面向文本聚类的实体—动作关联模型研究
2018-06-14刘作国陈笑蓉
刘作国,陈笑蓉
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
0 前言
近年来,语义实体建模逐渐成为信息挖掘领域的研究热点。语义实体建模挖掘文本中有价值的命名实体(人物、事件等),建立实体间的关联,构建实体链接和知识库,在信息抽取、句法分析、机器翻译、语义消歧、问答系统等诸多应用领域具有巨大的研究价值和深远的应用前景。
目前,国内外的大多数实体建模技术主要面向信息挖掘领域[1-2]和问答系统[3-4],关注实体的领域概念及映射关联。挖掘深度主要停留在词汇层面,缺少句法层面的分析[5-7],挖掘出的特征实体可能不是语句谓词的施体或受体,在语句中并不充当主要成分。例如语句“刺杀肯尼迪的凶手被捕了”,通常很多模型能挖掘出命名实体“肯尼迪”,但也很容易受此误导,认为肯尼迪被捕。
现行的实体描述模型注重刻画实体关系而忽略了行为及状态[8-9]。模型能够描述家族族谱、组织机构关系等静态关联,但难以刻画实体的动作行为、状态变迁及属性变化。例如“Joe送给Bob玩具”的行为,Bob很开心的状态都难以刻画。
目前国内外有一些建立在句法分析层面上的文本实体挖掘研究[10]。本文认为,这些研究关注“是什么”的问题,而文本聚类更关心“关于什么”的问题。例如以下两个语句:
例1A: 中国队战胜了日本队。
例2B: 日本队战胜了中国队。
两个语句所表述的语义截然相反,但它们都涉及了中国队与日本队的比赛。从聚类分析的角度来看,两句话是相似的。本文希望建立一个以汉语文本聚类为目标的实体—动作关联模型(entity-action relationship model,EARM),通过句法分析挖掘文本中的实体关系,描述动作及参与主体,并实施聚类分析。
1 实体—动作关联模型EARM
1.1 相关概念阐述
汉语的功能同其他人类语言一样,都是描述主观和客观的世界,即描述事物发生的行为、所处的状态及具有的认知等。本文希望从汉语语句中实体的行为及状态出发,挖掘行为的参与者或状态主体,建立表示文本的实体—动作关联模型。以下对本文论述的相关概念进行阐述。
动作: 对行为、关系、状态、认知等的描述。
实体: 动作的施体或受体。
动作元: 动作发生时关联的实体。
本文将事物的行为、关系、状态、认知等关联统称为动作。动作可以是单独的谓词,也可以是谓词的复合结构。借鉴动词配价理论,将动作分为零元、一元、二元、三元这四类动作[11]。零元动作发生时没有关联的实体,如“下雨”“刮风”。一元动作具有一个关联主体,如“[我]累了”。二元动作具有主体(也称施体)和受体,如“[他]打[我]”“[我]擦[桌子]”。三元动作多出现在双宾语句型中,具有主体(施体)、直接宾语(受体)、间接宾语(受体)这三个关联实体,如“[他]递给[我][钱]”。值得注意的是,在汉语语句中有时动作的关联实体可以省略,如“[我]已经给(你)(钱)了”。
实体可以是单独的体词,也可以是复合结构[12]。实体与体词的区别在于,体词只描述客观存在或抽象的概念,但未必参与动作。例如“我送给他的礼物被偷了”,语句涉及三个体词“我”、“他”、“礼物”,但动作“偷”则只涉及一个实体“礼物”。
1.2 EARM模型定义
