大特点就是文本篇幅简短,通常在50词以内,包含的有效信息较少、特征稀疏且上下文依赖性强.虽然目前很多成功的情感分类技术[1,2]被提出,但都是针对长文本数据集的,直接用于短文本的分类效果并不理想.传统的情感分类要求源领域和目标领域属于同一领域且数据分布一致,而在实际应用中此假设难以成立.直接利用某一领域数据训练的分类器对不同领域的数据进行分类预测,由于领域之间数据的差异会使其分类精度降低.而重新对测试集进行大量标记,耗时费力且易出错.标记信息的缺失使得跨领域情感分类[9-12]成为一种有效的解决方法,同时也可称为迁移学习[3-5].
随着移动互联的发展,情感数据以短文本的形式呈现不断增长,且数据只有少量是标记的.面向短文本的跨领域情感分类成为一个新的而具有挑战的课题.然而,短文本数据在跨领域情感分类技术上存在一些难题:
1)短小而特征稀疏的数据特点:采用传统的词袋模型进行文本数据的特征表示时,特征稀疏性问题严重,使得其分类性能显著下降;
2)短文本中的多词同义和共现关系的缺少给跨领域情感分类带来挑战,主要表现在相同情感倾向的多种词汇表达会使短文本中特征的极性不显著,同时降低了作为领域间桥梁的共享特征和特有特征的共现频率,加大了领域间迁移的难度.
因此,本文提出一种面向短文本的跨领域情感分类算法.该算法基于谱图理论[6]、领域共享特征和特有特征的共现关系,利用谱聚类[7,8]依次对领域共享特征、特有特征进行聚类,根据所得的聚类信息进行特征扩展,特征扩展有效地降低了短文本的特征稀疏性,而源和目标领域的特有特征扩展可以减小领域间数据分布的差异,提升分类效果.大量实验表明:与同类算法相比,该算法可以有效提高跨领域短文本的情感分类准确率.
2 相关工作
目前,跨领域情感分类算法主要分为三类:基于特征的跨领域情感分类、基于主题模型的跨领域情感分类和基于极性的跨域情感分类.本文算法属于基于特征的跨领域情感分类.
2.1 基于特征的跨领域情感分类
基于特征的跨领域情感分类是该领域内的重要模型之一,主要通过特征映射的方式实现知识迁移.代表工作包括:Blitzer[9]等人提出SCL算法通过对辅助任务联合学习得到一个潜在特征空间,将不同领域的特征映射到该特征空间中减小领域间的差异从而进行分类.该算法非常依赖于这一潜在空间的质量,辅助学习任务的数量和质量,局限性显著.在此基础上,Pan[11]等人提出SFA算法以领域无关特征作为桥梁通过谱聚类将源和目标领域的独有特征映射起来,以此降低领域间特征分布的差异.Zhang[12]等人针对特征的一词多义和多词同义问题提出一种特征极性迁移算法TPF,以共享特征为桥梁,将原始领域中的特征极性通过该桥梁传递至目标领域,达到跨领域情感分类的目的,该算法一定程度上解决了特征极性的歧义问题.然而,上述的算法都是基于原始的特征空间实现知识迁移,容易出现特征稀疏问题且未考虑应用短文本数据,短文本的固有特点使得上述SCL,SFA和TPF中特征间的共现相对较少.同时,也会对领域间的知识迁移造成困难,降低算法的精度.
2.2 谱聚类
图论中的谱图理论已被广泛应用于降维和聚类分析等难题.在谱图理论中,主要有两种观点:
1)若图中的两个点连接到许多公共点,它们应该是非常相似的(或相当相关);
2)复杂的图形背后隐藏一个低维潜在空间.
其中,两个点彼此相似,那么在原始图中也是类似的.以上的观点对跨领域情感分类中特征间的共现关系同样成立,本文将在下一节详细介绍.谱聚类算法建立在谱图理论基础上,其本质是将聚类问题转化为图的最优划分问题,是一种点对聚类算法.该算法首先根据给定的样本数据集定义一个描述成对数据点的相似矩阵,并计算矩阵的特征向量,然后选择合适的特征向量聚类不同的数据点.谱聚类算法具有坚实的理论基础,并且在很多领域取得了成功应用.
3 面向短文本的跨领域情感分类

表1 常用符号及其含义Table 1 Common symbols and their meanings
该算法分为3个步骤:
1)在原始数据集上,对领域共享特征进行谱聚类,得到共享特征聚类簇.遍历数据集,对每一个实例的共享特征进行扩展;
2)在共享特征扩展后的数据集上,基于特征的共现关系对特有特征进行谱聚类特征扩展;
3)在扩展后新的特征空间,构建分类器,实现跨领域情感分类.
