知识网络情绪互信息熵检测*
2018-06-06涂坤,孙彬,王东
涂 坤, 孙 彬, 王 东
(1. 新疆财经大学 计算机科学与技术学院, 乌鲁木齐 830012; 2. 新疆教育学院 新疆教育云重点实验室, 乌鲁木齐 830033)
情感交流渗透于网络认知活动中,影响着认知者的心智状态和行为趋向,基于情感互信息的情绪熵检测算法显示出非常重要的效用价值.
知识网络与情绪疏导的关联性研究及与本文紧密相关的典型成果梳理如下:
1) 关于认知活动中情绪触动效用的研究广泛,但知识资源层次结构与情绪关联的研究不足.利用Relieff算法进行特征选择[1],筛选出最主要的特征指标,并由此找出有效助学的情绪特征,几乎不涉及知识网络资源结构;PCA算法[2]使用实时情绪触动结果进行情感效能定位,提升情绪联动效果,不涉及资源网络结构问题;文献[3]将网民个体视为一个智能体建立情绪传播模型,较好地实现认知者的情感瓶颈问题,但关于知识资源结构本身的特征涉及的很少;基于多种社交凭证的社交认证模型[4]应用记录采集算法、社交凭证生成算法和社交认证算法等,实现了情绪促动的多层次因子,但所涉及知识网络结构问题很薄弱;文献[5]基于深度学习目标模型进行了细粒度的情感分析,达到对人类情感表达的深度理解,却完全不涉及知识网络的资源结构特征;采用卷积神经网络[6]可发现任务中的情感特征,但知识网络资源结构特征考虑的不够充分.虽然应用计算机进行情绪测算的成果丰富,但情感过程与网络知识结构相融合的研究较少,知识网络结构与情感促学的适用度研究有待改进.
2) 情感信息熵的情感演化测算体现出高聚集特征,情感检测适用度不足现象始终存在.信息墒改进TOPSIS算法[7]能弥补指标体系受主观偏好影响过大的缺陷,较好地体现情感评价的客观性、公正性和时效性,但是情感检测适用性不足;依托情感测算的信息熵算法模式[8]注重认知者的内在情感体验与人格的全面考察,更能贴近认知过程的“自我实现”,但没有结合知识网络的资源结构,使得应用难以推广;基于LDA微博用户关系的主题情感模型SRTSM[9]在资源结构基础上,加入情绪熵关系参数和情感极性,涉及知识层次结构,但深度有限;智能情感信息熵导引模型[10]可大幅度提高认知过程与情感倾向的关联作用,但关联深度不足;基于概率图模型的情感分析方法[11-12]能够有效运用“评价对象”和“评价词”二元特性的情感判定,但是适用范围有限.关于情绪在智慧活动中的效能检测,由于没有结合知识层次结构特征,适用度有限.用信息熵测量方法提高适用度是值得关注的研究方向.
3) 情熵理念被广泛应用于情绪检测工程中,往往成为其它分类算法的关键支撑,而在知识网络的情感切合方面需要进一步加深探究.文献[13]将信息熵定律应用到稳定系统的测算过程中,层次结构知识熵被应用到多个方面的聚类;文献[14-15]提出了情感强度和知识结构之间的关系熵测评理念,在情感数据分类挖掘的特定背景下,计算不同资源标识符属性,建立智能分类树,对本研究有重要的理性支持和启示.
总结上述观点可知,情感信息熵及知识资源层次结构的结合问题成为了认知效能研究的突破点,网络认知活动中情感信息熵理念和情感测算模型应该被赋予更高的关注度.从认知技术的角度来看,情绪测算是一项复杂的系统工程,涉及到知识资源自身的结构层次复杂性、情感疏导的广泛性及适用性.
1 情熵与效能测算法
知识认知过程是建立在一定情感积累基础上的,为使知识认知过程更加科学有效,贴合实际,情商诊断过程与认知效能测评环节尤为重要.需要实现知识结构合理布局与情感疏导的关联性测量,使当代认知引导观念获得有益的启示.
