一种针对天猫购物平台的网页URL去重策略研究
2018-06-22舒远仲
◆舒远仲 梁 涛 王 娟
一种针对天猫购物平台的网页URL去重策略研究
◆舒远仲 梁 涛 王 娟
(南昌航空大学信息工程学院 江西 330063)
本文在分析了Bloom Filter缺点的基础上,结合天猫购物平台网页URL的特征,对网页URL去重策略进行了改进,以此来提高网页URL去重效果及减小Bloom Filter误判率。实验结果表明,改进后的去重策略在针对天猫购物平台网页URL去重时,准确度上要优于传统的Bloom Filter。
布隆过滤器;网页URL去重;哈希处理;误判率;天猫
0 引言
随着互联网的快速发展以及网络购物平台的兴起,越来越多的人加入到“网购大军”中。以2016年“双十一”为例,据第三方数据公司星图数据11月12日发布的《星图数据1112:双十一网购大数据分析报告》[1]显示,2016年双十一全网总销售额为1770.4亿元,其中化妆品类销售总额为212.4亿元,占全网销售总额的12.0%。由此也带来了一些的问题:部分商家销售假冒伪劣产品,使得消费者权益受到侵害。因此,相关部门需要采取相应措施对网售商品进行监督管理。
网购平台的商品具有海量 、增长迅速、更新频繁的特点,在给消费者提供更多选择的同时,也给监管部门带来了巨大的挑战。监管部门需要获取网售商品的信息,用于与基础库上的信息进行比对,从而达到监管的目的。为了获取商品信息,需要使用网络爬虫自动抓取网页并提取网页内容。通常在给定的一个或多个统一资源定位符URL(Uniform ResourceLocator)种子集情况下,从种子网页开始采集,在抓取网页的过程中,不断将新的URL放进待爬行的URL队列中,直到满足一定条件(如待爬行队列为空、达到指定爬行数量)停止爬行[2]。如何选择符合主题的URL,如何过滤已抓取过的信息对系统来说至关重要。
本文提出了针对上述问题的解决方案。以天猫网购平台为例,针对其网页URL的特点,通过对URL去重方式的改进,使得网络爬虫能够更准确、更快速地抓取所需要的网页。