3.1 领域共享特征选择
首先,需要选择源和目标领域的共享特征.如上文所述,领域共享特征在源和目标领域都高频率出现且具有较强的情感极性.在SFA中基于词频和互信息列举了3种特征选择方法,3种特征选择方法在分类任务中各有优势,然而并没有较大的差异.本文先基于词频选取源领域和目标领域都至少出现k次的候选共享特征集,与SFA的特征选择方法1相同,保证候选共享特征在两个领域都具有较高的词频,然后用OR选取候选共享特征集中情感极性较强的特征作为领域共享特征,去除部分弱极性的特征.筛选后的领域共享特征与特有特征可以形成更简洁的共现关系.因此,选择领域共享特征如公式(1)所示.
ΦDI={DIi‖OR(DIi)>ε}
(1)
OR(DIi)=log(pipos(1-pineg)/pineg(1-pipos))
其中,ε表示能够在候选集中选择l个领域共享特征的最大值,pipos和pineg分别表示候选共享特征DIi在源领域正类和负类中出现的概率.
3.2 基于特征共现的谱聚类
基于上节所述,对于已经选定的领域共享特征和领域特有特征,可以构建图G=(VDS∪VDI∪VDT,E).在图G中,VDS的一个点对应源领域的一个特有特征,VDT的一个点对应目标领域的一个特有特征,VDI的一个点对应一个领域共享特征.此外,在E中的每一条边eij都有一个相关的非负权值mij,mij的值对应着共享特征DIi和特有特征DSj的共现次数.本文以MetaShare上的restaurant和laptops领域的简单例子说明,由图1可知,在三分图G中,领域的特有特征和共享特征的内在联系符合上述的谱图理论,而领域间数据分布的差异主要在于领域特有特征的不同.

图1 领域共享和特有特征关系三分图Fig.1 Tripartite graph of domain independent and specific features
本文认为,在基于特征共现的谱聚类中:
1)如果两个领域的特有特征和许多共同的领域共享特征共现,那么它们可能非常相关并被划分到相同类中;
2)谱聚类可以找到特征的一个更简洁和有意义的表示,减少两个领域的差异.如图1所示:特征never_work,still_wait有共同的特征hate,worst;类似的,特征very_light,delicious有共同的特征great,satisfied.因此,基于特征共现,特有特征never_work,still_wait可能极性相似并被划分到相同类中.同样,对very_light,delicious也成立.上述源和目标领域间特有特征的对齐,减小了领域间特有特征的不同.特征扩展可以有效降低文本的特征稀疏性,领域共享特征的扩展增强了文本的情感极性且提高了领域共享和特有特征的共现次数,有利于下一步的特有特征扩展.而基于特征共现的特有特征扩展,降低了领域间数据分布的差异.
进而,本文将说明在跨领域情感分类上如何对领域的特征聚类.首先,对领域共享特征进行谱聚类[5,6],因为在原始的数据集上,特征间的共现次数较少,不足以基于特征共现对共享特征进行谱聚类,而共享特征经常组合出现且都具有较高的词频,使其更适合基于自身进行谱聚类特征扩展.共享特征的特征扩展增加了源和目标领域特有特征和共享特征的共现次数.因此,可依据共享特征和特有特征的共现对特有特征进行谱聚类特征扩展.基于特征共现的谱聚类算法,具体如下:
1.构建权重矩阵M∈R(m-l)×l,其中Mij对应领域特有特征DSi和领域共享特征DIj的共现次数;
3.构建一个对角线矩阵:D,其中Dii=∑jAij,计算矩阵L=D-1/2AD-1/2;
4.找出L的k个最大特征向量,u1,u2,…,uk,选择前m-l行构建矩阵U=[u1,u2…uk]∈R(m-l)×k;

6.利用K-means聚类算法对U进行聚类,将m-l个领域特有特征聚成k类.
