基于生成对抗网络的语音增强算法研究*
2018-06-05徐志京
柯 健,徐志京
(上海海事大学 信息工程学院,上海 201306)
0 引言
语音一直是人与人之间交流与信息共享的主要方式,为人们的日常生活带来了极大的便利。然而社会环境是一个复杂的客体,时常会伴随着各种复杂的背景噪声,对语音清晰度产生极大影响[1]。语音增强的目的主要是从带噪语音中提取纯净语音或者去除复杂的背景噪声,以提高语音清晰度和可懂度[2]。
对语音增强的研究开始于20世纪60年代,传统语音增强算法主要有维纳滤波法、谱减法、最小均方误差法、子空间法等,该类方法大多需要依赖于对噪声的估计,因此噪声估计在传统语音增强方法研究中尤为重要。传统的语音增强算法原理简单,实现容易,但是由于对噪声谱的估计不准,导致存在“音乐”噪声。维纳滤波算法虽然有效解决了该问题,使残留噪声近似于白噪声,不再是音乐噪声,输出语音听起来更加悦耳,但维纳滤波器是基于最小均方误差估计,在处理非平稳噪声信号上效果不理想,容易造成语音失真。
随着神经网络的迅速发展,越来越多的神经网络模型也被应用到语音增强算法中,为语音增强算法带来新的可能。深度神经网络的隐含层数目多,而且隐含层的传递函数是非线性函数,可以更好地提取语音信号中的结构化信息和高维信息,具有更强大的表达与建模能力,但是其泛化能力有待提升。传统的语音增强算法中认为人耳对于相位并不敏感,故忽略了相位在语音增强中的作用性,然而2013年Martin Krawczyk等人[3]研究表明相位在提高语音质量上同样具有重要作用。因此,本文提出一种端到端的语音增强方法,采用生成对抗网络(Generative Adversarial Network,GAN),无需提取复杂的语音特征,保留原始特征,进一步有效提高语音质量。
1 维纳滤波算法
维纳滤波算法是基于最小均方误差估计的线性滤波算法[4],假设输入为平稳随机过程,且它的统计特性已知,求解维纳-霍夫方程即可得到最佳滤波器的冲击响应。
图1为维纳滤波语音增强在时域上的算法图,输入含噪声信号为:
y(t)=x(t)+n(t)
(1)
其中x(t)为纯净语音信号,n(t)为加性噪声信号,对式(1)进行傅里叶变换得到:
Y(t,k)=X(t,k)+N(t,k)
(2)
式(2)为第t帧、第k频谱上的输入信号频域表示。输入信号经过谱估计器h(t)得到增强信号s(t),其估计过程如下:
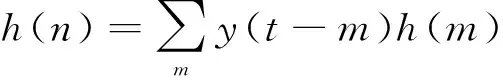
(3)
e(t)=x(t)-s(t)
(4)
E[e2(t)]=E[(x(t)-s(t))2]
(5)
其中,式(4)表示输出信号与预期信号之间的误差,式(5)为该误差的均方估计,对其进行求导,可获得滤波系统h的最优均方误差,得出维纳增益为:
(6)
其中ξ(t,k)表示先验信噪比。
S(t,k)=H(t,k)·Y(t,k)
(7)
式(7)通过H(t,k)与Y(t,k)相乘得到增强语音信号的频谱估计,再利用傅里叶反变换即可得到增强语音信号时域波形。

图1 维纳滤波语音增强时域算法图
2 生成对抗网络算法
生成对抗网络启发自博弈论中的二人零和博弈,由GOODFELLOW I J于2014年提出[5],此后在图像生成方面成绩显著,并在图像处理、语音识别和自然语言处理等领域中有着广泛应用。生成对抗网络是一种生成式模型,学习服从某种分布Z的样本z映射为服从另一种分布X的样本x,其博弈双方为生成模型(generative model)和判别模型(discriminative model),学习的过程就是两者相互对抗的过程,对抗的最终目标是获得纳什均衡,即生成器生成近似真实样本分布,判别器无法辨出真假。
