基于对抗训练策略的语言模型数据增强技术
2018-06-07张一珂张鹏远颜永红
张一珂 张鹏远 颜永红,3
语言模型(Language model,LM)是描述词序列概率分布的数学模型,广泛应用于各种自然语言处理(Natural language processing,NLP)领域,例如语音识别、机器翻译、词性标注等.
N元文法语言模型(N-gram LM)是一种常用的统计语言模型[1].由于实际自然语言中词汇组合的多样性,利用有限数据训练得到的N-gram LM不可避免地存在数据稀疏问题[2].数据增强是一种有效缓解数据稀疏问题的方法[3−5].就语言模型建模任务而言,常见的数据增强方法包括基于外部数据的方法[4−5]和基于递归神经网络语言模型(Recurrent neural network LM,RNN LM)随机采样的方法[6−7].前者按照一定的规则从其他来源(例如互联网)的数据中挑选部分数据扩充训练集,后者是利用训练好的RNN LM随机生成采样数据以丰富训练集中包含的语言现象.
在难以获取领域相关的外部数据的情况下,基于RNN LM随机采样的数据增强方法可以有效提升N-gram LM参数估计的鲁棒性.该方法将RNN LM作为一个生成模型,随机生成词序列.现有的序列生成模型均采用最大似然估计(Maximum likelihood estimation,MLE)算法估计模型参数.然而,MLE方法会使生成模型在生成采样过程中遇到暴露偏差问题[8−10].即在生成下一个词汇时,如果依赖的历史序列(即已生成的序列)未在训练数据中出现,偏差就会在序列生成过程中逐渐累积,最终导致生成的序列缺乏长时语义信息.
生成对抗网络(Generative adversarial nets,GAN)[11−12]是一种有效缓解暴露偏差问题的训练策略.GAN利用一个判别模型来判断给定的样例是否来自真实的数据,而生成模型则学习如何生成高质量的数据让判别模型失去判断能力.GAN已经成功应用于图像生成任务中,然而将其直接应用于NLP领域生成离散序列面临两个主要问题:1)当生成模型的输出为离散值时,判别模型的误差梯度无法利用反向传播算法回传到生成模型.2)判别模型只能对完整的序列进行评价,无法对未生成完的序列进行评价.
本文将离散序列生成问题表示为强化学习问题[13−15],将生成模型视为随机的参数化策略,利用判别模型的输出作为奖励对其进行优化,避免了判别模型与生成模型间难以进行误差梯度回传的问题,同时采用蒙特卡洛(Monte Carlo,MC)搜索算法[16−17]对生成序列的中间状态进行评估.
目前GAN的研究主要集中于特定图像及本文数据集上的生成任务,且对于生成的文本缺乏客观的评价标准.本文针对语音识别任务,初步探索了GAN在实际数据上的生成效果,并以识别率为客观标准对生成数据的质量进行了评价.具体来说,首先将GAN生成的数据用于增强语言模型,然后利用增强的语言模型对识别一遍解码中保留的多条候选进行重估.本文在两个低资源新闻识别数据集上进行实验,结果表明随着训练数据量的增加,本文提出的数据增强方法可以进一步降低识别字错误率(Character error rate,CER),且始终优于基于MLE的数据增强方法.当训练数据达到6M词时,本文提出的方法分别使两个测试集的CER相对基线系统降低5.0%和7.1%.
1 基于RNN LM的数据增强算法
RNN LM的目标是预测给定词序列中每个词出现的条件概率.给定一条训练语句w1,w2,···,wT(wt∈V,t=1,2,···,T),V表示词典空间.RNN LM按照下式将输入词序列编码为隐含层状态序列s1,s2,···,sT(st∈Rh,t=1,2,···,T)
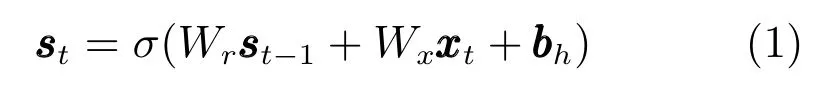
其中,是wt对应的独热码.是可训练参数,σ表示非线性激活函数.然后利用隐含层状态序列得到一系列条件概率分布.
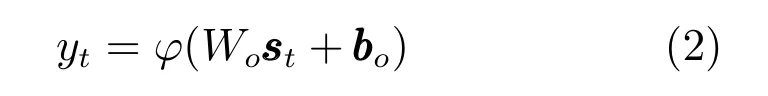
其中,是可训练参数,yt∈R|V|表示给定历史序列w1,w2,···,wt条件下,当前词wt+1的概率分布P(wt+1|w≤t),ϕ表示softmax激活函数.通常采用MLE算法对RNN LM参数进行估计,即最大化给定训练序列的对数概率.

