基于SVM算法的工业防火墙规则自学习方法*
2018-06-05王世伟
潘 峰,王世伟,薛 萍
(1.茅台学院,贵州 遵义 564507;2. 太原科技大学,山西 太原 030024)
0 引言
在“中国制造2025”和“互联网+”行动推进过程中,制造业与互联网融合发展不断加快,工业控制系统不再是物理环境上隔离的封闭系统,而是与互联网紧密相连,因此遭受网络攻击的隐患不断增加。
工业防火墙是专门为保护工业控制网络安全而设计的。它结合工业控制网络的特点,状态有限且行为稳定规律,在网络防火墙功能基础上增加工业协议深度过滤模块进行防护[1]。过滤模块中的核心部分就是基于白名单策略的规则表。工业防火墙过滤规则的配置深入协议内部,配置较复杂,人为配置规则在效率和准确率上差异大,将很大影响工业防火墙性能[2],所以研究自学习生成过滤规则的方法是十分必要的。
文献[3]中Byoung-Koo Kim等设计了工业防火墙系统,其中的访问控制过滤器是采用基于白名单策略的过滤规则进行访问控制,阻止未被识别的访问流量进入控制网络。文献[4]提出的算法不仅可以自学习生成白名单规则而且准确率达到人工设置水平。由于生成的规则表是五元组信息组成的,不能在应用层对工业协议内部数据进行深度检查。本文提出基于SVM的工业防火墙规则自学习方法,对工控网络数据流深入工业协议内部解析提取针对本工控网络的行为特征,然后分析工控数据特点,通过对样本数据和SVM模型参数进行优化,利用生成的识别模型识别出正常数据流并按一定模式自动加入规则表。