图2为生成对抗网络算法框图,定义输入的随机噪声z服从Pz(z)分布(高斯分布、均匀分布等),生成模型G是一个多层感知机,用来捕捉样本数据的分布,输出G(z)表示生成模型的生成样本,训练目标是生成近似于真实样本的假样本,其损失函数表示为:
log(1-D(G(z)))
(8)
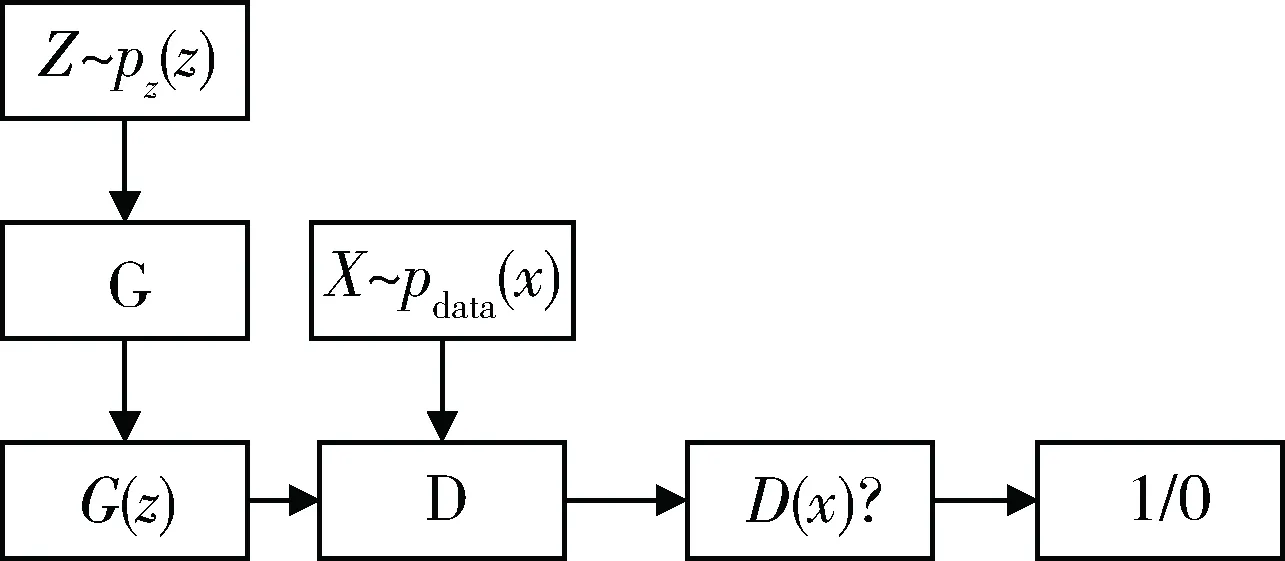
图2 GAN算法框图
在生成模型后再接上一个多层感知机,作为判别模型D,它可以看作是一个二分类器,输入为来自生成模型的假样本G(z)和真实样本x,输出为D(x)。D(x)表示判断真假样本的概率,其目标是揪出G模型生成的假样本,并判别输出结果D(G(z))概率为0,对于真实样本,判别输出结果D(x)概率为1。其损失函数表示为:
-(log(D(x))+log(1-D(G(z))))
(9)
两者在训练过程中性能不断得到优化,判别模型D的判别能力越来越强,生成模型G的生成样本愈加真实,该网络的代价函数表示为:
Ez~p(z)[log(1-D(G(z)))]
(10)
当最终D(G(z))=0.5时,即判别模型无法对输入数据做出判决,可以认为生成模型模拟出了近似于真实样本的分布。
3 基于GAN的语音增强算法
本文通过设置对抗网络来进行语音增强,输入原始语音信号,输出增强语音信号。生成模型G结构设置为全卷积神经网络(Fully Convolutional Networks, FCN),全卷积神经网络由卷积神经网络发展而来,与经典卷积神经不同,全卷积神经网络取消了最后一层用于得到固定长度的特征向量进行分类的全连接层,转而采用偏置卷积对最后一个卷积层的特征图进行上采样,使它恢复到原始输入尺寸,因此全卷积神经网络可以接受任意尺寸的输入。
图3为全卷积神经网络结构图,在卷积阶段,输入信号通过多个卷积层和池化层被降维压缩,每N步就会得到一个卷积结果,并且每层使用校正线性单元(The Rectified Linear Unit, ReLU)[6]作为激活函数,之所以选择该激活函数是因为在反向传播过程中,ReLU减轻了语音训练过程中梯度弥散。图4为生成模型G的训练结构图,生成模型G的网络结构是一个端到端的对称结构,类似于自动编码器的编码和解码过程。本文使用16 kHz对原始语音进行上采样,经过N个滤波器得到卷积结果c,并与潜在特征向量z连接,此时目标函数可表示为:
(11)

图3 全卷积神经网络结构图

图4 生成模型G的训练结构图
为了稳定训练并提高G中生成的样本的质量,本文使用改进的生成对抗网络,将目标函数的交叉熵损失函数用最小二乘代替,则生成模型G损失函数表示如下:

(12)
同时为减小误差损失,本文采用L2范数防止训练出现过拟合,提升网络的泛化能力,生成模型G的损失函数更新如下:
(13)
偏置卷积过程为卷积过程的逆过程,包括上采样和跳跃连接结构[7]。传统的池化会缩小样本尺寸,使一些细节信息丢失,通过上采样恢复原始尺寸,可以保留更详细的信息。跳跃连接结构用来优化输出,保证输出结果更加精细。
4 实验设置
4.1 数据集设置
所有的实验都是基于TIMIT语音数据集构建的[8],本文使用了320条纯净语音数据集,其中男女生语音各一半;噪声数据集来自加性噪声和9种来自Aurora2(Pearce et al.,2000)[9]的噪声数据集,其中每种噪声信噪比分为15 db,10 db,5 db,0 db,-5 db 5个等级。在训练集中将280条纯净语音数据与各种类型噪声数据相加来构建多种条件的训练语音数据集。在测试集中,选取另5种噪声数据集与40条纯净语音数据相加来构建不同条件的测试集。
4.2 实验设置
本文所有的语音信号均采用16 kHz下采样,相应帧长设置为1 s,帧移为500 ms,采样点数为16 384,在训练和测试过程中均使用预加重系数a为0.95的预加重滤波器对输入语音进行预处理。
