基于Spark的移动用户行为轨迹大数据分析
2018-06-20张嘉诚张晓滨
张嘉诚,张晓滨
(西安工程大学 计算机科学学院,陕西 西安 710048)
0 引 言
文献[3]基于实际的移动学习环境,提出一种根据传感器与学习操作行为对学习场景进行感知分类的方法;文献[4]针对移动用户行为识别模型中过度拟合的问题,提出一种基于随机Dropout深度信念网络的移动用户行为识别方法;文献[5]提出了基于多重运动特征的轨迹相似性度量,该度量对分析和理解移动对象的运动行为和规律具有重要意义;文献[6]建构了数据驱动的移动用户行为研究框架,系统梳理了移动用户行为研究的方法.
随着智慧城市建设和大数据等概念的不断深入,社会和用户对移动互联的要求越来越高[7].基于轨迹数据的行为分析已渗透到各行各业[8-9].本文将移动互联与大数据计算框架Spark相结合,对用户行为轨迹数据分析进行服务设计,对用户轨迹数据进行卡方检验和聚类分析,得到出行方式的普遍结果及在距离限制下的结果.
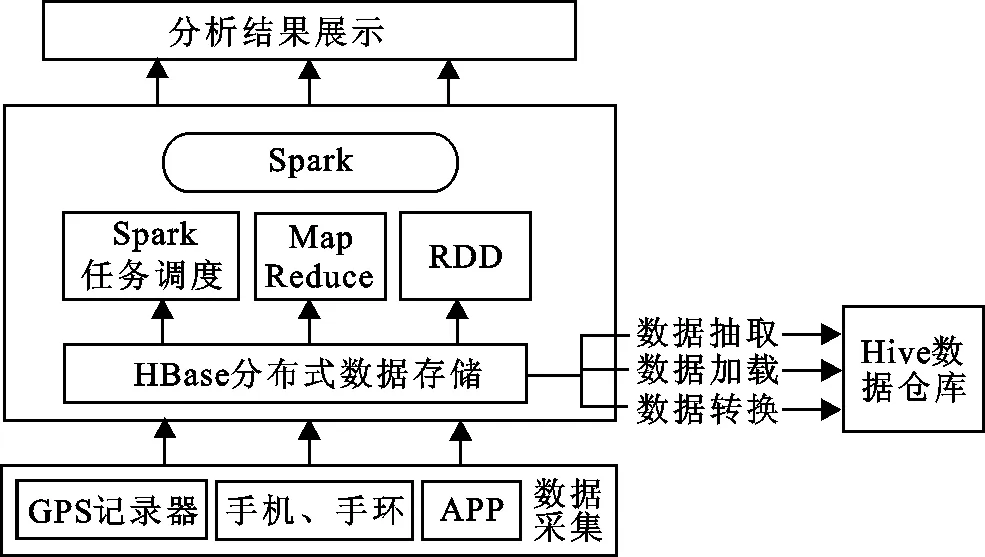
图 1 移动用户行为轨迹分析总体架构图Fig.1 The overall architecture of mobile user behavior trajectory analysis
1 移动用户数据分析平台设计
1.1 架构及功能设计
移动用户行为轨迹大数据分析系统基于可靠性、可扩展性、安全性、可维护性等原则,支持Hive、MySQL、Hadoop、HBase等平台的数据接入,同时采取分布式的任务调度执行,保证任务高效的执行.整个分析系统分为移动终端数据感知层、Spark数据分析层和结果展示层,移动用户行为轨迹分析总体架构图如图1所示.
(1) 移动终端数据感知层利用移动设备、GPS记录器实时收集用户轨迹数据,并将数据作为数据分析层的输入.
(2) Spark数据分析层主要是基于Spark分布式计算平台,利用其自身函数库分析数据收集层所收集到的数据.Spark在进行数据分析时,SparkContext和SparkExecutor不可缺少,其任务调度和执行的框架图如图2所示.
