一种能量函数意义下的生成式对抗网络
2018-06-07王功明乔俊飞王磊
王功明 乔俊飞 王磊
生成式对抗网络(Generative adversarial network,GAN)是由Goodfellow等[1]于2014年根据对抗竞争思想提出来的一种优化生成模型.GAN要解决的问题是如何从训练样本中学习到概率分布特征,并进一步生成新样本数据,训练样本是图片即生成新图片,训练样本是文字即输出新文字.GAN在学习算法上受博弈论中的零和博弈(参与博弈的各方在严格竞争下,一方的收益必然意味着另一方的损失,博弈各方的收益和损失相加总和永远为零,双方不存在合作的可能)的启发,网络由一个生成模型(Generative model)和一个判别模型(Discriminative model)构成.生成模型的训练目的是试图生成与训练样本具有一致概率分布的新样本,并作为判别模型的输入;判别模型的训练目的是判断生成模型生成的样本是否是真实的训练样本[2−4].GAN的优化和训练过程是一个极小极大的博弈问题,最终的目的是判别模型无法分辨出生成样本的真伪,即极大化判别模型的判断能力,极小化生成模型输出被判断为伪造的概率[5−6].
然而,GAN的优化和训练过程中也存在一些缺陷.一方面,基于传统深度学习方法的生成模型无法快速地学习并生成样本数据,即学习效率低、算法收敛慢.另一方面基于梯度下降算法的训练存在梯度消失的问题,即当真实样本和生成样本之间具有极小重叠甚至没有重叠时,其目标函数的Jensen-Shannon散度是一个常数,导致优化目标不连续[1,7−8].为了解决以上问题,Arjovsky等[9]提出了一种Wasserstein GAN(W-GAN)模型,利用Earth-Mover代替Jensen-Shannon散度来表征真实样本和生成样本分布之间的差异,用一个评价函数来对应GAN的判别模型,而且评价函数需要建立在Lipschitz连续性假设上.尽管W-GAN避开了优化目标不连续的障碍,但是其存在的最大问题是模型的收敛性无法保证.Donahue等[10]提出一种Bi-GAN模型,将复杂数据映射到隐变量空间,从而实现特征学习,并且引入了一个解码器用于将真实数据映射到隐变量空间,成功地实现了优化问题的等效转移.尽管能够部分地解决问题,但是Bi-GAN的训练耗时相对较长.
LeCun等[11]提出了能量模型的概念,并将待优化参数的每一种取值对应于一个能量取值,通过最小化能量来获取对应的参数取值.这种能量模型概念的提出有助于提高GAN的学习效率,因为该方法无需在损失函数中加入正则化项也能较精确地完成训练目标.同时,能量函数模型无需计算复杂的配分函数(Partition functions).当传统浅层神经网络用作判别模型时,能量函数的选择相对简单,即将实际输出和期望输出的差值作为能量函数.然而,当判别模型用深度学习模型表述时,由于深度学习模型的训练方式大都采用无监督学习[12],所以能量函数的选取及其稳定性分析比较困难.
针对以上问题,本文提出一种基于重构误差的能量函数的GAN模型(Energy reconstruction error GAN,E-REGAN).生成模型由基于深度学习模型的自适应深度信念网络(Adaptive deep belief network,ADBN)来实现,判别模型由自适应深度自编码器(Adaptive deep auto-encoder,ADAE)来实现.其中,ADBN的输入是真实样本x和噪音z的组合,自适应学习率能够加快生成模型和判别模型的学习速度[13−15],ADAE的重构误差作为能量函数.在MNIST和CIFAR-10标准数据集上的实验结果表明,与现有的几种类似GAN模型相比,EREDBN模型在学习速度和数据生成能力两方面均有较大提高.
本文结构安排如下:第1节介绍介绍生成式对抗网络;第2节介绍E-REGAN模型,包括学习过程和网络性能分析;第3节给出实验研究;第4节对本文工作进行总结.
1 生成式对抗网络
GAN学习原理启发于博弈论中的二人零和博弈(Two-player game).GAN模型中的博弈双方分别由生成式模型和判别式模型来实现.生成模型G用来学习已有样本的概率分布,并试图生成与已有样本一致分布的数据,通常用到的方法的是利用服从某一分布(高斯分布或均匀分布)的噪声z生成一个类似真实训练数据的样本,越逼近真实样本越好.判别模型D是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率.如果样本来自于真实的训练数据,D输出大概率;否则,D输出小概率.GAN的训练过程即不断的调整G和D,直到D不能把生成的样本从真实样本中区分出来为止.在调整过程中,需要做到:1)优化G,使它尽可能地生成让D无法区分的样本;2)优化D,使它尽可能地区分出生成的样本.当D无法区分出生成的样本时,可以认为G达到最优状态.
假定已有的样本数据为x,生成的样本数据为G(z),那么生成模型G和判别模型D的损失函数定义如下:

其中,max∗(·)=max(0,·),α是一个正实数.
由式(1)和式(2)可知,最小化FG(z)就是最大化FD(x,z)中的第二项,即GAN的优化过程就是一个极小极大化问题.
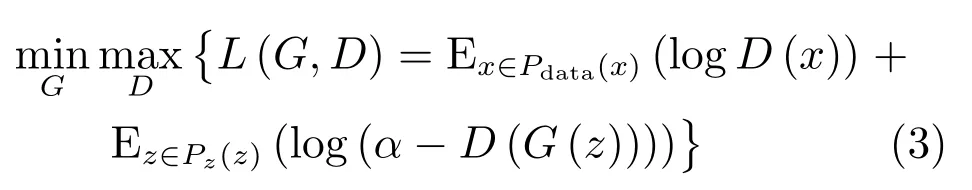
其中,Pdata(x)和Pz(z)分别表示真实样本数据的概率分布和初始噪音数据的概率分布(可视为一种先验分布),E(·)表示计算期望值.