根据前文阐述,基于实体动作关联的EARM模型定义如下:
定义1EARM: EARM由实体、动作、动作元这三个要素构成,描述形式如式(1)所示。
EARM=Action(R(E))
(1)
Action为动作集合;E为实体集合;R(E)表示动作元,即发生关联的实体。例如,“市长/来到/西吉县将台堡/瞻仰/红军/长征/会师/纪念碑”,该语句属于连谓句型:
E={市长, 西吉县将台堡, 红军, 纪念碑};
R= {(市长, 西吉县将台堡),(市长, 纪念碑), (红军, 长征),(红军, 会师)};
Action={来到, 瞻仰, 长征, 会师}。EARM= {来到(市长, 西吉县将台堡), 瞻仰(市长, 纪念碑), 长征(红军), 会师(红军)}
对应实体—动作关系如图1所示。

图1 实体关联模型
1.3 句法成分识别
汉语句法分析比印欧语系的句法分析更为困难,这是由汉语本身的语法特点决定的。朱德熙先生在《语法答问》[13]中提到: 汉语属于非形态语言。与印欧语系相比,虽然汉语语法灵活多变,但又强调词序;虽然汉语虚词对描述语义有重要贡献,但又时常省略部分虚词。朱先生总结了汉语的两大特点: 一是汉语词类跟句法成分之间并非简单的一一对应关系,其句法成分对应关系如图2所示;二是汉语句子的构造原则跟词组的构造原则基本一致。

图2 汉语句法成分对应关系
基于汉语句法这两个特点,必须建立成分识别机制,识别语句中的动作和实体。由于汉语词汇没有时态、语态的变化,句法格式也不像英语那样严格,语句成分缺省和倒装的现象比英语更普遍[14-15]。为了准确分析出动作的参与者,应当建立句法关联分析器。
相关研究显示,体词通常作为语句的主语或宾语,谓词主要作为谓语成分。本文参考文献[16]提出的实体关系模式获取策略,设计了基于句型结构的EARM模型构造器。构造器包括成分识别器(recognizing machine)、关联分析器(analyzing machine)、体词特征规则(nominal rules)、谓词特征规则(predicate rules)、句型特征库(syntax library),如图3所示。
(1) 成分识别
建立EARM的关键在于识别实体及动作。本文借助复旦大学中文语料库,对其中的大量语句进行了人工标注,并参考朱德熙先生的观点(图2的句法成分对应关系),对汉语的体词及谓词类别特征进行了研究和总结,分别建立体词规则库和谓词规则库,概括了各类体词和谓词的特征。

图3 EARM构造器
体词特征包括:
① 名词;
② 动词;
③ 以名词为中心的偏正短语结构;
④ 以动词为中心的偏正短语结构;
⑤ 多个体词构成的联合结构。
谓词特征包括:
① 动词;
② 形容词,语句结构为体词+形容词或体词+副词+形容词;
③ 以谓词为中心的偏正短语结构;
④ 多个谓词构成的联合结构。
成分识别器根据特征规则识别实体及动作,下面介绍相关规则。
规则1实体识别规则: 以下结构特征识别为实体:
① 单独的体词;
② 多个体词形成的联合结构,如并列结构、紧缩结构等;
③ 以体词为中心的偏正结构,如“产生的烟雾”;
④ 谓词+体词构成的动宾结构,如“练习游泳”。
规则2动作识别规则: 以下结构特征识别为动作:
① 单独的谓词;
② 多个谓词构成的联合结构,如“进行分析”;
③ 以谓词为核心的偏正结构,如“奋勇地拼搏”。
