依赖混沌流形指数方程的宜居城市指数评价模型研究
2018-06-12龚芳
龚 芳
(安徽新华学院 信息工程学院,合肥 230088)
宜居城市指数评价在行业中是广泛存在的,同时也是不能忽视的重要问题,归属于有序命题类问题[1].评价类问题在人们的平时生活中是很常见的,随着信息技术的飞速发展,各个行业都面临着艰巨的任务与挑战,最为明显的就是宜居城市指数[2-4].对于随机性导致的不确定性与模糊性导致的不确定性可以双管齐下,目前得到了广泛的应用[5].以当前数据和历史行为为依据,采用结合数据理论与贝叶斯法对信用卡的欺诈行为进行检测[6-7].把群体评价与传统数据理论加以整合,提出了集成评价方法.
本文提出了一种利用混沌流形指数方程的宜居城市指数评价模型,以层次聚类方法混沌流形指数方程为依据的,首先对海量的信息进行采集,接下来便是预处理,预处理完成后,形成多个簇,再根据数值数据和序数数据的特点对质心进行计算,质心则作为该簇的代表信息.质心需要进行基本混沌流形(Basic chaotic manifold,BCM)处理.最后,以混沌流形指数方程为基准,对各数据进行组合,从而形成对宜居城市指数的评价.
1 混沌流形指数方程
混沌流形指数方程理论是针对有序类问题的,定义如下:

①当μ1=μ0时,有f(μ0,μ2)=f(μ2,μ0)=μ2;
②当μ1≠μ0且μ2≠μ0时,有:
其中,
μ0∈R,满足μ0(si)=0,对i=1,2,…,n
∀μ1,μ2∈R.g∈[1,n],g表示最有可能为真之命题的序号.
对于上文中出现的组合函数,对其进行详尽的分析,把定义1中的式(1)改写成:
其中,
其中,w1+w2=1,Δ1,Δ2>0(两个待定常数),一般可选Δ1=0.2,Δ2=0.8.
若被组合的数据个数m>2时,式(2)则为式(3):

(3)
其中,
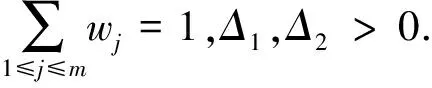
2 基于混沌流形指数方程评价模型构建
本文把混沌流形指数方程恰到好处地引入宜居城市指数性评价中,提出了新颖的混沌流形指数方程宜居城市指数评价模型.算法基本步骤如下:
(1)以A1,A2,…,An为依据,对数据的规模与特点进行采集,确定模型的分支因子B、阀值T与叶节点中子簇数的最大值L.设定初始值,B=10,T=0,L=15;
(2)采用混沌流形指数方程模型对所采集到的海量数据进行编号;
(3)以步骤(2)的聚类结果为依据,对每个簇的质心数据Q1,Q2,…,Qr进行计算;
(4)以应用问题的特点为依据,确定辨识框架:{H1,H2,…,Hk};
(5)对模型库建立模糊模型标记.以H1,H2,…,Hk的一定量样本数据为依据,针对某个属性Ai,确定属性的MAX(最大值)、MIN(最小值)与AVG(平均值),以这3个属性值为基准,建立一个三角形模糊数来描述命题Hj.从而对应的隶属函数μAiHj(x),i=1,2,…,n,j=1,2,…,k也随之建立;
(6)确定数据的观测函数.对于属性Ai,需要计算出模型库中全部模型标记属性Ai的平均方差,再依据平均方差与当前测量值,进而扩展为三角模糊数,从而形成相对应的传感器观测函数gAi(x),i=1,2,…,n;

(8)根据簇的质心信息,依据选定的属性A1,A2,…,An,对步骤(6)~(9)加以重复,从而生成质心对应的n条数据;
(9)使用组合公式,结合步骤(10)形成反映簇Ci的合成数据cmi(Hj),i=1,2,…,r,j=1,2,…,k;