1 工业防火墙系统结构
工业防火墙是在通用防火墙模块基础上在应用层访问控制中增加工业协议深度过滤模块,如图1所示。通用防火墙模块阻止系统被非法访问,防止病毒、恶意代码等肆意传播。工业协议过滤模块对工业协议识别和过滤,阻止非法指令通过工控设备。
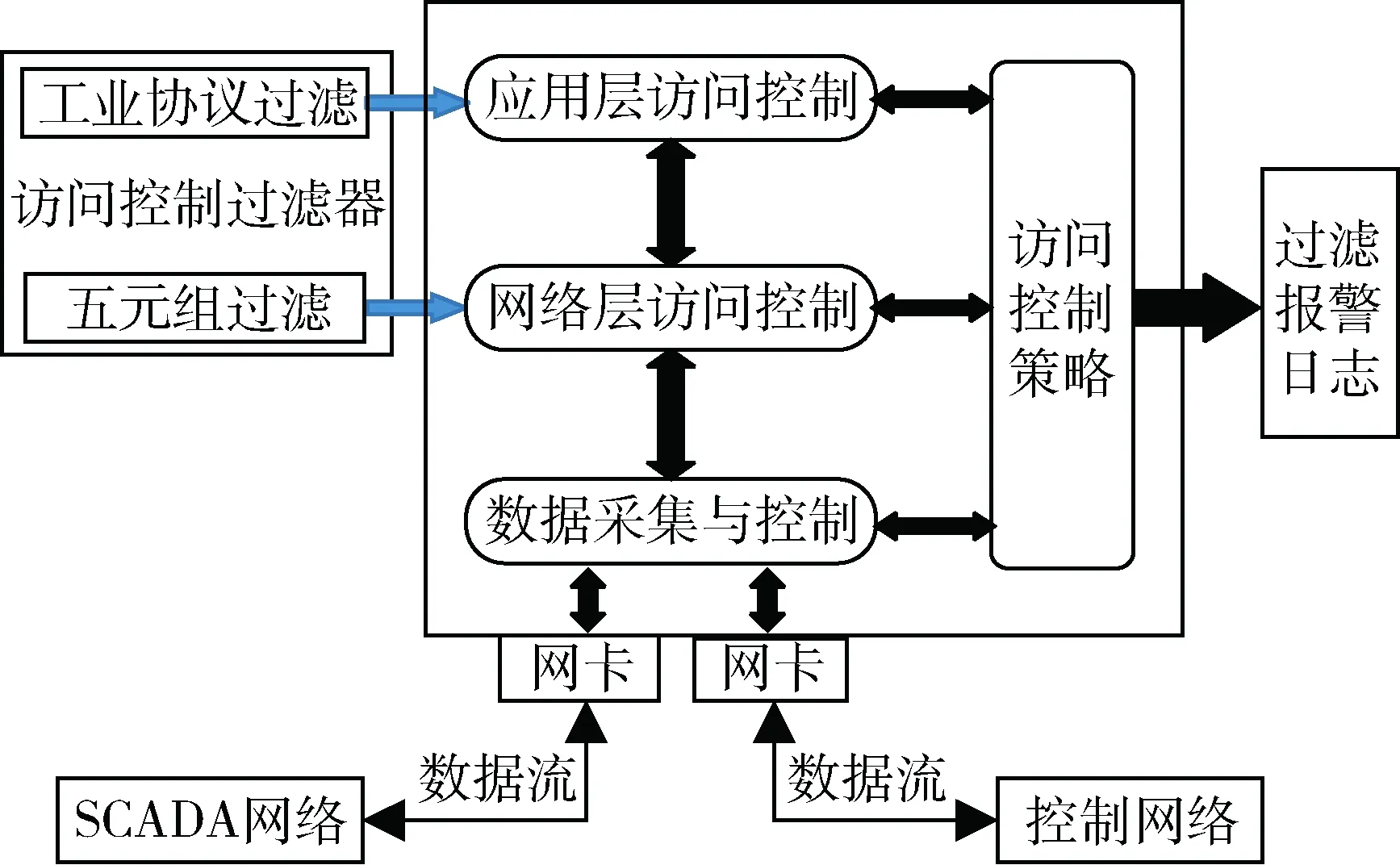
图1 工业防火墙系统结构
工业协议过滤模块采用白名单策略,对工控网络数据的正常行为进行分析,总结其具有的特征,并将这些特征用防火墙规则形式描述,创建只允许合法数据通过的过滤规则表。在过滤时将数据包与规则表内的规则进行匹配,如果与其中的某一条吻合,则被认为是合法数据允许通过[5]。
本文通过设计规则,自学习模块使用机器学习算法自动学习工控网络数据流的行为规律并生成白名单规则表,避免了人工配置规则的复杂性,提高防火墙效率和性能。
2 SVM算法简介
支持向量机(Support Vector Machine, SVM)是一种有效的分类算法,通过核函数将原始特征空间中的非线性分类界面映射到更高维的特征空间中,使分类界面在高维特征空间中变得线性可分,从而获得良好的分类效果[6]。