2 E-REGAN模型
2.1 基于能量的模型
假设一个预测问题:一个概率模型利用观测到的输入数据X来预测输出数据Y.要想完成此任务需要学习X到Y的映射规律,并求取能够使得P(Y/X)最大化的映射权值参数W.当给定输入数据X和映射权值参数W时,必然会得到一个对应的输出Y,定义E(W,Y,X)为此时概率模型的能量.在有监督学习框架下,这种基于能量模型的学习原理是对于训练集中每一个输入样本X,输入输出组合(X,Y)对应的能量当且仅当Y是期望输出时,取得最小值;Y越偏离期望输出,能量值越大.
2.2 E-REGAN结构及其学习过程
E-REGAN模型由自适应深度信念网络(ADBN)和自适应深度自编码器(ADAE)构成,ADBN和ADAE分别充当生成模型G和判别模型D.ADBN和ADAE的训练交替进行展开,先训练生成模型G,优化判别模型D,看是否满足能量函数指标要求;然后固定判别器D,继续训练生成模型G,使得D的判别准确率最小化.当且仅当Pdata=Pg(纳什均衡)[1]时,达到全局最优解.E-REGAN的结构原理如图1所示.
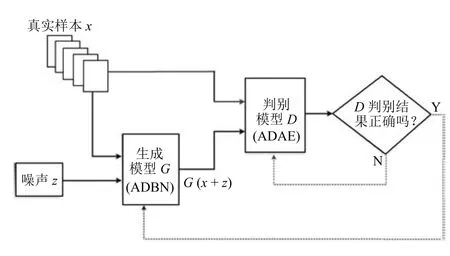
图1 E-REGAN结构原理图Fig.1 Structure and scheme of E-REGAN
2.2.1 自适应深度信念网络
ADBN由若干个顺序堆叠的自适应受限玻尔兹曼机(Adaptive restricted Boltzmann machine,ARBM)和一个输出层构成,前一个ARBM的输出作为后一个ARBM的输入.ARBM只有两层神经元,一层为可视层,由显性神经元组成,用于输入训练数据;另一层为隐含层,由隐性神经元组成,用于提取训练数据的特征.ARBM的结构如图2所示,其中可视层有m个节点,隐含层有n个节点,W是连接权值矩阵.
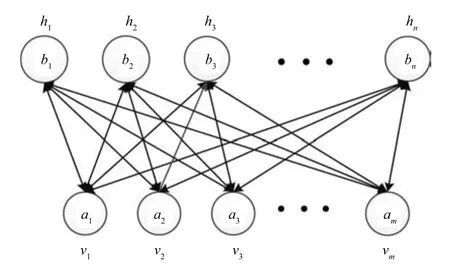
图2 ARBM结构图Fig.2 Structure of ARBM
给定模型参数θ={W,a,b},那么可视层和隐含层的联合概率分布P(v,h;θ)用能量函数E(v,h;θ)定义为


对于一个伯努利(可视层)分布–伯努利(隐含层)分布的RBM,能量函数定义为
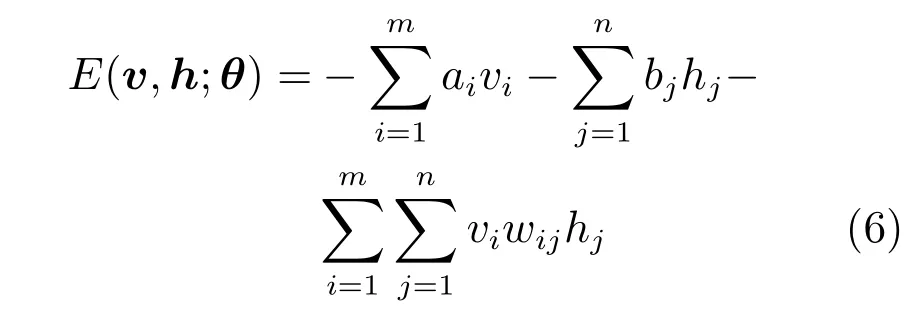
其中,wij是RBM 的连接权值,ai和bj分别表示可视层节点和隐含层节点的偏置.那么条件概率分布可表示为
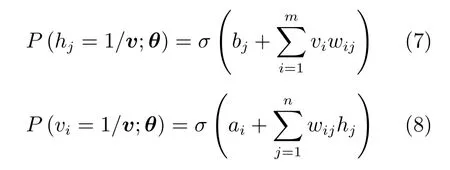
其中,σ(·)是一个Sigmoid函数.
可视层和隐含层是二值状态,判断其二值概率取值的标准常通过设定一个阈值来实现[16],以隐含层为例,可表示为

其中,δ为一个介于0.5∼1的常数.
