虚拟内存密集型多线程程序的性能改进方法
2018-07-04陈健康
陈健康,张 昱
(中国科学技术大学 计算机科学与技术学院,合肥 230027)
1 引 言
随着多核处理器越来越普及,基于共享内存的多线程程序被大量地开发出来.其中,虚拟内存密集型多线程程序作为常见的一类多线程应用而大量存在;主要特征是存在大量而且频繁的地址空间操作[1].这些地址空间操作主要包括page faults 和 mmap、munmap等系统调用.由于多线程共享地址空间,为了保证这些并发地址空间操作的正确性,Linux系统使用一个全局读写锁(mmap_sem)来同步这些操作.然而,mmap_sem会串行化page faults 和内存映射操作.对于虚拟内存密集型程序,在高并发时,线程串行执行地址空间操作将会导致这类程序性能下降.
目前,一种比较好的解决方案是使用更加高效的锁来替换该全局读写锁.Clements等人就使用了并发性更加好的Read-Copy-Update(RCU)锁来替换该读写锁[1],但是这种解决方案并不能完全消除应用的地址空间竞争.另外一些解决方案是将具有共享地址空间的多线程修改为具有私有地址空间的多进程,例如Psearch(来自MOSBENCH[2]的应用),但是将应用从多线程修改为多进程通常是比较困难的.
本文提出了一个性能和扩展性较好的线程模型PMthreads.PMthreads采用线程地址空间隔离的策略,能够完全消除多线程竞争mmap_sem.然而,线程地址空间隔离却引起了如下三个问题:无法保持共享变量、现有堆分配器无法适用、无法直接支持Pthreads接口.通过自定义字符设备驱动轻量级更改Linux内核中进程全局数据区域,PMthreads保持线程共享全局变量;通过设计实现IAmalloc堆分配器,PMthreads保持了堆变量的共享并且避免分配上的竞争;通过在隔离栈空间的线程模型上实现同步算法并支持Pthreads接口,Pthreads程序可以无修改的使用PMthreads.
在32核机器上,本文使用PARSEC[3]和Phoenix[4]中的5个程序,来评测PMthreads和Pthreads的性能和可扩展性,其中包括两个虚拟内存密集型程序:histogram以及dedup.
本文主要贡献如下:
· 详细分析了虚拟内存密集型多线程程序在共享地址空间上存在性能瓶颈的原因.
· 提出了一个基于隔离地址空间的线程模型,可以完全消除线程在mmap_sem上的竞争,同时可以保持线程共享变量.
· 实现了原型系统PMthreads:以自定义字符设备驱动轻量级修改Linux内核中进程的全局数据区域来保持线程共享变量;以设计和实现IAmalloc堆分配器来保持共享堆变量的分配和释放;以实现同步算法并支持Pthreads接口,Pthreads多线程应用可以无修改地调用PMthreads.
· 使用了5个应用评估比较PMthreads和Pthreads的性能.对于虚拟内存密集型应用histogram和dedup,实验结果表明,在32线程时PMthreads相对于Pthreads性能提升了2.17倍和3.19倍;在16线程时,非此类应用的linear_regression也因削减假共享获得8.15倍性能提升.
本文其余部分的组织如下:第2节是问题分析与基本知识;第3节是线程模型特征介绍.第4节是相关难点的实现.第5节是实验和分析.第6节将会对全文进行总结.
2 基本知识与问题分析
2.1 Linux地址空间组织
Linux中多线程共享父进程的地址空间.进程的地址空间主要是由大量的内存映射区域组成,例如栈区域、代码段区域等.Linux内核以一个称之为内存描述符的数据结构(mm_struct)来表示一个进程的地址空间及其映射.mm_struct主要通过两种结构来保存这些内存映射区域:一个是红黑树,红黑树的主要目的是为了能够快速地通过地址找到对应的内存映射区域.另外一个是内存区域映射链表,如图 1 所示,其中的VMAs list就是管理所有内存映射区域的内存映射链表.

图1 Linux 地址空间组织结构Fig.1 Address space structure of Linux
Linux中,每一个内存映射区域(VMA)都是通过一个vm_area_struct结构来描述.如图1所示,在内存映射链表中的每一个VMA中,vm_start代表了该内存映射区域的起始地址,而vm_end代表了该内存映射区域的结束地址.除此之外,VMA中还包括该内存映射区域的读写和映射属性的相关信息.