基于RNN LM的数据增强算法的基本思路是首先利用RNN对原始训练语料进行建模.虽然训练完成后模型的参数是确定的,仍然可以从该模型中随机采样生成不同的词序列.因为RNN模型的输出yt定义了一个多项分布P(wt+1|w≤t),可以依据此概率分布从词典V中随机采样,生成当前词wt+1.然后将wt+1作为下一时刻的输入送入RNN模型,得到新的多项分布P(wt+2|w≤t+1),并从该分布中采样得到wt+2.重复此过程直到生成指定长度的序列或生成句子结束符号.重复上述随机采样过程即可得到若干采样序列.通常,利用生成的数据和原始数据(RNN模型的训练数据)分别训练不同的N-gram LM,然后将两个模型进行插值,从而提高N-gram LM参数估计的鲁棒性.
2 序列生成对抗网络
2.1 生成对抗网络
GAN由Goodfellow等于2014年提出[11],是无监督式学习的一种方法.它让两个神经网络通过相互博弈的方式进行学习.GAN由一个生成模型G与一个判别模型D组成.G从隐藏空间中随机采样作为输入,输出结果需要尽量模仿训练集中的真实样本.D的输入为真实样本或G的输出,目标是尽可能将G的输出从真实样本中分辨出来.而G则要尽可能欺骗D.两个模型相互对抗,不断调整参数,最终目的是使D无法分辨G的输出与真实样本.具体地,给定一个先验噪声分布pz(z),pd(x)表示真实数据的分布,D的优化目标是最大化
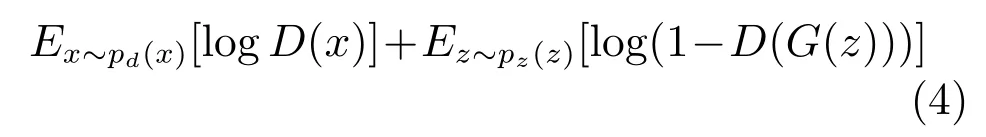
G的优化目标则是最小化
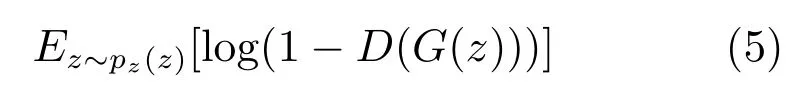
2.2 基于策略梯度的序列生成对抗网络
序列生成问题可以解释为给定一个包含若干序列化数据的训练集,训练一个参数化生成模型Gθ来生成序列Y1:T=(y1,···,yt,···,yT),yt∈V.V表示词典空间,包含若干候选词条.序列生成问题也可以表示为强化学习问题:在t时刻,状态s是当前已经生成的序列y1,···,yt−1,动作a是将要生成的下一个词条yt.依据当前状态s,如何选择将要执行的动作a,由策略Gθ(yt|Y1:t−1)决定.实际上,策略给出了在当前状态s下,执行动作a的概率.
此外,训练一个参数化判别模型Dφ来指导生成模型Gθ的学习过程.Dφ(Y1:T)表示生成序列Y1:T与真实数据的相似程度,是一个概率值.如图1所示,判别模型Dφ的输入为真实数据或生成模型Gθ产生的数据.生成模型Gθ通过策略梯度来更新参数,奖励信号来自判别模型,并通过MC搜索传递到序列的中间状态.
当不存在中间状态的奖励时,生成模型(策略)Gθ(yt|Y1:t−1)的目标是使生成序列的期望奖励J(θ)最大.
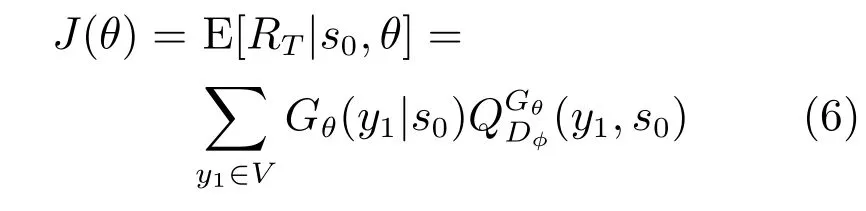
其中,s0表示初始状态,RT表示判别模型Dφ对生成序列Y1:T的奖励.是“动作–值”函数,表示从状态s开始,依据策略Gθ采取动作a的期望奖励.“动作–值”函数的功能是估计当前状态与预期目标的相符程度,即从当前状态开始最终能否生成类似真实数据的序列.而判别模型Dφ的输出值恰好是生成序列与真实数据相似程度的概率值.因此,本文采用Dφ(Y1:T)做为作为“动作–值”函数,即:

