利用Copeland社会选择理论的在线商品群体评价
2018-07-04付晓东刘利军
殷 岩,付晓东,2,刘 骊,岳 昆,刘利军,冯 勇
1(昆明理工大学 信息工程与自动化学院,昆明 650500)
2(昆明理工大学 航空学院,昆明 650500)
3(云南大学 信息学院,昆明 650091)
1 引 言
随着电子商务和电子服务的蓬勃发展,网上购物已在人们日常生活中得到广泛应用.然而,由于互联网的虚拟性、匿名性等特点,消费者在选择合适的商品方面面临诸多困难:首先,消费者在交易前无从查证商家的真实性、可靠性以及商家所售商品的优劣性,只能通过搜索查看大量同款商品的评分评论来比较商品优劣;其次,在实际交易过程中,会存在个别消费者独裁现象,独裁者给出高评分或低评分,影响商品最终的群体评价,导致群体消费者因独裁者的反馈做出错误判断;最后,由于利益牵引,存在不良商家雇佣大量消费者共谋评分,即通过给予其商品高分或给予对手商品低分评分,来引导该商品的群体评价,提升自身信誉或贬低竞争对手[1-3].为此,需要一个客观的在线商品群体评价方法来帮助消费者选择合适商品.而群体评价方法是通过集中群体中多数消费者对在线商品的偏好意见,形成群体对在线商品的偏好意见,得到最终的在线商品群体评价,为消费者提供正确的购买决策[4].
目前许多在线网站,如EBay,Amazon,Netflix等,借助第三方在线评分反馈机制来衡量在线商品的评价.其中最常用的评价方法就是SUM累加法和AVG均值法[5,6].累加法将消费者对商品的反馈评分分为好、中、差三种评级,在线商品的评价计算如下:每收到一条好评得+1分;每收到一条中评得0分;每收到一条差评得-1分[5].然后对得分进行累加,结果作为消费者对在线商品的群体评价的依据;均值法将消费者对商品的所有反馈评分进行累加,然后除以评分次数,记作消费者对在线商品的群体评价.然而这两种方法都假设消费者对商品进行评分时评价标准一致,具有相同的主观偏好[7].事实上,不同的消费者拥有不同的背景和消费心理,使得消费者的评价标准不一致.即使评价标准一致,在真实评价过程中,上述两种方法也容易被不良商家通过雇佣消费者共谋评分,即通过给予其商品高分或给予对手商品低分评分,来引导该商品的群体评价,提升自身信誉或贬低竞争对手,为其他消费者提供错误的购买决策[1,2].
为此,本文提出利用Copeland社会选择理论的在线商品群体评价[4,15].以社会选择理论为基础,在不需要假设消费者偏好一致的情况下解决消费者评价标准不一致导致的在线商品评分不可比较,以及提升商品评价操纵复杂性的问题.
2 相关研究工作
近年来,大量研究者致力于协助消费者购买在线商品时能够做出正确的购买决策,为了达到较好的商品评价效果,已经有一些文献采取各种方法对在线商品评价问题进行了处理.
一些研究者基于在线商品评分进行评价[5-7].文献[5][6]提出将累加法应用于eBay这样的电子商务网站上,得到在线商品评价;文献[7]提出的在线评分反馈机制在进行在线商品评价时,假设消费者具有相同的主观偏好和评价准则,然后进行在线商品评价.文献[8]在累加法的基础上提出了加权累加信用度计算模型,这种模型更能体现商家的信誉状况,但依然没有将商家的信用情况、合谋、 欺诈等其他因素添加到模型中.
目前,大多数电商网站对于在线商品评价的处理还处于初级阶段,通常只是采用约束或激励控制消费者给予公正的评分,以及允许消费者选择评价的排序显示方法,这些排序方法虽然简单和直观,但效果往往不够理想.例如:按时间排序可能会导致消费者错失很多公正的评分以及消费者容易受到虚假评分的误导;按评分可靠性排序会存在不合理评分的问题等[9].为此,一些研究者提出根据不同的属性对在线商品进行排序[10-12].文献[10]根据消费者评论有用性,提出一个基于评论特征的商品排序系统,使用文本分析技术从大量消费者评论信息中抽取商品特征,与同类商品作比较,最终创建一个统一的商品排序.文献[11]提出了不确定性下的在线商品排序.不同于一般的只是基于预测的评级来排序商品,该方法将评分的不确定性和预测的可信性考虑在内评估消费者信息搜寻的效益,有助于提高消费者的决策过程,并提高消费者选择合适商品的满意度,同时也节省了消费者的时间和精力.随后,文献[12]提出个性化商品排序,利用后验等级分布和置信水平作为两个关键因素预测不确定性,来提高个性化商品排序的准确性,使消费者能够更准确地购买到合适的商品.
