一种基于Python的商品评论数据智能获取与分析技术
2018-06-13孙隽韬陈炳丰黄爱华
孙隽韬,陈炳丰,黄爱华
(1.电子科技大学格拉斯哥学院,成都 611731;2.广东工业大学计算机学院,广州 510006;3.广东工业大学发展规划处,广州 510006)
0 引言
随着互联网技术的发展,网上购物已然成为社会的主流购物方式,而这种购物方式存在普遍的弊端,人们无法在购买商品时对其好坏进行评判,而只能通过商家的描述与买家的商品评论来辨别。对于卖家对商品的描述多数存在不确定因素,即买家无法辨别商家所陈述的是否属实。因此,买家对商品的评论成为评价该商品的重要因素。然而,对于购物者而言,要在短时间内获取大量评论信息并加以分析是不现实的,而在大量的评论样本集合中抽取个别样本分析会导致估计的评价缺乏准确性与可信性,因此需获取大量的评论数据并且加以分析才可得出可靠准确的评论结果。
为解决上述问题,本文通过使用Python爬虫,从网络商城上获取每一件商品下的所有评论,并且将这些数据持久化地保存于电脑硬盘中,同时对于已保存的评论数据,再将其通过分词手段将句子分割成若干词语,并对分割出的词语进行筛选,获取对评论商品有意义的特定词语,从而达到分析评论的目的。
1 相关工作
网络爬虫是获取互联网信息的重要工具。目前对于网络爬虫的研究与技术有很多[1-3],国内也有很多针对社交平台的网络爬虫[4-5],而社交平台上的信息抓取同获取网购商品评论是类似的。同时,针对于中文句子的分词处理,现有的基于不同语言的函数库如NL⁃PIR、结巴分词等都可胜任。
1.1 Python爬虫
凭借其拥有强大的函数库以及部分函数对获取网站源码的针对性,Python成为能够胜任完成网络数据爬取的计算机语言。对于大量网络信息的爬取,周中华等[4]针对新浪微博的数据获取开发了一款从用户登录到关键字匹配的网络爬虫,并采用并行处理方式提高爬虫效率。同样,李俊丽[6]也提出了基于Linux的Python多线程爬虫程序设计方法以获取大量微博数据,通过和基于开方API的爬虫程序进行比较,在较长时间下,基于Linux的Python多线程爬虫性能更优异。
1.2 中文分词
对于中文自然语言的词语分割,俞鸿魁等[7]采用HMM模型识别出嵌套了人名、地名的复杂地名与机构名,并在对大规模真实语料库的封闭实验中,人名、地名和机构名的F-1值分别达到92.55%、94.53%、86.51%。袁俊[8]对基于HMM连续语音识别系统声学层的Viterbi算法进行了改进,以提高解码效率。而结巴分词系统[9]在算法上采用了基于汉字成词能力的HMM模型以及使用了Viterbi算法,使得该系统在基于Intel Core i7-2600 CPU@3.4GHz环境下拥有1.5Mb/s的最大分词速度。
1.3 分布式文件存储
由F.Chang等[10]提出的Bigtable分布式存储系统提供了一个灵活的、高性能的解决方案用来管理庞大数量的结构化数据;同样为NoSQL类型的数据库还有Redis、MongoDB、HBase等。朱建生等[11]则验证了采用NoSQL数据库可极大缩短数据搜索时间,提高数据读写效率和横向拓展能力,即验证了NoSQL数据库技术在处理大数据查询和分析中的高可用性。
2 数据智能获取技术
将商品评论信息进行定性评判有四个部分,即数据筛选获取、分词处理、数据定性、数据整合。
2.1 评论数据获取
目前,主流的网络商城有淘宝、天猫、京东、苏宁易购等,所有的网络商城会针对不同的商品为其进行分类,以方便消费者对所要购买的商品进行合理的浏览,而在同一类别下有数目庞大的商品品种,其评论数目之多,无法采用人工方法去收集数据,而采用爬虫来解决评论数据获取的问题。

图1 爬虫获取评论数据流程
数目庞大的评论需要一条清晰的收集思路。对于消费者而言,最为重要的是同类商品不同种之间的对比,通常的,在网上商城输入的搜索关键词即为产品的分类,商品分类的粗细与关键词的多少为直接关系。在搜索关键词后得到的一系列商品便是目标商品,而目标商品的评论便是所需获取的数据。
2.2 分词处理
对于一个句子而言,往往可以通过其中的字词的使用从而判定该句子的语气与性质,针对于这一流程,为了让电脑能同样准确的识别出一个句子的意义,则需要建立字典,通过运用字典来比对句子中的词语,从而对句子意思进行判别。而在比对的过程中,需要根据自然语言的断句规则先将句子进行拆分,即为分词,从而得到有意义的词语,这一步运用结巴分词系统来得以实现。