2.2 地址空间操作及其同步
操作系统提供了mmap、munmap(统一称之为内存映射操作)以及page faults等地址空间操作:page faults负责分配物理页面和建立对应该页面的页表项.mmap系统调用主要是从虚拟内存区域中分配一个空闲的地址空间段.随后mmap将该地址空间段的VMA插入到mm_struct所管理的映射链表中;munmap操作从映射链表中删除一个内存映射区域,并且撤销页表中相关的页表项.
多个线程会触发page faults以及并发调用内存映射操作.为了保证执行正确性,Linux操作系统采用一个全局读写锁mmap_sem(如图1)来同步这些并发操作.在执行内存映射操作之前,线程需要作为写者来竞争mmap_sem,多个写者必须串行执行.page faults会作为读者来竞争mmap_sem,并且同一时刻可以允许多个读者一起获得该锁.当mmap作为写者获得mmap_sem的时候,其会阻塞读者获得该锁.此外,当多个page faults作为读者获得锁时,写者必须陷入睡眠,直到所有读者都完成操作之后写者才可以获得该锁.
2.3 虚拟内存密集型程序性能瓶颈分析
虚拟内存密集型多线程程序是非常重要的一类多线程程序.这类应用的主要特征是包含大量的地址空间操作.例如应用频繁地触发page faults,或者应用包含频繁而且大量的堆分配操作导致应用频繁地调用内存映射操作.然而,全局读写锁mmap_sem将串行化page faults和内存映射操作,并且多个内存映射操作之间也必须串行执行,例如mmap、munmap之间必须串行执行.对于虚拟内存密集型多线程应用,这种串行化将极大地限制应用的性能和可扩展性.

图2 应用histogram 中mmap_sem开销Fig.2 Mmap_sem overhead in histogram
图2是测试的虚拟内存密集型程序histogram中mmap_sem开销占总执行时间的比重.当超过8核时,mmap_sem引起的开销不断增加,在32核的时候更是达到了总运行时间的49.32%.所以对于虚拟内存密集型多线程程序,在高并发时全局读写锁mmap_sem将导致应用极大的性能下降.本文主要致力于解决该问题.
2.4 Pthreads线程模型
Pthreads是基于共享地址空间实现的、广泛使用的多线程编程模型.和进程相比,Pthreads可以保持多线程共享变量.同时Pthreads也提供了一些编程接口,使得用户可以管理共享内存.
如图3所示,图左边代表Pthreads线程模型.从图中可以看到线程T1和T2拥有共享的地址空间,并且在共享地址空间中,线程T1和T2各自拥有独立的栈空间.地址空间中每一个内存区域映射的物理内存都属于进程私有.线程T1和T2通过共享的内存描述符来访问这些物理内存,以达到共享内存的目的.线程T1和T2会并发执行内存映射操作,用于分配或者删除内存映射区域,同时线程T1和T2也会触发page faults来分配物理页面.

图3 两种线程模型对比Fig.3 Comparing the two kinds of thread models
然而,如2.2和2.3分析可知,当T1和T2大量并发执行内存映射操作以及触发page faults时,Pthreads多线程程序必然会因为共享地址空间而引起性能下降.对于虚拟内存密集型应用来说,这种性能下降更加明显.
3 PMthreads线程模型特征
本节首先讨论PMthreads线程模型的特征.其中,本文将讨论PMthreads线程地址空间隔离的特征,以及PMthreads线程共享变量的原理.最后本节将讨论实现难点.
3.1 PMthreads线程模型
3.1.1 线程地址空间隔离
为了完全避免线程竞争地址空间,本文采用隔离地址空间的做法,从而使线程拥有各自独立的地址空间.当线程调用内存映射操作和触发page faults时,并不会和其他线程产生任何竞争.如图3,图右边代表PMthreads线程模型.线程T1和线程T2各自拥有私有的地址空间.当线程T1和T2并发地执行内存映射操作和page faults的时候,T1和T2仅仅会在自己的私有地址空间上执行操作.因此,线程之间并不需要竞争mmap_sem读写信号量,同时这种隔离地址空间天然地保证了线程私有栈特征,如图3所示.