1 天猫网购平台网页URL分析
天猫采用是动态URL,即同一商品对应的网页可能存在多个URL。通过对这些URL的分析,找出它们之间的联系,从而可以简化URL去重。如表1,选取多个URL实例来分析其特点。

表1 天猫网购平台网页URL实例
从表1中可以得出,同一店铺同一产品可能对应多个URL;不同店铺同一产品对应URL不同;同一店铺不同产品对应的URL也不一样。但对各个URL具体分析后,可以发现:每个URL中都含有参数id,对于同一店铺同一产品,尽管对应多个URL,但参数id的值是一致的;不同店铺同一产品URL中的参数id的值不一样;同一店铺不同产品URL中的参数id的值不一样。
2 布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出来的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于判断一个元素是否存在于一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。布隆过滤器是一种空间利用率高的算法,特别适合于海量数据集的表示和查找,尽管存在一定的误判率,但在海量信息搜集的系统中,不失为一种可行的解决方案[3-5]。
2.1布隆过滤器原理及判断方法
如图1所示,布隆过滤器原理如下:

图1 布隆过滤器(Bloom Filter)原理
(1) 设数据集合S={S1,S2,S3,……,Sn},含有n个元素,为待操作的集合;
(2) Bloom Filter用一个长度为m的位向量V来表示集合中元素,位向量初始化全为0;
(3) 选取k个相互独立的哈希函数h1,h2,h3,……,hk;
(4) 用Bloom Filter表示集合S的所有元素。首先,对集合里的元素Si通过k个哈希函数产生k个哈希值h’1,h’2,h’3,……,h’k,将位向量V的h’1,h’2,h’3,……,h’k位上的值置为1。由于通过个哈希函数将位向量V相应位置为1,多个集合元素进行增加操作时,可能会出现向量相应位置已经为1,此时不对相应位的值进行操作。