(2) 关联分析
文献[17-18]指出,汉语句型包括主谓结构、动宾结构、偏正结构、补充结构、联合结构五类基本句型。由这五类基本句型可以构成连谓结构、同位语结构、双宾语结构、兼语结构等复杂句型。作者对各类句型特征进行了分析归纳,建立句型特征库。例如以下是连谓句型的特征。
特征1连谓句型特征: 实体1+动作1+实体2+动作2+实体3
EARM描述: 动作1(实体1,实体2),动作2(实体1,实体3)。
例如“他E/伸出A/手E/接过A/烟E”,对应描述为: “他伸出手”“他接过烟”。
以下是兼语句型的特征。
特征2兼语句型特征: 实体1+动作1+实体2+动作2,且实体2是动作2的施体。
EARM描述: 动作1(实体1,实体2),动作2(实体2)。
例如,“他的话E/让A/我E/落泪A”,对应描述为: “他的话让我”“我落泪”。
(3) 模型建立
借助体词特征规则和谓词特征规则,由成分识别器识别语句成分(体词、谓词),关联分析器检验句型结构并挖掘实体关系。设语句s长度为n,构建s的EARM的总体过程如下:
过程1语句EARM构建总体过程
Function: CreateEARM(s)
Begin
Sets=(w1,w2,…,wn);
Loop: eachwins:
Matchwwith Nomial and Predicate rules;
EndLoop
Return matchedresult;
Loop: eachsyntaxin Syntax library
If:resultmatchessyntax
Create a newEARMbyrule;
EndIf
EndLoop
Output all EARM;
End
1.4 实体调序机制
通常情况下实体与动作具有如下关联:
规则3一般实体—动作关联规则:
① 零元动作无实体与之关联;
② 一元动作通常为主谓结构,它的施体位于动作之前,如“我困了”;
③ 二元动作通常为主谓宾结构,动作的施体位于动作之前,受体位于动作之后,如“我擦桌子”;
④ 三元动作通常为双宾结构,动作的施体位于动作之前、直接宾语和间接宾语位于动作之后,如“他递给我一支烟”。
规则3总结了一般情况下的实体关联规则,但汉语句法结构较为灵活,有时会出现语句成分(实体、动作)缺省或移位的情况[19-20],例如,“桌子我已经擦了”。
根据实体的定义及规则1,作者认为体词的连续(紧邻)出现有多种情况,但实体的连续出现只能由以下两类情况引发:
① 双宾语或宾语从句,例如,“我告诉她这件事”;
② 语句成分移位现象。
若模型构造器识别到紧邻的实体a和b,从句型库匹配双宾语句型,若匹配失败则说明不属于①类情形而属于②类现象。检查匹配程度最高的句型特征进行实体调序。设语句s经过模型构造器识别后抽象出ne个实体,na个动作,k=ne+na。则s=(s1,s2,…,sk),实体调序过程如下:
过程2实体调序过程
Function: EntityReorg(s)
Begin
Sets=(s1,s2,…,sk);