3.1.2 线程共享变量
在通过Pthreads运行的多线程应用中,多线程共享主线程的全部地址空间.多线程主要包括两种共享变量,一个是共享的全局变量,另外一个是共享的堆变量.一个线程在这些共享变量上修改以后,修改后的数据可以立即被其他的线程所见,并且代码也是线程重要的共享数据.
地址空间隔离导致线程无法通过共享内存描述符来共享内存.为了保证线程可以共享全局变量、堆变量、代码,如图3虚线框key所示,PMthreads将这些虚拟内存区域映射到共享的物理内存.当调用fork创建子线程的时候,子线程的虚拟内存相关区域也可以映射到对应的物理内存中.
3.2 地址空间隔离引起的问题以及实现难点
无法保持共享变量:每一个进程的全局数据区域都是被映射到一个私有可写的文件.为了完全消除地址空间竞争,PMthreads给每一个线程一个隔离的地址空间.然而,由于私有文件映射特征,地址空间隔离将导致线程执行写时复制(copy-on-write),而产生私有的物理内存.因此无法保持PMthreads线程共享全局数据.为了保持线程共享全局变量,PMthreads提供了共享的物理内存.但是,Linux内核通过一个VMA来管理进程的全局数据区域.因此,必须修改内核中相关数据结构才能保证共享全局变量.本文需要在不做太多Linux内核改动的前提下,确保线程共享全局数据区域的物理内存.
现有堆分配器无法适用:同样,共享的堆变量是基于共享内存的多线程进行线程通信的一类重要的共享变量.在Pthreads线程模型中,线程通过堆分配器在地址空间上进行共享堆变量的空间分配.然而,在PMthreads中,由于线程具有私有的地址空间,现有的堆分配器具有两方面限制:一方面是现有堆分配器仍然从私有地址空间中分配内存,例如mmap分配一个私有chunk,无法保证堆变量在线程之间共享.另一方面是堆分配器本身具有大量的共享数据结构,这些共享数据结构(堆初始化时mmap分配)将因为地址空间隔离而私有化.因此本文提供了IAmalloc堆分配器,以解决现有堆分配器无法适用PMthreads的问题.
无法支持Pthreads接口:Pthreads多线程程序往往需要调用许多同步管理接口,用于多线程间的同步操作.这些接口包括:互斥量、条件变量、barrier等.Pthreads底层实现这些互斥量、条件变量、barrier算法时,需要采用全局数据和共享栈数据.但是PMthreads线程地址空间完全隔离,导致线程无法共享栈数据.因此,为了保证Pthreads应用可以无修改地被支持,本文在PMthreads上实现了互斥量、条件变量以及barrier算法,并保持和Pthreads相关接口与语义的一致.
4 PMthreads线程模型
本节主要讨论PMthreads的实现.首先本讨论如何实现共享变量;其次将讨论IAmalloc堆分配的特点及其实现;最后讨论PMthreads如何支持Pthreads接口.
4.1 共享变量实现
4.1.1 全局变量共享
Linux内核仅仅使用一个VMA来管理一个进程的全局数据区域.通过VMA中的相关标识,Linux内核确定一个进程的全局数据区域是一个私有可写的内存映射区域.同时该VMA记录了可执行文件的描述符,来确定进程全局数据区域是一个私有可写的文件映射.为了确保被隔离地址空间的线程能够共享全局变量,PMthreads采用共享文件映射策略.但是,这需要将PMthreads线程的全局数据区从私有文件修改为共享文件映射.因此,内核中进程全局数据区域的VMA必须要修改.然而,直接修改Linux内核并不是一个可以被广泛使用的方式.因此本文通过实现一种了字符设备驱动来完成修改工作.用户仅仅需要将该模块安装到他们自己的内核中,而不需要修改内核.
该字符设备驱动拦截了write系统调用.当应用开始执行的时候,在主函数之前,线程会调用该write系统调用.通过传入的主线程的PID以及设备驱动号,该系统调用会将主线程的PID传入对应的设备驱动.设备驱动随后会查找到主线程得的mm_struct,将主线程的全局数据区域由私有文件映射修改为共享文件映射.不同线程可以通过共享文件映射达到共享全局数据区域的物理内存的目的.