行业精神是“一个行业在长期的发展实践中逐步提炼和培育形成,并为行业全体成员所认同的价值取向、理想信念、心理特征和精神风貌的总和”[3]。受互联网时代的冲击,传统行业间的界限正在日趋模糊,但各行业精神却在随着时代发展而不断充实新的内涵。“双一流”建设强调高校教师要有较高的思想政治素质和业务素质,并特别强调要“传承创新优秀文化”。我国行业特色型大学作为承担行业人才培养和供给的高等教育载体,必须承担“行业精神”传承的历史使命和责任,这也是各行业特色型大学“特色一流大学精神和大学文化”建设的重要组成部分和内容,因此,行业特色型大学教师要注重行业精神的培育与宣传。
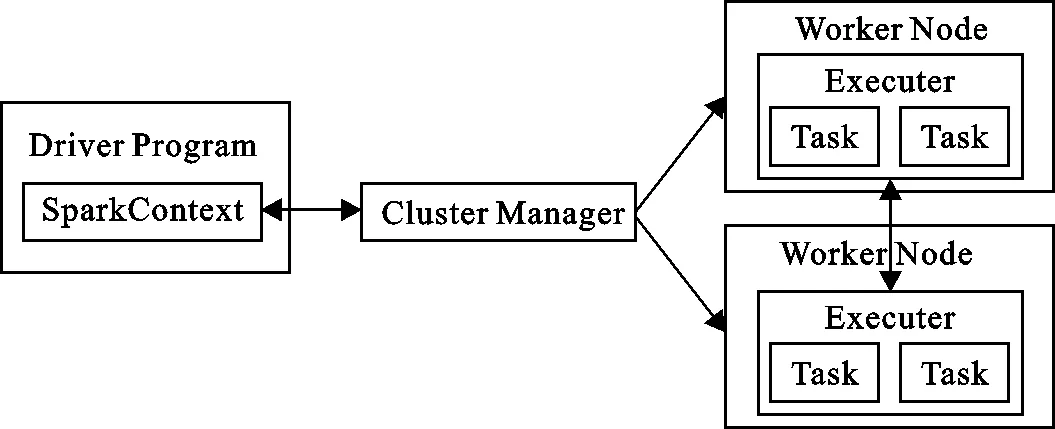
图 2 任务调度和执行框架图Fig.2 Frame diagrams of task scheduling and execution
从图2可以看出,SparkContext启动用户程序,负责与Executor通过资源调度模块进行通信;Executor通过Worker节点运行,负责执行任务[10].
(3) 结果展示层主要是对数据分析层所分析的用户轨迹数据结果以图表等形式直观地展示出来.
1.2 数据采集
在获取移动用户行为轨迹数据的过程中,主要通过GPS记录器、具有GPS功能的手机、手环和移动APP获取用户行为轨迹信息[11-12].全球定位系统主要是通过卫星信号记录坐标数据,记录的时间频率由移动设备决定;移动轨迹数据是用户使用移动终端时产生的坐标信息.所用的移动用户行为轨迹数据来自微软研究亚洲项目中的数据,该数据集包括182个志愿者自2007.4月到2012.8月出行的经度、纬度、海拔高度及出行时间、出行方式等,数据集中相关定义:
(1) GPS轨迹点:t时刻下轨迹点的经纬坐标(x,y,t);
(2) 用户行为轨迹:连续的轨迹点构成用户行为轨迹T={(X1,Y1,Z1)…(Xn,Yn,Zn)}.
GPS采集的数据是用户移动行为轨迹数据的主要来源,客观反映了其在真实世界中的路线轨迹,以海量轨迹行为数据集为基础,从分析移动行为轨迹数据出发,得到移动用户的普遍行为特点[13-15].