在判断一个元素X是否属于该集合时,我们只需要对X使用相同的k个哈希函数得到k个哈希值,如果位向量V上对应位置上的k个值全为1,那么我们就认为该元素存在于该集合中;反之,我们就认为该元素不存在于该集合。如图2所示,元素X1是该集合的元素,X2不是该集合的元素。
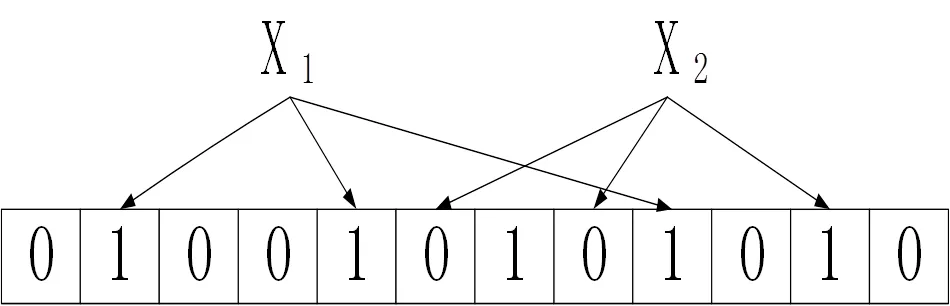
图2 判断元素是否属于该集合
显然,这个判断并不能保证结果100%的正确。当我们判断一个元素元素不属于该集合时,这个判断是100%正确的,但当我们判断一个元素属于该集合时,这个判断可能是个误判[6-8]。
2.2布隆过滤器的缺点及误判率
虽然布隆算法的空间效率及查询时间都远远超过其他算法,但是布隆过滤器还是存在缺点。
(1)Bloom Filter存在一定的误判率。对于已经映射在集合中的元素,通过集合查找运算一定可以判定该元素在集合中,但对于尚未映射到集合中的元素,可能存在误判,即不在集合中的元素误判为在集合中。
假设集合S中含有n个元素,需要使用k个哈希函数进行处理,Bloom Filter长度为m,则某一位被置为1的概率为1/m,为0的概率为(1-1/m)。所以在集合S中的元素全部用Bloom Filter表示后,某位仍为0的概率为:
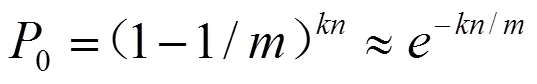
则误判的概率为
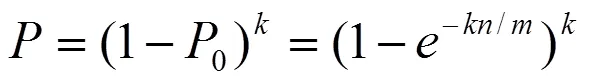
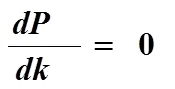
(2)Bloom Filter无法从Bloom Filter集合中删除一个元素。因为一个元素对应的位可能与另一个元素对应的位存在共同位。如图3所示。

图3 存在共同位的元素