上述研究假设所有消费者的评价标准一致,如果这个假设成立,所有消费者对在线商品评分是可以比较的,那么结合消费者的评分对在线商品评价将不会有问题[16].然而,不同的消费者拥有不同的消费背景和消费心理,自然对在线商品的评价标准也不一致.此外,上述研究在进行在线商品评价时忽略了方法中的评分易被操纵的问题,导致不良商家雇佣虚假消费者,给出误导性的商品评价.
考虑到以上研究中存在的评价标准不一致和操纵复杂度低的问题,提出利用Copeland社会选择理论的在线商品群体评价.在不需要假设消费者评价标准一致的情况下,基于消费者历史评分建立每个消费者对在线商品的偏好关系,分析个人偏好和集体选择之间的关系[15].利用Copeland方法解决消费者评价标准不一致和操作复杂性低的问题,实现在线商品群体评价.最后,通过与已有的SUM和AVG法进行对比,来验证本文方法的合理性、有效性.
3 问题定义
3.1 问题定义
为了解决消费者评价标准不一致和商品评价操纵复杂性低的在线商品群体评价问题,本文对在线商品群体评价问题描述如下:
定义1.消费者集合C={c1,c2,…,cm},m≥2,商品集合P={p1,p2,…,pn},n≥2.其中m为消费者个数,n为商品个数.
定义2.评分矩阵R=[ri,a]m×n.ri,a的取值表示消费者ci对商品pa的评分,ri,a=0时表示消费者ci未对商品pa评分.
定义3.在线商品群体评价p1,p2,…,pn.pn表示第n个商品的评价值.其中p1表示群体评价最高的最优商品,pn表示群体评价最低的最差商品,pa>pb则表示商品pa优于商品pb.
3.2 举例说明
例1.假设给定5个消费者对4种商品进行评分,消费者集合为C={c1,c2,c3,c4,c5},商品集合为P={p1,p2,p3,p4},其中消费者-商品评分表示消费者对商品表现的偏好程度,采用电子商务评价机制中常用的5分制,rmn=[1,5]分别表示非常不偏好,不偏好,一般,偏好,特别偏好,0表示消费者未对在线商品进行评分.
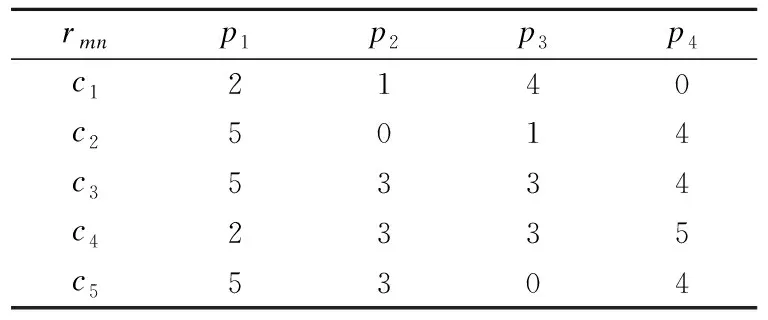
表1 消费者-商品评分矩阵Table 1 Ratings matrix of consumer-product
由表1可知,消费者c1对商品p1不偏好,而消费者c2对商品p1特别偏好,然而不同的消费者有不同的消费者背景和消费心理,消费者的评价标准自然不一致,那么不同消费者对同一商品的评分不可比较,也就无法判断商品p1的优劣.而SUM和AVG法则是假设消费的评价标准一致,使评分具有可比较性,再得到商品的评价结果.
由表1可以看出,有超过一半以上的三个消费者c2,c3,c5认为商品p1优于其他所有商品,同时只有一个消费者c4认为商品p4优于商品p1,根据孔多赛原则,商品排序应为p1>p4.
由表2可知,SUM和AVG法的评价结果为p4>p1,评价结果与大多消费者的偏好p1>p4不一致,违背了孔多塞原则,评价结果与独裁者c4的偏好一致,违背了社会选择理论中的非独裁性,使评价结果不公平.