通过计算对数似然函数logP(v;θ)的梯度,并根据ARBM训练过程连续两次迭代后的参数更新方向的异同[13,15]设计自适应学习率η的方法,可以得到ARBM权值更新公式为
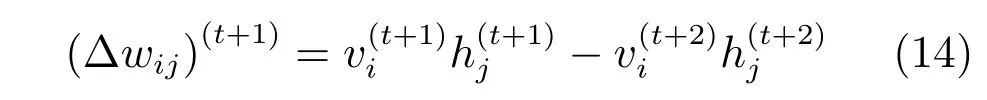
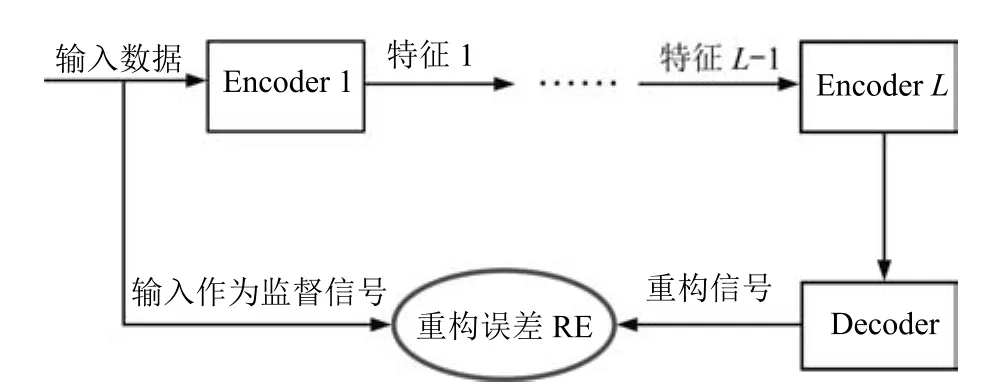
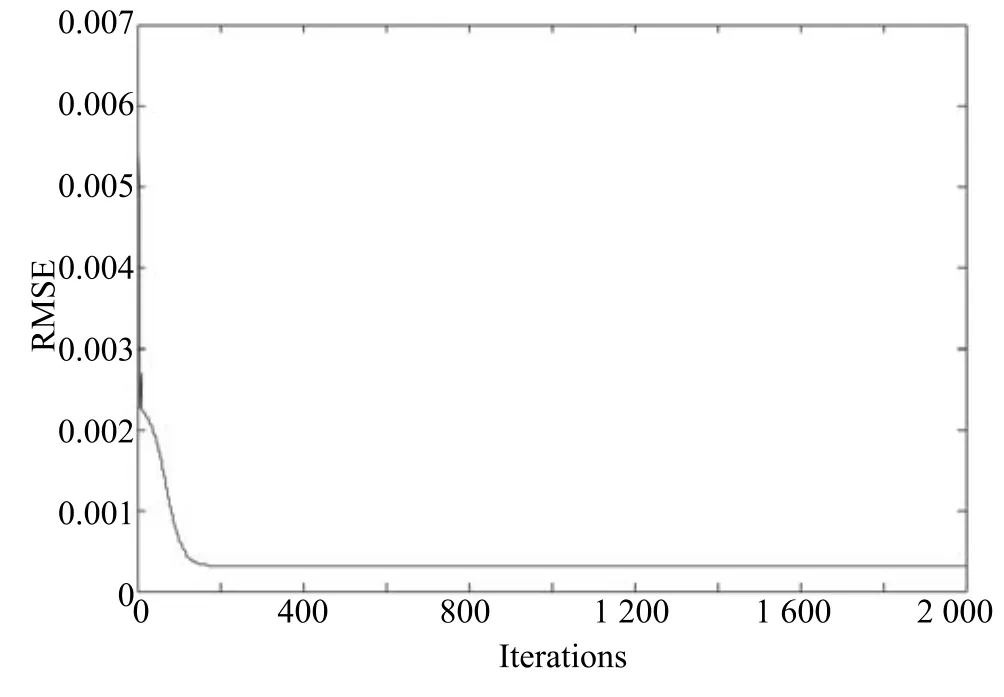
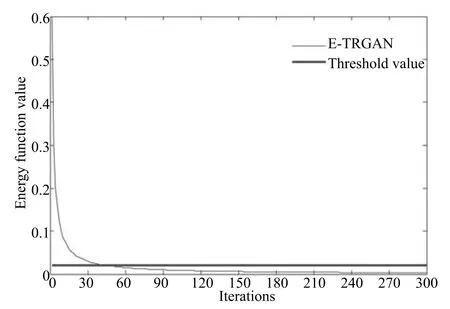
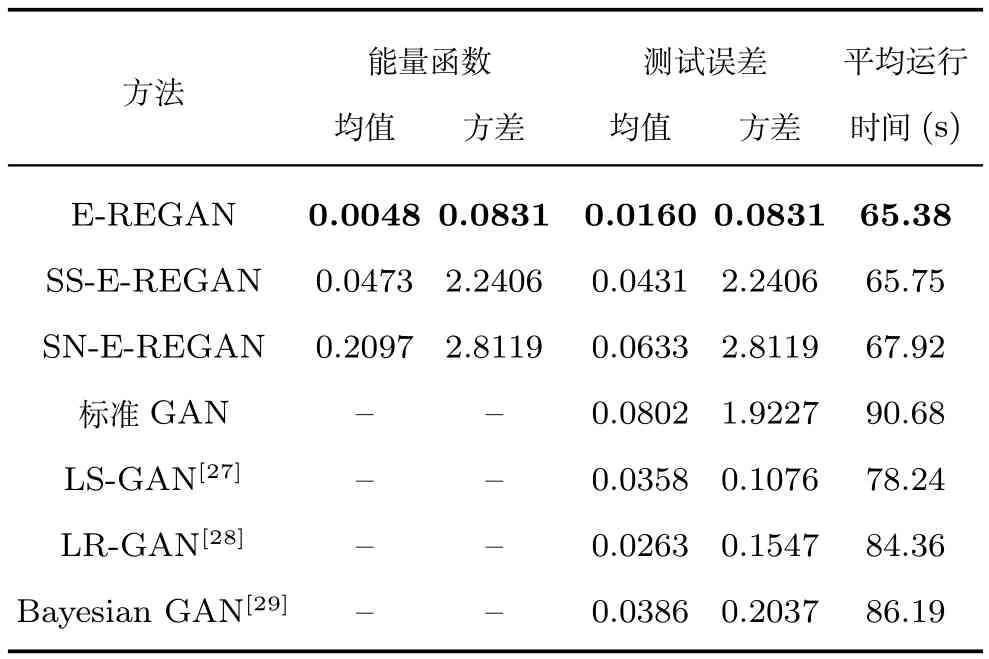
其中,τ和η分别表示ARBM 的迭代次数和学习率,Edata(vihj)和Emodel(vihj)分别表示训练集中观测数据的期望和模型确定的分布上的期望,t是吉布斯采样步数[17].通常情况下,Emodel(vihj)可由吉布斯采样近似得到[17].ARBM 的这种训练称为自适应对比散度(Adaptive contrastive divergence,ACD)算法[13,15,18].u和v分别表示学习率增大系数和减小系数,且0 堆叠的ARBM训练结束后,再利用BP算法从输出层开始由上到下对整个ADBN的权值进行微调(Fine-tuning)[18]. 2.2.2 自适应深度自编码器 ADAE由若干个ARBM顺序堆叠而成,是一种用于对数据进行无监督特征提取和原始数据复原的深度模型.ADAE与ADBN的区别在于ADAE没有监督信号层[19−20],其结构如图3所示.可用ACD算法快速训练ADAE并实现判别模型对真实样本和生成样本的正确判别.由于ADAE是一种无监督学习模型,所以基于逼近误差的能量函数模型选取方法不再适用.在此,开创性地将ADAE的重构误差(Reconstruction error,RE)作为能量函数模型,RE定义如下所示: 其中,Ns和Nd分别表示样本数据个数和样本数据维数;vij和ij分别表示原始输入样本集的数据点值和输入样本集的重构数据点值. 图3 ADAE结构原理图Fig.3 Structure and scheme of ADAE 用作判别模型时,ADAE首先对真实样本数据进行特征提取,经过快速有效地编码,得到对真实样本数据的抽象特征表述F并保存下来;然后对抽象表述进行复原处理(解码),得到真实样本数据的重构信息.在此过程中,将重构误差作为一种能量函数,能量函数越小,对应的判别模型学习的越充分,理想情况下能量函数为0.但在实际应用中,考虑到判别模型的训练成本问题,经常设置一个能量函数指数λ(0<λ<1). 训练结束后,将生成模型的生成数据作为ADAE的输入,得到对生成数据的抽象特征表述F0.当F和F0的绝对误差|F−F0|小于或等于能量函数阈值γ(0<γ<λ),需要稳定判别模型,继续训练生成模型,然后再以同样的原理利用判别模型检验生成模型的生成能力.由于以能量函数阈值和能量函数指数作为评价指标的优化问题不需要求梯度校正信号,所以只需通过判断是否满足指标要求来做更进一步的迭代优化即可.E-REGAN的成功之处在于,只要满足充足的训练迭代步数,ADBN和ADAE将无限接近理想状态[21−23].在此,自适应学习率对加速训练过程起着重要作用. GAN的基本思想源自博弈论的二人零和博弈,由一个生成模型G和一个判别模型D构成,通过对抗学习的方式来迭代训练,直至逼近纳什均衡.因此,E-REGAN的稳定性主要取决于G和D在迭代训练过程中能否达到纳什均衡. 假设PG是生成样本G(z)的概率密度分布,定义纳什均衡函数为 训练判别模型D来最小化f,训练生成模型G来最小化g,那么纳什均衡的平衡点即为G和D的最优组合对(G∗,D∗),且满足 定理1.如果(G∗,D∗)是一个纳什均衡的平衡点,那么当PG∗=Pdata时,满足f(G∗,D∗)=α. 证明.对式(16)作展开处理 现给出式(2)的一般形式如下所示: 其中,A,B≥0,0≤D<∞.那么ψ(D)的导数为 由式(22)可知,当A 由于ψ(D)在[0,∞)上是收敛的,所以存在以下两种情况: 1)如果D∗(x)>α且(x)=min(D∗(x),α),那么不难得到f(G∗,) 2)用ψ(D)的最小值代替D∗(x)可得f(G∗,)的上界[24],即 根据式(19)可得 联立式(20)和式(24)可得 由于D∗(x)≤α,所以有 通过式(23)和式(26)可知,α≤f(G∗,D∗)≤α,即f(G∗,D∗)=α. 分析E-REGAN模型结构可知,ADBN具有可靠的稳定性[13,15],所以生成模型G稳定.接下来讨论判别模型D的稳定性问题,即重构误差RE的收敛性问题. RE是对ADAE的重构输入数据和原始输入数据计算绝对误差的方法,计算过程中需要提前知道每一个隐含层(ARBM)的状态(中间变量).