基于Spark的CVFDT分类算法并行化研究
2018-06-20李玲娟
庄 荣,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
面对实时到达、连续、无限的流数据[1],传统的数据挖掘算法难以满足流数据挖掘的需求,因而流数据的分类挖掘[2]研究一直是热门话题并且具有重大意义。概念适应快速决策树算法(concept-adapting very fast decision tree,CVFDT)[3]是经典的流分类算法之一。CVFDT主要克服了VFDT(very fast decision tree)算法[4]对于数据样本的不断变化而不能更换模型的缺点,并且可以有效地解决概念漂移[5]的问题。与传统的静态大数据处理平台Hadoop[6]不同,Spark[7]扩展了广泛使用的MapReduce[8]模型,提出了基于内存的并行计算框架,通过将中间结果缓存在内存中以减少I/O磁盘操作,从而更高效地支持多次迭代式计算模式。为此,文中研究了基于Spark的CVFDT分类算法并行化,用以提高CVFDT算法对流数据的分类效率。
1 CVFDT算法分析
1.1 CVFDT简介
CVFDT属于一种增量式的分类挖掘方法,即用新到样本修正旧分类器,产生新分类器,以适应新环境。CVFDT在树的所有节点上维持统计信息用于计算基于属性值的信息增益测试,即统计测试,并基于Hoeffding不等式确定叶节点变成分支节点所需的样本数目,对数据流建立分类决策树。
以t为时间戳,xt表示t时刻到达的数据向量,数据流可表示为{…,xt-1,xt,xt+1,…}[9]。CVFDT算法的有关定义如下:
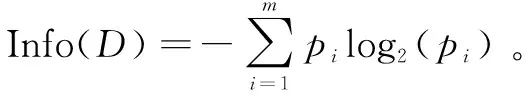
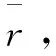
1.2 CVFDT算法流程
在拿到新的数据流样本后,从上到下遍历决策树,并在树的每个分支节点根据属性取值等判断进入不同的分支,最终到达树的叶节点。随着数据流样本的不断增多,信息增益测试为了满足一定条件,其叶节点必须要以较高的置信度确定最佳划分属性,从而变成一个分支节点,这样循环可以不断地决策学习新的叶节点。如遇到概念漂移问题,CVFDT就会在相应分支节点上并行生成备选子树,原子树会随着备选子树的精度远远超过其本身时被替换和释放。
2 Spark平台
Spark不同于Hadoop MapReduce的是,Job中间输出结果可以保存在内存中,从而不再需要频繁读写HDFS[12],可以显著提高运行速度。Spark还提供了SparkSQL、Spark Streaming[13]、MLib[14]等计算模式组件,更适用于分布式平台场景。Spark Streaming是构建在Spark上的处理Stream数据的框架,基本原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据。
弹性分布式数据集RDD[15]是Spark的核心和基础。RDD是一种分布式的内存抽象,表示只读的分区记录的集合。它只能通过在稳定物理存储中的数据集或其他已有的RDD上执行一些确定性操作(并行操作中的转换操作)来创建,并且RDD仅支持粗粒度转换,即在大量的记录上执行单一的操作,因此省去了大量的磁盘I/O操作,对于需要多次迭代计算的机器学习算法、交互式数据挖掘来说,效率得到了极大地提升;同时它具有非常出色的容错机制和调度机制,能够有效确保系统的长时间稳定运行。所以Spark能够更高效地支持交互式查询以及迭代式计算等多种计算模式。
3 CVFDT基于Spark的并行化方案设计
3.1 CVFDT的分割点计算过程的并行化
在CVFDT建树过程中计算最佳分割点时,需要将Hoeffding边界作为节点分裂条件找到最佳分割点,其首要任务是计算并比较各个属性的最佳基尼分割指数。在面对含多种属性类别的数据集时,线性串行的计算模式会大大降低运行效率。
因此,针对CVFDT算法的分割点计算过程,考虑到每个属性的基尼分割指数求解是完全独立计算,可以对这些计算进行同步,设计了如图1所示的属性间并行化方案。

图1 针对分割点计算过程的属性间并行化方案
如图1所示,首先计算每个任务的最佳基尼指数和Hoedding边界,从而找到每个任务的最佳分割点;然后在每个任务计算完成后进行比较,获取最佳分割点。这种改进的计算模式可以有效地降低时间复杂度。
3.2 基于Spark的RDD实施CVFDT的并行化
1.Spark的并行计算过程简述。
RDD为了让海量数据分散在不同的计算节点上进行并行处理,会横向地拆分成N个分区,因此对RDD进行计算操作时,集群会对每个分区进行计算,然后由相应的集群控制器将结果进行汇总,最终统计整个RDD结果。因此,Spark的并行属于“横向”并行化。
