基于数据挖掘的图书馆读者借阅系统设计
2018-06-12阎星宇
阎星宇
摘 要: 分析图书馆读者借阅对提高图书借阅率、统计图书量具有重要意义。传统图书馆读者借阅系统主要通过以往读者借阅信息对图书借阅率、图书量所需增减情况进行分析,忽略了图书库存量对读者借阅率的影响。为此,提出并设计基于数据挖掘的图书馆读者借阅系统。在分析其整体结构的基础上,给出详细的硬件设计过程,引入数据挖掘方法,实现对软件部分的设计。实验结果表明,采用改进图书馆读者借阅系统可实现图书的高速借阅,提高借阅率及借阅准确度,具有一定的实用性。
关键词: 数据挖掘; 图书借阅率; 读者借阅信息; 借阅系统; 图书库存量; 系统设计
中图分类号: TN919.25?34 文献标识码: A 文章编号: 1004?373X(2018)12?0180?03
Abstract: Library reader borrowing analysis is of great significance in improving the borrowing rate of books and obtaining the quantity of books. The traditional library reader borrowing system mainly analyzes the increase and decrease demand of book quantity and book borrowing rate according to the past borrowing information of readers, which ignores the impact of book inventory on the reader borrowing rate. Therefore, a library reader borrowing system based on data mining is proposed and designed. On the basis of analyzing its overall structure, the detailed hardware design process is given, and the data mining method is introduced to realize the design of the software part. The experimental results show that the improved library reader borrowing system can achieve the high?speed borrowing of books, and improve the borrowing rate and borrowing accuracy, which has a certain practicability.
Keywords: data mining; book borrowing rate; reader borrowing information; borrowing system; book inventory; system
design
0 引 言
图书馆作为搜集、整理、收藏图书资料供人阅览、参考的机构,是知识文化传播的重要阵地,也是图书信息聚集和分散的主要场所。其资料繁多,内含大量的信息数据。当前,图书馆内图书数量的逐年递增,在如此庞大的图书规模中找到读者感兴趣的书籍非常困难。传统图书馆读者借阅系统存在借还流程长、盘点和查找工作繁琐、借阅和安全脱节、图书管理员与读者的满意度低、条形码技术缺陷等问题,已经不能满足现有图书管理的需求,且搜索功能的不强大,搜索结果众多,读者发现在自己感兴趣的书籍十分困难[1]。在这种情况下,研究并设计一种能够整合读者行为数据,读者兴趣爱好的新图书馆读者借阅系统,成为该领域亟待解决的问题。对此,本文结合数据挖掘,根据读者已有的历史信息智能分析读者的兴趣爱好,运用数据挖掘技术全面、准确地给读者推荐满意的书籍,帮助读者完成快速借阅图书。
1 借阅系统整体结构分析
本文设计的图书馆读者借阅系统主要由图书借还模块、图书管理模块、读者管理模块、图书盘点模块和账户管理模块组成,最终结果在显示器显示借阅结果。为了提高借阅系统的借阅率及图书推荐准确度[2],在其控制层添加数据挖掘的功能,通过实现对图书数据进行挖掘,缩短查找图书所用时间,提高借阅率。其图书馆读者借阅系统整体结构如图1所示。

由图1可知,系统通过读者输入要求对其内容在控制层进行判断,合理调度处理功能模块。在模块中进行借书、还书、图书管理、读者管理、图书盘点模块及账户管理等功能[3]。而视图层为读者提供出错处理及借阅信息的显示,出错处理负责处理出错信息,并将出错信息返回给读者。整体图书借阅系统启动并初始化以后进入到主界面等待读者的输入,当用户输入图书信息时,首先要确定读者的身份[4],确认完毕方可进行下一步图书借阅。每个子系统的界面都会为各种功能模块提供使用方法,控制层在对读者输入的信息进行判断,调用相应的模型处理输入信息。
2 硬件部分设计
在硬件设计过程中,主要对借书模块、读者管理模块、数据库及控制层进行设计分析,具体步骤如下:
1) 借书模块主要通过读者及管理员两部分进行使用。图书管理员借阅是对读者借阅图书的记录进行管理,主要包括查询超期的读者、催促读者还书等。通过不同列表的不同数据,在超期记录中向用户发送催还信息,在预约记录中向读者发送预约信息,为了避免记录过多,可在当天或前两天进行记录[5]。图书管理员可以使用该模块实现对书库中图书情况进行查询,也可通过图书借阅实现读者对图书的借阅及续借[6]。