3.3 领域共享特征和特有特征的特征扩展
从短文本自身的稀疏性出发,基于上述得到的聚类信息,对领域共享和特有特征进行特征扩展,可以有效提高跨领域短文本的情感分类准确率.但是,在实验中完全正确地选择共享特征和基于特征的共现实现谱聚类特征扩展是不现实的.因此,本文算法的特征扩展权重计算采用均值法,如公式(2)所示:
(2)
其中,nclu为每个类中的特征数目,wi,wj是同一类中的特征,p(wi)和p(wj)是特征的权重.最后,本文提出的算法框架如下:
算法:面向短文本的跨领域情感分类算法

输出:分类器f:X→Y
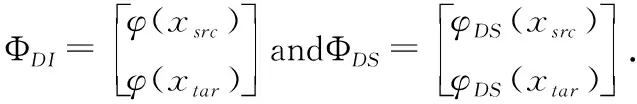
2.基于ΦDI构建领域共享特征的权重矩阵M∈Rl×l,其中Mij对应领域共享特征DIi和共享特征DIj的共现次数;
4.依据领域共享特征的聚类簇,对源和目标领域进行共享特征的特征扩展;
5.基于ΦDI和ΦDS构建领域特有特征的权重矩阵M∈R(m-l)×l,其中Mij对应领域特有特征DSi和领域共享特征DIj的共现次数;
7.依据领域特有特征的聚类簇,对源和目标领域进行特有特征的特征扩展;
4 实验结果与分析
4.1 实验数据集
本文的实验数据:短文本数据集MetaShare*http://metashare.ilsp.gr:8080/repository/search和文[11,12]中的亚马逊数据集RevDat.数据集MetaShare来自国外的数据交流共享平台Meta-Share,包括laptop(L)、movies(M)和 restaurant(R)三个不同领域的评论,每个领域有1000个正类和1000个负类.在该数据集上可以构建L->M,L->R等6个跨领域情感分类任务,前面的字母代表源领域,后面的字母代表目标领域.数据集RevDat被广泛用于跨领域情感分类中,包括四种不同类型的产品评论:Books(B),DVDS(D),Electronics(E)和 Kitchen (K).每个领域有1000个正类和1000个负类.在该数据集上可以构建12个跨领域情感分类任务.
借鉴文[13,14]的短文本数据预处理方法,本文所使用的短文本数据集,都进行了Bi-gram处理,采用词袋模型并在分类前对每一个实例标准化.关于实验数据集的具体描述见表2.
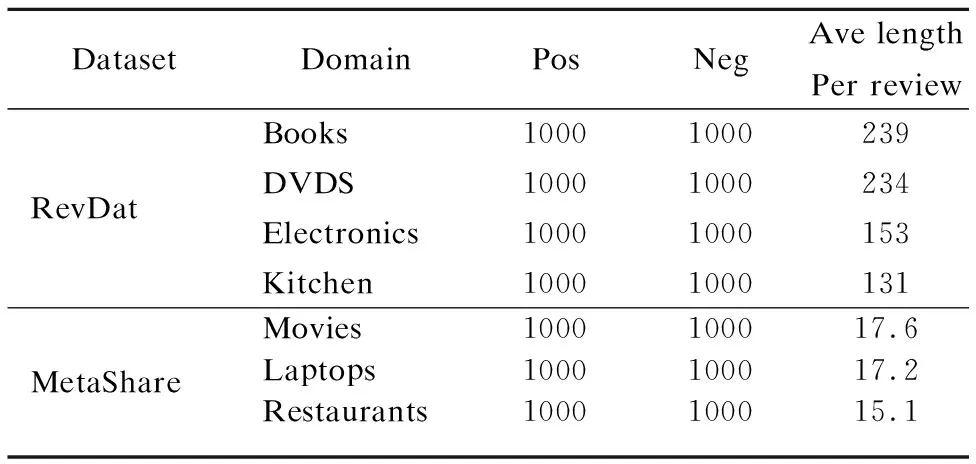
表2 数据集RevDat和MetaShare说明Table 2 Dataset description:RevDat and MetaShare
为了说明本文算法的有效性,本文采用如下的基准算法进行对比.
1)NoTransf:源领域训练的分类器,直接用于目标领域分类.
2)SCL:构建枢纽特征,并利用枢纽特征构建2个领域特征间的映射关系.
3)SFA:基于特征的共现关系,通过谱聚类将源和目标领域的领域独有特征映射起来,以此降低领域间特征分布的差异.
4)TPF:以共享特征为桥梁,将原始领域中的特征极性通过该桥梁传递至目标领域,使目标领域专有特征具有极性标注,从而进行分类.
4.2 参数讨论
下面我们讨论本文参数的最优值,领域共享特征的数目m,领域共享特征和领域特有特征的谱聚类参数kDI,kDS,为了简明起见,图中的分类精度以数据集MetaShare上的所有情感分类任务为标准,展示实验结果和参数的相关关系.领域共享特征数目m在算法中是一个重要参数,我们固定kDI=0.4,kDS=0.5,给出在不同m下的分类任务的精度.由图2可知:领域共享特征的最优值m在[250,350]时,分类任务达到最好的精度,m过小,则容易导致共现矩阵稀疏;m过大,则领域共享特征情感倾向不强.因此,本文将m设为300.