所以,要证明RE的收敛性问题必须保证ADAE中间变量的有界性.不失一般性,将式(7)和式(8)中激活函数的上下渐近线设为AH和AL,那么对于任何一个ARBM,分别表示可视层的输入状态和经过t次采样得到的重构状态,分别表示由得到的隐含层状态和对模型经过t次采样得到的隐含层状态.那么经过t次采样后有 由式(27)∼(30)可以看出,在每个ARBM 的吉布斯采样过程中,网络输出与采样过程的中间状态有关. 定理2.假设分别是ARBM的输入状态、中间状态和输出状态,那么ADAE中间变量有界的充分必要条件是所有状态满足 证明.由于组成ADAE的ARBM是顺序叠加的,所以当时,由式(27)∼(30)可知,最后一个ARBM的隐含层在经过t次吉布斯采样后,状态范围必定为[AL,AH],即所以满足整个ADAE在训练过程中输入输出有界性,网络稳定.充分性得证. 若ADAE稳定,则每个ARBM的可视层和隐含层状态均满足输入输出有界性.由于Sigmoid函数具有单调递增性,且随着二值神经元中取1的神经元个数不断增加.可得不等式 即中间状态满足 必要性得证. 通过以上分析及对两个定理的证明可知,EREGAN具有可靠的稳定性. 为了验证所提E-REGAN模型的对抗学习能力,分别在MNIST数据集和CIFAR-10数据集上进行测试.为了排除无关因素对实验结果的影响,客观反映E-REGAN的性能,仿真实验的编译软件和计算机运行环境设置如下:编译软件为MATLAB 8.2版本,计算机处理器为Intel(R)Core(TM)i7-4790,主频为3.6GHz,RAM为8GB. MNIST数据集包含60000张训练数字图像和10000张测试数字图像,每一个数字均用多种手写体显示.每张图像均是一个0∼9的手写数字,大小为28×28的像素规格.随着模式识别和数据挖掘技术的不断发展,很多理论方法应用到该数据库中.该数据库被视为一种理想的、标准的测试新方法的经典对象[25−26].取100张图像数据和随机噪音的组合作为训练样本对生成模型进行训练,首先对EREGAN的生成模型ADBN进行训练,然后对判别模型ADAE进行编码解码训练.其中ADBN结构为781-80-80-781,ADAE结构为781-80-80-80-80.E-REGAN生成模型ADBN的固有学习参数设置如表1所示. 表1 MNIST数据集测试中ADBN的固有参数Table 1 Fixed parameters of ADBN on MNIST dataset 图4是生成模型ADBN最后一个阶段的训练均方根误差(Root mean square error,RMSE).从图4可以看出,尽管上一阶段ADBN的生成样本依然被判别模型从真实样本中识别出来,但是ADBN上一阶段的训练RMSE已经很小,收敛到0.005.最后一个阶段训练RMSE收敛到0.000376,训练速度非常快,在前100次迭代中已接近收敛.图5是判别模型的能量函数变化曲线.其中,SS-E-REGAN(Single sample E-REGAN)是指生成模型的输入只有真实样本x的E-REGAN,SN-E-REGAN(Single noise E-REGAN)是指生成模型的输入只有噪音z的E-REGAN.从图5可以看出,缺少噪音输入的生成模型对应的E-REGAN鲁棒性差,缺少真实样本输入的生成模型对应的E-REGAN精度不高;相比之下,同时将噪音和真实样本作为生成模型输入的E-REGAN具有较强的鲁棒性,对抗学习性能优越.同时,ADAE中的自适应学习率也加速了能量函数的收敛速度. 图6是E-REGAN生成的手写数字样本,图7是SS-E-REGAN生成的样本图像,图8是SN-EREGAN生成样本图像,图9是利用基于梯度校正信号且无能量函数模型的GAN(Gradient-GAN,g-GAN)的生成样本图像,图10是Loss-sensitive GAN(LS-GAN)[27]的生成样本图像.可以看出,在经过充分的对抗学习过程后,E-REGAN生成的样本最清晰,与真实的手写数字图像几乎完全一致,至少用肉眼无法辨别出真伪. 图4 生成模型ADBN的训练RMSEFig.4 RMSE curve of generative model ADBN 图5 E-REGAN的能量函数变化曲线Fig.5 Energy function curves of E-REGAN 图6 E-REGAN生成的样本图像Fig.6 Sample images generated by E-REGAN 图7 SS-E-REGAN生成的样本图像Fig.7 Sample images generated by SS-E-REGAN 图8 SN-E-REGAN生成的样本图像Fig.8 Sample images generated by SN-E-REGAN 图9 g-GAN生成的样本图像Fig.9 Sample images generated by g-GAN 图10 LS-GAN生成的样本图像Fig.10 Sample images generated by LS-GAN 为了更客观地反映E-REGAN优越的学习性能和对抗生成能力,将E-REGAN与其他类似模型进行比较,结果来自20次独立实验,如表2所示.