表2 商品评价表Table 2 Product evaluation
此外,当增加一个对商品p2给予5分好评,对其他商品不予评分的虚假消费者c6.SUM和AVG法的评价结果表明商品p2的排序由劣于商品p3上升到优于商品p3,说明SUM和AVG法的操纵复杂性较低,容易被不良商家利用给出误导性商品评价.
4 利用Copeland社会选择理论的在线商品群体评价
由于消费者的消费背景和消费心理不同,使消费者的评价标准不一致,从而导致不同消费者对同一商品的评分不可比较.消费者对商品的评分属于个人效用,效用作为一种心理现象是无法计量的,也不能加总求和,所以集结不同消费者的基数评分不能用来衡量评价结果[15].为此,我们采用序数效用论通过顺序或等级来研究不同消费者对同一商品的评价问题,即利用消费者偏好的高低来表示商品的优劣排序[15].因此,我们需要得到同一消费者对不同商品的序数偏好关系.然而目前的评价系统为了方便消费者操作,采用简单的评分形式,要改变评价系统得到消费者对购买商品的偏好次序需要付出太大的代价.同时,消费者必然不愿花费大量的时间、成本、隐私等方面问题提供复杂的偏好信息.
基于以上分析,我们提出先将每个消费者对不同商品的评分转化为消费者对商品的偏好关系,解决不同消费者对同一商品的评分不可比较的问题.然后集结消费者对商品的偏好,两两比较得到对商品偏好的消费者总数,最后利用Copeland社会选择理论的在线商品群体评价实现在线商品的群体评价[4,13].此外,利用Copeland方法自身的操纵复杂性可增加商品评价的操纵复杂度,降低不良商家雇佣消费者给出误导性评价的影响[4].
4.1 社会选择理论
本文进行的群体评价需要一个公平合理的将个人偏好集结成群体偏好的方法.社会选择理论作为现代经济学的重要发展成果之一,其研究的根本性问题即是通过集中群体中各位成员的偏好意见,形成集体意见,制定出符合成员利益的正确决策[4,16].其中的社会选择函数与群体偏好相关,它是与群体中成员的偏好有关的数量指标,能反映群体对各候选商品的群体评价[15].
社会选择函数包含Condorcet方法、Borda方法、Copeland方法等多种方法[15].Copeland方法是由Ramon Llull于1299年在Ars Electionis上提出的排名方法,该方法利用成对比较的赢输之差对候选人进行排名[19,20].相比其他方法,Copeland方法利用消费者有偏好的投票产生最优商品,更易于理解,且处理灵活,并能够快速确定最优最差商品的排序[18].同时,Copeland方法具有操纵复杂性,该性质可降低不良商家雇佣消费者给出误导性评价的影响[4].
4.2 协同过滤填充矩阵
为了对在线商品进行群体评价,需要先从消费者的历史评分数据中获取每个消费者对在线商品的评分.但由于在线商品数量庞大,消费者共同评分过的商品数量过少,所以消费者对商品的评分矩阵一般是不完整的,而本文方法是基于消费者对商品偏好的两两比较,因此需要对不完整评分矩阵进行填充.目前,协同过滤方法[17]已被广泛地用于推荐系统,该方法通过寻找与自己评价指标最相似的消费者进行推荐[14].因此,本文使用协同过滤推荐方法填充不完整的消费者-商品矩阵.
首先利用消费者的共同评分数据Iij表示对商品偏好的相似程度,采用皮尔逊相关系数法度量消费者间相似性[15]:
(1)
其次,将相似度值超过阈值γ的消费者作为目标消费者的邻居.在选择消费者的共同评分Iij来计算消费者间的相似性时,若共同评分Iij数目较少时,说明消费者对商品偏好的相似度不高,那么需要根据数据实际情况,预先设定的阈值γ来加以设定调整,表示如下:
(2)
其中,γ(γ>0)为根据数据实际情况预先设定的阈值,min(Iij,γ)表示取Ii,j和γ中数值较小的一个.
最后,引入阈值K来限定消费者相似近邻的选取,根据所求相似度Sim′(i,j),选择当前消费者ci的前K个相似邻居来预测消费者cj对商品pa的评分rj,a,表示如下:
(3)
4.3 建立偏好关系
由于消费者评分属于个人效用不能加总求和,需要采用序数效用论来研究不同消费者对同一商品的评价问题,因此我们建立同一消费者对不同商品的序数偏好关系[15].