1.1 认知效能模型
在知识网络中,认知过程是个由浅入深的渐进过程,认知者围绕知识网络,实现认知层次进阶过程.知识节点之间能构成一个有向图拓扑结构,其中每一条有向边均代表着一条知识探索途径,捆绑着若干认知参与者的学习属性特征.假设分布式网络由众多的认知结构模型知识节点和知识连接线(认知边)构成,并定义知识节点为m,构成的知识认知网络为G(V,L),且属于一个有向图,知识节点构成的节点数据集为V={v1,v2,…,vm},认知途径集为L={(vi,vj)vi,vj∈V}.在认知网络G中,任何一个节点都可以用直接相邻知识点拓扑分析,获得节点的前导集合F(vi)和后续集合B(vi).考虑到学习途径进阶的需要,节点vi被疏通的概率分布为
(1)
认知者在认知网络节点间移动,进行认知活动,受情绪、环境和特殊偏好的影响,表现为各自不同的学习效能.将这些异质的情绪属性设计为情商基因,表示为D={ξ1,ξ2,…,ξk},对应于“兴趣所致”、“生计压力”、“群体压力”、“感悟”、“欣赏”和“自我实现”等情感因子,每种基因假定有5个级别强度:{0-无,1-弱,2-中,3-强,4-极强}.对于认知网络G的任意节点vi,假设有m个认知节点,每个节点采集k种基因,可形成情绪强度数据矩阵,第i个认知节点的第k个基因ξk的强度记为xik,表示矩阵为
(2)
对于情绪基因ξk而言,基于节点vi的情绪偏离度为
(3)
学习往往是一个反复攻关的过程,所以必须考虑学习行为的重复性,由此在知识边上,将发生的ξk情绪行为的总强度记为

(4)
则认知者在情感ξk作用下,vi知识节点被疏通的概率分布为
(5)
式中:csk(i)为探求其它知识节点的总情绪强度;ctk(i)为访问vi节点进行求知活动的总情绪强度.
1.2 情绪与认知效能的互信息
在没有情绪干扰的情况下,随机访问程度趋向于最大程度的无序时,信息熵H(v)趋于最大.对于预定的认知网络G,知识节点(知识边)的访问效能信息熵为
(6)
在知识点(vi)及知识路径(vi→vj)预先布局的情况下,将情绪量(ξk)变化所产生的熵定义为条件熵,表示为

(7)
随机变量组(v,ξ)的联合分布与独立分布乘积的相对熵被定义为互信息.互信息结构如图1所示,互信息被看作是一个随机变量与另一个随机变量的关联性,其不确定性的变异程度可表示为

(8)
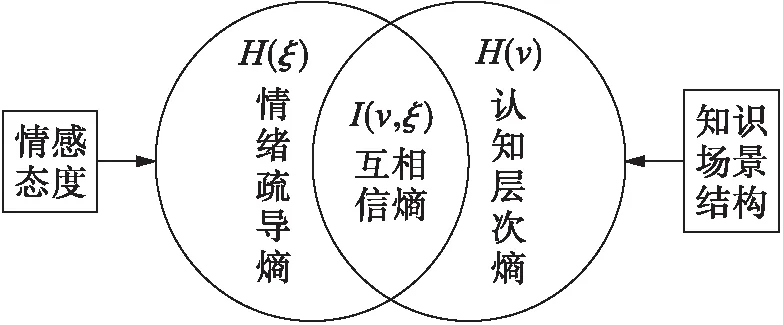
图1 互信息结构Fig.1 Mutual information structure
1.2.1 情绪重要度
按照情绪应当适用于认知过程的原则,合理搭配知识节点和知识边资源,就能把结构层次调整为最优适用性,以获得高效率的认知效果.衡量知识节点的重要性即是情感认知引导的首要问题.定义节点vi的情商重要度为
τ(vi)=IG-{vi}(v,ξ)-IG(v,ξ)
(9)
定义节点子集s(s={v1,v2,…,vk},s⊂V)的重要度为
τ(s)=IG(v,ξ)-IG-s(v,ξ)
(10)
重要度τ(vi)和τ(s)在增补优良知识节点、遴选核心骨干知识点及进行知识节点的择优挑选等方面具有较高的应用价值.