图2 不同共享特征数目下的分类精度Fig.2 Accuracy of varying with the number of independent features
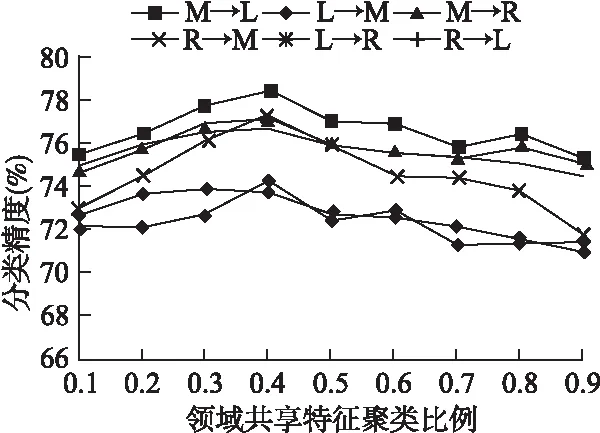
图3 不同共享特征聚类比例下的分类精度Fig.3 Accuracy of varying with clustering proportion of independent features
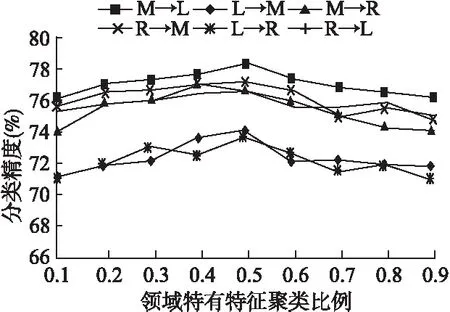
图4 不同特有特征聚类比例的分类精度对比Fig.4 Accuracy of varying with clustering proportion of specific features
kDI,kDS是关于领域共享特征和领域特有特征的谱聚类比例参数,它们的取值范围是(0,1).固定m=300,kDS=0.5,分类任务的精度随参数kDI的变化情况如图3所示:当kDI在0.4左右,实验效果最好.最后,图4给出分类任务的精度随参数kDS的变化情况,其中m=300,kDI=0.4,当kDS在0.5左右,实验效果最好.
4.3 跨领域情感分类精度对比
为了证明本文算法的有效性,将本文的算法与基准算法分别在数据集MetaShare和数据集RevDat上进行对比.图5是在MetaShare上的各算法的实验精度对比.从实验结果可知:本文算法在MetaShare上分类精度相对其他基准算法有2%-4% 的提升.分析原因如下:Notransf,SCL,SFA和TPF算法都是基于特征层面,容易受文本稀疏性影响.而TPF在一定程度上解决了源领域和目标领域的特征极性分歧问题,在若干分类任务中要优于SFA算法,但TPF对领域间特有特征的极性迁移同样依赖于特征间的共现关系.与TPF算法相比,本文算法对领域特征间的共现关系进行了分析,并通过特征扩展提高特征间的共现次数,减少了领域间数据分布的差异,在一定程度上解决了短文本的稀疏性,在短文本分类精度上具有很大的优势.
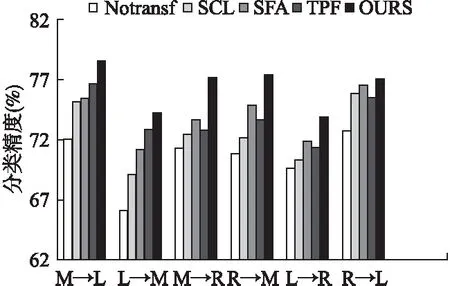
图5 MetaShare上分类精度对比Fig.5 Comparison results on MetaShare
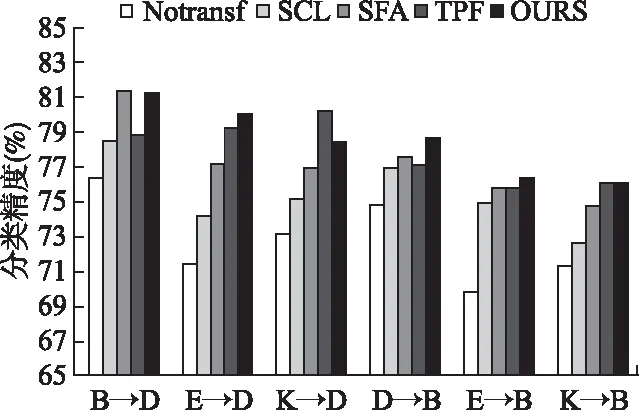
图6 目标领域为D或B时分类精度对比Fig.6 Comparison results when target domain is D/B

图7 目标领域为E或K时分类精度对比Fig.7 Comparison results when target domain is E/K
图6和图7是在亚马逊数据集RevDat上各算法的实验精度对比,与SFA一致,领域共享特征数m=500,共享和特有特征的谱聚类输入参数分别为kDI=0.4,kDS=0.5.对于所有的基准算法,参数设置以算法最优为准.由实验结果可知:本文所提算法在其中的6个任务都优于基准算法,这是因为在长文本中同样也存在数据稀疏的问题,而本文所提算法可以有效地降低文本特征的稀疏性.与SFA相比,本文算法的精度在B->D,D->K和E->K三个任务中低于SFA,其主要原因是领域间的特征共现次数充分,不需要过多的特征扩展.与TPF相比,本文算法的精度在 K->D,K->B,D->E和D->K四个任务中低于TPF,其主要原因是在这些任务中,领域间的特有特征存在较多的极性分歧问题.