基于完整的消费者-商品评分矩阵R,计算每一个消费者ci∈C对商品pa,pb∈P(a,b=1,2,…,n且a≠b)的偏好矩阵CPi=[cpab]n×n,其中cpab=1表示相较于商品pa消费者ci更偏好商品pb;cpab=0表示消费者ci对商品pa和商品pb同样偏好;cpab=-1表示相较于商品pb消费者ci更偏好商品pa.
(4)
进一步,根据每一个消费者对在线商品的偏好矩阵CPi统计m个消费者中cpab=1的人数为spab,即spab表示相较于商品pb更偏好商品pa的消费者ci的总数,并将求出的所有商品被偏好的统计值spab表达为商品-商品偏好比较矩阵SPm=[spab]n×n:
(5)
根据上述步骤求出3.2中例1的商品-商品偏好比较矩阵如表3所示:
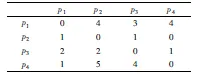
表3 商品-商品偏好比较矩阵表Table 3 Preference comparison matrix of product-product
其中,矩阵中p1p2=4表示在商品p1和商品p2比较中,偏好商品p1的消费者总数为4,即对应表1中偏好商品p1的四个消费者c1,c2,c3,c5.
4.4 在线商品群体评价
为了清楚地阐述本文提出的利用Copeland社会选择理论的在线商品群体评价,首先引进两个定义.
本文方法的核心思想是获取商品pa和商品pb的Copeland评价值.而这里的Copeland评价值指的是消费者对商品pa和商品pb的偏好程度.所以我们用商品-商品偏好比较矩阵SPm=[spab]n×n来表示消费者对商品偏好情况,成对比较商品被偏好的次数后,将比较结果中商品pa赢输的次数分别累加,得到商品pa赢的次数Pw(pa)(即被偏好的次数)与输的次数Pl(pa)(即不被偏好的次数),将赢输次数作差得到商品pa的Copeland评价值Cs(pa).
定义4.商品-商品偏好比较矩阵SPm=[spab]n×n.spab的取值表示商品pa和pb的择优中,偏好商品pa的消费者总数.
为了得到最终的在线商品群体评价,我们利用Copeland社会选择理论将商品-商品偏好比较矩阵SPm=[spab]n×n中的商品偏好成对比较:pavspb即spabvsspba,表示在商品pa和商品pb的择优中,比较偏好商品pa的消费者总数spab和偏好商品pb的消费者总数spba,若spab>spba则表示消费者认为商品pa为最优商品,记作pa赢一次,pb输一次;若spab (6) 根据上述步骤求出3.2中的例1的商品-商品偏好比较结果如表4所示: 定义5.Copeland评价值Cs(pn).Cs(pn)的排序表示商品的优劣情况p1,p2,…,pa,…,pn,其中p1为群体评价最高的最优商品,而pn为群体评价最低的最差商品. 将择优偏好比较结果中商品pn赢输的次数分别累加,得到商品pn赢的次数Pw(pn)与输的次数Pl(pn),将赢输差值作为商品pn的Copeland评价值Cs(pn)如下: Cs(pn)=Pw(pn)-Pl(pn) (7) 表4 商品-商品偏好比较结果表Table 4 Result of product-product preference comparison 对在线商品Copeland评价值Cs(pn)进行排序得到商品的优劣情况p1,p2,…,pa,…,pn,从而实现在线商品的群体评价. 根据上述步骤求出3.2中的例1的在线商品群体评价如表5所示. 表5 在线商品群体评价表Table 5 Group evaluation of online product 由表5可知商品p1赢的次数Pw(p1)=3,商品p1输的次数Pl(p1)=0,则Copeland评价值Cs(p1)=3-0=3.其他商品以此类推,由此可实现在线商品的群体评价p1>p4>p3>p2,即商品p1为最优商品.上述方法用算法描述如下. 4.4.1 算法描述及基本框架 算法:基于Copeland的在线商品群体评价算法 输入:在线商品评分矩阵R=[ri,a]m×n 输出:在线商品群体评价 1.computethecompleteRbycollaborativefilteringalgorithm; 2.fori=1 tomdo 3.compute thespabby (5); 4.endfor 5.Pw(pa):=0; 6.Pl(pa):=0; 7.fora=1tondo 8.forb=a+1tondo 9. if(a≠b)then 10. if(spab>spba)then 11.pn:=pa; 12.Pw(pa):=Pw(pa)+1; 13.Pl(pb):=Pl(pb)+1; 14. elsepn:=pb; 15.Pw(pb):=Pw(pb)+1; 16.Pl(pa):=Pl(pa)+1; 17.endfor 18.Cs(pn):=Pw(pn)-Pl(pn) 19.pn:=sort(Cs(pn)); 20.endfor 21.returnpn. 