在工控网络中主要是将正常数据流和异常数据流两类进行分类。以两类训练样本集为例,设给定的训练样本集为{(x1,y1),(x2,y2), …,(xn,yn)},yi∈{+1,-1},i=1,2, …,n代表样本类别。构造代价函数使其最小化得到:
(1)
约束条件为:
yi(wTxi+b)≥1-ξi
ξi≥0,i=1,2,…,n
(2)
判决函数:
f(x)=(w·x)+b
(3)
其中,ξi是松弛变量,表示训练样本的错分程度;C是惩罚常数,控制对错分样本的惩罚程度;w和b分别为判决函数的权向量和阈值。利用核函数映射到更高维计算求得判别函数为:
(4)
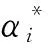
根据所求得的判别函数f(x),将待检测的数据经特征提取得到的特征向量x输入判别函数,根据输出结果判别,若输出为1,则认为数据正常,将其按一定模式加入规则表;若输出为-1,则认为是异常数据。
通过对工控网络数据流分析,发现正常数据流数量远大于异常数据流数量,两类具有明显的不均衡特征。利用标准的SVM算法对不均衡数据集进行分类时,少数类样本的分类精度是非常低的。因此,当对少数类即异常数据进行判别时,出现错分的几率会很高,就会将异常数据误判为正常数据加入规则集中。这种错分后果将是严重的,工业防火墙性能将大大降低。