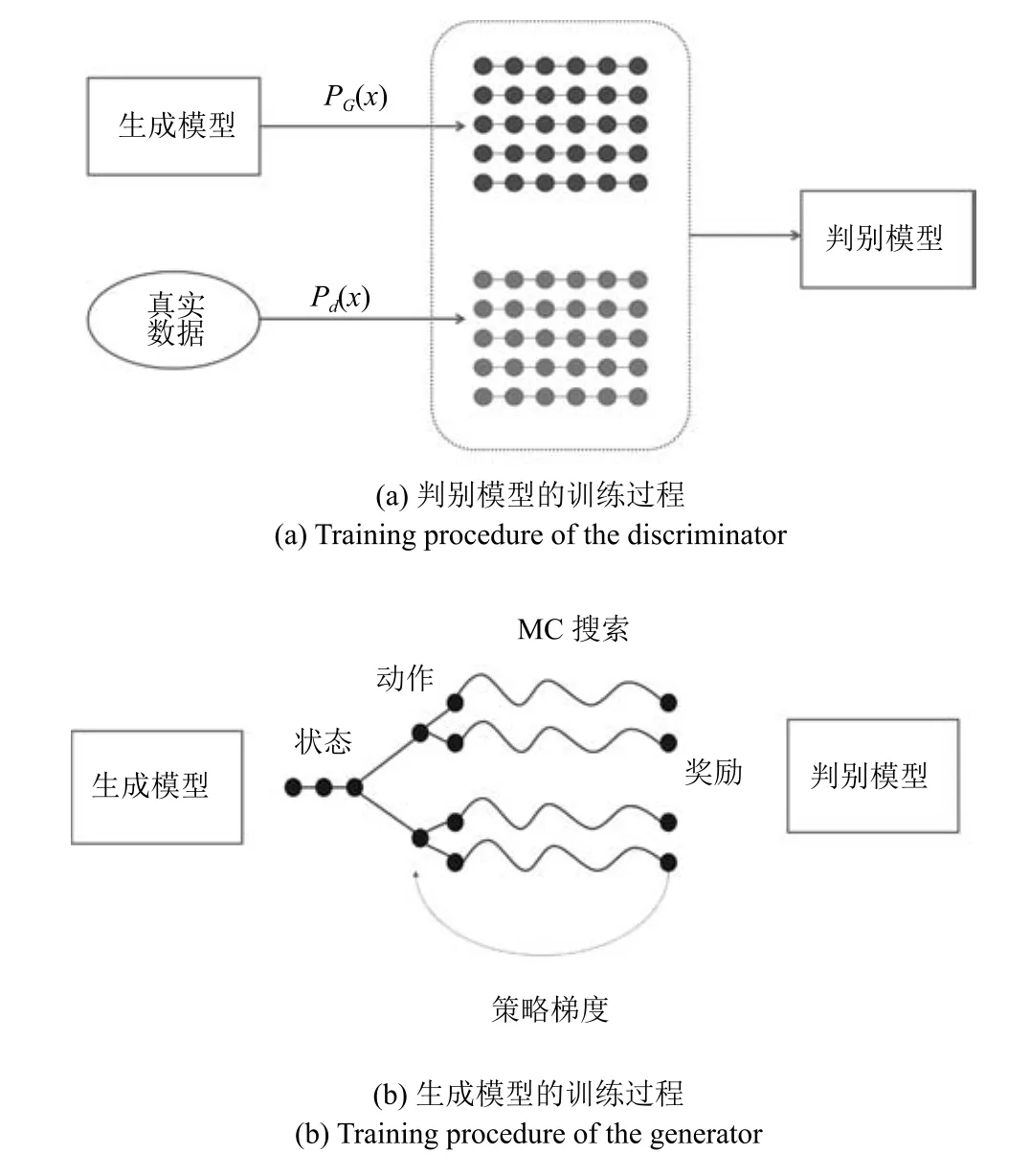
图1 序列生成对抗网络训练过程Fig.1 Training procedure of the sequential generative adversarial network
然而,判别模型只能对生成完成的序列进行评价.我们希望奖励信号不仅考虑已生成的序列是否符合最终目标,同时也考虑已生成序列中前缀子序列对生成后续词条的影响.为了评估生成序列的中间状态,本文采用MC搜索算法从模拟策略Gβ中采样尚未生成的最后T−t个词条.定义N次MC搜索如下:

其中,根据当前状态从模拟策略Gβ中采样得到.本文选取的模拟策略Gβ与生成模型Gθ拓扑结构相同.实际上,为了加速训练过程,可以选取更简单的模型作为模拟策略.为了减少方差并获取更精确的状态值,从当前状态开始按照模拟策略Gβ对尚未生成的子序列进行N次采样,得到N条采样序列.此时,“状态–值”函数变为

从式(9)可以看出,当没有中间状态奖励时,“状态–值”函数迭代的定义为从状态s=Y1:t开始下一状态的值,直到序列结束.
由于判别模型Dφ可以动态地更新,使用Dφ作为奖励函数可以迭代地提升生成模型Gθ的性能.一旦可以通过Gθ得到更加真实的生成序列,按照下式重新训练Dφ.
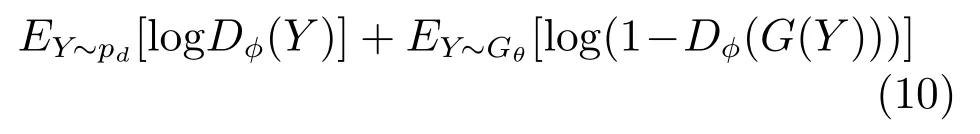
每当新的判别模型Dφ训练完成,迭代训练了生成模型Gθ,最大化目标函数为