元素X1、X2是同一集合的元素,当删除元素X1,即把元素X1对应位置为0时,X2对应位则变为011,此时元素X2被判断为不在集合中。所以,一个简单的改进方法就是使用计数型布隆过滤器(Counter Bloom Filter),在Bloom Filter 进行集合元素添加操作时,对相应的向量位进行加1操作。如图4所示。
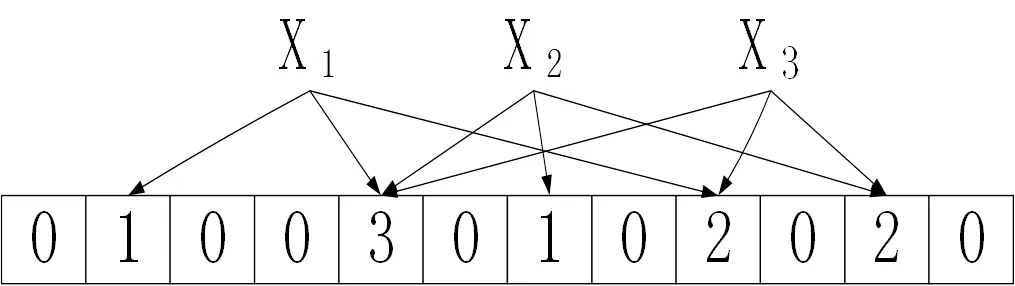
图4 Counter Bloom Filter
3 网页URL去重
针对天猫网页URL的特点及Bloom Filter存在误判率的缺点,本文提出一种基于Bloom Filter的改进的URL去重的策略。如图5所示。
(1)抓取一个URL,分析判断URL中是否含有参数id。对于不存在参数id的URL直接舍弃;
(2)提取参数id并对其进行多个哈希处理;
(3)判断处理后的id是否存在于布隆过滤器中,如果不存在,则直接将此URL放入待抓取URL队列中,并将处理后的id添加到布隆过滤中,同时将id存储到id数组中;
(4)如果处理后的id存在于布隆过滤器中,为了避免布隆过滤器的误判,则判断id是否存在于id数组中,如果不存在,则将此URL放入待抓取URL队列中,同时将id存储到id数组中;如果存在,则说明此商品URL已存在于待抓取URL队列中,则舍弃该URL;
(5)初始化的id数组为空,插入数据时应有序插入。这样,对于查找判断一个id是否存在于该数组时可使用二分法进行,从而可以节省查找时间。
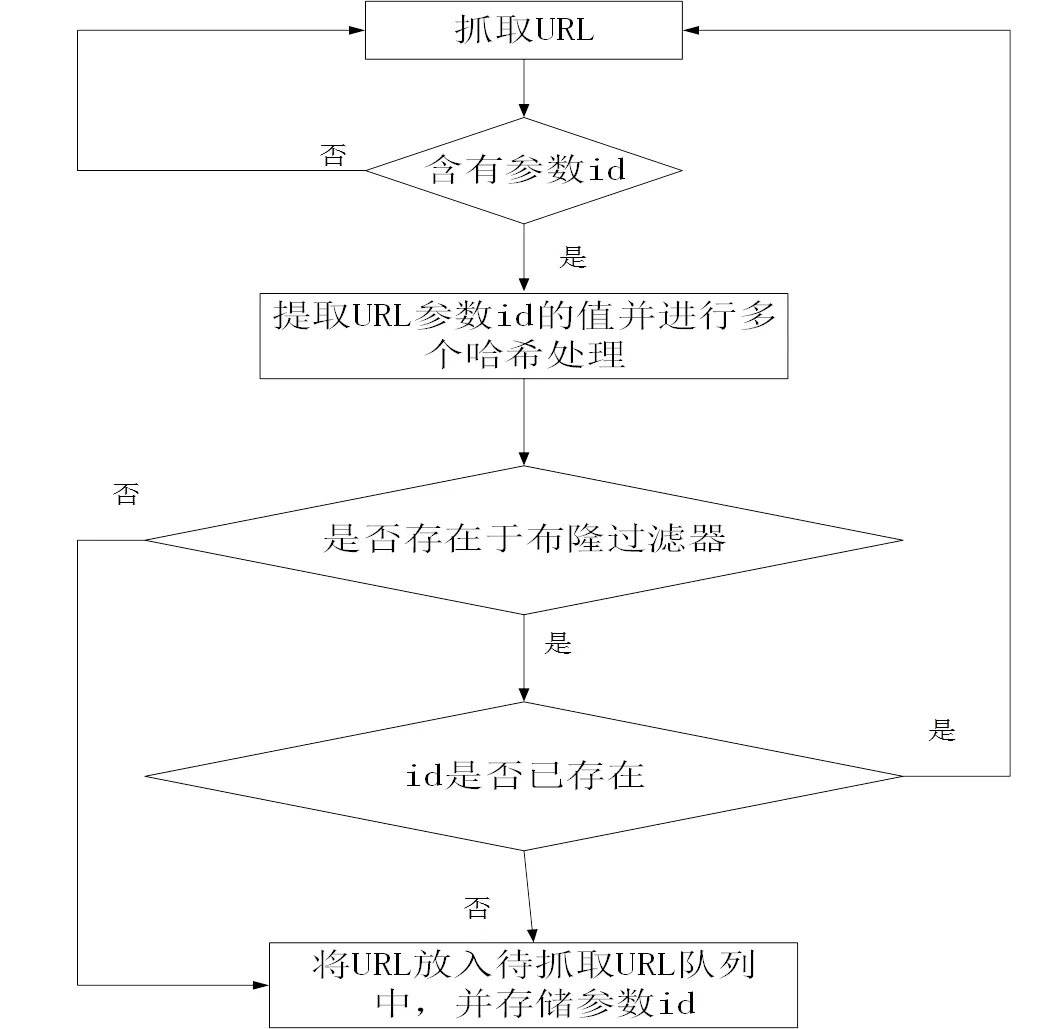
图5 改进后的URL去重策略
4 实验分析
由于进行的是仿真实验,通过采集天猫网页URL,将URL缓存于内存空间,分别使用传统Bloom Filter与改进后的Bloom Filter对URL进行去重,比较两者对于比较时间、准确度上的区别。结果如图6、图7所示。
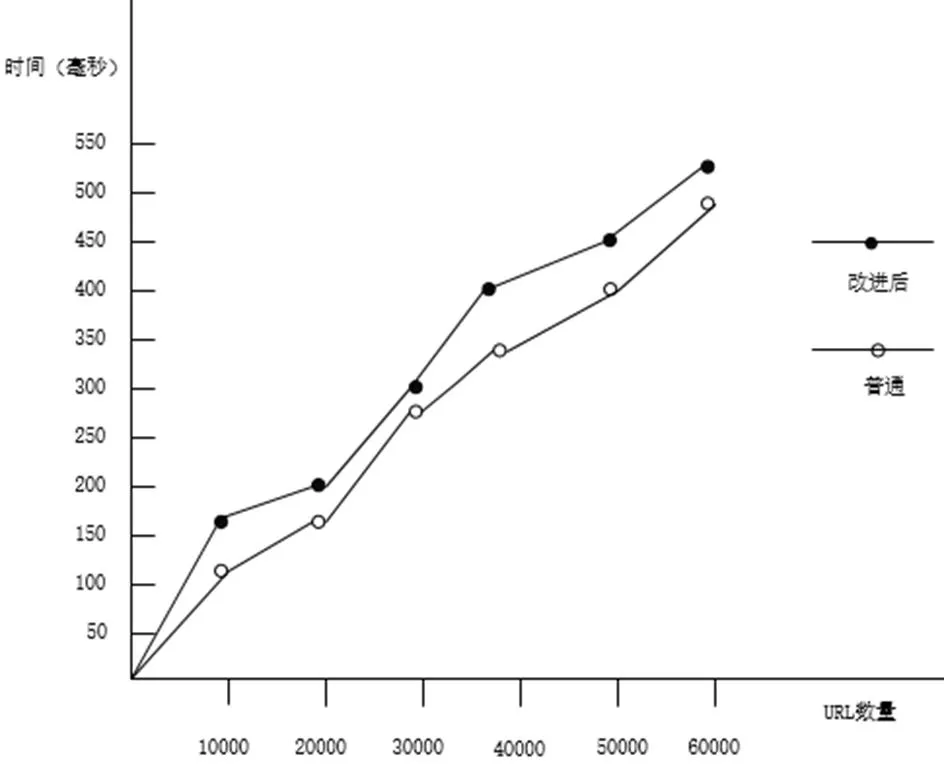
图6 传统与改进后Bloom Filter去重的时间对比