本文结合工控网络特点采用过抽样法,设计了生成工控异常数据的方法,合理增加少数类样本数据改善工控数据不均衡性,并且利用改进的网格搜索法对影响判别模型本身的参数C及核函数参数寻优,综合优化使识别模型整体性能有较大提高。
3 规则自学习方法
基于SVM的工业防火墙规则自学习方法,如图2所示。规则自学习方法主要分为三个部分:工控数据特征提取、优化生成判别模型、检测生成过滤规则。
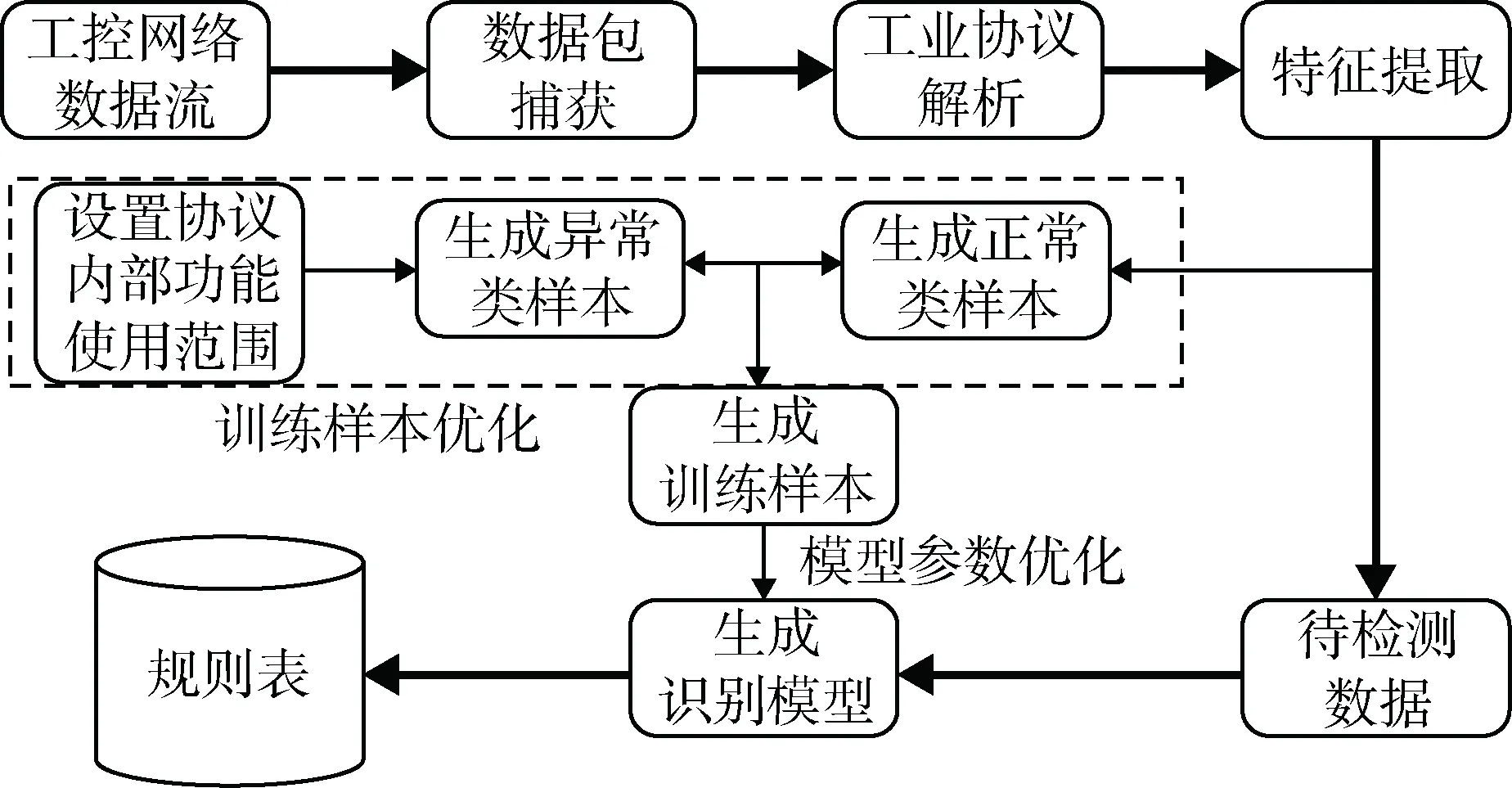
图2 基于SVM的规则自学习方法流程图
3.1 工控数据特征提取
在SCADA后台与控制网络之间使用抓包工具捕获工控网络数据流,然后利用工业协议解析工具对其进行深度解析,提取代表原数据包的特征属性。在对特征属性进行选择时,属性选择越多,能代表原数据包的信息就越全面,然而每增加一种属性就会在样本数据中增加一个维度。SVM算法因其特点虽不会出现维数灾难,但计算量也会相应增大。因此,在提取数据的特征属性时,对不同类型数据进行分类提取,将每一类可以描述其行为特性的代表属性按一定格式生成SVM算法可识别文本[7],完成训练样本集中正常类数据的收集。
3.2 优化生成判别模型
识别模型是对样本数据的行为特征属性进行训练生成的,用来检测数据流是否符合正常数据流的行为特征。因此如何生成准确率高的识别模型将是规则自学习方法的关键。在用SVM算法生成识别模型过程中,将影响模型的两个重要部分进行优化。