Loop: eachsiins,i If:siandsi+1belong EntitySet //find continuous Entity Checkswith Syntax library; Loop:sdoesn’t match Double Object Syntax //entity recoganizing Get another nearestsyntax from Syntax library; Get location ofsi,si+1, predicatep; //assumesi+1is closer top Movesireference onsyntax; Get new sentences′; If:s′ matches Syntax library //s′ is a Chinese sentence Outputs′; EndIf EndLoop EndIf EndLoop End 例:s=“桌子我已经擦了”,句型为实体a(桌子)+实体b(我)+动作v(已经擦了)。b距离v更近。 ① 采用双实语句型实施调序:syntax=动作+实体+动作。将实体a(桌子)进行试移位,但对于a的所有位移结果s′,syntax均无法成功匹配,故syntax不是最佳句型; ② 再以主谓宾句型实施调序:syntax=实体+动作+实体进行匹配,将实体a(桌子)进行试移位,s′=“我已经擦了桌子”与syntax成功匹配。动作v为二元动作,动作描述为: 已经擦了(我,桌子)。 ③ 如果对实体b(我)进行位移,则匹配结果为s’=“桌子已经擦了我”,动作描述为: 已经擦了(桌子,我)。虽然动作施体和受体颠倒,但前文已经论述过聚类分析并不强调区别施体和受体,②和③的动作差别在聚类分析中可以忽略。 本节基于EARM进行文本表示。一个文本包含多个语句,每个语句对应一个实体—动作关联模型: EARM=Action(R(E))。合并各语句的实体和动作可建立文本的EARM表示模型。 语句中的各动作可能处于不同的层级。例如图1中动作“来到”、“瞻仰”处于第一层级,“长征”、“会师”处于第二层级。建立EARM时应当对多级动作实施层次分解,合并实体及动作关联。 本文认为EARM的动作通常没有分解的必要,语句分解主要是对关联实体进行递归分解,将复杂的实体分解为简单的体词或语句。汉语句型结构通常不超过二层,三层以下的语句成分对EARM的贡献已经较小。本文设定动作层次分解的最大深度为三层,采用底层替换规则将第三层的动作替换为简单句型。 规则4动作层次分解规则: ① 由高层向低层逐层分解; ② 将复杂语句分解为简单语句,例如1.3节连谓句特征和兼语特征; ③ 对复杂结构的实体,如宾语从句,从句+体词构成的偏正结构等,分解为主句和从句,主句实体简化为原实体的中心词,从句按照以上过程递归分解; ④ 如果存在第三层结构,则进行底层替换。 规则5底层替换规则: ① 偏正短语替换为该短语的中心词; ② 一元动作和二元动作替换为动作的谓词; ③ 三元动作替换为动作的直接宾语,如“他递给我一支烟”替换为“烟”; ④ 多个实体或动作构成的联合句型,按照①~③分别替换,构造成并列结构“X和Y”。 以图1的例句“市长E/来到A/西吉县将台堡E/瞻仰A/红军E/长征A/会师A/纪念碑E”为例,该语句属于连谓句型。动作层次分解结果如图4所示,语句分解为“市长来到西吉县将台堡”“市长瞻仰纪念碑”“红军长征和会师”三个简单语句。 图4 动作层次分解 (1) 合并语句模型 基于语句EARM构建文本的EARM,设动作Action1(R(E1))、Action2(R(E2)),有E=E1∩E2≠Ø。