然后,利用随机梯度下降算法更新生成模型Gθ的参数.
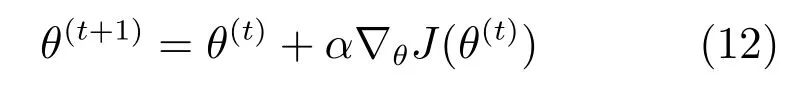
其中,α表示学习率,θ(t)表示第t次迭代中生成模型的参数.
算法1详细描述了序列生成网络的训练步骤.首先,采用MLE算法对生成模型Gθ进行预训练,然后利用预训练得到的Gθ生成采样数据对判别模型Dφ进行预训练.Goodfellow在文献[11]中指出,当判别模型Dφ在迭代训练过程中始终保持最优时,生成模型Gθ的分布会逐渐收敛到真实数据的分布.对Dφ进行预训练可以使其在对抗训练过程中迅速收敛到近似最优的状态.在预训练之后,生成模型与判别模型交替地进行训练.在对生成模型进行若干步更新之后,判别模型需要重新训练来和生成模型保持平衡.在对判别模型进行训练时,从给定的训练集中采样得到正样本,而负样本则由生成模型产生.为了保持平衡,在判别模型的每次训练中,保持正样本与负样本数目相同.为了减少估计的方差,类似Bootstrapping算法[18],在每次迭代中,采用不同的负样本对判别模型进行训练.
算法1.序列对抗生成网络
输入.训练集S={X1:T}
输出.生成模型(策略)Gθ
随机初始化生成模型(策略)Gθ,判别模型Dφ
在S上利用MLE算法对Gθ进行预训练
初始化模拟策略Gβ←−Gθ
利用Gθ生成负样本,对Dφ进行预训练


2.3 模型拓扑结构
2.3.1 生成模型
本文采用RNN作为序列生成模型.RNN模型的定义见式(1)和式(2).为了缓解梯度消失问题与梯度爆炸问题[19−20],本文采用长短时记忆单元(Long short-term memory units,LSTM units)结构代替式(1)[21−22].实际上,任何RNN模型的变体,例如门递归单元[23]和注意力机制[24],都可以作为序列生成模型.本文LSTM 单元的具体实施如下:
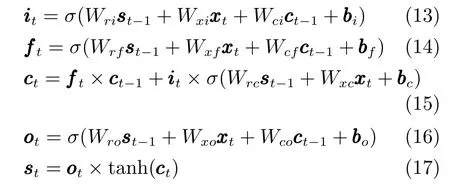
2.3.2 判别模型
深度神经网络[25]、卷积神经网络(Convolutional neural network,CNN)[26]和递归卷积网络[27]已被成功应用于序列分类任务中.近年来,CNN被广泛应用于文本分类问题,并取得了良好的效果[28].因此本文选取CNN作为判别模型.
首先将给定序列w1,w2,···,wT表示为

其中,是词条wt对应的k维词矢量,通过对wt的独热码进行线性变换得到[29].通过连接操作◦,可以得到输入序列的二维矩阵表示ε1:T∈Rk×T.然后,利用窗长为l的卷积核r∈Rk×l对输入特征ε1:T进行卷积操作,得到新的特征图.

其中,∗表示卷积操作,ρ是非线性函数,b是偏置项.采用多组不同窗长的卷积核即可得到多组不同的特征图.最后,对每张特征图在时间维度上进行最大值池化操作.
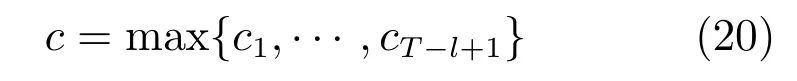
为了提高分类性能,在池化操作后添加了通道结构[30].