4.1.2 共享代码段特征
在PMthreads中每一个线程拥有独立的地址空间,并且每一个线程的代码段是只读的内存映射区域.对于只读映射区域的物理内存,PMthreads中的多线程可以直接共享.
4.2 共享堆分配器
为了保证多线程进行正常的动态内存分配,本文设计了一个堆分配器,称为IAmalloc,可以直接适用于PMthreads.IAmalloc主要解决如下几个问题:首先,在隔离地址空间的线程之间,如何共享堆变量;其次,IAmalloc如何保证高效的堆分配;最后,IAmalloc如何保证线程释放堆空间中的任何变量.
堆变量共享:如图3,每一个线程的地址空间都包含一个固定大小的内存映射区域作为堆区域.该区域是一个匿名共享映射区域.当PMthreads初始化时,该区域由主线程调用mmap系统调用创建.多进程可以共享匿名共享映射区域的物理内存.虽然PMthreads线程位于隔离的地址空间,但是线程之间通过此匿名共享映射区域可以保持堆变量共享.
堆分配效率提升:堆分配器的效率是一个影响应用性能和可扩展性的重要因素.在频繁进行堆分配的应用中,高效的堆分配器能够极大地提高应用的性能.为了保证堆分配效率,IAmalloc将整个堆空间分成了若干个子堆.每一个线程会占有一个子堆,并且规定每一个线程仅仅被允许在自己的子堆中分配堆空间.因此,IAmalloc并没有使用任何锁保护分配.这有两方面的好处,一方面是消除了堆变量分配重叠的严重错误;另一方面,当线程从子堆中分配的时候,线程并不需要竞争性地获得堆空间.虽然采用子堆策略,但是线程仍然可以访问所有线程的子堆.这种子堆策略能够极大地提高上层应用分配堆空间的效率.
释放规则和堆算法:IAmalloc将堆释放进行了加锁处理,以保证线程可以释放其他线程子堆中的堆变量.同时,为了保证释放时的性能,IAmalloc仅仅在子堆上进行细粒度锁处理.IAmalloc的分配和释放算法来自dlmalloc[6].*http://gee.cs.oswego.edu/dl/html/malloc.html
4.3 同步算法和接口支持
在大量的Pthreads应用程序中,仅仅使用两类常用接口:一类是线程管理相关接口,一类是同步相关接口.其中同步相关接口,主要有三种,分别是互斥量、条件变量以及barrier.为了保证不用修改应用代码,PMthreads对这些接口进行了实现支持.
4.3.1 线程管理
由于PMthreasds采用隔离地址空间的做法,所以在PMthreads中,pthread_create通过调用fork系统调用来实现轻量级进程的创建,并且PMthreads给每一线程一个确定的ID号.在pthread_join中,我们通过waitpid来等待线程.
4.3.2 同步算法和接口
PMthreads将同步变量(互斥量、条件变量、barrier)中的数据结构进行重新设计和组织.在初始化同步变量时,其关键的共享数据将会被组织在共享的堆中.例如,PMthreads采用睡眠唤醒的同步策略,因此在堆中每一个同步变量都将会被包含一个共享的睡眠队列.在此基础上,PMthreads实现了同步算法.
其中,互斥量和barrier算法来自[7],对于条件变量算法本文采用[9]中的算法.基于这些同步算法,PMthreads实现了Pthreaads中的互斥量、条件变量以及barrier管理接口.Pthreads多线程应用可以不经过任何修改地调用PMthreads.
5 实验评估
5.1 实验平台和实验方法
我们在4×Intel Xeon E7-4820处理器(总共为32核)、128GB内存的64位Ubuntu 12.04(内核版本为3.2.0)上测试,所有程序用gcc-4.4.7编译,glibc为glibc-2.15.每一个核数上仅仅运行一个线程,所以下文全部采用核数代表线程数.