图2 分词处理示例
2.3 评论定性
一条评论中可以有很多种的表述,对于商品的各方各面都会有所评判,因此,字典不仅仅为评论的定性提供标准,也要为评论对商品所评价的方面提供基础。通过建立两个分别定性与分类的字典,来达到对评论进行精准分类与定性的目的。
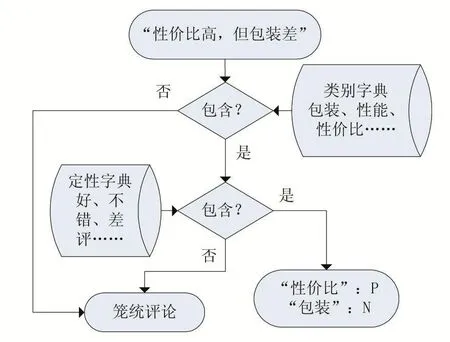
图3 评论的判定过程示例
先使用分类字典与分词后所得的词语进行比对,得出评论中所涉及到的评论方面,再通过使用定性词典对该方面之后的描述进行判定,所得结果输出是与否,即表为褒义评价或贬义评价。而对于未能识别的评论,或者提到该方面却为识别出性质的评论,则将其判定为笼统评论,如图3所示。
2.4 结果处理
在每一条评论进行处理之后,经过分类处理,使用分布式存储系统将处理后评论系统性地存储进数据库中。完成所有的评论收集工作,得到一个分类详尽的评论分析列表,如图4例中所示,列表可清晰罗列出每一条评论所评价的方面及褒贬。
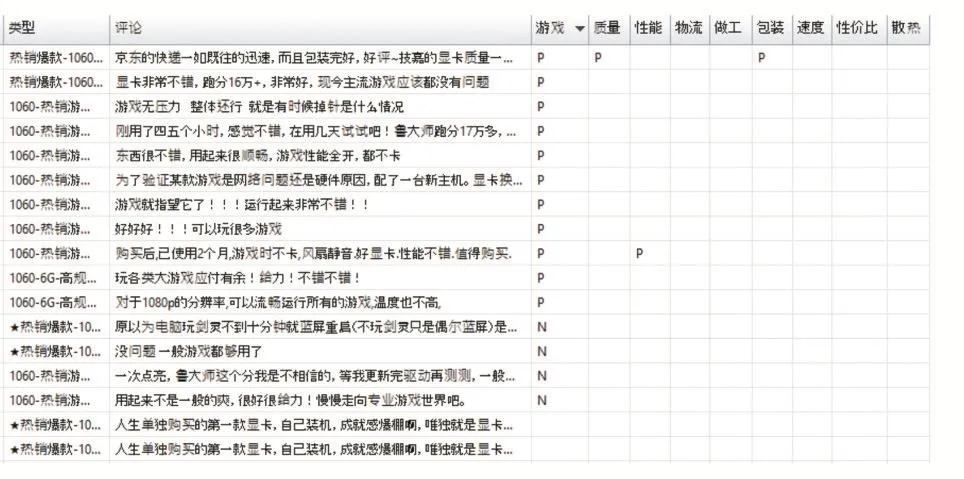
图4 数据储存后的示例视图
同时,对列表数据进行整合统计,可以得出对该商品所有评论的分析统计,进而全面详细地了解商品各方面的好坏。最后所得出的结论可直接反馈给消费者,由此完成通过大量评论数据的分析而反映出的商品问题。
3 实验结果与分析
以京东网络商城中“技嘉显卡”目录下的部分商品为测试数据,通过对其评论数据进行获取与分析,并且通过分析后所得结果的整合与统计,所得结论用以验证该设计方法的可行性。