其中,H,T,C表示对池化层输出c进行不同的仿射变换后再进行非线性变换,通常采取sigmoid函数作为非线性激活函数.T表示变换门,C表示运输门.为了简化计算,本文令C=1−T.WH,WT,Wc是可训练参数矩阵.最后,采用sigmoid激活函数的全连接层输出分类概率.
3 实验
3.1 实验设置
本文实验在THCHS30[31]和AISHELL[32]两个中文普通话语音识别数据库上进行.THCHS30是清华大学开发的语音库,共30小时,文本取自大量新闻内容.AISHELL是北京希尔贝壳科技有限公司发布的数据集,共178小时,包含400位来自中国不同口音区域的发言人,录音文本包含财经、科技、体育、娱乐等领域.
本文利用THCHS30和AISHELL提供的转录文本作为原始数据训练RNN生成模型,并利用该RNN模型生成采样数据.然后利用生成的数据训练新的N-gram LM与转录文本训练的N-gram LM插值.最后用插值后的语言模型对识别候选进行重估.
本文利用Kaldi工具[33]搭建基线识别系统,输入特征是11帧串联的MFCC特征.基线语言模型与生成数据估计的语言模型采用Kneser-Ney平滑的三元文法语言模型,由SRILM工具[34]训练得到.序列生成对抗网络中的RNN与CNN模型的训练由TensorFlow工具[35]实现.
RNN生成模型包含2层隐含层,每层由150个LSTM单元组成.输出层节点数等于词典大小,词典共包含55590个中文词.为了防止模型对训练数据过拟合,训练时采用了丢弃正则化技术,在预训练与对抗训练过程中初始丢弃率均为0.3.
CNN判别模型分别采用窗长为1,2,3,4,5,10的卷积核进行卷积操作,每个窗长分别使用50个不同的卷积核.此外,判别模型包含2层通道层,每层150节点.输出层包含1个节点,表示输入序列与真实数据相似程度.在训练过程中,同样采取丢弃正则化技术防止模型过拟合,丢弃率为0.3.同时在输出层采用L2范数正则化技术,正则项系数为0.1.
生成模型和判别模型的训练采用基于Adam算法[36]的批量(Mini-batch)随机梯度下降更新参数,输入序列长度为20,批量数目为35.生成模型的初始学习率为0.01,衰减速率为0.95.判别模型的学习率为0.0001.
3.2 对抗训练中超参数的选取
在对抗训练过程中,超参数的选取对最终生成模型的性能至关重要.对抗训练中主要的超参数包括:每次迭代中生成模型的训练步数g-steps,每次迭代中判别模型的训练步数d-steps,每次迭代中用于判别模型训练的负样本采样数samples(以Minibatch为单位).为了分析上述超参数对模型性能的影响,本文在THCHS30数据集上进行了相关实验,结果如图2所示.
从图2可以看出,当用于判别模型训练的负样本采样数(samples)增加时,生成模型和判别模型训练误差的方差减小.同时,增加负样本采样数会加快判别模型的收敛,如图2(b)所示.当生成模型训练步数(g-steps)增加时,生成模型训练误差迅速减小并保持稳定,但是判别模型在大约500次批量更新时才收敛到最优.此时生成模型学习到的分布并不是真实数据的分布,因为判别模型尚未收敛到近似最优[11].本文实验取g-steps=1,d-steps=1,samples=3.
3.3 基于相对交叉熵的数据扩增
序列生成对抗网络在不同数据集上的性能如图3所示.从图3(a)可以看出,在THCHS30和AISHELL两个数据集上,生成模型均迅速收敛.图3(b)给出了生成模型在验证集上交叉熵的变化.模型在开发集上的交叉熵越高,说明模型分布(即生成数据的分布)与开发集数据分布相差越大.从图3(b)可以看出,单独使用THCHS30或AISHELL数据集的转录文本对生成模型进行训练时,虽然生成模型可以生成高质量的采样数据,但生成模型对训练集过拟合,生成的数据泛化性较差.数据增强的目的是在保证生成数据的分布与原始数据分布接近的条件下,生成尽可能多样化的采样数据,以丰富原始数据的文法现象.
为了解决上述问题,从网易、搜狐等网站爬取了部分新闻数据(约860M词).然后按照文献[37]中基于相对交叉熵的数据挑选算法,将THCHS30和AISHELL的转录文本作为目标数据,从网页爬取数据中挑选了部分与目标数据风格接近的文本(约6M 词)扩充生成模型的训练集.然后将扩充的数据集(包含THCHS30和AISHELL的转录文本以及挑选的网页数据,记为AUGMENT)作为生成模型的训练数据,生成模型的训练误差及其在开发集(此处的开发集合并了THCHS30和AISHELL的开发集)上的交叉熵分别在图3(a)和图3(b)给出.扩充训练集后,虽然生成模型在训练集上收敛较慢且最终误差较高,但其在开发集上始终保持良好的泛化性能,符合数据增强的目的.因此,在后续的语音识别多候选重估实验中,采用扩充后的训练集对生成模型进行训练.
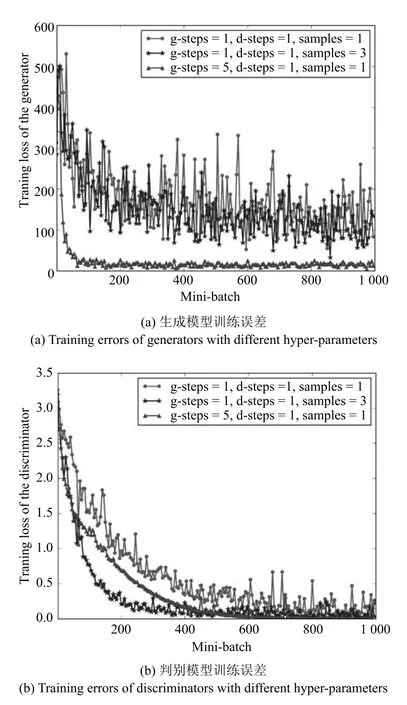
图2 不同超参数条件下序列对抗生成网络训练误差Fig.2 Training errors of sequential generative adversarial networks with different hyper-parameters
3.4 识别多候选重估实验
在训练得到生成模型之后,按照第1节的方法生成采样数据.为了对比对抗训练策略与MLE两种训练准则对生成模型性能的影响,分别从采用两种训练准则得到的生成模型中采样生成1000000条句子.为了保证实验的公平性,两个生成模型采用相同的数据集进行训练,即第3.3节中扩增后的数据集.然后利用采样数据分别训练Kneser-Ney平滑的三元文法语言模型.词典与训练生成模型的词典相同,共包含55590个中文词.

图3 序列生成对抗网络在不同数据集上的性能Fig.3 Performance of sequential generative adversarial networks on different datasets
对于测试集中的每条语音,本文保留一遍解码中得分最高的100条候选.实际操作时,为了方便遍历最优的插值系数,将新语言模型的得分与基线语言模型的得分进行动态的插值.首先用新语言模型计算每条候选的新语言模型得分.然后,将每条候选的新语言模型得分与基线语言模型得分按如下公式加权作为该候选最终的语言模模型得分slm.

其中,snew表示新语言模型得分,sbase表示基线语言模型得分,ω是新语言模型得分的插值权重.最后计算该候选的总得分.

其中,γ是语言模型得分权重因子,sam表示该候选的声学模型得分.得到各条候选新的得分之后,从中选取得分最高的候选作为该测试语音的重估解码结果.表1是对重估解码结果CER的统计.