表1 测试程序特征和数据集合Table 1 Workloads feature and dataset
表1给出了测试程序和相应的数据集,并且本文也评测了在应用中发生的malloc的总次数.除了 dedup 外,其他均是 Phoenix 提供的测试程序.对于实验的每个测试程序,我们收集了它 10 次运行的时间,并去掉最大值和最小值,将剩下 8 个的平均值作为程序的运行时间[10].其中,histogram 和 dedup属于虚拟内存密集型程序,其他是普通程序.
5.2 性能结果分析
图4显示了在不同核数上运行测试程序时,原Pthreads版本相对于PMthreads版本的执行时间对比.从图4中可以看出来,mm 和 sm 在两种线程模型上的执行性能相当;当在32核时,hist在PMthreads上执行速度是Pthreads上的2.17倍.同时在32核上,dedup在PMthreads上性能提升了3.19倍.除了单核以外,lr的性能在其他核数上都有所提升,并且在16核上,性能提升了8.15倍.
mm 和 sm这两个应用程序都不属于虚拟内存密集型程序,一方面这两个应用在多核下没有较多的物理内存开销,其次在多核下并没有多线程调用大量的mmap或者mprotect等等.由于PMthreads采用隔离地址空间,在创建线程上开销要比Pthreads要多,但是在一些耗时较多的计算密集型应用上,例如mm和sm等应用,PMthreads的开销几乎不会有较多的影响,因此mm和sm会有相当的性能.
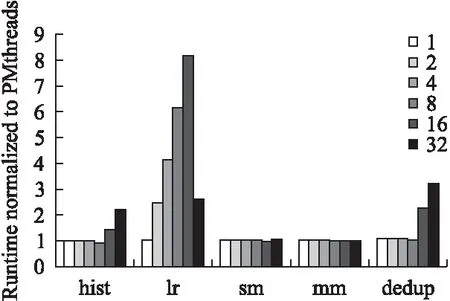
图4 原Pthreads 程序相对于PMthreads版本的时间开销Fig.4 Runtime overhead of Pthreads relative to the PMthreads
5.3 可扩展性展示
图5给出了测试程序在Pthreads上和PMthreads上的可扩展性对比,其中p代表应用运行在Pthreads下,pm代表应用运行在PMthreads下.从图中可以看出,对于dedup,从8核开始dedup-p加速比不断地下降.而对于dedup-pm,其加速比

图5 应用程序相比于单核时的并行加速比Fig.5 Parallel speedup over its own single-CPU
在不断地上升.对于histogram应用,hist-p从16核开始加速比不断地下降,到32核下降最明显.然而,hist-pm从1核到32核加速比在不断地上升.对于应用linear_regression,在Pthreads线程模型下,其加速比几乎没有提升,而在PMthreads线程模型下,其加速比在不断地上升.在string_match和matrix_multiply上PMthreads和Pthreads表现出了相当的加速比.
5.4 虚拟内存密集型程序性能分析
在这些测试应用中,histogram和dedup属于比较常见的虚拟内存密集型应用.接下来,本文给出关于这两个虚拟内存密集型应用的详细性能分析,以证明PMthreads可以提高这类应用的性能.
5.4.1 histogram 应用
histogram是一个来自于Phoenix的重要的数据并发应用.其主要是将一张图片的红绿蓝的像素的数量形成一个柱状比例,其中所有的数据的空间全部由主线程从堆中分配.本文评估了histogram的物理内存的消耗,实验结果展示其在32核的时候有将近1.4GB的物理内存的开销.大量的物理内存开销将导致频繁的page faults.为了测试histogram性能提升的主要原因以及histogram的Pthreads版本性能损失的主要原因,本文通过Linux perf工具测试了热点函数的分布情况.
histogram在Pthreads线程模型下,其热点函数是dead_read_trylock()和up_read(),这两个函数全部来自于Linux内核.图6,Pthreads版本的结果显示随着核数增加,两个函数的开销也在不断地增加;而且,在32核的时候分别达到了总运行时间的30%和20%.对于PMthreads版本,这两个热点函数的开销在所有的核数下全部低于0.5%.随后,本文检查了这两个热点函数的调用路径,这两个函数全部来自于page faults处理函数中.其中down_read_trylock用于读竞争读写信号量mmap_sem.up_read用于释放该读写信号量.在Pthreads下,虽然是读竞争,由于线程共享读写锁导致处理器需要不断进行cache 一致性处理,引起较大开销;而PMthreads隔离了地址空间,产生私有的读写锁,因此,线程并不会发生竞争.所以,PMthreads在削减信号量竞争上具有很好的效果.