合并相同实体集E,即将中心词相同的实体进行合并;合并实体后若Action1=Action2,合并Action。建立文本的表示模型EARM=Action(R(E))。 (2) 实施权重量化 经过动作层次分解,复杂实体已经简化为简单实体,本节借助词频TF来量化实体和动作对表示文本的贡献。实体e在文本d中的权重量化为e在d中的词频,如式(2)所示。 WE(e,d)=TF(e,d) (2) n元动作a在文本d中的权重量化为a的所有动作元的共现频率,如式(3)所示。 (3) 其中TF(e,d)为实体e在文本d中的词频,TF(e1,Λ,en,d)为n个实体e1,Λ,en在文本d中的共现频率。 两个文本中,实体及谓词完全相同的动作是极少的,但相同的实体或相同的谓词是广泛存在的。作者将单个文本的EARM视为一个有向图结构,如式(4)所示。 EARM=G= (4) Node为图的节点集合,对应EARM实体集合E,∀i∈E,Wnode(i)=WE(i);Edge为图的边集,对应EARM谓词集合Action,∀i∈Action,Wedge(i)=WA(i)。两个文本的相似度即对应的实体—动作关联模型EARM的相似度,等价于有向图G的相似度。 本文在文献[21]中设计并实现了一种基于最大公共子图的文本相似度计算模型GBTS。本文沿用相关计算策略,将有向图GA、GB的相似度定义为其最大公共子图的节点相似度NS与边相似度ES之和,如式(5)所示。 Sim(A,B)=NS(A,B)+ES(A,B) (5) 节点相似度NS计算如式(6)所示。 (6) 边点相似度ES计算为如式(7)所示。 (7) 其中0≤α≤1为权重调节因子。若α→1,算法强调节点相似度;若α→0,算法强调边相似度。Sum()为权重累加函数,如式(8)所示。 (8) VSM和EARM均采用相同的聚类算法实施聚类,本节只讨论两种模型在提取文本特征和计算文本相似度时的差异。 设文本集为S=(t1,…,tk),包含N个特征项,实体及动作总数为M,文本集语句总数量为P;文本ti的语句数量为pi,动作层次分解后文本ti的语句数量为qi,文本集语句数量为Q。在一般情况下pi≤qiP≤QM VSM空间维度等于文本集的特征数目n,构建n维空间向量并计算两个文本的距离,时间复杂度为O(N),空间复杂度为O(N)。 EARM处理整个文本集需要分析P个语句,M个实体及动作,并存储Q个关联模型,时间复杂度为O(P+M),空间复杂度为O(Q)。EARM的时间复杂度及存储空间开销均比VSM更低。 此外,就单个文本ti的分析而言,EARM时间复杂度仅为O(pi),空间复杂度为O(qi),VSM时间复杂度和空间复杂度仍为O(N)。可见不论是单个文本的挖掘还是整个文本集合的分析,EARM都更有效率。 本文共包括两个实验: 语句实体动作分析实验检验EARM对语句分析的效果。聚类实验检验EARM计算文本相似度的准确性。本文语料库来自复旦大学中文语料库。分别选取艺术、哲学、经济、政治、军事、农业、通信、运输、法律、医药十个类别的文本进行实验。 从十个类别的文本中随机选取5 000个语句,共计五万个语句构成本实验的数据。本文对语句集进行了人工标注。