表1 不同数据增强技术对识别字错误率的影响(%)Table 1 Character error rates of different methods(%)
从表1中可以看出,不同的语言模型数据增强技术均可以有效降低CER.相比于基于MLE的语言模型数据增强技术,本文提出的基于对抗训练策略的数据增强技术可以进一步降低CER.在两个测试集上,本文提出的方法使CER相对基线系统分别下降5.0%和7.1%.实际上,判别模型的输入特征是不同阶数的N元文法特征,由不同窗长的卷积核与输入特征进行卷积得到.即判别模型通过给定文本序列的N元文法特征判断其与真实数据的相似性.因此生成模型产生的文本序列中的N元文法分布更类似于真实数据中的N元文法分布.而N-gram LM正是通过训练文本中的N元文法的分布来估计给定句子的概率.因此,基于对抗生成策略的数据增强技术可以有效提升语言模型在语音识别任务中的性能.
为了进一步分析本文提出的数据增强方法与基于MLE的数据增强方法的性能差异,本文在不同规模的训练数据上进行了对比实验.已有的研究结果[38]表明,RNN模型的性能不仅取决于训练数据的规模,同时也取决的训练数据的质量.即只有在增加领域相关的训练数据时,RNN模型的性能才会提升,否则其性能反而会下降.由于无法获取大量领域相关的文本数据,本文中的实验在训练集的不同子集上进行.
本文首先将训练集 (约 6M 词)分为A(约0.7M 词)、B(约 1.5M 词)、C(约 2.9M 词)三个子集,且C子集包含B子集,B子集包含A子集.然后采用上文所述的方法和模型参数在各个训练集上分别训练生成模型、生成采样数据、最终利用增强的语言模型进行识别结果重估,结果如图4所示.
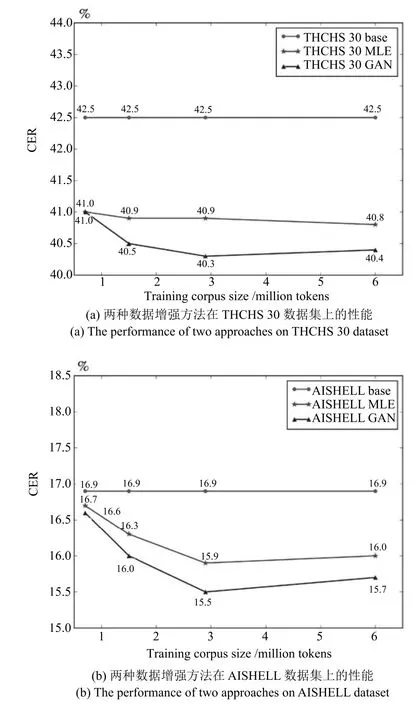
图4 训练数据规模对两种数据增强技术性能的影响Fig.4 The effect of the size of training data on two augmentation approaches
实验结果表明,在各个子集上,两种数据增强技术均可以降低CER.在子集A上,由于训练数据过于稀疏,生成模型无法鲁棒地建模训练数据的分别,同时判别模型也无法学到真实数据与采样数据之间的差异,本文提出的方法与基于MLE的方法性能基本一致,且对识别性能提升较小.在B,C子集和全集上,本文提出的方法相对基于MLE的方法可以进一步降低CER.然而在全集上两种数据增强方法的性能反而略差于在C子集上的性能,可能的原因是第3.3节中用以扩充训练集的网络数据与原始领域相关的数据(语音转录文本)存在一定的差异,当增加的网络数据较多时,会对模型的性能造成一定的影响.
从图4中两种数据增强方法性能随训练数据量变化趋势可以看出,两种方法的性能均随着训练数据增加而提升.文本提出的方法在不同规模数据集上均取得了更低的CER,且相对基于MLE的方法的性能提升首先随数据量增加而增大,随后在数据量达到一定规模后(约1.5M词)基本保持稳定.
值得注意的是,本文提出的方法是为了缓解有限训练数据条件下语言模型参数估计鲁棒性差的问题.相关研究表明,当领域(任务)相关训练数据足够多时,数据增强技术带来的性能提升十分有限.这是因为原始训练数据中已包含绝大部分文法现象,数据增强技术仅能提供有限的补充数据.因此可以推测,随着训练数据量的增加,基线语言模型性能不断提升,未使用数据增强技术的基线模型、基于MLE方法的数据增强方法与本文提出的方法三者之间的性能差异逐渐减小甚至消失.因此,本节的实验结论并不适用于大规模训练数据的情况.
3.5 生成模型性能分析
当采样数据足够多时,采样数据的分布可以近似表示生成模型的分布.因此,为了分析生成模型的性能,本文分别利用基于MLE的生成模型和基于对抗训练策略的生成模型生成50000句文本,同时从训练数据中随机抽取50000句文本.然后利用文献[39]中的算法得到每句文本的分布表示,即将每句话表示为一个向量.本文实验采用100维的向量表示一句采样文本或真实文本.为了可视化采样数据与真实数据的分布,本文采用t-SNE算法[40]将文本的分布表示映射到二维空间.结果如图5所示.从图5可以看出,基于对抗训练策略的生成模型的分布与真实数据的分布更接近.
为了进一步分析不同训练准则对生成模型性能的影响,从训练数据中随机挑选若干句文本,将每句文本的前半句作为历史信息送入生成模型,让生成模型生成下半句文本.表2是实验中的部分样例,逗号前的文本表示历史信息,MLE表示基于最大似然估计的生成模型产生的文本,GAN表示基于对抗训练策略的生成模型产生的文本.
首先,与MLE相比,对抗训练策略产生的文本具有更加明确的语义信息(样例2,3).其次,对抗训练策略产生的文本与历史信息之间的关系更密切.例如样例1历史信息中的“旱情”与生成文本中的“粮食”,样例3历史信息中的“销售额”与生成文本中的“增至”.此外,对抗训练策略可以在一定程度上缓解暴露偏差问题.例如样例4中,MLE根据历史信息产生的文本最终的着重点在“创新”,而对抗训练策略生成的文本虽然开始部分与历史信息的语义差距较大,但最终生成文本的着重点在“规划”,与真实数据一致.说明基于对抗训练策略的生成模型的分布与真实的数据分布更接近,同时生成文本的长时语义信息更加明确.