4.4.2 算法时间复杂度分析 从上面描述不难看出,算法中第7行的for循环表示逐一遍历商品p1到pn的每种商品,即商品pa中a的取值范围是a=1,2,…,n,其时间复杂度为O(n).算法中第8行的for循环表示逐一遍历商品p2到pn的每种商品,即商品pb中b的取值范围等于a+1的取值范围,即b=2,…,n,其时间复杂度也为O(n).两次for循环表示在商品pa=p1时,商品pb依次等于p2到pn,以此类推,pa循环一次,pb遍历所有商品一次,则算法总的时间复杂度为O(n2). 为了通过验证本文方法的合理性和有效性,下面对利用Copeland社会选择理论的在线商品群体评价的对孔多赛原则、非独裁性、一致性和操纵复杂性进行理论分析. 定理1.孔多赛原则:若存在商品pa,使得有一半以上的消费者ck(k>m/2)认为pa>pb,则商品pa是孔多赛候选商品. 证明:因为对任意的b={1,2,…,n|b≠a}都有偏好商品pa的消费者总数spab>spba,则Pw(pa)>Pl(pa),Pw(pb) 由3.2例1可知,SUM和AVG法的评价结果p4>p1>p3>p2均不满足孔多塞原则.本文方法的评价结果为p1>p4>p3>p2,商品p1为最优商品,满足多数消费者的偏好,评价结果符合孔多赛原则. 定理2.非独裁性:当且仅当只有一个独裁者ci认为商品pa>pb,而其他所有消费者ck(k={1,2,…,m|k≠i})均持相反态度,评价结果中商品pb的评价结果不会低于商品pa. 证明:假设存在独裁者ci认为pa>pb,而所有其他消费者认为pb>pa(b={1,2,…,n|b≠a}),当n>2时,spba=n-1>spab=1,则商品pb的Pw(pa) 由3.2例1可知,当只有一个消费者c4认为p4>p1商品,其他所有消费者均持相反的偏好时,SUM和AVG法的评价结果与独裁者c4的偏好一致.而本文方法的评价结果未受独裁者c4的偏好影响,说明本文方法具有非独裁性,使评价结果更具公平性. 定理3.一致性:对任意商品pa,pb,若所有消费者都认为pa>pb时,有Cs(pa)>Cs(pb),则商品pa一定是群体评 1http://www.grouplens.org/node/73 价最高的最优商品. 证明:假设所有消费者都认为pa>pb时,即对任意的b={1,2,…,n}都有偏好统计总数spab=n,spba=0,所以Pw(pa)=n,Pl(pa)=0,Pw(pb)=0,Pl(pb)=n,则Copeland评价值Cs(pa)=n,Cs(pb)=-n.那么Cs(pa)>Cs(pb)恒成立,评价结果与假设一致,商品pa是群体评价最高的最优商品.说明本文方法具有一致性.反之亦成立. 定理4.操纵复杂性:对任意商品pa,增加对商品pa给予高评分的虚假消费者数量,而不改变其对其他商品pb的评分,评价结果不变. 证明:假设存在商品pb>pa,增加m个只对商品pa给予高分而对其他商品pb未进行评分的消费者,根据本文方法需要先根据公式(1)(2)(3)对未评分数据进行填充,填充后的数据与m个消费者对商品pa评分相同,则偏好商品pa和pb的消费者总数spba,spab值是同步增加的,因此Copeland评价值Cs(pb)>Cs(pa)保持不变,则评价结果与假设一致,表明本文方法的操纵更加复杂. 由3.2例1可知,相较于SUM和AVG方法的评价结果明显向着操纵方向发生改变,本文方法的评价结果几乎不变,说明本文方法的操纵复杂性更高. 为了验证本文提出的利用Copeland社会选择理论的在线商品群体评价的有效性,实验数据采用具有真实评分的电影数据集MovieLens1来模拟在线商品的数据.该数据集1682部电影模拟为在线商品数,943名消费者模拟为消费者数量,10万条左右的评分模拟为消费者对在线商品的评分.为了更明显的呈现实验结果,本实验分别筛选出前1/32,1/16,1/8,1/4,1/2的商品五组实验数据.实验环境为PC机,Windows 8系统,Corei3处理器,4 GB内存,Sublime Text为开发工具,Python为开发语言对五组数据进行调用,并记录运行时间(单位:s). 为了进一步验证在线商品群体评价模型的有效性,我们使用目前比较流行的两种在线商品反馈机制:EBay的SUM累加法和Amazon的AVG均值法作为对比方法,分别对孔多塞原则、一致性和操作复杂性进行如下实验验证. 若本文方法的群体评价中的最优商品与孔多赛候选商品一致,则本文方法满足孔多赛原则.