表1 七款显卡商品关于九个方面的褒贬评价
3.1 实验数据集获取
该实验中共获取20367条评论数据,分别属于7种商品的评论列表中,其中GTX 1060系列产品的评论数为6455条,GTX 1080为1439条,GTX 1070系列有3423条,GTX 1050Ti中有6454条,GTX 1050系列有1153条,GT 1030系列拥有577条,以及GTX 1070Ti系列的866条。
3.2 实验数据处理
对于显卡这类商品而言,消费者的主要关注点在于以下九个方面:游戏、质量、性能、物流、做工、包装、速度、性价比、散热;对于形容这九个词的描述,则建立为定性字典。将分词处理后的评论与字典比对,得出评论中是否所涉及到如上九个方面,以及对这些方面的评价,实验中用“P”表示了积极评价(Positive)以及用“N”表示了负面评价(Negative)。在对数据的统计中记录该商品每一方面所拥有的“P”与“N”的个数,从而可直观的对商品进行分析。
3.3 实验数据分析
对实验所得数据经过处理之后,得到的是评论面向不同方面的性质统计,如表1所示,共列举了所有七款商品关于九个方面的褒贬评价统计。在这些评论中,共有3511条评论是可以被成功识别出在这九个方面有所评价。
表2所示为在被成功识别出的评论中,关于其中三款显卡商品评论的判断与评论本意相比的正误统计,以及得出的识别正确率。

表2 其中三款商品关于成功识别评论的识别正误统计
对于识别率与正确率,其计算公式为:
识别率(正确率)=成功识别数(识别正确数)/样本总数(成功识别数)×100%
由上述数据可得知,评论的识别率为17.24%,可知对于这九个方面的评论数据识别并不多,约6条评论中有1条被成功识别,评论的无法识别是因为其中没有有关这九个方面的关键字,或者即使有,也无法识别出其所表达的褒贬含义,即如图5所示,而京东评论中则存在多数此类只有笼统而无具体意义的评论。但是对于成功识别的评论而言,其定性的正确率高于90%。

图5 评论无法识别例子
同时,对表1数据进行分析可知,对于入门级显卡而言(GT 1030、GTX 1050),消费者普遍在游戏、性能与做工上存在抱怨,而中高端显卡(GTX 1050Ti、GTX 1060、GTX 1070)消费者不满的方面多数集中在游戏、性能、做工与包装上,顶级游戏显卡(GTX 1070、GTX 1070Ti、GTX 1080)则是表现在包装、做工及散热上。这一统计说明入门低端显卡不能满足消费者对性能与游戏的追求,同时低价位的显卡也体现了做工上的问题;中高端显卡有着同样的问题,且体现了与低端显卡的多一点需求:包裹的包装问题;而消费者对于顶级显卡则有着良好散热的需求。因此,这符合显卡市场的需求规律,继而验证了评论识别的准确性。
4 结语
本文关于对网络商城评论的获取与分析的方法给予了一般消费者一个快捷的手段去获取商品的评论统计,进而方便了消费者在选购商品是对于商品更客观的对比。通过爬虫先对网购商品评论进行批量获取,对已获取的评论进行分词与比对分析,得出评论对于商品某些方面的定性评判。该方法可满足不同商品对于不同方面的定性评判,因而具有普遍适用性。
[1]Boldi,Paolo,et al.Ubicrawler:A Scalable Fully Distributed Web Crawler.Software:Practice and Experience[J],2004,34(8):711-726.
[2]Ahmadi-Abkenari F,Selamat A.An Architecture for a Focused Trend Parallel Web Crawler with the Application of Clickstream Analysis[J].Information Science,2012,184(1):266-281.
[3]郑冬冬,赵朋朋,崔志明.Deep Web爬虫研究与设计[J].清华大学学报(自然科学版),2005(S1):1896-1902.
[4]周中华,张惠然,谢江.基于Python的新浪微博数据爬虫[J].计算机应用,2014,34(11):3131-3134.
[5]陈政伊,袁云静,贺月锦,武瑞轩.基于Python的微博爬虫系统研究[J].大众科技,2017,19(08):8-11.
[6]李俊丽.基于Linux的python多线程爬虫程序设计[J].计算机与数字工程,2015,43(05):861-863+876.
[7]俞鸿魁,张华平,刘群,吕学强,施水才.基于层叠隐马尔可夫模型的中文命名实体识别[J].通信学报,2006(02):87-94.
[8]袁俊.HMM连续语音识别中Viterbi算法的优化及应用[J].电子技术,2001(02):48-51.
[9]Github-fxsjy/jieba:结巴中文分词[EB/OL].https://github.com/fxsjy/jieba/,2018-01-20.
[10]F.Chang,J.Dean,S.Ghemawat,W.C.Hsieh,D.A.Wallach,M.Burrows,T.Chandra,A.Fikes,R.E.Gruber.Bigtable:A Distributed Storage System for Structured Data[J].ACM Transactions on Computer Systems(TOCS),2008,26(2).
[11]朱建生,汪健雄,张军锋.基于NoSQL数据库的大数据查询技术的研究与应用[J].中国铁道科学,2014,35(01):135-141.