图5 不同采样数据的分布图Fig.5 Distribution of sentences sampled from different sources
4 结论
本文提出了一种基于对抗训练策略的语言模型数据增强方法,并将GAN产生的数据应用于语音识别任务中.首先利用生成模型产生的采样文本对语言模型进行数据增强,然后将增强的语言模型用于语音识别多候选重估.与传统生成任务不同,在语言模型增强任务中,必须保证生成文本数据的多样性,即使生成模型保持一定的泛化性能.同时由于实际数据的复杂性,在对抗训练中需要对判别模型进行充分优化,才能使其性能在整个对抗训练过程中保持近似最优.识别多候选重估实验表明,相比基于MLE的语言模型数据增强方法,本文提出的方法可以进一步降低识别错误率.且相对基于MLE的数据增强方法的性能提升,本文提出的方法首先随着训练数据量的增加而增大,随后当训练数据量达到一定规模后,相对性能提升基本保持恒定.此外,本文对不同生成模型生成的数据进行了详细的分析.实验表明,利用本文提出的方法生成的数据的分布更接近真实数据的分布,且生成的句子具有更加明确的长时语义信息.

表2 相同历史信息条件下不同生成模型生成的文本对比Table 2 Sentences generated by different models given the same context
本文提出的方法主要是为了缓解有限训练数据条件下语言模型参数估计鲁棒性差的问题,并不适用于大规模训练数据条件下的语言模型建模和识别任务.如何利用对抗训练策略提升大规模训练数据条件下语言模型及识别系统的性能是后续研究的一个方向.
1 Si Yu-Jing,Xiao Ye-Ming,Xu Ji,Pan Jie-Lin,Yan Yong-Hong.Automatic text corpus generation algorithm towards oral statistical language modeling.Acta Automatica Sinica,2014,40(12):2808−2814(司玉景,肖业鸣,徐及,潘接林,颜永红.面向口语统计语言模型建模的自动语料生成算法.自动化学报,2014,40(12):2808−2814)
2 Allison B,Guthrie D,Guthrie L.Another look at the data sparsity problem.In:Proceedings of the 9th International Conference on Text,Speech,and Dialogue.Brno,Czech Republic:Springer,2006.327−334
3 Janiszek D,De Mori R,Bechet E.Data augmentation and language model adaptation.In:Proceedings of the 2001 IEEE International Conference on Acoustics,Speech,and Signal Processing.Salt Lake City,UT,USA:IEEE,2001.549−552
4 Ng T,Ostendorf M,Hwang M Y,Siu M,Bulyko I,Lei X.Web-data augmented language models for mandarin conversational speech recognition.In:Proceedings of the 2001 IEEE International Conference on Acoustics,Speech,and Signal Processing.Philadelphia,USA:IEEE,2005.589−592
5 Si Y J,Chen M Z,Zhang Q Q,Pan J L,Yan Y H.Block based language model for target domain adaptation towards web corpus.Journal of Computational Information Systems,2013,9(22):9139−9146
6 Sutskever I,Martens J,Hinton G.Generating text with recurrent neural networks.In:Proceedings of the 28th International Conference on Machine Learning.Bellevue,Washington,USA:IEEE,2011.1017−1024
7 Bowman S R,Vilnis L,Vinyals O,Dai A M,Jozefowicz R,Bengio S.Generating sentences from a continuous space.arXiv:1511.06349,2015.
8 Ranzato M,Chopra S,Auli M,Zaremba W.Sequence level training with recurrent neural networks.arXiv:1511.06732,2015.
9 Norouzi M,Bengio S,Chen Z F,Jaitly N,Schuster M,Wu Y H,et al.Reward augmented maximum likelihood for neural structured prediction.In:Proceedings of the 2016 Advances in Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.1723−1731
10 Lamb A,Goyal A,Zhang Y,Zhang S Z,Courville A,Bengio Y.Professor forcing:a new algorithm for training recurrent networks.In:Proceedings of the 29th Conference on Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.4601−4609
11 Goodfellow I J,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,Ozair S,et al.Generative adversarial nets.In:Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal,Canada:NIPS,2014.2672−2680
12 Wang Kun-Feng,Gou Chao,Duan Yan-Jie,Lin Yi-Lun,Zheng Xin-Hu,Wang Fei-Yue.Generative adversarial networks:the state of the art and beyond.Acta Automatica Sinica,2017,43(3):321−332(王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报,2017,43(3):321−332)
13 Kaelbling L P,Littman M L,Moore A W.Reinforcement learning:a survey.Journal of Arti ficial Intelligence Research,1996,4(1):237−285
14 Van Otterlo M,Wiering M.Reinforcement learning and Markov decision processes.Reinforcement Learning:Stateof-the-Art.Berlin,Germany:Springer,2012.3−42
15 Chen Xing-Guo,Yu Yang.Reinforcement learning and its application to the game of go.Acta Automatica Sinica,2016,42(5):685−695(陈兴国,俞扬.强化学习及其在电脑围棋中的应用.自动化学报,2016,42(5):685−695)