使用无标注的数据集进行EARM句法分析,并与人工标注结果进行比较,由人工来评价EARM对每个语句的实体动作挖掘是否正确,根据EARM分析结果与人工标注结果的一致性进行评分,评分原则如下: ① 5分: 完全一致,即动作及实体分析完全正确; ② 3分: 基本一致,即动作分析正确且实体分析部分正确; ③ 1分: 部分一致,即动作分析不正确但实体分析完全或部分正确; ④ 0分: 完全不一致,动作及实体完全错误。 实验结果如表1所示。 表1 语句实体动作分析实验结果 续表 表1显示语句EARM分析总体上是有效的,各类别语句完全识别(5分)率为81.30%,错误(0分)率0.64%。各类别语句关联分析的平均得分为4.4~4.6。可见EARM实体和动作的挖掘是比较成功的。本实验错误的分析结果主要出现在歧义句,尤其是复杂的歧义句。如“咬死猎人的狗跑了”可能包括以下两种实体动作划分,①“咬死A/猎人的狗E/跑了A”;②“咬死猎人的狗E/跑了A”。模型在歧义句处理能力上尚嫌在不足。 本文在文献[22]中设计并实现了一种基于高斯加权的重构性K-NN聚类算法GWR K-NN。本小节设计了均衡样本实验和非均衡样本实验,采用GWR K-NN实施聚类。 均衡样本实验: 从语料库十个类别的文本中,每类选择1 000个样本,共计10 000个样本构成实验数据,分别使用经典的VSM和EARM模型进行文本表示,并使用GWR K-NN进行聚类,对比所得聚类结果的准确率和召回率。实验结果如表2所示。 非均衡样本实验: 在语料库十个类别中随机选取10 000个样本构成实验数据,每个类别的样本规模存在差距。分别使用经典的VSM模型和EARM进行文本表示,并使用GWR K-NN进行聚类。实验结果如表3所示。 表2 均衡样本聚类实验对比 表3 非均衡样本聚类实验对比 续表 类别Ci的准确率Pi、召回率Ri及Fi值定义如式(9)~式(11)所示。 均衡样本与非均衡样本下,各聚类F-Score值对比如图5、图6所示。 图5 VSM聚类性能对比 图6 EARM聚类性能对比 实验结果显示: 在均衡样本和非均衡样本下,基于EARM模型的聚类性能更为优秀。各个类别下,EARM聚类的准确率和召回率比VSM模型更高。非均衡样本下,军事类和农业类样本规模较小,传统VSM模型受到样本规模及样本分布的影响,效率明显下降。基于EARM的重构性K-NN能够很好地适应非均衡的样本空间,不论是均衡样本下还是非均衡样本下,EARM性能的波动都比VSM小。 本文面向文本聚类问题,设计并实现了一种基于实体—动作关联的文本表示模型EARM。模型构造器根据词库特征和句型特征挖掘实体和动作,构造EARM。对不同层级的动作进行动作层次分解,将复杂语句拆分简化为简单句型。本文采用统计学原理量化EARM模型的实体和动作的权重,基于加权的EARM模型计算文本相似度并实施聚类。 本文将EARM模型与VSM模型进行了对比实验,实验结果表明EARM是有效的。模型能识别常见的汉语句型和词汇,但是对歧义句的鉴别能力不足,下一步将引入多值函数或借助机器学习的方法来增强EARM处理歧义的能力。 [1] 宋巍, 张宇, 刘挺, 等.基于检索历史上下文的个性化查询重构技术研究[J].中文信息学报,2010, 24(3): 144-152. [2] 曹雷, 郭嘉丰, 白露, 等. 基于半监督话题模型的用户查询日志命名实体挖掘[J]. 