为了便于查看结果,本实验特选取其中数据量最小的一组1/32,即943名消费者对52种商品的评价结果.利用孔多赛方法集结所有消费者的偏好,挑选出有一半以上的消费者认为该商品优于其他所有商品的孔多赛候选商品#8商品. 图1 孔多赛原则验证Fig.1 Condorcet verification 进一步,由图1可知,Copeland评价值最高的是#8商品,该商品为所选最优商品;Copeland评价值最低的是#52商品,该商品为最差商品.本文方法得到的评价结果与孔多赛候选商品一致,所以本文方法结果满足孔多赛原则. 对五组实验数据进行验证,本文方法的孔多赛商品命中率达到100%,而AVG均值法和SUM累加法为0. 所有消费者都认为商品pa>pb,则商品pa一定是群体评价最高的最优商品.若本文方法的评价结果中最优商品为pa,说明本文方法具有一致性.为了验证本文方法的一致性,并能够清晰展现评价结果,特选取1/32组的前20个消费者对前20种在线商品的评分,查看数据集发现,所有消费者对#3商品评分均高于其他所有商品的评分.分别利用SUM法、AVG法和本文方法进行测试,测试结果如图2所示. 图2 三种算法的一致性对比Fig.2 Comparison of Consistency of Three Algorithms 由图2可知,本文方法的评价结果区分明显,更加直观,SUM和AVG法的评价结果均在横坐标上方,比较起来区分不明显.本文方法最终的评价值是通过赢输之差(被偏好次数减去不被偏好的次数)得到的,Copeland评价值分布在横坐标上下两部分.排在横坐标上方的Copeland评价值为正,评价值越高,对应商品排序越靠前;排在坐标轴下方的Copeland评价值为负,评价值越高,对应商品排序越靠后,因此根据本文方法可快速找到横坐标上方评价值最高的最优商品是#3号商品,横坐标下方评价值最高的最差商品#18商品.最终的评价结果验证了本文方法的一致性,也体现了Copeland方法的快速排序的优点. 影响商品评价的一个重要问题就是不良商家和消费者共谋评分.共谋评分是指不良商家雇佣消费者对其商品给予高分或给予对手商品低分评分,来引导该商品的群体评价,提升自身信誉或贬低竞争对手[1-3].这种方式严重影响了消费者的购买决策,为此,本文利用Copeland方法的操纵复杂性来降低不良商家和消费者的共谋评分.为了验证本文方法的操纵复杂性,并清晰查看效果,特选取数据最少的一组52种在线商品的评价情况为例.随机抽取该组在线商品#6商品,然后随机找出5个对#6商品评分为0的消费者,将该消费者对#6商品的评分逐次提升为1分,2分,3分,4分,5分后,记录对应三种算法的群体评价值如图(a)所示.最后,逐次增加10个对排序最低的#52商品给予5分好评,对其他商品给予1分差评的虚假消费者,共增加6次,记录对应三种算法的群体评价值如图(b)所示. 由图3可知,无论是逐次提升#6商品的评分,还是逐次增加对#52商品好评的虚假消费者数量,本文方法的评价结果均未有明显的变化.而根据SUM和AVG法得到的评价结果均有明显地提升或降低.因为SUM和AVG法均是采用基数效应论的思想直接基于评分进行评价,更容易被操纵,而本文方法采用序数效用论的思想,将评分转化为偏好关系,并利用Copeland方法对偏好总数两两比较实现在线商品的群体评价,增加了评价的操纵复杂性.由此实验结果可见,本文的方法的操纵复杂性得以验证. 图3 操纵复杂性验证Fig.3 Complexity of manipulation verification 利用三种算法分别测试五组数据,在不同在线商品数据集下,三种算法的性能不同.当消费者的数量固定,依次增加在线商品的数量,记录下三种算法的运行时间(单位:s). 图4 三种算法的性能比较情况Fig.4 Comparison of the performance of the three algorithms 由图4可知,随着在线商品的数量增加,每种算法的运行时间基本都成线性速度增长,由趋势线可知,本文方法的运行时间随着在线商品数量的增多快速增长,其他两种算法的增速则呈放缓趋势.本文方法的运行时间虽然增长过快,但在操纵复杂性上占优,相较于SUM和AVG法,本文方法更不易被不良商家操纵,更能为消费者提供可靠、真实的在线商品群体评价. 本文提出利用Copeland社会选择理论的在线商品群体评价,基于消费者历史评分进行群体评价,为消费者做出正确的购买决策提供参考.本文方法首先利用协同过滤算法对已有的消费者不完整评分数据集进行填充,并建立每个消费者对在线商品的偏好关系;然后通过社会选择理论中的Copeland社会选择函数两两比较消费者对在线商品的偏好,最终得到在线商品的群体评价.