其中,LS-GAN是Loss-sensitive GAN[27];LR-GAN是Layered-recursive GAN[28];Bayesian GAN[29]是一种基于贝叶斯准则的GAN.在对比实验中,利用分类正确率作为衡量E-REGAN在MNIST数据集上生成样本(100个图像)的优劣指标(所有生成样本图像由同一个RBM分类器来分类). 表2 MNIST数据集实验结果对比Table 2 Result comparison on MNIST dataset 由表2可知,E-REGAN具有最好的对抗学习能力和样本生成能力以及较好的鲁棒性能,同时具有较快的网络学习速度. CIFAR-10数据集包含10类60000个32×32的彩色图像,其中有50000个训练图像和10000个测试图像.该数据集分为5个训练块和1个测试块,每个块有10000个图像.随着深度学习技术的不断发展,基于深度神经网络的识别方法不断涌现,CIFAR-10数据库目前已成为最具说服力的测试新方法的数据集之一[30−34].取100张图像数据和随机噪音的组合作为训练样本对生成模型进行训练,首先对E-REGAN的生成模型ADBN进行训练,然后对E-REGAN的判别模型ADAE进行编码解码训练.其中ADBN结构:1024-100-100-100-1024,ADAE结构:1024-100-100-100-100-100.EREGAN生成模型ADBN的固有学习参数设置如表3所示. 表3 CIFAR-10数据集测试中ADBN的固有参数Table 3 Fixed parameters of ADBN on CIFAR-10 dataset 图11是生成模型ADBN在最后一个训练阶段的RMSE变化曲线.可以看出,尽管上一个对抗迭代过程中ADBN的生成样本被判别模型从真实样本中识别出来,但是ADBN的训练RMSE已经很小,收敛到0.0052.最后一个对抗迭代过程训练RMSE收敛到0.00032,训练速度非常快,在前16次迭代中已接近收敛.图12是判别模型的能量函数变化曲线,可以看出E-REGAN的能量函数值在前50迭代中已经接近收敛,且满足能量函数阈值要求,此时生成模型的性能达到相对理想的状态.图13是E-REGAN生成的CIFAR-10数据样本,图14是Loss-sensitive GAN(LS-GAN)[27]生成的CIFAR-10数据样本,图15是Layered-recursive GAN(LR-GAN)[28]生成的CIFAR-10数据样本,图16是Bayesian GAN[29]生成的CIFAR-10数据样本.可以看出,在经过充分的对抗学习过程后,E-REGAN生成的样本图像与真实的CIFAR-10数据集中的图像最接近,至少用肉眼无法辨别出真伪. 为了更为客观地反映E-REGAN优越的学习性能和对抗生成能力,将E-REGAN与其他类似模型同时在CIFAR-10数据集上进行试验验证并作比较.相应结果来自20次独立实验,如表4所示.在对比实验中,利用测试误差(Test-error)作为衡量E-REGAN在CIFAR-10数据集上生成样本的优劣指标.测试误差Test-error定义如下: 图11 生成模型ADBN的训练RMSEFig.11 RMSE curve of generative model ADBN 图12 E-REGAN的能量函数变化曲线Fig.12 Energy function curves of E-REGAN 图13 E-REGAN生成的样本图像Fig.13 Sample images generated by E-REGAN 表4 CIFAR-10数据集实验结果对比Table 4 Result comparison on CIFAR-10 dataset 图14 LS-GAN生成的样本图像Fig.14 Sample images generated by LS-GAN 其中,pi和i分别为真实图像和生成图像经过向量化和归一化后的元素,I为图像向量化后的维数. 从表4可以看出,E-REGAN具有较好的样本生成能力和更强的鲁棒性,同时,具有最快的网络学习速度. 图15 LR-GAN生成的样本图像Fig.15 Sample images generated by LR-GAN 图16 Bayesian GAN生成的样本图像Fig.16 Sample images generated by Bayesian GAN 针对现有生成式对抗网络GAN生成模型学习效率低下和判别模型的学习过程易出现梯度消失的两个缺点,本文提出了一种能量函数意义下的生成式对抗网络(E-REGAN).