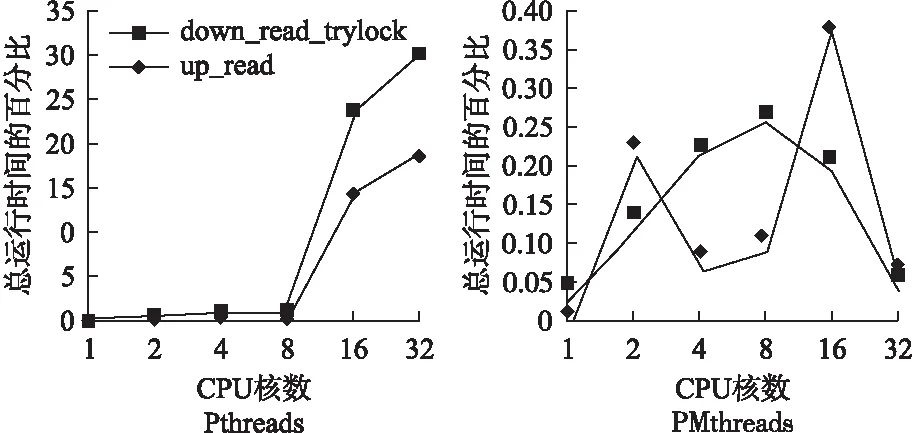
图6 histogram 热点函数开销Fig.6 Hot function overhead of histogram
从图6中可以看出PMthreads在down_read_trylock和up_read上呈现出不规则的结果,这两个函数全部来自于page faults中,由于PMthreads采用私有地址空间的策略,所以每一个线程的地址空间都存在上下文切换,在测试时候存在一些误差.但是,在这两个函数上的开销则全部非常的低.
5.4.2 dedup应用
这是一个来自PARSEC中的应用,这个应用结合着局部压缩和和全局压缩对数据进行充分的压缩.本文中所有的针对该应用的实验都使用的是large类型的数据集合.如表1所示,该应用使用了大量的堆空间和进行了非常频繁的堆分配,该应用是一个典型的虚拟内存密集型应用[1].
为了查找该应用性能提升的根本原因,我们也使用perf来检测该应用在PMthreads和Pthreads不同模型下执行时候的热点函数的开销.实验结果显示,在Pthreads模型下,dedup的热点函数是一个来自内核中的自旋锁__ticket_spin_lock;并且在32核CPU下,其开销占了总运行时间的24.7%,如图6所示;而在PMthreads中运行的情况显示,该函数的开销全部都在2.37%以下.同样,我们查找了该函数的调用栈信息.
调用栈信息显示,__ticket_spin_lock是一个内核中函数,其主要是被函数rwsem_down_failed_common调用.该函数主要来自两个方面,一个是系统调用mmap等,另外一个是page faults.当执行page faults或者mmap竞争mmap_sem失败的时候,线程会调用该函数进入共享队列中睡眠.所以,可以得出结论,dedup的Pthreads版本在执行时对读写信号量mmap_sem的竞争是dedup开销的重要一方面.这也证明PMthreads的隔离地址空间策略极大地降低了线程对地址空间的竞争,应用由此获得了性能提升.
5.5 其他方面性能收益
linear_regression是一个针对给定点集合的线性回归计算的应用.该应用需要频繁地更新代表线性回归的变量.我们通过perf给出linear_regresson在两种不同模型下的L1缓存的load miss率和store miss的比值情况.如图8所示,在Pthreads下load miss率最高是PMthreads下的8倍,store miss 率最高达到了52倍.所以,该应用极端差的可扩展性是由于需要不断进行L1级cache的一致性处理.