中文信息学报,2012, 26(5): 26-32. [3] Kuznetsov V A, Mochalov V A, Mochalova A V. Ontological-semantic text analysis and the question answering system using data from ontology[C]//Proceedings of the 18th International Conference on Advanced Communication Technology. Pyeongchang, South Korea. IEEE, 2016: 651-658. [4] Shen Haiying, Liu Guoxin, Wang Haoyu, et al. Social Q&A: An online social network based question and answer system[J]. IEEE Transactions on Big Data, 2017, 3(1): 91-106. [5] 刘丹丹, 彭成, 钱龙华, 等. 《同义词词林》在中文实体关系抽取中的作用[J]. 中文信息学报,2014, 28(2): 91-99. [6] 刘丹丹, 彭成, 钱龙华, 等. 词汇语义信息对中文实体关系抽取影响的比较[J]. 计算机应用,2014, 32(8): 2238-2244. [7] Fei Wu, Daniel S W. Open information extraction using Wikipedia[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Pennsylvania, USA. Association for Computational Linguistics, 2010: 118-127. [8] 杨丹, 申德荣, 聂铁铮, 等. 异构信息空间中实体关联关系挖掘算法[J]. 计算机研究与发展,2014,51(4): 895-904. [9] Yuenhsien Tseng, Lunghao Lee, Shuyen Lin, et al. Chinese open relation extraction for knowledge acquisition[C]//Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics. Gothenburg, Sweden. Association for Computational Linguistics, 2014: 12-16. [10] Qiu Likun, Zhang Yue. ZORE: A syntax-based system for Chinese open relation extraction[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: Association for Computational Linguistics, 2014: 1870-1880. [11] Bai Xiaopeng, Li Bin.Comparing argument structure in