将自适应深度信念网络(ADBN)作为生成模型来加速生成式学习,自适应深度自编码器(ADAE)作为判别模型来加速判别式学习.噪音和真实样本同时作为自适应深度信念网络的输入信号,判别模型采用无监督学习,自适应深度自编码器的重构误差作为能量函数.能量函数意义下的判别基准无需梯度校正信号使得生成模型和判别模型在对抗学习过程中实现快速精确的交替优化.与其他几种模型相比,基于能量函数的E-RAGAN能够在快速的交替对抗优化过程中生成大量无限接近于真实样本的数据,且网络鲁棒性较强.本文仍有不足之处,由于深度自编码器的引入,自适应学习率在面对深层次的特征提取时,加速效果已不再明显.在今后的工作中,如何从网络结构的角度提高特征提取的效率将是优先研究方向. 1 Goodfellow I J,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,Ozair S,et al.Generative adversarial nets.In:Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal,Canada:MIT Press,2014.2672−2680 2 Makhzani A,Shlens J,Jaitly N,Goodfellow I,Frey B.Adversarial autoencoders.arXiv preprint arXiv:1511.05644,2015. 3 Mao X D,Li Q,Xie H R,Lau R Y K,Wang Z,Smolley S P.Least squares generative adversarial networks.arXiv preprint ArXiv:1611.04076,2016. 4 Durugkar I,Gemp I,Mahadevan S.Generative multiadversarial networks.arXiv preprint arXiv:1611.01673,2016. 5 Huang X,Li Y X,Poursaeed O,Hopcroft J,Belongie1 S.Stacked generative adversarial networks.arXiv preprint arXiv:1612.04357,2016. 6 Saito M,Matsumoto E,Saito S.Temporal generative adversarial nets with singular value clipping.In:Proceedings of the 2017 IEEE Conference on Computer Vision.Venice,Italy:ICCV,2017.2849−2858 7 Che T,Li Y R,Zhang R X,Hjelm R D,Li W J,Song Y Q,et al.Maximum-likelihood augmented discrete generative adversarial networks.arXiv preprint arXiv:1702.07983,2017. 8 Wang Kun-Feng,Gou Chao,Duan Yan-Jie,Lin Yi-Lun,Zheng Xin-Hu,Wang Fei-Yue.Generative adversarial networks:the state of the art and beyond.Acta Automatica Sinica,2017,43(3):321−332(王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报,2017,43(3):321−332) 9 Arjovsky M,Chintala S,Bottou L.Wasserstein GAN.arXiv preprint arXiv:1701.07875,2017. 10 Donahue J,Krähenbühl P,Darrell T.Adversarial feature learning.arXiv preprint arXiv:1605.09782,2016. 