16 Chaslot G M J B,Winands M H M,Uiterwijk J W H M,Van Den Herik H J,Bouzy B.Progressive strategies for Monte-Carlo tree search.New Mathematics and Natural Computation,2008,4(3):343−357
17 Silver D,Huang A J,Maddison C J,Guez A,Sifre L,Van Den Driessche G,et al.Mastering the game of go with deep neural networks and tree search.Nature,2016,529(7587):484−489
18 Quinlan J R.Bagging,boosting,and C4.5.In:Proceddings of the 13th National Conference on Arti ficial Intelligence and the 8th Innovative Applications of Arti ficial Intelligence Conference.Portland,USA:AAAI,1996.725−730
19 Pascanu R,Mikolov T,Bengio Y.On the difficulty of training recurrent neural networks.In:Proceedings of the 30th International Conference on Machine Learning.Atlanta,USA:ACM,2013.III-1310−III-1318
20 Pascanu R,Mikolov T,Bengio Y.Understanding the exploding gradient problem.arXiv:1211.5063,2012.
21 Hochreiter S,Schmidhuber J.Long short-term memory.Neural Computation,1997,9(8):1735−1780
22 Sundermeyer M,Schlüter R,Ney H.LSTM neural networks for language modeling.In:Proceedings of the 13th Annual Conference of the International Speech Communication Association.Portland,USA:IEEE,2012.601−608
23 Cho K,Van Merrienboer B,Gulcehre C,Bahdanau D,Bougares F,Schwenk H,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation.arXiv:1406.1078,2014.
24 Bahdanau D,Cho K,Bengio Y.Neural machine translation by jointly learning to align and translate.arXiv:1409.0473,2014.
25 Veselý K,Ghoshal A,Burget L,Povey D.Sequencediscriminative training of deep neural networks.In:Proceedings of the 14th Annual Conference of the International Speech Communication Association.Lyon,France:IEEE,2013.2345−2349
26 Kim Y.Convolutional neural networks for sentence classi fication.arXiv:1408.5882,2014.
27 Lai S W,Xu L H,Liu K,Zhao J.Recurrent convolutional neural networks for text classi fication.In:Proceddings of the 29th AAAI Conference on Arti ficial Intelligence.Austin,USA:AAAI,2015.2267−2273
28 Zhang X,LeCun Y.Text understanding from scratch.arXiv:1502.01710,2015.
29 Mikolov T,Chen K,Corrado G,Dean J.Efficient estimation of word representations in vector space.arXiv:1301.3781,2013.
30 Srivastava R K,Gre ffK,Schmidhuber J.Highway networks.arXiv:1505.00387,2015.
31 Wang D,Zhang X W.THCHS-30:a free Chinese speech corpus.arXiv:1512.01882,2015.
32 Bu H,Du J Y,Na X Y,Wu B G,Zheng H.AIShell-1:an open-source mandarin speech corpus and a speech recognition baseline.arXiv:1709.05522,2017.
33 Povey D,Ghoshal A,Boulianne G,Burget L,Glembek O,Goel N,et al.The Kaldi speech recognition toolkit.In:Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition and Understanding.Hawaii,USA:IEEE,2011.1−4
34 Stolcke A.SRILM—an extensible language modeling toolkit.In:Proceedings of the 7th International Conference on Spoken Language Processing.Denver,USA:IEEE,2002.901−904
35 Abadi M,Agarwal A,Barham P,Brevdo E,Chen Z F,Citro C,et al.Tensor flow:large-scale machine learning on heterogeneous distributed systems.arXiv:1603.04467,2016.
36 Kingma D P,Ba J.Adam:a method for stochastic optimization.arXiv:1412.6980,2014.
37 Moore R C,Lewis W.Intelligent selection of language model training data.In:Proceedings of the 2010 ACL Conference Short Papers.Uppsala,Sweden:ACM,2010.220−224
38 Tüske Z,Irie K,Schlüter R,Ney H.Investigation on loglinear interpolation of multi-domain neural network language model.In:Proceedings of the 2016 IEEE International Conference on Acoustics,Speech,and Signal Processing.Shanghai,China:IEEE,2016.6005−6009
39 Le Q,Mikolov T.Distributed representations of sentences and documents.In:Proceedings of the 31st International Conference on Machine Learning.Beijing,China:IEEE,2014.1017−1024
40 Van Der Maaten L.Accelerating t-SNE using tree-based algorithms.The Journal of Machine Learning Research,2014,15(1):3221−3245