Chinese verb taxonomy and Chinese propbank[C] //Proceedings of 2015 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology. Singapore: IEEE, 2015: 188-190. [12] Ma Hong, Lian Xin, Jiang Kun, et al. Research on delay ambiguity solving method based on Chinese remainder theorem[C]//Proceedings of 2014 International Conference on Information and Communications Technologies. Nanjing, China. IET, 2014: 1-4. [13] 朱德熙. 语法答问[M]. 北京: 商务印书馆,1985. [14] 范婷. 现代汉语歧义表层结构形式及其分化方法研究[D]. 成都: 四川外语学院硕士学位论文,2012. [15] 怀宝兴, 宝腾飞, 祝恒书, 等. 一种基于概率主题模型的命名实体链接方法[J]. 软件学报,2014,25(9): 2076-2087. [16] 邓擘, 郑彦宁, 傅继彬. 汉语实体关系模式的自动获取研究[J]. 计算机科学,2010,37(2): 183-185. [17] 朱德熙. 语法讲义[M]. 北京: 商务印书馆,1982: 38-55. [18] Huang C T J, Li Y H A,Yafei Li. The Syntax of Chinese[M]. America: World Book Inc,2013: 108-113. [19] 赵元任. 汉语口语语法[M]. 北京: 商务印书馆,1979. [20] 何钟豪, 苏劲松, 史晓东, 等. 引入集成学习的最大熵短语调序模型[J]. 中文信息学报,2014,28(1): 87-93. [21] Liu Zuoguo, Chen Xiaorong. Mapping texts into graphs: An improved text similarity algorithm[C]//Proceedings of 2012 2nd International Conference on Computer Science and Network Technology. Changchun: Springer, 2012: 1357-1361. [22] 刘作国, 陈笑蓉. 高斯加权的重构性K-NN算法研究[J]. 中文信息学报,2015,29(5): 112-116.2 文本表示
2.1 动作层次分解

2.2 建立EARM
2.3 文本相似性度量

2.4 计算复杂性分析
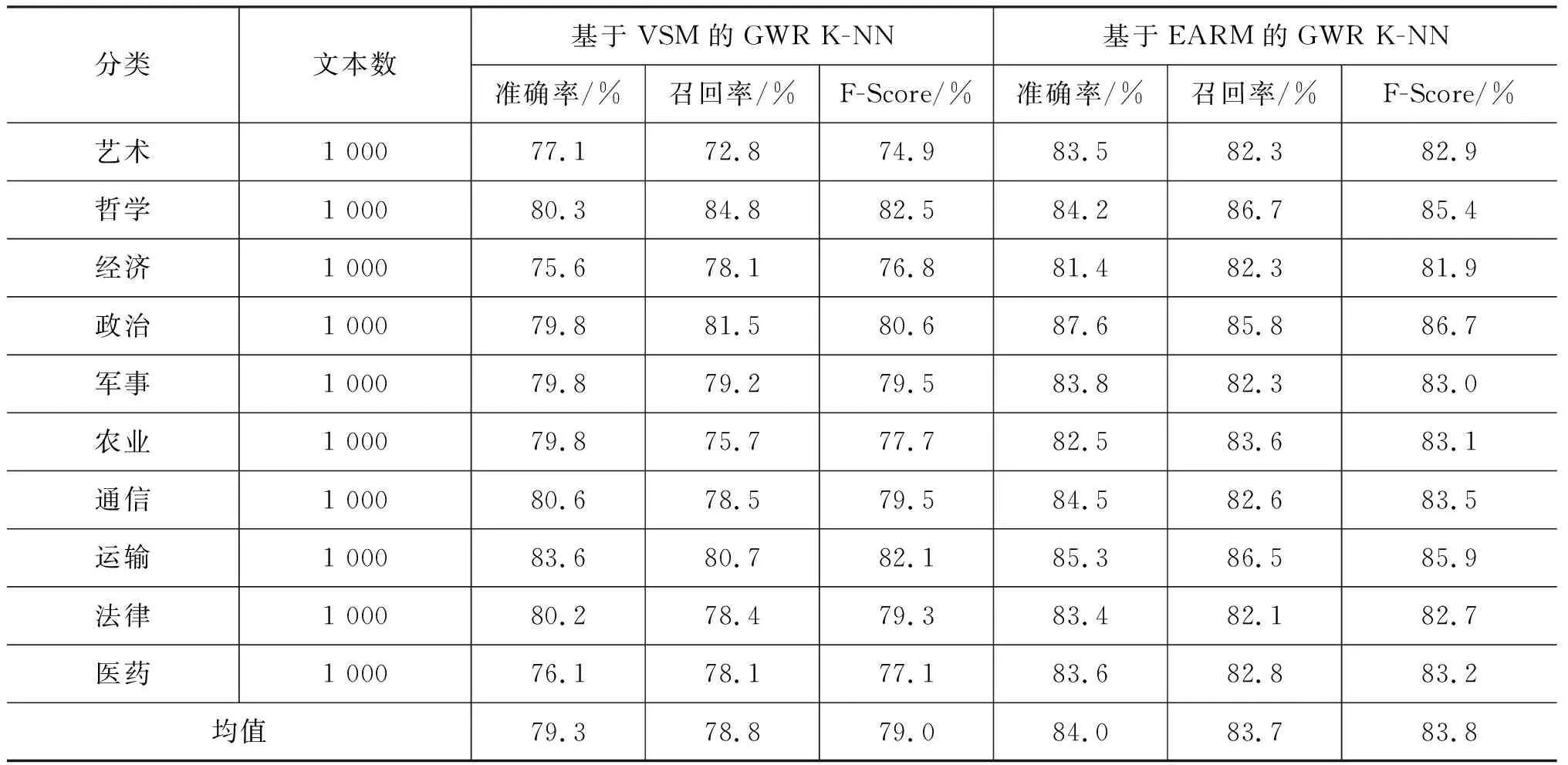
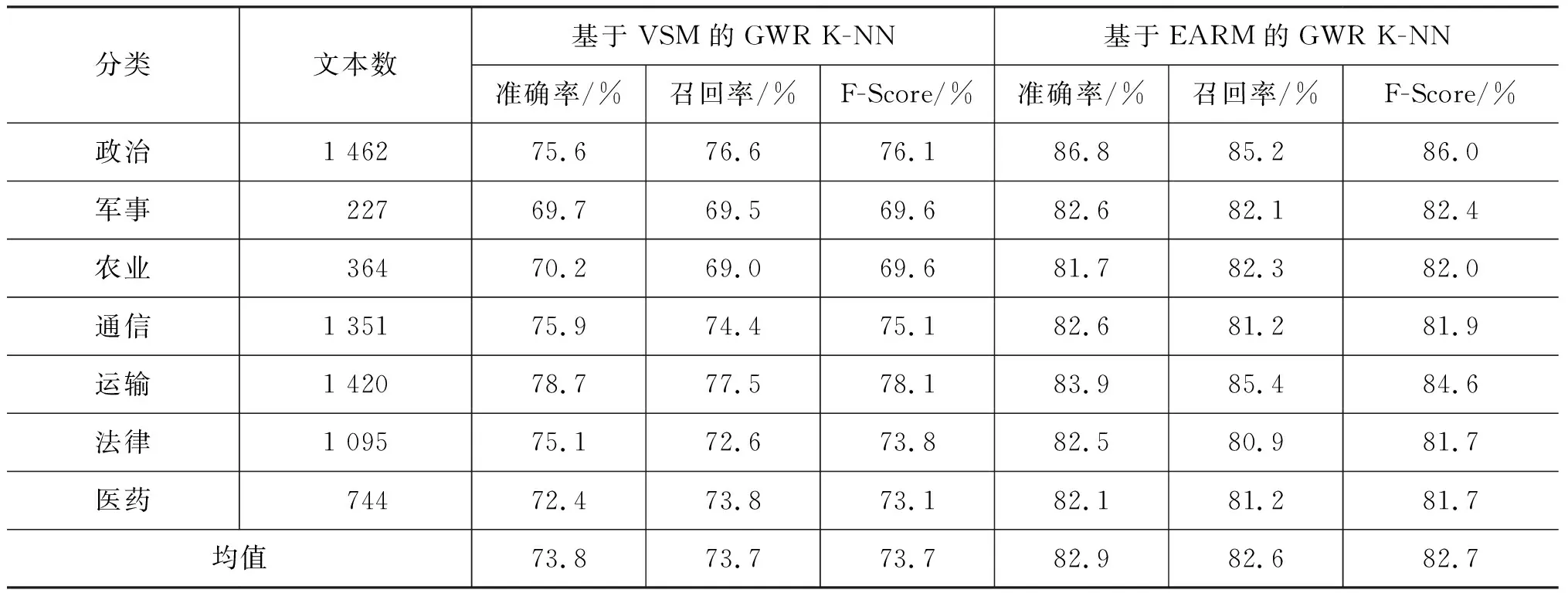
3 实验分析
3.1 语句实体动作分析实验


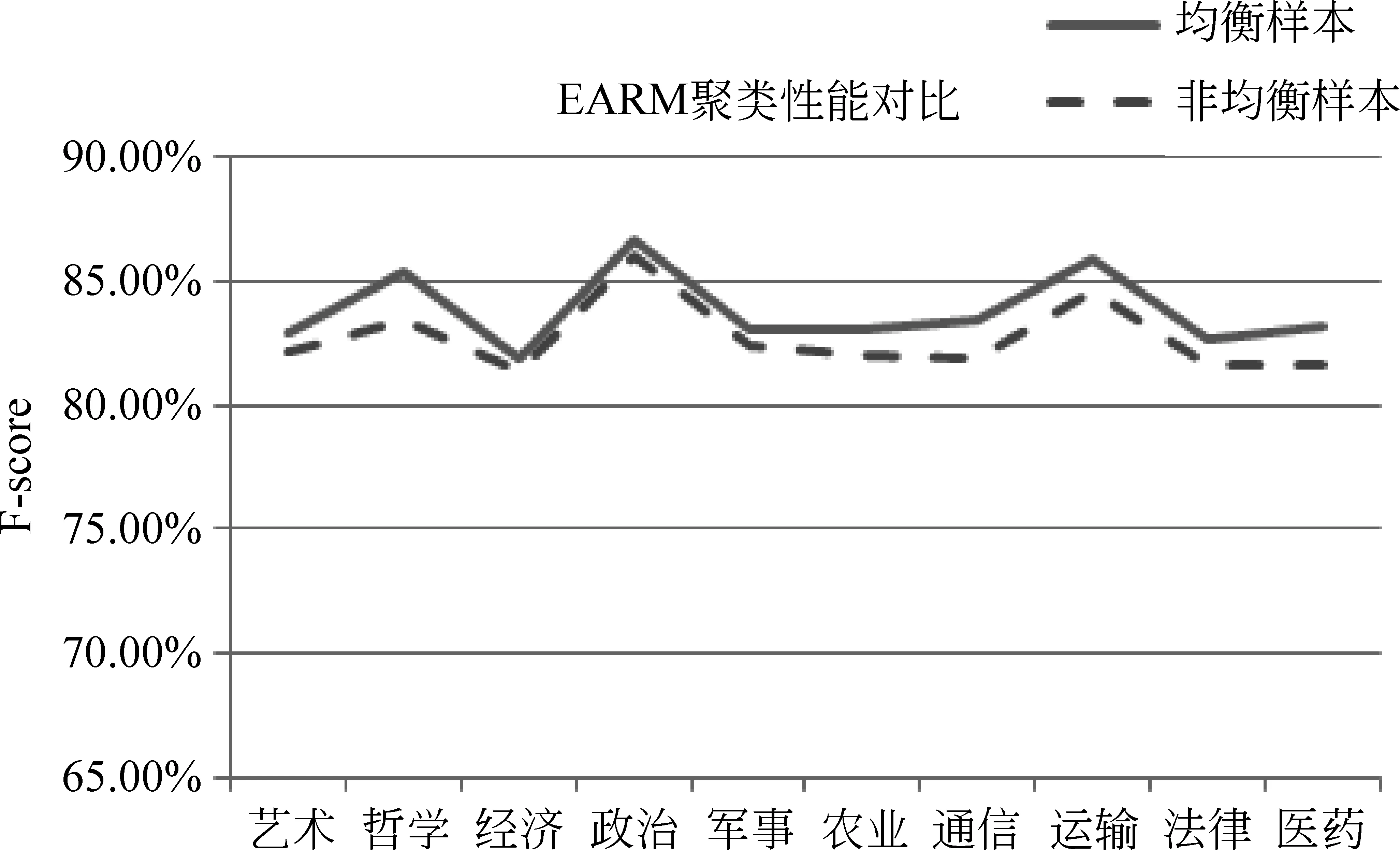
3.2 文本聚类实验


4 结束语