11 LeCun Y,Huang F.Loss functions for discriminative training of energy-based models.In:Proceedings of the 10th International Workshop on Arti ficial Intelligence and Statistics.Barbados:AIS,2005.206−213 12 Qiao Jun-Fei,Pan Guang-Yuan,Han Hong-Gui.Design and application of continuous deep belief network.Acta Automatica Sinica,2015,41(12):2138−2146(乔俊飞,潘广源,韩红桂.一种连续型深度信念网的设计与应用.自动化学报,2015,41(12):2138−2146) 13 Qiao Jun-Fei,Wang Gong-Ming,Li Xiao-Li,Han Hong-Gui,Chai Wei.Design and application of deep belief network with adaptive learning rate.Acta Automatica Sinica,2017,43(8):1339−1349(乔俊飞,王功明,李晓理,韩红桂,柴伟.基于自适应学习率的深度信念网设计与应用.自动化学报,2017,43(8):1339−1349) 14 Lopes N,Ribeiro B.Towards adaptive learning with improved convergence of deep belief networks on graphics processing units.Pattern Recognition,2014,47(1):114−127 15 Wang Gong-Ming,Li Wen-Jing,Qiao Jun-Fei.Prediction of effluent total phosphorus using PLSR-based adaptive deep belief network.CIESC Journal,2017,68(5):1987−1997(王功明,李文静,乔俊飞.基于PLSR自适应深度信念网络的出水总磷预测.化工学报,2017,68(5):1987−1997) 16 Hinton G E.Training products of experts by minimizing contrastive divergence.Neural Computation,2002,14(8):1771−1800 17 Le Roux N,Bengio Y.Representational power of restricted boltzmann machines and deep belief networks.Neural Computation,2008,20(6):1631−1649 18 Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets.Neural Computation,2006,18(7):1527−1554 19 Alain G,Bengio Y.What regularized auto-encoders learn from the data-generating distribution.The Journal of Machine Learning Research,2014,15(1):3563−3593 20 Chan P P K,Lin Z,Hu X,Tsang E C C,Yeung D S.Sensitivity based robust learning for stacked autoencoder against evasion attack.Neurocomputing,2017,267:572−580 21 Huang G B,Chen L,Siew C K.Universal approximation using incremental constructive feedforward networks with random hidden nodes.IEEE Transactions on Neural Networks,2006,17(4):879−892 22 Leung F H F,Lam H K,Ling S H,Tam P K S.Tuning of the structure and parameters of a neural network using an improved genetic algorithm.IEEE Transactions on Neural networks,2003,14(1):79−88 23 de la Rosa E,Yu W.Randomized algorithms for nonlinear system identi fication with deep learning modi fication.Information Sciences,2016,364−365:197−212 24 Zhao J B,Mathieu M,LeCun Y.Energy-based generative adversarial network.arXiv preprint arXiv:1609.03126,2016. 