理论分析和实验验证了该方法满足孔多赛原则、非独裁性、一致性和操纵复杂性等性质,从而该方法对在线商品群体评价的有效性. 由于无法采集到新消费者的历史评分记录,不能准确地推断新消费者的偏好.因此,因此下一步我们将继续研究新消费者冷启动问题. : [1] Wang G,Xie S,Liu B,et al.Review graph based online store review spammer detection[C].Proceedings of the 2011 IEEE 11thInternational Conference on Data Mining.IEEE Computer Society,2011:1242-1247. [2] Pan W,Xiang E W,Yang Q.Transfer learning in collaborative filtering with uncertain ratings[C].Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence,AAAI Press,2012:662-668. [3] Zhang Y,Bian J,Zhu W.Trust fraud:a crucial challenge for China′s e-commerce market[J].Electronic Commerce Research and Applications,2013,12(5):299-308. [4] Endriss U.Social choice theory as a foundation for multiagent systems[C].German Conference on Multiagent System Technologies,Springer International Publishing,2014:1-6. [5] Pinyol I,Sabater-Mir J.Computational trust and reputation models for open multi-agent systems:a review[J].Artificial Intelligence Review,2013,40(1):1-25. [6] Wu Y,Yan C G,Ding Z,et al.A novel method for calculating service reputation[J].IEEE Transactions on Automation Science and Engineering,2013,10(3):634-642. [7] Jøsang A,Guo G,Pini M S,et al.Combining recommender and reputation systems to produce better online advice[M].Modeling Decisions for Artificial Intelligence,Springer Berlin Heidelberg,2013:126-138. [8] Ji Shu-xian,Hu Pei,Cheng Fei.Research on credit calculation model in online reputation management system [J].Forecast,2008,27(4):59-64. [9] Lin Yu-ming,Wang Xiao-ling,Zhu Tao,et al.Survey on quality evaluation and control of online reviews[J].Journal of Software,2014,25(3):506-527. [10] Najmi E,Hashmi K,Malik Z,et al.CAPRA:a comprehensive approach to product ranking using customer reviews[J].Computing,2015,97(8):843-867. [11] Zhang M,Guo X,Chen G,et al.Predicting consumer information search benefits for personalized online product ranking:a confidence-based approach[C]. Pacific Asia Conference on Information