2.针对建树过程的基于Spark的横向并行化。
在3.1提出的属性间并行化的基础上,基于Spark的横向并行化,针对CVFDT算法的建树过程做如下并行化改造:
(1)If(都是同类属性的数值||获取的属性列表个数不超过阈值)
(2)将含有同属性最多数值的类复制给节点N的Decision类并且返回;
(3)Else
(4)得到节点N的属性列表AttList,将所有属性列表转化为对应的RDD;
(5)计算由每个RDD生成的并行化任务,汇总并比较每个最佳分割点;
(6)再计算Hoeffding边界产生节点分裂条件,找到最佳分割点;
(7)在AttList中找到该分割点相应属性的属性列表并删除,然后对其余属性表进行分裂,得到属性表Attlist1,Attlist2,…,AttlistN;
(8)新的子节点N1,N2,…,Nn由节点N生成,并将属性列表Attlist1,Attlist2,…,AttlistN分别赋给N1,N2,…,Nn;
(9)执行buildTree(n1),buildTree(n2),…,buildTree(n)操作,递归建立决策树。
4 实验结果与分析
选择传统单机CVFDT算法和基于Spark集群的CFVDT并行化算法对实验数据集进行分类操作,算法运行环境是:
集群硬件环境:1个Master节点,2个Slave节点。
集群操作系统:centos6.6。
集群软件环境:JRE1.7.0_13、Scala_2.11.6、Spark1.3.1。
单机环境:eclipse_4.5.0、JRE1.7.0_13、Windows7、2.13 GHz、4 GB内存。
目的是借助流数据处理平台提高CVFDT算法的执行效率。为了验证所设计的CVFDT算法基于Spark的并行化方案的可行性和有效性,对比了单机和集群并行环境下,CVFDT算法处理不同数据量所需的时间。
实验使用的数据集源自Kaggle比赛,基于美国UGC网站Stumbleupon提供的历史数据,设计分类模型,预测该网站提供的网页是否长期流行。训练集样本数目为10 706个,测试集样本大小为5 171 M。
4.1 建树效率的比较
为了考虑算法的实用性,选取了200k、300k、500k、800k、1 000k条这五种不同规模的数据集,测试结果如表1所示。
表1 建树时间测试结果

数据大小/条 现有算法/s并行化算法/s综合效率提高/%200k6766.90.13300k110106.43.37500k197187.15.28800k310289.67.011 000k401367.49.14
当选取200k条规模数据集时,算法(建树)效率提升微乎其微,并且10 000条数据规模下,建树时间反而增加。原因是资源管理、网络传输会伴随着Spark运行集群而产生额外开销。当数据规模达到300k以上时,或者海量数据规模时,基于Spark的CVFDT并行化有明显的效率提升。
4.2 数据处理时间的比较
图2对比了单机和Spark集群环境下在数据规模分别为200 M、300 M、500 M、800 M、1 000 M时所需的时间。
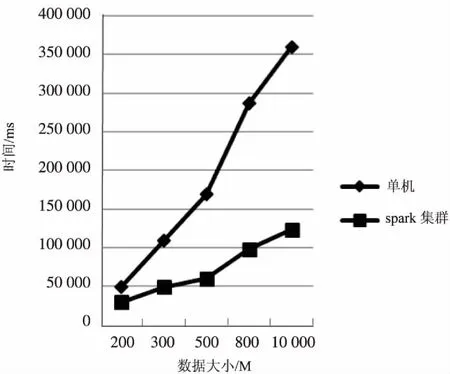
图2 对应不同数据量的处理时间测试结果
在单机环境下,随着数据规模的扩大,数据处理时间急剧增加;在Spark集群环境下,在200 M数据规模下,处理时间提升不明显,除了上一节提到的原因之外,主要还存在求解每个分裂条件的基尼系数时,会依照分裂条件对RDD进行过滤,然后再调用count()函数来统计个数,每一次的count操作都是在Spark集群中完成,然后将计算结果传输给虚拟机。当属性列表数据条数N不是很大时,Spark的优势无法体现。300 M数据量之后,可以看到并行化算法的数据处理时间明显减少,当数据量到1 000 M时,处理时间缩减了66.6%。
4.3 测试结果分析
由表1和图2可以看出,基于Spark集群的并行化CVFDT算法在处理规模较大的流式数据时,运行效率有所提高,并且在数据规模增大时,其效果会越发明显。并且并行化CVFDT算法相对于单机环境在处理海量数据时处理效率有显著提高,而且合理设定RDD过滤可使处理效率进一步提高。
5 结束语
将经典的流数据分类挖掘算法CVFDT部署于流数据处理平台Spark上,借助构建在Spark之上的实时计算框架Spark Streaming来实现对流数据的并行化分类。对CVFDT算法进行了属性间并行化改造,并且基于Spark的RDD进行了CFVDT算法在建树流程上的横向化并行。测试结果证明了该设计思想的正确性和方案的有效性,也说明了基于Spark的并行化CVFDT算法对大规模流数据有良好的适应能力。