25 Larochelle H,Bengio Y,Louradour J,Lamblin P.Exploring strategies for training deep neural networks.The Journal of Machine Learning Research,2009,10:1−40 26 Wang Y,Wang X G,Liu W Y.Unsupervised local deep feature for image recognition.Information Sciences,2016,351:67−75 27 Qi G J.Loss-sensitive generative adversarial networks on lipschitz densities.arXiv preprint arXiv:1701.06264,2017. 28 Yang J W,Kannan A,Batra D,Parikh D.LR-GAN:layered recursive generative adversarial networks for image generation.arXiv preprint arXiv:1703.01560,2017. 29 Saatchi Y,Wilson A.Bayesian GAN.arXiv preprint arXiv:1705.09558,2017. 30 Hinton G E,Srivastava N,Krizhevsky A,Sutskever I,Salakhutdinov R R.Improving neural networks by preventing co-adaptation of feature detectors.arXiv preprint arXiv:1207.0580,2012. 31 Xu B,Wang N Y,Chen T Q,Li M.Empirical evaluation of recti fied activations in convolutional network.arXiv preprint arXiv:1505.00853,2015. 32 Goroshin R,Bruna J,Tompson J,Eigen D,LeCun Y.Unsupervised learning of spatiotemporally coherent metrics.In:Proceedings of the 2015 IEEE Conference on Computer Vision(ICCV).Santiago,Chile:IEEE,2015.4086−4093 33 Metz L,Poole B,Pfau D,Sohl-Dickstein J.Unrolled generative adversarial networks.arXiv preprint arXiv:1611.02163,2016. 34 Springenberg J T.Unsupervised and semi-supervised learning with categorical generative adversarial networks.arXiv preprint arXiv:1511.06390,2015.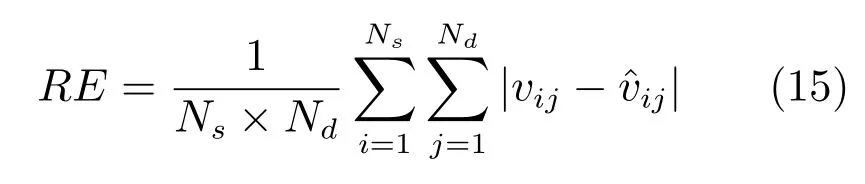
2.3 E-REGAN稳定性分析
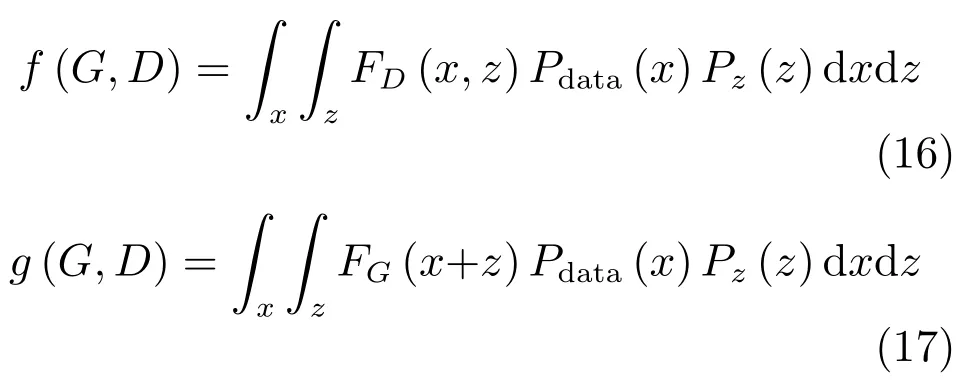

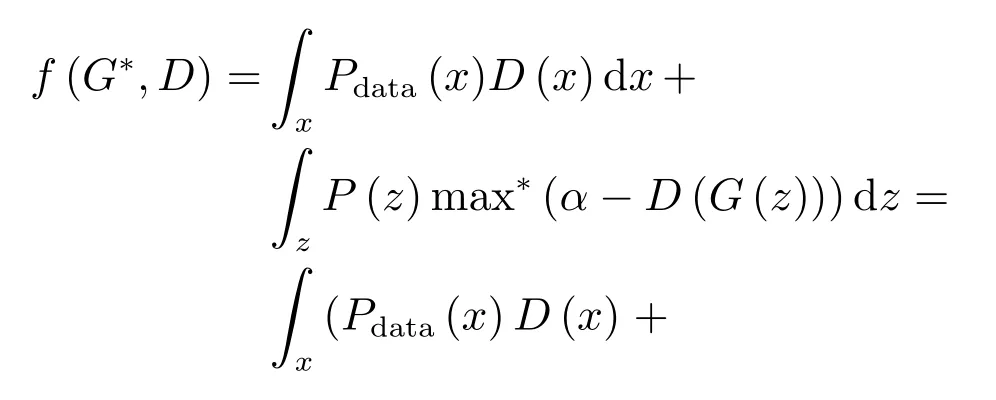
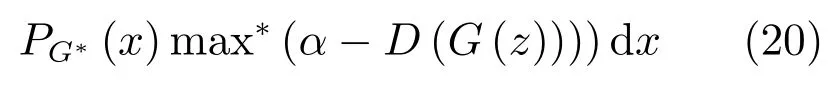

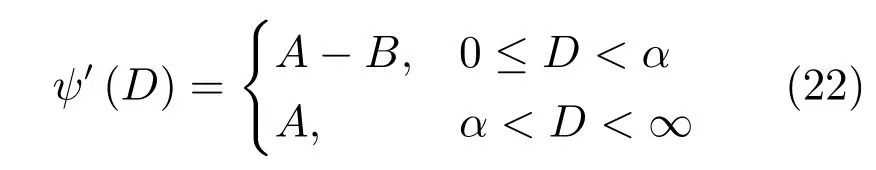
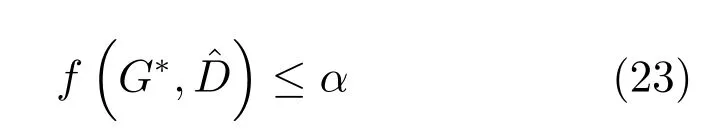
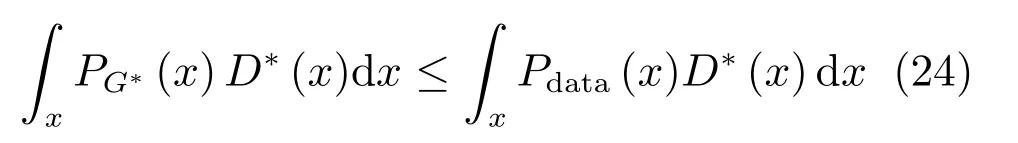
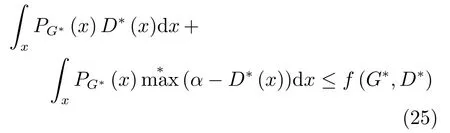

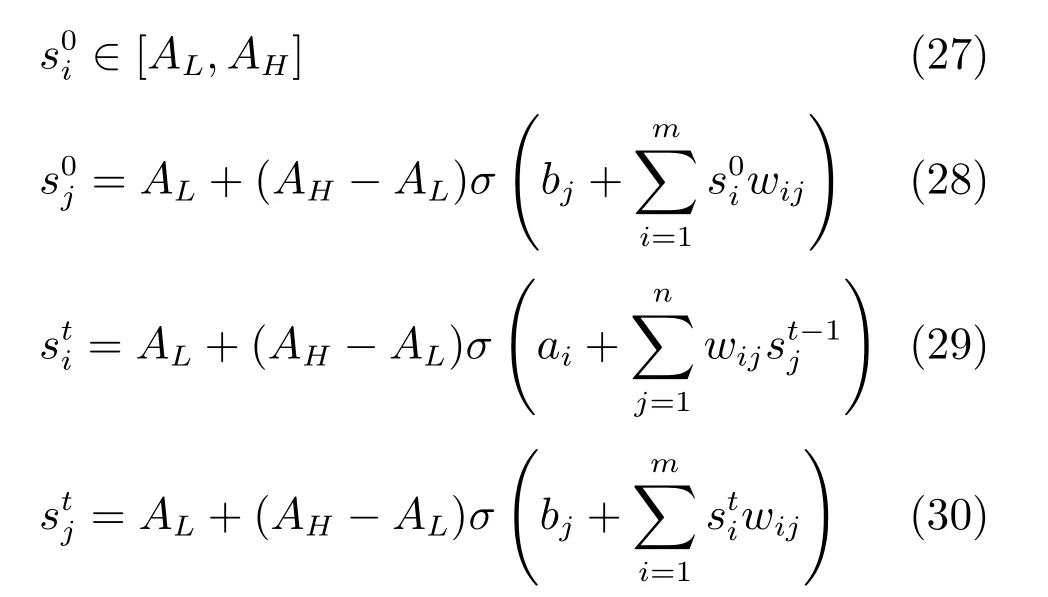


3 实验研究
3.1 MNIST数据集









3.2 CIFAR-10数据集




4 结束语