一是在样本层面对具有明显不均衡特征的工控数据集进行改善。本文通过分析工控网络中的攻击行为,设计生成工控异常数据的方法,如图3所示。设定本PLC已使用的功能码和地址列表,将已用功能码和地址列表之外的有效功能码和地址列表列出,通过对列出的功能码和地址进行合成生成异常类数据样本集。生成的异常类数据可分为三类:功能码正确地址错误、功能码错误地址正确、功能码和地址均错误。从而改善训练样本中多数类与少数类数据的不均衡。
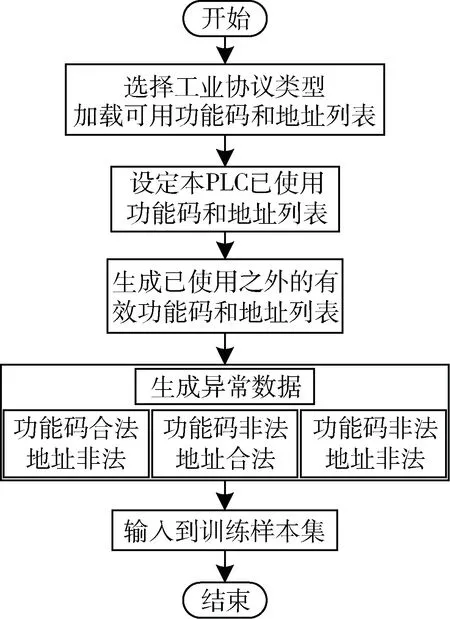
图3 生成工控异常数据流程图
二是在算法层面,对网格搜索法中的参数进行改进[8],优化SVM模型参数。对网格搜索法的搜索范围和步长进行调整,先通过大范围较长步长搜索,然后在较小范围精细寻优,搜索流程如图4所示。
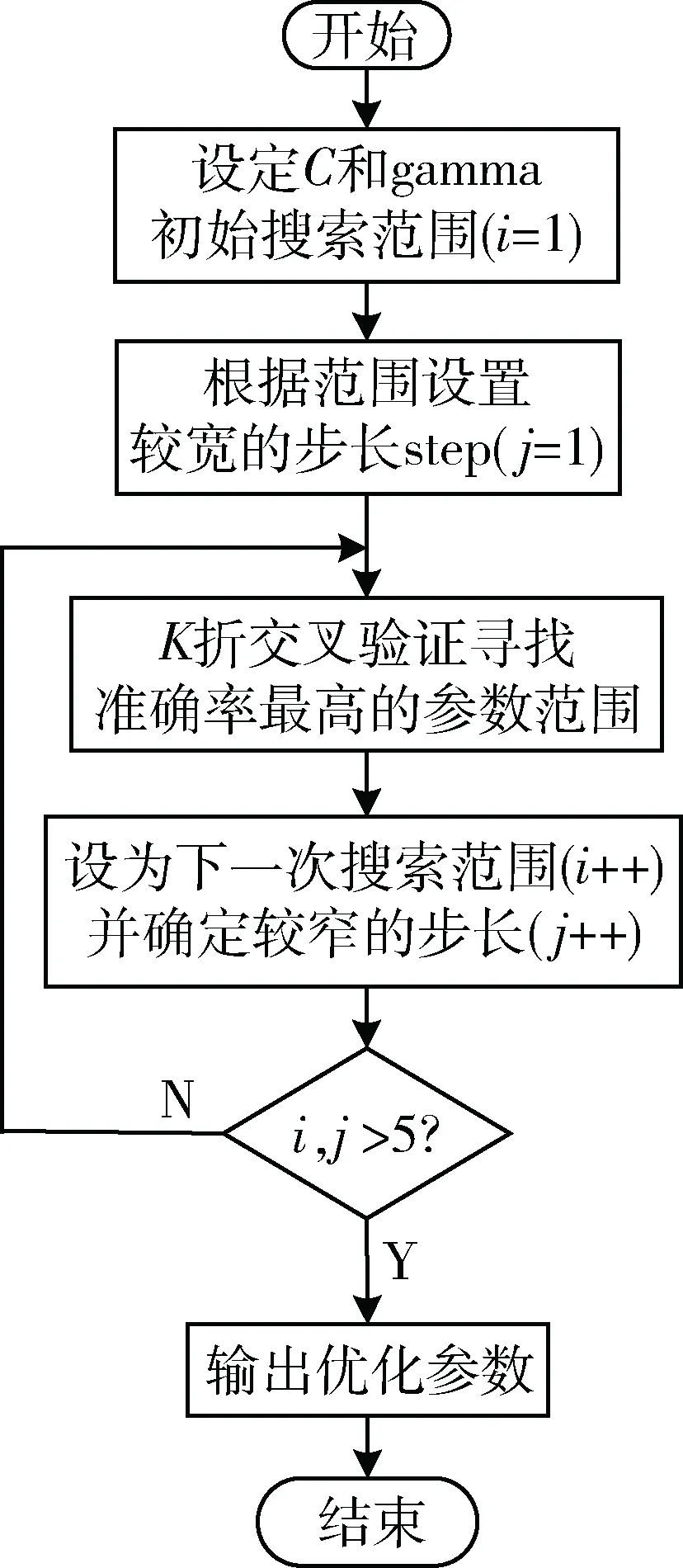
图4 改进网格搜索参数设置流程
3.3 检测生成规则
将待检测数据输入识别模型,输出为1的是正常数据流,按一定模式加入规则表中。例如,允许IP为192.168.0.10访问1号PLC,并且只能使用06功能码在4x0000地址中写入值,则规则设置如下:
[Action: Allow] [IP: 192.168.0.10->192.168.0.1] [502->3524] [Unit: 01] [FC: 06] [SA: 4x0000]