在训练阶段,本文的训练样本由两部分组成,如图5所示,第一部分是判别模型D的输入为噪声信号和纯净语音信号的合成,输出标记为1,第二部分判别模型D的输入为生成模型G生成的增强语音信号,输出是假样本并标记为0。本文设置训练模型学习率(learning rate, lr)为0.000 2,批尺寸(batch-size)为150,训练周期为150次。

图5 基于生成对抗网络语音增强结构图
生成模型G网络结构的卷积部分由11个卷积层构成,步长为2,输入服从N(0,1)的标准正态分布作为随机噪声z,维度和深度均为256,特征图的个数随着滤波器个数的增加而增加,每层卷积特征图数增加一倍,样本数减小一倍。如前所述,反卷积阶段与卷积过程相反,参数相同。
判别模型D的网络结构与生成模型G的卷积阶段结构类似,是一个二分类卷积神经网络,判别模型D有两个输入为16 384×1维的通道,每层卷积层使用参数α为0.3的Leaky-ReLU非线性激活函数。
4.3 实验结果
语音增强的评价标准主要分为主观评价和客观评价。本文采用的是客观评价法,客观评价是目前使用比较广泛的一种方法,本文选取分段信噪比(Segmental SNR,SSNR)和语音质量听觉评估(Perceptual Evaluation of Speech Quality, PESQ)两种方法对模型进行评估。分段信噪比(SSNR)计算公式如(14)所示:
SSNR=
(14)
其中,l(l=0,1,…,L)表示帧号,L为总的帧数,N为窗长。分段信噪比(SSNR)越大,语音质量越高[10]。
语音质量听觉评估(PESQ)是语音质量评价中的一种典型算法,受到广泛使用,与主观评价相似度较高[11],其采用的是线性评分制度,数值在-0.5~4.5之间,表示输入测试语音与输出语音相比语音质量的高低,分数越高,语音质量越好。
本文选取5种不同类型的噪声数据集与40条纯净语音数据相加构建不同条件的测试集对该生成对抗网络进行评估。对测试集的处理与输入模型中的方法相同,用测试集验证方法的准确性。表1为客观评价结果,其中,Noisy表示原始语音信号,Winner表示使用维纳滤波算法的语音增强信号,Gan表示使用生成对抗网络算法的语音增强信号。为便于分析,将本文算法与传统方法中的维纳滤波语音增强方法相比较,从表1可以看出,生成对抗网络的PESQ分数相比较于传统的维纳滤波算法略高0.97%,而在分段信噪比上生成对抗网络要比维纳滤波算法高15.91%,实验表明使用生成对抗网络进行语音增强可懂度略微提高,语音信号的清晰度较好,进一步验证了本文提出方法的可行性和有效性。
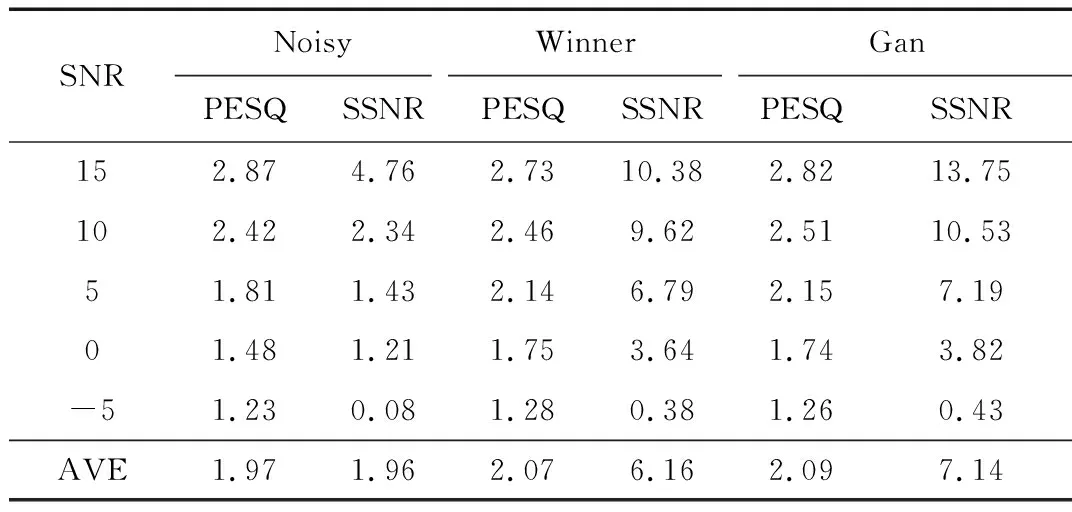
表1 客观评价结果
5 结论
本文以一种新的方法实现了语音增强,不同于传统的基于谱估计算法和深度神经网络算法,本文采用一种端到端的语音增强算法,利用对抗方式生成增强语音信号,保留原始语音信号时域上的相位细节信息,对生成对抗网络在语音增强领域做了初步探索。通过实验表明,该方法不仅可行,并可以有效替代传统流行方法,得到更好的增强性能。
由于本文采用生成对抗网络模型,在训练过程中存在一些新的问题。首先,在对数据集的选取上,噪声类型不够全面,语音数量较少,以后可以进一步扩大数据库,进行相应的研究。其次,未来在对生成对抗网络结构优化上还需进一步研究。
[1] LOIZOU P C. Speech Enhancement:theory and pratice (2nd ed)[M]. Boca Raton, FL, USA:CRC Press, Inc., 2013.