2) 读者管理主要目的是为管理人员提供读者类别、读者信息、借书卡等日常维护管理。其中读者类别主要是对读者信息进行查询、增加、修改及删除等。读者信息管理主要对读者进行查询、增加、修改及注销。借书卡管理主要是办理借书卡或者对借书卡进行挂失、注销[7]。整体的读者管理部分由读者管理员进行负责,对读者进行管理时,管理员身份需要验证,并在系统初始化部分对读者信息进行分类及对读者类型进行添加[8]。读者类型的添加也是挖掘读者信息的前提条件,读者管理员可以根据实际需求调整是否对新的读者类型进行添加或对已有读者类型进行修改、删除。
3) 数据库设计。为了更好地与借书模块结合,系统的用户采用r_user表,及外扩的sys_role,读者角色关联表sys_user_role,菜单表sys_menu[9],角色菜单关联表sys_role_menu等辅助表。
4) 控制层设计。在控制层添加数据挖掘的功能形成数据仓库,将挖掘的图书相关数据存储在数据仓库中。而数据仓库主要是为管理决策模式的设置提供对应支持信息,用于读者数据处理的决策支持,主要处理方式以挖掘分析为主。其与数据库的区别为数据库直接与日常操作处理数据相关,数据仓库主要是应用于高层决策分析,主要来源于对数据库的日常业务操作[10],主要为图书借阅系统提供读者决策支持的当前及历史数据。数据仓库可有效地把操作数据集成在统一的环境中,為读者提供决策型数据,并对其余模块进行访问。图书数据挖掘的引入可让读者更快、更方便地查询所需图书信息,缩短查询图书所用时间,提高借阅率。
3 软件部分设计
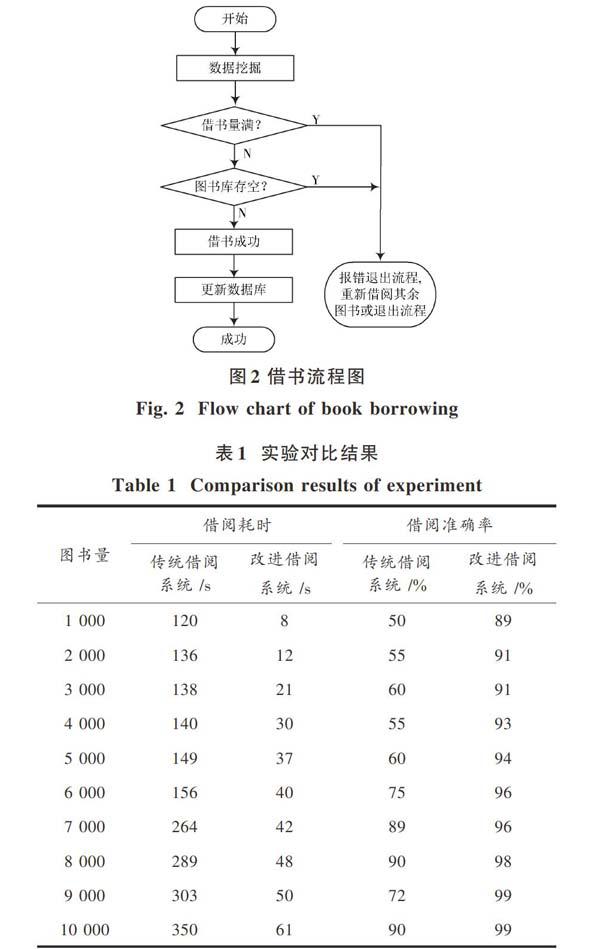
在软件设计部分,主要针对借书流程进行分析,其实现流程如图2所示。其中,查询借书量是从读者借阅数据库里查找读者借书量的信息,加入借书量为该图书馆账户借书量的最大值时,则进行报错提示,重新进行其他书籍的借阅;反之,假如借书量未达到最大值,则从图书数据库中搜查该书是否有足够的库存,有则借阅成功,同时进行图书数据库更新。由图2可知,流程开始后,首先通过用户数据挖掘确定用户信息,通过挖掘图书数据确定图书信息;其次检验读者身份;然后调用借书模块功能完成对图书库出借信息的填写(此步骤显示借书量是否已经达到、图书库存是否为空,若均存在显示报错,退出借书流程,重新进行借书);最后将借书结果显示在显示器上,即图书借阅成功(此步骤与借阅成功后对图书库信息的更新同步进行)。
4 系统验证
为了验证改进系统在图书馆读者借阅图书时的有效性,设置其开发环境为eclipse 5.8, apache?tomcat 6, MySQL?9,后台开发框架为Spring Framework 6.0, Spring MVC 4.0, MyBatis 3.2+; 前台开放框架为Jquery 1.9, Twitter Bootstrap 2.3.1。采用传统借阅系统与改进借阅系统为对比,以图书借阅耗时及图书借阅准确率为指标进行实验分析,结果如表1所示。
从表1可知,在图数量一定的情况,采用传统借阅系统时,其借阅耗时随着借阅图数量的增加逐渐增大,最高时达到了350 s,最低时耗时为120 s;其图书借阅准确度也随着图书量的增加而增加,但其准确度出现了忽高忽低的现象,不稳定,最高时为90%,最低时为50%;相比传统方法,采用改进方法时,其借阅耗时及准确度均随着图书数量的增加而延长,但未出现忽高忽低的现象,稳定性较好。耗时最高为61 s,最低为8 s,节约时间最高289 s,最低112 s,准确度最高为99%,最低为89%,最多提高了39%,最少提高了9%,具有一定的实用性。
5 结 论
本文研究围绕传统借阅系统存在因借阅耗时长导致的借阅率低、准确性差的问题,提出并设计了基于数据挖掘的图书馆读者借阅系统,得到结果如下:通过控制层构造出读者对图书的借阅信息,并利用数据挖掘算法对读者信息进行挖掘,减少搜索空间,降低借阅耗时;通过验证发现,相比传统借阅系统,改进系统的图书借阅率及图书借阅准确率均有提高。
参考文献
[1] 韩吉义.基于数据挖掘技术的高校图书馆档案信息管理平台的构筑[J].山西档案,2015(6):61?63.
HAN Jiyi. Data?mining technology based construction of archival information management platform for university libraries [J]. Shanxi archives, 2015(6): 61?63.
[2] 茹文,忻展红.图书馆借阅数据分类信息的关联性研究[J].北京邮电大学学报(社会科学版),2016,18(1):14?19.
RU Wen, XIN Zhanhong. Associations between different classifications of library circulation data [J]. Journal of Beijing University of Posts and Telecommunications (Social sciences edition), 2016, 18(1): 14?19.
[3] 赖剑菲,江舟.基于WLAN的图书馆读者行为采集分析平台框架研究[J].图书情报工作,2015(10):67?71.
LAI Jianfei, JIANG Zhou. Study on collection and analysis platform framework of library readers′ behaviors based on WLAN [J]. Library and information service, 2015(10): 67?71.