2 移动行为轨迹数据分析
2.1 出行方式统计
在对出行方式进行统计分析时,采用Pearson卡方检验对移动轨迹数据因素间的相关性分析,在对数据处理分析前,应获取判断相关性的因子,由于在获取因子时互不干扰,因此,创建两个弹性分布式存储(即RDD)对数据文件进行处理得到原始数据集合,通过调用SparkContext中的sc.textFile()读取HDFS中的分布式文件,并以数据分片的形式存储在集群中[16],通过.flatMap()函数对每行的单词以空格分隔为单词的列表,然后将这个按照行构成的单词列表合并为单词列表集合,将所得单词列表集合中的每个单词转化为Double类型.map(-.toDouble).得到处理好的原始数据集合,在原始数据集合上采用卡方检验对数据的处理步骤如下:
(1) 任意选定两个独立因子(如出行人员a,出行方式b),提出原假设值H0;
(2) 在出行方式数据集中各属性交叉统计,记录出现频数f,行总频数R,列总频数C;
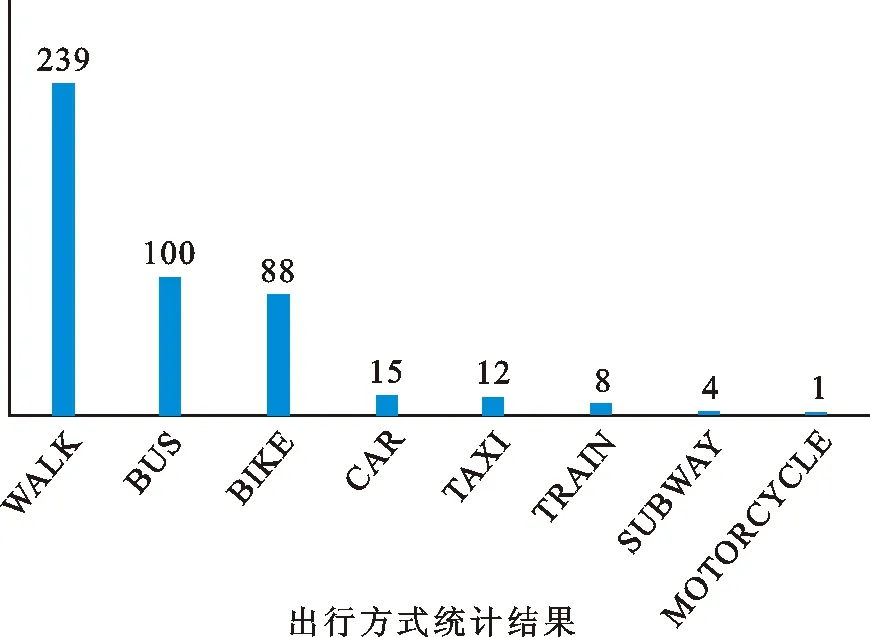
图 3 出行方式统计结果图Fig.3 Statistical results of travel patterns
(5) 设定显著性水平α,当观察频数和期望频数偏离程度较大时(即χ2〉α),则拒绝该假设,即认为该出行人员a拒绝该出行方式b;当观察频数和期望频数偏离程度较小时(即χ2〈α),则接收该假设,即认为该出行人员接受该出行方式.基于此对数据进行处理,得到出行人员对不同出行方式的接受程度,即得到对出行方式的统计结果如图3所示.
从图3可以看出,基于特定应用场景下的移动用户轨迹数据统计,人们的出行方式普遍选择步行、公交车、自行车、小汽车等,基于此特定数据下的多种出行方式,步行是被人们接受的出行方式,其次是公交和自行车,而摩托车则受用户接受的程度较小.然而考虑出行方式可能会受出行距离、出行天气等客观因素的影响,不能仅从此统计结果得出何种出行方式更受人们青睐.文中以出行距离为限制条件,分析不同出行距离对出行方式选择的影响.
2.2 出行方式排名
在分析出行方式排名时,通过Spark并行处理不同时间段的距离,对所得距离用K-Means算法聚类分析,该算法通过迭代过程把数据集划分为不同类别,使评价聚类性能的准则函数达到最优[17].
如上文所述,同一个用户的GPS轨迹数据包括轨迹点(x,y,t),通过式(1)欧式距离公式计算用户从t1时刻的轨迹点(x1,y1)到t2时刻的轨迹点(x2,y2)之间的两点距离:
(1)
式中:TA,TB为用户轨迹点;xak为TA轨迹中第k个轨迹点的经度;xbk为TA轨迹中第k个轨迹点的纬度,同理可知uak,ubk的含义.由于各个轨迹点间的距离各自独立互不干扰,因此可以并行化处理,多个任务同时处理轨迹点间的距离,得到用户轨迹点间的距离数据集D(d1,d2,…dn),改进传统的K-Means算法,对此距离数据集聚类分析,得到不同出行距离下的出行方式.
改进传统的K-Means算法,使其基于Spark数据分析层中的MapReduce模式并行处理用户出行方式数据集主要步骤:
(1) 对HDFS中的距离数据集D聚类中心初始化,选出初始聚类中心并存于文件中;
(2) 划分HDFS中的数据集为多个数据块,用Map函数处理;
(3) 将待聚类的距离数据集和初始聚类中心或迭代产生的新聚类中心作为Map阶段的输入,将数据块以
(4) 在main函数中,计算聚类中心的相似度,如果大于预先设定的阈值则算法结束输出结果,否则进行下一次迭代.