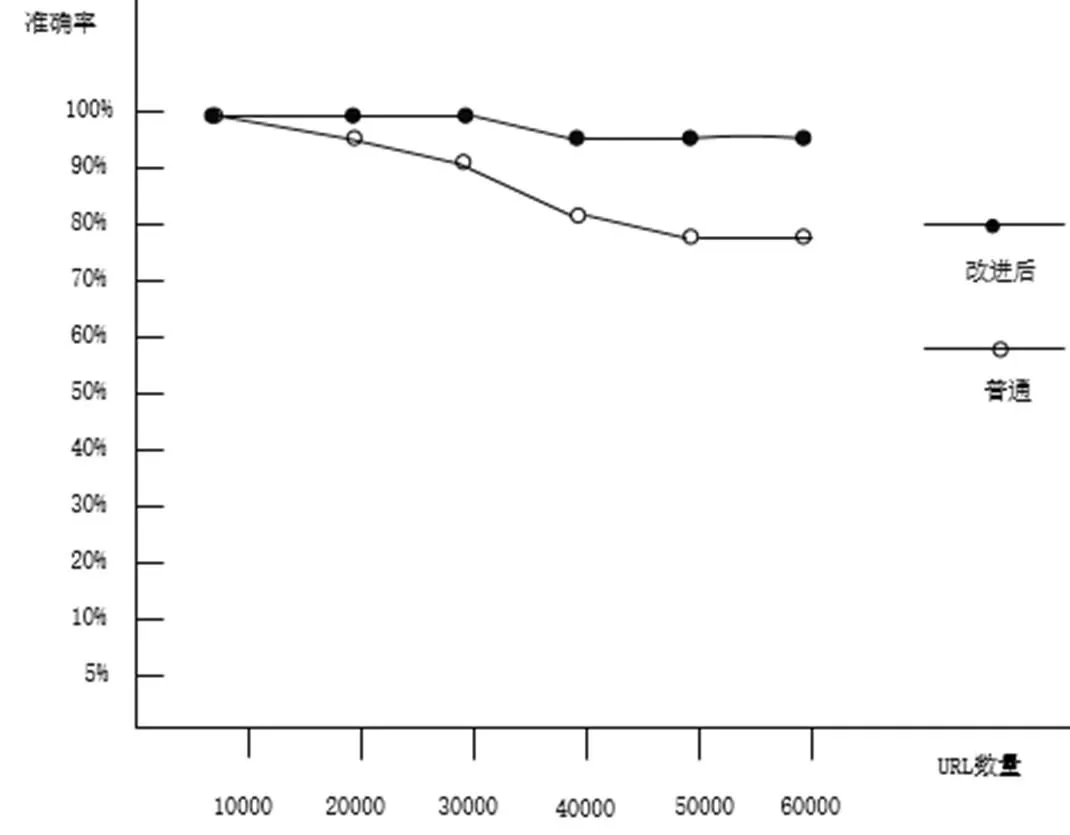
图7 传统与改进后Bloom Filter去重的准确度对比
通过实验结果可以看出,在准确度上,改进后的Bloom Filter要优于传统Bloom Filter,在时间上,略慢于传统Bloom Filter。
5 结束语
本文研究了Bloom Filter的基本工作原理,并对其在网页URL去重中的应用进行改进,结果表明改进后的策略去重准确率提高。同时,改进后的策略在去重速度上仍有改进的空间。
[1]星图数据.星图数据1112:双十一网购大数据分析报告EB/OL].http//www.syntun.com.cn/xing-tu-shu-ju1112- shuang-shi-yi-wang-gou-da-shu-ju-fen-xi-bao-gao.html,2016.
[2]黄正德.主题爬虫关键技术研究[D].黑龙江:哈尔滨工程大学,2013.
[3]苏国荣,杨岳湘,邓劲生.一种去除重复URL的算法[J].广西师范大学学报(自然科学版),2010.
[4]黄诚.一种高速URL过滤算法的研究与应用[J].现代计算机(专业版),2016.
[5]刘佐达,张久岭,陈茂科,李星.一种面向BBS信息检索的主题网络爬虫算法[J].郑州大学学报(理学版),2010.
[6]张宗华,屈英,叶志佳等.基于多特征匹配和Bloom filter的重复数据删除算法[J].深圳大学学报(理工版),2016.
[7]ZHANG Guo,ZHANG Jianhui,WANG Binqiang,ZHANG Zhen.On-line Popularity Monitoring Method Based on Bloom Filters and Hash tables for Differentiated Traffic[J].中国通信,2016.
[8]赵艳红,李洪奇,朱丽萍等.基于Bloom Filter的去重方法研究[J].计算技术与自动化,2016.