1.2.2 情商适用度
知识边情绪如何参与到认知活动中将直接影响到情绪的总强度,进而改变互信息熵.参与角色的情感描述与知识点层次结构的灵活组合构成了认知策略的多样性.
在知识网络G中,新认知活动T参与后,形成认知资源G+T,借鉴Jaccard相似原理,定义适用度函数为
(11)
J(T)是新资源T对认知网络G的适用度评价成绩,J(T)成绩越高,则G与T相关性程度越高,资源子网T具有较高的优选作用.
1.2.3 认知资源聚类算法
1) 将包含部分知识边(参与的情绪项元素)和部分知识资源的节点子集按照其重要性τ(fi)或适用度J(fi)降序排列成子集序列f={f1,f2,…,fk},对应的适用度列表为{J(f1),J(f2),…,J(fk)}.
2) 资源项消重处理.每重资源项只保留首次出现的子集形式.
3) 构建差值数列{h1,h2,…,hn},其中,hi=J(fi).
5) 将子序列资源列表按照邻近且Δγi≤λ决定同类的规则(即Δγi≤λ,那么fi和fi+1属于同类;否则fi和fi+1分属于不同类别)进行分类.
6) 对每个子类再进行下一级递归分类,实施更多维度的分类,直到组内成员间的适用度差值均低于预定阀值.
1.2.4 情熵距离
本工作采用不同氮含量保护气氛下熔炼坯料、1 000°C固溶保温1 h并快速淬火的方式研究了N含量对Fe-21Cr-3Ni-1Mo-N双相不锈钢凝固组织的影响,并得出以下结论.
在认知知识资源网络G上,所有子资源网络集合为d={d1,d2,…,dn}.针对一个认知项目rx,将d中所有包含rx项目的资源子集合定义为π(rx).对于G的任意两个资源子集π(rx)、π(ry)情感距离定义为
(12)
以认知项目rx为中心,设定一类阈值τ0,面对G中的任意其它项目均可测算情熵距离.将情熵距离小于τ0的认知项目称为rx的情感紧密项目.
通过情熵距离和子集资源可以发现最优认知路径,从而丰富情感疏导在认知活动中的适用性,为认知者提供适用的、具体且行之有效的知识资源咨询与关爱服务.
2 实践结果与分析
为验证情绪熵与认知效能之间的关联性,本文采集真实数据,并对真实认知数据进行了聚类,抽取典型认知案例,布局成认知知识网络,对假设观点进行实践测试.数据集记录了认知网络中的认知数据与情绪数据情况,共包含34个结构各异的数据表,有12 Gbit记录.实验中分离出7个认知单元的有效数据集:销售知识技巧(z1)、物流快送知识(z2)、电商促销知识(z3)、页面制作知识(z4)、广告知识(z5)、包装工艺知识(z6)和业务推广知识(z7),各数据集邻接概况如表1所示.

表1 数据集邻接概况Tab.1 Adjacency profiles of data sets
2.1 情绪熵聚类作用
结合认知网络知识点的布局,计算情绪信息熵重要度指标,并进行节点学习效能特征和情绪基因特征的关联性测量,测量结果如图2所示.通过情绪信息熵的聚类实践可以发现:
1) 情绪聚类数量值可以代表情绪属性边的数值量.用情绪聚类数量值进行实际的情绪变化测算可以直接降低相关情绪数据集的规模,达到数据集快速约简和检索的目的.
2) 通过认知网络层次结构的设计,可以设置情绪调整因素的强度,实施有利分类策略,将积极适用的情感因素捆绑在知识边属性特征中,从而能限制情绪熵的类别数量,形成适用的网络认知调节机制.
3) 核心知识节点数与有效情绪边数量的调整有利于特异情感问题的发现.控制知识学习中的特异型情绪,就是控制情绪子类奇异的过程,有助力于情熵碎片排除工作,能够及时发现骄傲、孤僻和偏激等情绪倾向,将成为心理健康导引的强力工具.