在K-Means算法确定簇中心时,将初始簇中心向量和簇类数目作为共享数据,将整个移动数据分组成k类,开始随机选择簇中心,计算每个节点数据到簇中心的距离,将节点数据划到离其最近的簇中心,通过每次迭代不断更新簇中心[18],循环以上步骤,在目标函数达到最优或者最大迭代次数即可停止,K-Means算法处理数据步骤:
(1) 将出行方式划分到对应类中:对出行距离数据集D(d1,d2,…dn)随机选取k个聚类中心点{b1,b2,b3…bk};
(2) 重选聚类中心:在每个簇内,计算同一类中距离的均值作为该簇类的聚类中心.
采用欧氏距离公式计算不同出行方式下的出行距离数据集对象xd与中心点xb的距离dist(Td,Tb),对所有属于同一中心点,即相同出行方式下的出行距离求均值:
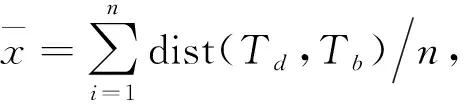
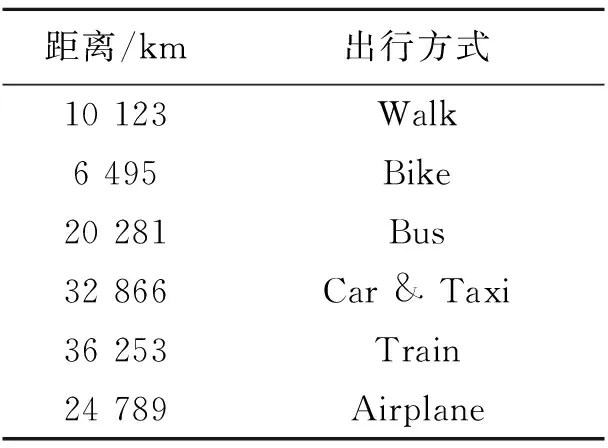
表 1 出行方式排名统计结果
在对出行方式排名分析的过程中,将距离数据集合D分为k个簇类,对每个点的出行方式xi进行聚类处理,将每个点的出行方式xi仅归于k个聚簇中的1个,通过多次测试不同k值下的聚簇信息,选定最合适的k值及对应k值下的出行方式xi,得到不同出行距离对出行方式的影响结果见表1.
从表1可以看出,以出行距离为限制条件,通过分析不同出行距离下对出行方式的选择得出距离较远时,人们倾向于选择火车、汽车;距离较近时,人们倾向于步行或自行车,说明出行距离对出行方式的选择有很大的影响.
基于轨迹数据的行为分析已渗透到各行各业,通过对移动用户轨迹数据的分析,得到海量移动用户的普遍行为特点.
3 结束语
采用皮尔森卡方检验算法统计轨迹数据中的出行方式,通过改进的K-Means算法分析出行距离对出行方式的选择.在实现了对用户行为轨迹数据的统计分析后得出移动用户行为的特点及用户出行的规律,更好地实现了在正确的时间和地点为用户提供个性化得服务.
参考文献(References):
[1] PENCHIKALA S.Big data processing with apache Spark-(Part 1):Introduction 2015[EB/OL].(2015-12-25)[2018-01-01].https://www.infoq.com/articles/apache-spark-introduction.
[2] 李致昊,朱闽峰,黄兆嵩,等.一个基于基站轨迹数据的城市移动模式可视分析系统[J].计算机辅助设计与图形学学报,2018,30(1):68-78.
LI Z H,ZHU M F,HUANG Z S,et al.A visual analytics approach for urban mobility patterns based on mobile phone data[J].Journal of Computer-Aided Design & Computer Graphics,2018,30(1):68-78.
[3] 叶舒雁,张未展,齐天亮,等.一种基于传感器与用户行为数据分析的移动学习场景感知分类方法[J].计算机研究与发展,2016,53(12):2721-2728.
YE S Y,ZHANG W Z,QI T L,et al.A sensor and user behavior data analysis based method of mobile learning situation perception[J].Journal of Computer Research and Development,2016,53(12):2721-2728.