参考文献:
[1] DING Shifei,WU Fulin,QIAN Jun,et al.Research on data stream clustering algorithms[J].Artificial Intelligence Review,2015,43(4):593-600.
[2] ABURROUS M,HOSSAIN M A,DAHAL K,et al.Predicting phishing websites using classification mining techniques with experimental case studies[C]//7th international conference on information technology.Las Vegas,NV,USA:IEEE,2010:176-181.
[3] 王 涛,李舟军,颜跃进.一种基于哈希链表的高效概念漂移连续属性处理算法[J].计算机工程与科学,2008,30(8):65-68.
[4] 袁 磊,张 阳,李 梅,等.在数据流管理系统中实现快速决策树算法[J].计算机科学与探索,2010,4(8):673-682.
[5] MINKU L L,WHITE A P,YAO Xin.The impact of diversity on online ensemble learning in the presence of concept drift[J].IEEE Transactions on Knowledge & Data Engineering,2010,22(5):730-742.
[6] DITTRICH J,QUIANÉRUIZ J A,JINDAL A,et al.Hadoop++:making a yellow elephant run like a cheetah (without it even noticing)[J].Proceedings of the VLDB Endowment,2010,3(1-2):515-529.
[7] 黎文阳.大数据处理模型Apache Spark研究[J].现代计算机,2015(8):55-60.
[8] 沈 超,邓彩凤.论Storm分布式实时计算工具[J].中国科技纵横,2014(3):53.
[9] RAAHEMI B,ZHONG Weicai,LIU Jing.Peer-to-peer traffic identification by mining IP layer data streams using concept-adapting very fast decision tree[C]//Proceedings of the 20th IEEE international conference on tools with artificial intelligence.Dayton,OH,USA:IEEE,2008.
[10] 张发扬,李玲娟,陈 煜.VFDT算法基于Storm平台的实现方案[J].计算机技术与发展,2016,26(9):192-196.
[11] YIN Chunyong,FENG Lu,MA Luyu,et al.A feature selection algorithm of dynamic data-stream based on Hoeffding inequality[C]//International conference on advanced information technology and sensor application.[s.l.]:IEEE,2015:92-95.
[12] 欧阳永.运营商大数据系统建设的分析与研究[D].南京:南京邮电大学,2016.
[13] 管祥青.大数据可视化模型的协同过滤算法研究及应用[D].长沙:湖南大学,2015.
[14] XIN R S,GONZALEZ J E,FRANKLIN M J,et al.GraphX:a resilient distributed graph system on Spark[C]//International workshop on graph data management experiences and systems.New York,NY,USA:ACM,2013.
[15] 刘志强,顾 荣,袁春风,等.基于SparkR的分类算法并行化研究[J].计算机科学与探索,2015,9(11):1281-1294.