图2 数据集聚类对比Fig.2 Comparison in cluster of data sets
2.2 知识点增加效用
对网络知识活动的情绪熵数据重要度分析过程中,将情绪调节项目保持不变,随着资源(知识点)的增加,其情绪适用度变化趋向明显,结果具有一定的借鉴作用.以z1、z2、z3和z4四类数据集为例,情绪项数据(边属性)保持不变,而知识节点由50项逐步扩大到600项,适应度变化过程如图3所示.不同知识数据集的情绪适用度各异,其中z4数据集伴随着适用度线性增加,且一直保持最高;z2和z3数据集也基本保持增函数特征;而z1数据集发生明显的互信息熵适应度递减的想象.

图3 情绪适应度变化曲线Fig.3 Change curve of emotional fitness
由图3分析可知:
1) 同样的情绪调控措施不能应用于所有的知识学习布局结构中.在一种知识布局结构中,表现良好的情绪调控项目在另一种知识数据布局结构中就可能完全不适用.
2) 在知识点规模不同的认知网络中,同样的情绪调控措施可能出现不同的控制效果.
2.3 激励效用
网络认知的知识节点保持不变,将各种情绪调整因素进行等量激励加强(如“关注”、“突出显示”、“奖励”、“表扬”和“定级”等情绪激励活动),动态测算情绪信息熵的变化特征.以z1、z2、z3和z4数据集为例,围绕固定不变的知识点布局结构,设计情绪调节项目等量递增,仅使用积极性激励调整手段,情绪激励项目由0项增加到50项,再逐步降低到0项.情绪互信息熵在情绪调整项目加入后,情感适用度变化趋势如图4所示.

图4 情绪适应度趋势Fig.4 Emotional fitness trend
由图4变化曲线可以发现:
1) 初期的表扬激励(10~20项)对情绪信息熵适用度的作用较大,随着激励表扬项目的逐步增多,情绪适用度的增加效应基本丧失.
2) 不同数据集对激励表扬措施的情绪适用度总趋势是一样的,表扬激励项目超过30项之后,激励的作用就大大降低.
2.4 情熵距离效用
情熵距离用于表示情绪事件前后的差异程度.以关注、肯定、奖励和惩罚项目的平均基因强度为参照,观察情熵距离的变化情况如图5所示.

图5 情熵距离变化曲线Fig.5 Change curve of emotional entropy distance
奖励项目的情绪变动能使情绪熵产生较大值,但存在最佳刺激强度区间,该项激励容易发生过度无效;惩罚项目带来的情绪变动最直接,但是有效强度界于0.3~1.8之间;关注项目给认知参与者带来的情绪变化比较缓慢,但持续有效刺激区间较宽;肯定项目给认知参与者带来的情绪变化最为缓慢,持续有效刺激区间最宽.
3 结 论
在知识资源网络中,知识布局结构与情绪过程有显著关联.情绪互信息熵能有效地诠释网络环境下情绪资源的优择问题,通过对情绪效益指标的测量,把网络认知过程中的有益情绪提取出来,及时准确地发现认知过程中的优势因素和干预因素,使学习行为在知识网络布局结构上进行优化,实现积极情绪与认知资源的有益融合.
参考文献(References):
[1] 刘群,张振.基于智能移动终端触屏行为的情绪识别 [J].微电子学与计算机,2016,33(6):44-48.
(LIU Qun,ZHANG Zhen.Emotional state detection from touch-based behavior on touch-screen device [J].Microelectronics & Computer,2016,33(6):44-48.)
[2] 王万森,温绍洁,郭凤英.基于人工情绪的智能情感网络认知系统研究 [J].小型微型计算机系统,2016(3):569-572.
(WANG Wan-sen,WEN Shao-jie,GUO Feng-ying.Study of intelligent affective network tutoring system based on artificial emotion [J].Journal of Chinese Computer Systems,2016(3):569-572.)
[3] 赵卫东,赵旭东,戴伟辉.突发事件的网络情绪传播机制及仿真研究 [J].系统工程理论与实践,2015,35(10):2573-2581.
(ZHAO Wei-dong,ZHAO Xu-dong,DAI Wei-hui.Emotion propagation mechanism of emergency events in cyber space and simulation [J].Systems Engineering-Theory & Practice,2015,35(10):2573-2581.)