[2] YANG L P, FU Q J. Spectral subtraction-based speech enhancement for coghlear implant patients in background noise[J]. Journal of the Acoustical Society of America, 2005, 117(3): 1001-1004.
[3] PALIWAL K, WJCICKI K, SHANNON B, The importance of phase in speech enhancement[J]. Speech Communication, 2011, 53(4):465-494.
[4] LIM J S, OPPENHEIM A V. Enhancement and bandwidth compression of noisy speech[J]. Proceedings of the IEEE, 1978, 67(12):1586-1604.
[5] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. Advances in Neural Information Processing Systems(NIPS), 2014: 2672-2680.
[6] HE K, ZHANG X, REN S,et al. Delving deep into rectifiers: surpassing human-level performance on imagenet classification[J]. Proceedings of the IEEE International Conference on Computer Vision(ICCV), 2015: 1026-1034.
[7] RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv preprint arXiv:1511.06434, 2015.
[8] GAROFOLO J S. Getting started with the DARPA TIMIT CD-ROM: an acoutic phonetic continuous speech database[J]. National Institute of Standards and Technology(NIST), Gaithersburgh, MD, 1988, 107: 16.
[9] PEARCE D, HIRSCH H G. The aurora experimental framework for the performance evaluation of speech recognition systems under noisy confitions[C]//Proceedings of the 6th International Conference on Spoken Language Processing, 2000:29-32.
[10] DELLER J R, HANSEN J H L. Discrete-time processing of speech signals (2nd ed)[M]. New York: IEEE Press, 2000.
[11] RIX A W, BEERENDS J G, HOLLIER M P, et al. Perceptual evaluation of speech quality(PESQ)-a new method for speech quality assessment of telephone networks and codecs[C]//ICASSP. IEEE Computer Society, 2001:749-752.