3.4 识别模型性能评价
识别模型性能评价方法采用不均衡数据下的评价标准,列出二分类问题混合矩阵如表1所示[9]。

表1 二分类问题的混合矩阵
正常类数据预测精度(Precision):TP/(TP+FN)。
异常类数据预测精度:TN/(FP+TN)。
少数类查准率(Recall):TP/(TP+FN)。
(5)
(6)
几何均值G-Mean是少数类精度与多数类精度的平方根。当两者的值都大时几何均值才大,合理地评价不均衡数据集的总体分类性能。F-Measure值可以有效评价不均衡数据集的少数类的分类性能,是查准率Precision和查全率Recall的组合,β通常取值为1。
4 仿真实验与结果分析
首先模拟真实工业生产过程搭建了一个简单的工控系统仿真实验环境,如图5所示。操作员站采用WinCC系统进行监控操作,工程师站对PLC配置编程。PLC使用S7-300,CPU为315-2 PN/DP。利用通信模块及Modbus函数库在操作员监控系统和PLC之间建立Modbus TCP通信。实验中通过工程师站对PLC配置并编程步进电机的工作程序下载到PLC内来模拟车间的一个工作程序。工业防火墙规则自学习模块布置在操作员监控系统与PLC之间,其主要由抓包工具、工业协议解析工具及SVM算法程序组成,在这里使用林智仁教授开发的LIBSVM程序[10]。