(11)利用组合公式(3),结合步骤(9)的r条合成数据进行融合,得到融合结果.
3 仿真实验
本文选取了对产业指数影响最大的两个变量作为代表进行判断,这两个变量分别是产业规模与产业数量.设置了两个地区,编号分别为Zone1和Zone2内,同时布置了3个与4个数据采集点.在本文中采用了两种方法进行融合,分别是(Computable General Equilibrium,CGE)模型与本文模型,以融合结果为依据,从而对某地区内、某时间段内的宜居城市指数进行评价.
3.1 数据的生成和组合
采用广义三角模糊数对相关函数加以定义,分别是产业规模隶属函数μti(x)和产业数量隶属函数μhi(x),其中,i=1,2,…,n.
(4)
(5)
本文以Zone1的数据采集为例加以说明,根据平均方差把测量值扩展为可以表示的三角模糊数(15.25,19.25,23.25),传感器的观测函数gt1(x)为
(6)

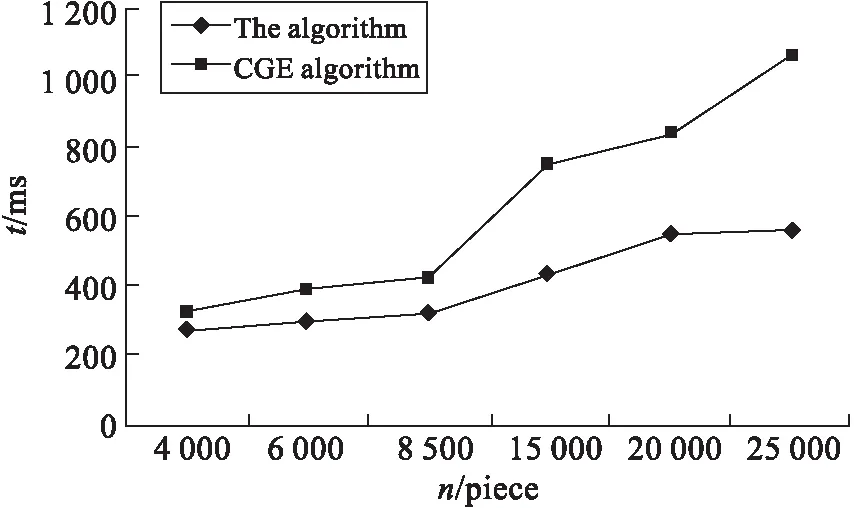
图1 CGE模型与本文模型运行时间比较

(7)
对所有新生成的数据加以利用,采用领域相似度理论进行组合就可以得到新的融合结果,根据融合指数进一步判断该地区在某个时间段内产业指数的合理程度.
3.2 大规模数据融合结果分析
本文中,以Zone1和Zone2两个区域为基准,对3个连续的时间段采集了6组数据,数据规模4 000~24 000不等,采用的模型是CGE模型与本文模型.结果见图1与表1.在图1中,对两种模型多耗费的时间进行对比,由实验结果可知:本文模型所耗费的时间更少,优势是显著的,即使是数据量继续增加.在本文的模型中,时间的增长速度也要比CGE模型慢着很多,如果数据的规模超过了15 000条的时候,CGE的模型耗用的时间就更多了,达到本文模型的两倍之多.
在表1中,对本文模型与CGE模型的最后评价结果进行比较,很明显:本文模型与CGE模型对数据的融合处理是保持高度一致的,差别不是非常突出.
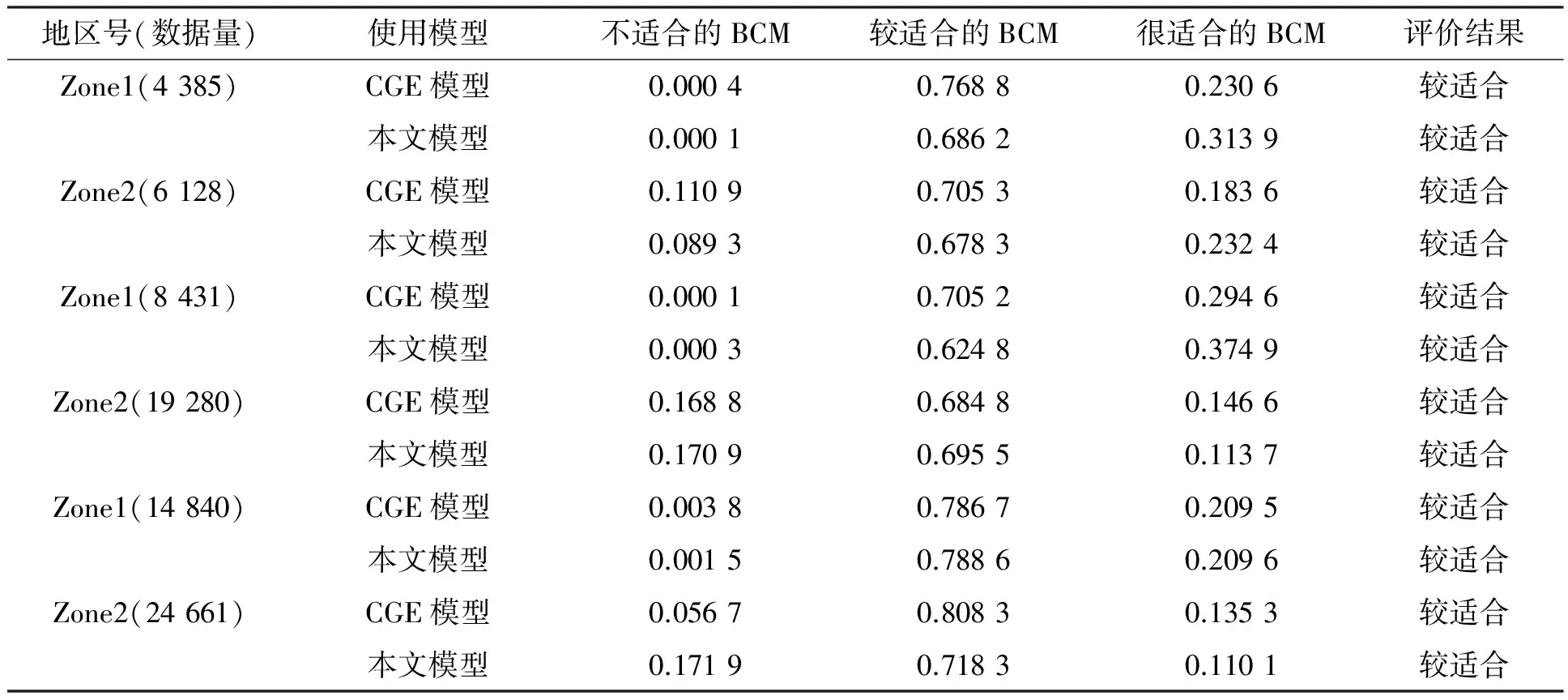
表1 CGE模型与本文模型最终融合结果的比较
综上所述,可得出:与传统混沌流形指数方程进行比较,本文采用的新模型不管是处理海量数据,还是处理大规模数据,在时间方面,优势是非常明显的,它的评价结果与传统方法也保持高度一致.
4 结语
本文以有序命题类问题中的不确定性问题作为切入点,采用大数据聚类方法领域相似度对采集的海量数据进行了预处理,从而形成了多个簇.再计算所有簇的质心,并作为簇的代表,采用广义三角模糊数的方法对任何一个质心信息进行基本概率指派.最后,再以混沌流形指数方程为根据完成各数据的组合,并最终完成了海量信息的评价.仿真实验结果表明:本文采用的新模型可以保证在评价结果正确的前提下有效缩减海量信息的评价时间,做到了省时、高效,可谓新时代高效合理的海量信息评价的新方法.
[参 考 文 献]
[1] QUINN A,KINNEY P, SHAMAN J.Predictors of summertime heat index levels in new york city apartments[J].Indoor Air,2017,27(4):840-851.
[2] CHEN C, SONG H.Soliton solutions for quasilinear schrö dinger equation with critical exponential growth[J].Applications of Mathematics,2016,61(3):317-337.
[3] RAHMAN M Z,SIDDIQUA S,KAMAL A S.Liquefaction hazard mapping by liquefaction potential index for dhaka city,Bangladesh[J].Engineering Geology,2015,188:137-147.
[5] CHIN S A.Understanding saul’yev-type unconditionally stable schemes from exponential splitting[J].Numerical Methods for Partial Differential Equations,2015,30(6):1961-1983.
[6] ROSHAN G,SAMAKOSH J M, OROSA J A.The impacts of drying of lake urmia on changes of degree day index of the surrounding cities by meteorological modeling[J].Environmental Earth Sciences,2016,75(20):1387.
[7] ALATAWI A M,KUMAR R,SALEH W.Transportation sustainability index for tabuk city in saudi arabia:an analytic hierarchy process[J].Transport,2016,30(15):47-55.