Systems,Pacis,2014:375-388. [12] Zhang M,Guo X,Chen G.Prediction uncertainty in collaborative filtering:Enhancing personalized online product ranking[J].Decision Support Systems,2016,83:10-21. [13] Nápoles G,Dikopoulou Z,Papageorgiou E,et al.Aggregation of partial rankings-an approach based on the Kemeny ranking problem[C].International Work-Conference on Artificial Neural Networks,Springer International Publishing,2015:343-355. [14] Sun Hui,Ma Yue,Yang Hai-bo,et al.Collaborative filtering recommendation algorithm by optimizing similarity and clustering users[J].Journal of Chinese Computer Systems,2014,35(9):1967-1970. [15] Yue Chao-yuan.Decision theory and method [M].Beijing:Science Press,2003. [16] Fu X,Yue K,Liu L,et al.Aggregating ordinal user preferences for effective reputation computation of online services[C].IEEE International Conference on Web Services.IEEE,2016:554-561. [17] Breese J S,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering[J].New Page,2013,7(7):43-52. [18] Alsharrah G.Ranking using the copeland score:a comparison with the Hasse diagram[J].Journal of Chemical Information & Modeling,2010,50(5):785. [19] Leake C.Multicriterion decision in management:principles and practice[J].Journal of the Operational Research Society,2001,52(5):603-603. [20] Colomer J M.Ramon Llull:from′Ars electionis′to social choice theory[J].Social Choice and Welfare,2013,40(2):317-328. [21] Moulin H.Handbook of computational social choice[M].Cambridge University Press,2016. 附中文参考文献: [8] 纪淑娴,胡 佩,程 飞.在线信誉管理系统中信用度计算模型研究[J].预测,2008,27(4):59-65. [9] 林煜明,王晓玲,朱 涛,等.消费者评论的质量检测与控制研究综述[J].软件学报,2014,25(3):506-527. [14] 孙 辉,马 跃,杨海波,等.一种相似度改进的用户聚类协同过滤推荐算法[J].小型微型计算机系统,2014,35(9):1967-1970. [15] 岳超源.决策理论与方法[M].北京:科学出版社,2003.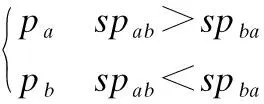


4.5 评价模型理论分析
5 实验评估
5.1 孔多赛原则
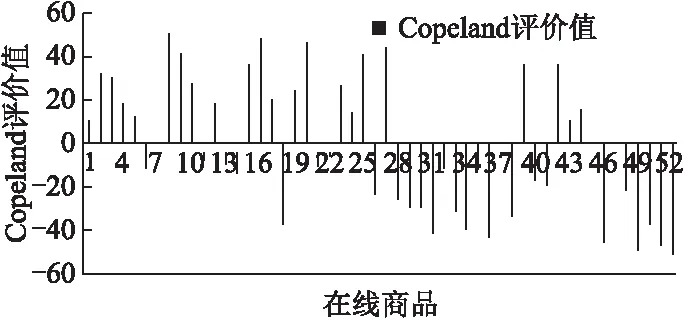
5.2 一致性
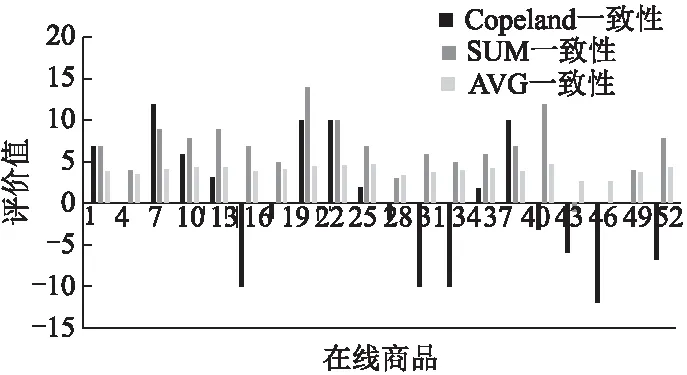
5.3 操纵复杂性
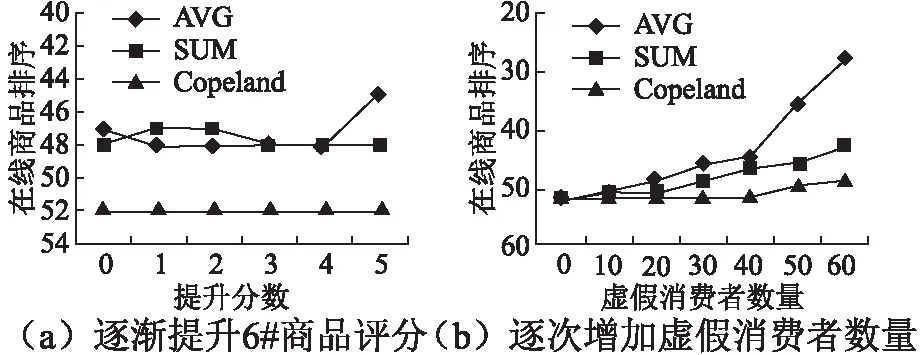
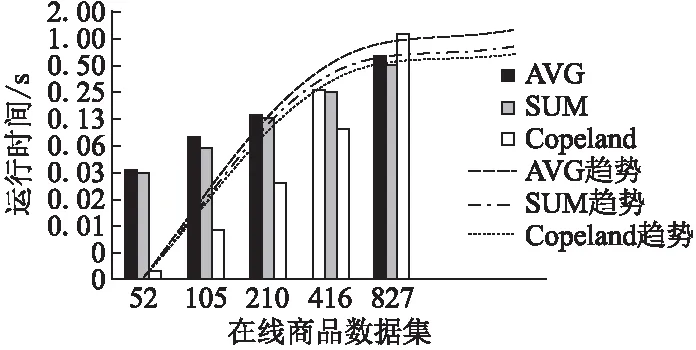
5.4 算法性能测试
6 结 语