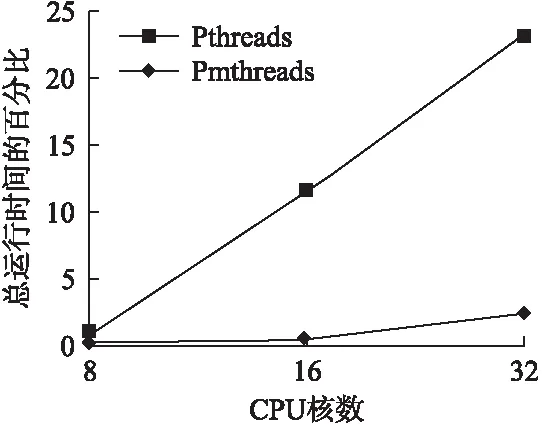
图7 dedup应用中ticket_spin_lock开销Fig.7 Ticket_spin_lock overhead of dedup

图8 L1 cache miss 率的比值,Pthreads比PMthreadsFig.8 Ratio of L1 cache miss rate,Pthreads/PMthreads
随后,我们观察了应用本身的特征.应用的计算结果被保存在一个共享的结构体数组中,每一个线程会将计算的结果更新到数组中的对应元素中.但是由于堆分配的特征导致该结构体数组的地址并未按64B对齐,导致产生假共享.所以,当线程频繁地更新结构体中元素时,必然会产生大量的缓存一致性问题.但是,在PMthreads中,由于对堆分配的地址进行了处理,所以并不会发生假共享的情况;从而PMthreads减少了cache一致性处理,提高了应用的性能和可扩展性.这是堆分配器带来的额外的性能提升.
6 总 结
本文首先分析了由共享地址空间引起的虚拟内存密集型应用的性能瓶颈问题.随后,本文给出了基于地址空间隔离的线程模型来提升应用性能.最后对比了两个线程模型在虚拟内存密集型应用上的性能特征.实验结果表明PMthreads可以极大的提升虚拟内存密集型程序性能.然而,IAmalloc堆分配器分配不均衡,以及PMthreads需要支持更多的Pthreads接口.这些都是亟待解决的问题.
:
[1] Austin T Clements,Frans Kaashoek M,Nickolai Zeldovich.Scalable address spaces using RCU balanced trees[C].In Proceedings of the Seventeenth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS XVII),ACM,New York,NY,USA,2012:99-210.
[2] Boyd Wickizer S,Clements A T,Mao Y,et al.An analysis of Linux scalability to many cores[C].USENIX Symposium on Operating Systems Design and Implementation(OSDI′10),2010,10(13):86-93.
[3] Christian Bienia,Sanjeev Kumar,Jaswinder Pal Singh,et al.The PARSEC benchmark suite:characterization and architectural implications[C].In Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques (PACT′08),ACM,New York,NY,USA,2008:72-81.
[4] Ranger C,Raghuraman R,Penmetsa A,et al.Evaluating mapreduce for multi-core and multiprocessor systems[C].In High Performance Computer Architecture(HPCA 2007),IEEE 13th International Symposium on.Ieee,2007:13-24.
[5] Weaver,Vincent M.Linux perf_event features and overhead[C].The 2nd International Workshop on Performance Analysis of Workload Optimized Systems,FastPath,Vol.13,2013.
[6] Lea D.A memory allocator[EB/OL].http://gee.cs.oswego.edu/dl/html/malloc.html,2000.
[7] Ulrich Drepper.Futexes are tricky[C].In Futexes are Tricky,Red Hat Inc,Japan,December,2005.
[8] Kai Lu,Xu Zhou,Tom Bergan,et al.Efficient deterministic multithreading without global barriers[C].In Proceedings of the 19th ACM SIGPLAN Sym,Posium on Principles and Practice of Parallel Programming (PPoPP′14),ACM,New York,NY,USA,2014:287-300.
[9] Birrell A.Implementing condition variables with semaphores[C].In Computer Systems Theory,Technology,and Applications,2004:29-37.
[10] Cao Hui-fang,Zhang Yu.Exploring the programmability and implementation performance for a deterministic multithreaded programming model[J].Journal of Chinese Computer Systems,2016,37(6):1126-1131.
附中文参考文献:
[10] 曹慧芳,张 昱.确定性多线程编程模型的可编程性及其实现性能的探索[J].小型微型计算机系统,2016,37(6):1126-1131.