5 总 结
本文基于谱图理论提出一种在短文本上的跨领域情感分类算法.该算法利用领域共享特征和特有特征的共现关系进行谱聚类特征扩展,弥补短文本的特征稀疏性,降低了域间数据分布的差异,从而提升跨领域情感分类在短文本上的适应性和效果.大量实验表明:本文提出的算法分类效果优于基准算法.
然而本文仅考虑了短文本情感数据,未来的工作可从以下几点展开:
1)除了情感数据,目前还有很多其他类型的短文本数据,如可在短文本上进行主题模型迁移学习;
2)在针对短文本数据特征稀疏性的同时,解决跨领域特有特征的极性分歧问题.
:
[1] Pang B,Lee L.Opinion mining and sentiment analysis [J].Foundations and Trends®in Information Retrieval,2008,2(1-2):1-135.
[2] Liu B,Zhang L.A survey of opinion mining and sentiment analysis [M].Mining Text Data,Springer US,2012:415-463.
[3] Bahadori M T,Liu Y,Zhang D.A general framework for scalable transductive transfer learning [J].Knowledge and Information Systems,2014,38(1):61-83.
[4] Pan S J,Yang Q.A survey on transfer learning [J].IEEE Transactions on Knowledge and Data Engineering,2010,22(10):1345-1359.
[5] Weiss K R,Khoshgoftaar T M.An investigation of transfer learning and traditional machine learning algorithms [C].Tools with Artificial Intelligence (ICTAI),2016 IEEE 28th International Conference on IEEE,2016:283-290.
[6] Chung F R K.Spectral graph theory [M].American Mathematical Soc,1997.
[7] Ng A Y,Jordan M I,Weiss Y.On spectral clustering:analysis and an algorithm [C].Advances in Nural Information Processing Systems (NIPS),2001,14(2):849-856.
[8] Von Luxburg U.A tutorial on spectral clustering [J].Statistics and Computing,2007,17(4):395-416.
[9] Blitzer J,McDonald R,Pereira F.Domain adaptation with structural correspondence learning [C].Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing,Association for Computational Linguistics,2006:120-128.
[10] Blitzer J,Dredze M,Pereira F.Biographies,bollywood,boom-boxes and blenders:domain adaptation for sentiment classification [C].Association of Computational Linguistics (ACL),2007,7:440-447.
[11] Pan S J,Ni X,Sun J T,et al.Cross-domain sentiment classification via spectral feature Alignment [C].Proceedings of the 19th International Conference on World Wide Web,ACM,2010:751-760.
[12] Zhang Y,Hu X,Li P,et al.Cross-domain sentiment classification - feature divergence,polarity divergence or both? [J].Pattern Recognition Letters,2015,65:44-50.
[13] Thelwall M,Buckley K,Paltoglou G,et al.Sentiment strength detection in short informal text[J].Journal of the American Society for Information Science and Technology,2010,61(12):2544-2558.
[14] Wang S,Manning C D.Baselines and bigrams:simple,good sentiment and topic classification [C].Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics:Short Papers-Volume 2,Association for Computational Linguistics,2012:90-94.
[15] Song G,Ye Y,Du X,et al.Short text classification:a survey [J].Journal of Multimedia,2014,9(5):635-643.
[16] Pak A,Paroubek P.Twitter as a corpus for sentiment analysis and opinion mining[J].Springer, New York, NY,DOIhttps://doi.org/10.1007/978-1-4614-6170-8,2010.
[17] Gao L,Zhou S,Guan J.Effectively classifying short texts by structured sparse representation with dictionary filtering [J].Information Sciences,2015,323:130-142.
[18] Wang M,Lin L,Wang F.Improving short text classification through better feature space selection [C].Computational Intelligence and Security (CIS),2013 9th International Conference on.IEEE,2013:120-121.