[4] 王忠民,王希,宋辉.基于随机Dropout深度信念网络的移动用户行为识别方法[J].计算机应用研究,2017,34(12):1-6.
WANG Z M,WANG X,SONG H.Human activity recognition method based on random Dropout deep belief network[J].Application Research of Computers,2017,34(12):1-6.
[5] 朱进,胡斌,邵华.基于多重运动特征的轨迹相似性度量模型[J].武汉大学学报(信息科学版),2017,42(12):1703-1710.
ZHU J,HU B,SHAO H.Trajectory similarity measure based on multiple movement features[J].Geomatics and Information Science of Wuhan University,2017,42(12):1703-1710.
[6] 黄文彬,吴家辉,徐山川,等.数据驱动的移动用户行为研究框架与方法分析[J].情报科学,2016,34(7):14-20.
HUANG W B,WU J H,XU S C,et al.Data-driven mobile user behavior analysis framework and methods[J].Information Science,2016,34(7):14-20.
[7] 刘先林.移动互联时代的GIS[J].遥感信息,2017,32(1):1-4.
LIU X L.Geographic information in mobile internet Era[J].Remote Sensing Information,2017,32(1):1-4.
[8] 黄腾,阮宗才.基于运动轨迹分析的头部行为识别[J].计算机工程,2012,38(17):218-221,231.
HUANG T,RUAN Z C.Head behavior recognition based on analysis of trajectory[J].Computer Engineering,2012,38(17):218-221,231.
[9] 许佳捷,郑凯,池明旻,等.轨迹大数据:数据、应用与技术现状[J].通信学报,2015,36(12):97-105.
XU J J,ZHENG K,CHI M M,et al.Trajectory big data:Data,applications and techniques[J].Journal on Communications,2015,36(12):97-105.
[10] 冯兴杰,王文超.Hadoop与Spark应用场景研究[J].计算机应用研究,2018,35(9):1-8.
FENG X J,WANG W C.Hadoop and Spark application scenario research[J].Application Research of Computers,2018,35(9):1-8.
[11] 蒲剑苏,屈华民,倪明选.移动轨迹数据的可视化[J].计算机辅助设计与图形学学报,2012,24(10):1273-1282.
PU J S,QU H M,NI M X.Survey on visualization of trajectory data[J].Journal of Computer-Aided Design & Computer Graphics,2012,24(10):1273-1282.
[12] 刘震,付俊辉,赵楠.基于移动通信数据的用户移动轨迹预测方法[J].计算机应用与软件,2013,30(2):10-13.
LIU Z,FU J H,ZHAO N.Users mobile track prediction method based on mobile communication data[J].Computer Applications and Software,2013,30(2):10-13.
[13] 陈万志,林澍,王丽,等.基于用户移动轨迹的个性化健康建议推荐方法[J].智能系统学报,2016,11(2):264-271.
CHEN W Z,LIN S,WANG L,et al.Personalized recommendation algorithm of health advice based on the user′s mobile trajectory[J].CAAI Transactions on Intelligent Systems,2016,11(2):264-271.
[14] LOU Y,ZHANG C,ZHENG Y,et al.Map-matching for low-sampling-rate GPS trajectories[C]//Proceedings of ACM SIGSPATIAL Conference on Geographical Information Systems.Seattle:ACM,2009:352-361.
[15] YE Y,ZHENG Y,CHEN Y,et al.Mining individual life pattern based on location history[C]//Tenth International Conference on Mobile Data Management:Systems,Services and Middleware.Taipei:IEEE,2009:1-10.
[16] 余涛,刘泽燊.基于Spark的并行遗传算法研究[J].计算机时代,2017(1):43-46.
YU T,LIU Z S.Research of massive parallel genetic algorithm based on Spark[J].Computers Era,2017(1):43-46.
[17] 刘江华.一种基于kmeans聚类算法和LDA主题模型的文本检索方法及有效性验证[J].情报科学,2017,35(2):16-21.
LIU J H.A text retrieval method based on kmeans clustering algorithm and LDA topic model and its effectiveness[J].Information Science,2017,35(2):16-21.
[18] 王永贵,武超,戴伟.基于MapReduce的随机抽样k-means算法[J].计算机工程与应用,2016,52(8):74-79.
WANG Y G,WU C,DAI W.k-means algorithm of random sample based on MapReduce[J].Computer Engineering and Applications,2016,52(8):74-79.