[4] 周炜,牛连强,王斌.面向社交网络的认证模型 [J].沈阳工业大学学报,2016,38(5):545-550.
(ZHOU Wei,NIU Lian-qian,WANG Bin.Authentication models faced on social networks [J].Journal of Shenyang University of Technology,2016,38(5):545-550.)
[5] 李阳辉,谢明,易阳.基于深度学习的社交网络平台细粒度情感分析 [J].计算机应用研究,2017(3):743-747.
(LI Yang-hui,XIE Ming,YI Yang.Fine-grained sentiment analysis for social network platform basedon deeplearning model [J].Application Research of Computers,2017(3):743-747.)
[6] 刘龙飞,杨亮,张绍武.基于卷积神经网络的微博情感倾向性分析 [J].中文信息学报,2015,29(6):159-165.
(LIU Long-fei,YANG Liang,ZHANG Shao-wu.Convolutional neural networks for chinese micro-blog sentiment analysis [J].Journal of Chinese Information Processing,2015,29(6):159-165.)
[7] 刘芳,宫华,许可.基于熵权改进的TOPSIS法的认知质量评价 [J].沈阳工业大学学报,2017,39(5):540-544.
(LIU Fang,GONG Hua,XU Ke.Teaching quality evaluation for teachers based on TOPSIS method with improvement of entropy weight [J].Journal of Shenyang University of Technology,2017,39(5):540-544.)
[8] 陈小辉,张功萱.基于信息熵的符号属性精确赋权聚类方法 [J].重庆邮电大学学报(自然科学版),2014,26(6):850-855.
(CHEN Xiao-hui,ZHANG Gong-xuan.Symbol property accurate weight clustering method based on information entropy [J].Journal of Chongqing University of Posts and Telecommunications(Natural Science Edition),2014,26(6):850-855.)
[9] 黄发良,于戈,张继连.基于社交关系的微博主题情感挖掘 [J].软件学报,2017,28(3):694-707.
(HUANG Fa-liang,YU Ge,ZHANG Ji-lian.Mining topic sentiment in micro-blogging based on micro-blogger social relation [J].Journal of Software,2017,28(3):694-707).
[10]孙彬,王东.微信息舆情的主动介入导引模式 [J].沈阳工业大学学报,2016,38(5):584-589.
(SUN Bin,WANG Dong.Active intervention guidance mode of micro-message public opinion [J].Journal of Shenyang University of Technology,2016,38(5):584-589.)
[11]吴钰洁,朱福喜,周竞.基于概率图模型的文本情感分析 [J].小型微型计算机系统,2015,36(7):1421-1425.
(WU Yu-jie,ZHU Fu-xi,ZHOU Jing.Using probabilistic graphical model for text sentiment analysis [J].Journal of Chinese Computer Systems,2015,36(7):1421-1425.)
[12]李芮,王万森.融入性格的E-Learning情绪模型 [J].计算机工程与设计,2016(1):216-220.
(LI Rui.WANG Wan-sen.Emotional model merged with personality in E-Learning [J].Computer Engineering and Design,2016(1):216-220.)
[13]潘瑞林,李园沁,张洪亮.基于α信息熵的模糊粗糙属性约简方法 [J].控制与决策,2017,32(2):340-348.
(PAN Rui-lin,LI Yuan-qin,ZHANG Hong-liang.Fuzzy-rough attribute reduction algorithm based on α information entropy [J].Control and Decision,2017,32(2):340-348.)
[14]彭长根,丁红发,朱义杰.隐私保护的信息熵模型及其度量方法 [J].软件学报,2016,27(8):1891-1903.
(PENG Chang-gen,DING Hong-fa,ZHU Yi-jie.Information entropy models and privacy metrics methods for privacy protection [J].Journal of Software,2016,27(8):1891-1903.)
[15]廖军,蒋朝惠,郭春.一种基于权重属性熵的分类匿名算法 [J].计算机科学,2017,44(7):42-46.
(LIAO Jun,JIANG Chao-hui,GUO Chun.Classification anonymity algorithm based on weight attributes entropy [J].Computer Science,2017,44(7):42-46.)