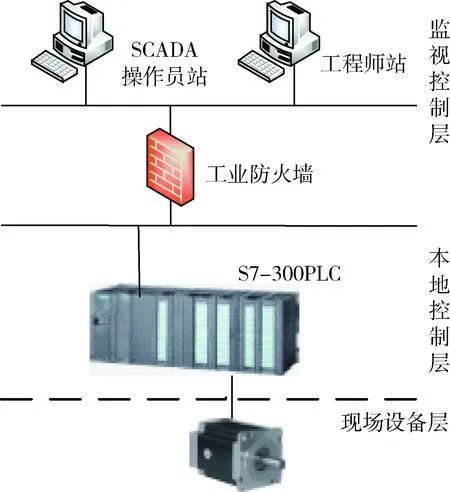
图5 工控系统仿真实验环境
运行仿真实验平台,工业防火墙自学习模块对通讯网络进行抓包、解析、提取特征生成正常类流量样本数据。通过设定本PLC使用的功能码和地址列表,利用未使用的功能码和地址与已使用的进行合成,生成异常类数据。训练样本中正常类数据为1 000个,异常类样本数据逐渐增加,比例分别为1/100,1/60,1/50,1/40,1/35,1/30,1/25,依次编号为1至7号。用于测试的样本数据中正常类与异常类数据各60个,比例为1/1。
首先对五组异常数据与正常数据比例为1/100的训练样本,在标准LIBSVM中学习、参数优化,生成的识别模型对测试数据中的正常与异常数据分别预测,结果如图6所示。
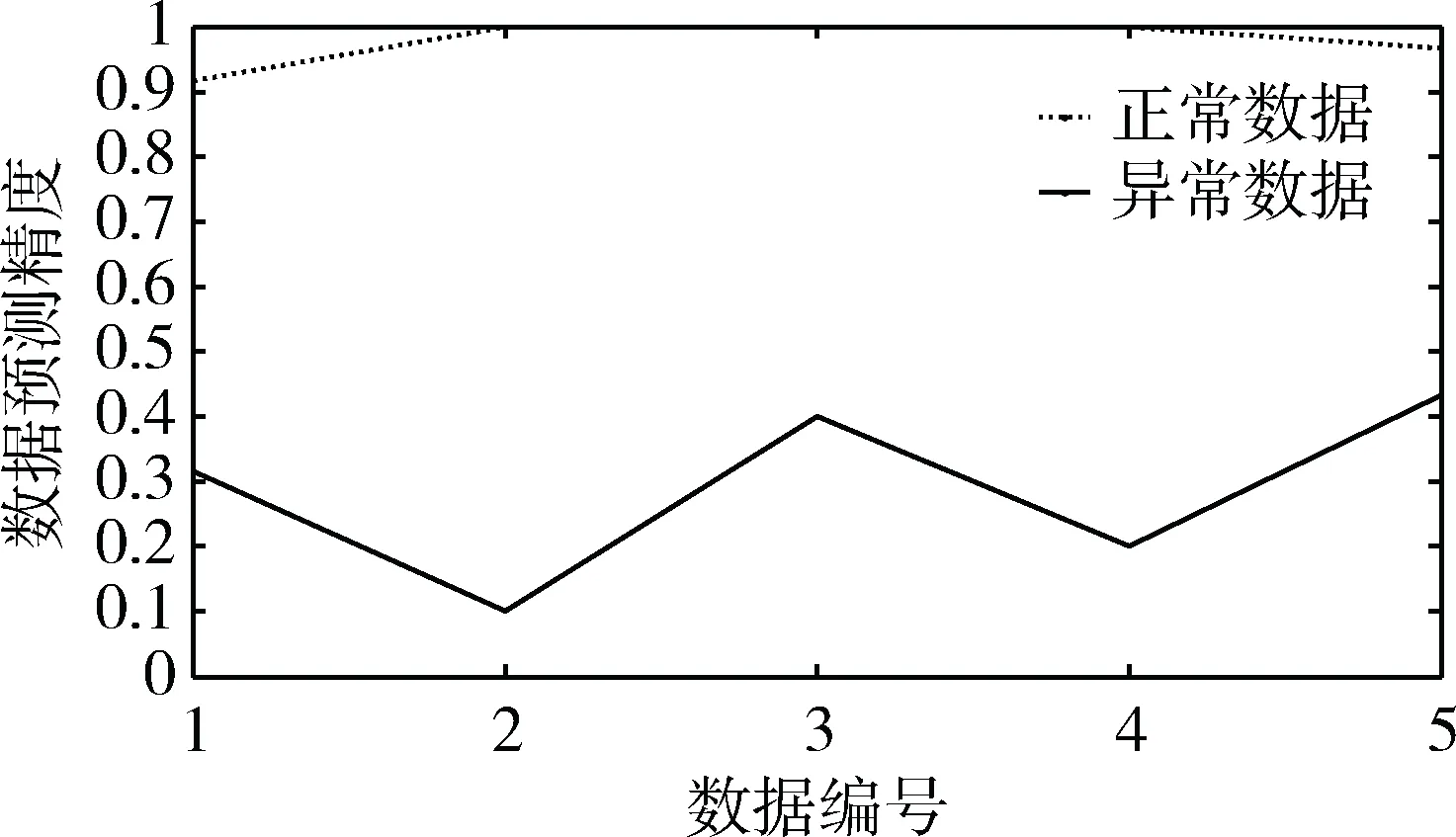
图6 不均衡数据下数据预测精度
从图6可知,在样本不均衡性较大时,对正常数据的预测精度在90%以上甚至100%,对异常数据的预测准确率在40%以下。
然后将改善的工控数据样本、LIBSVM算法程序及改进前优化参数,如表2所示,导入MATLAB仿真软件中运行,得到正常类和异常类数据预测精度,如图7所示。
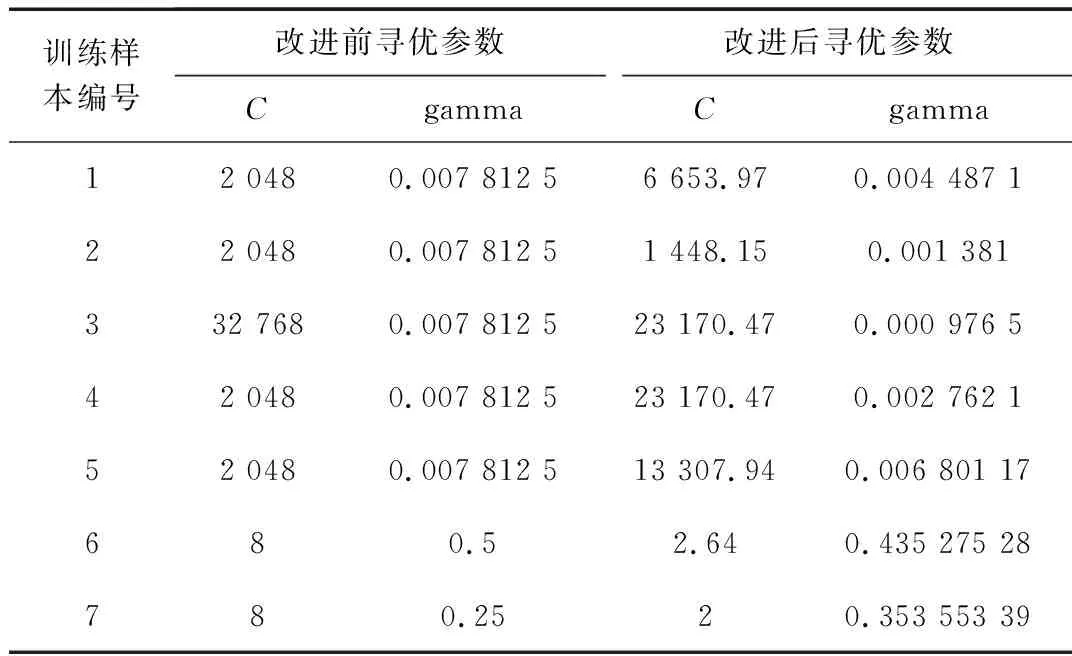
表2 各样本寻优C和gamma参数
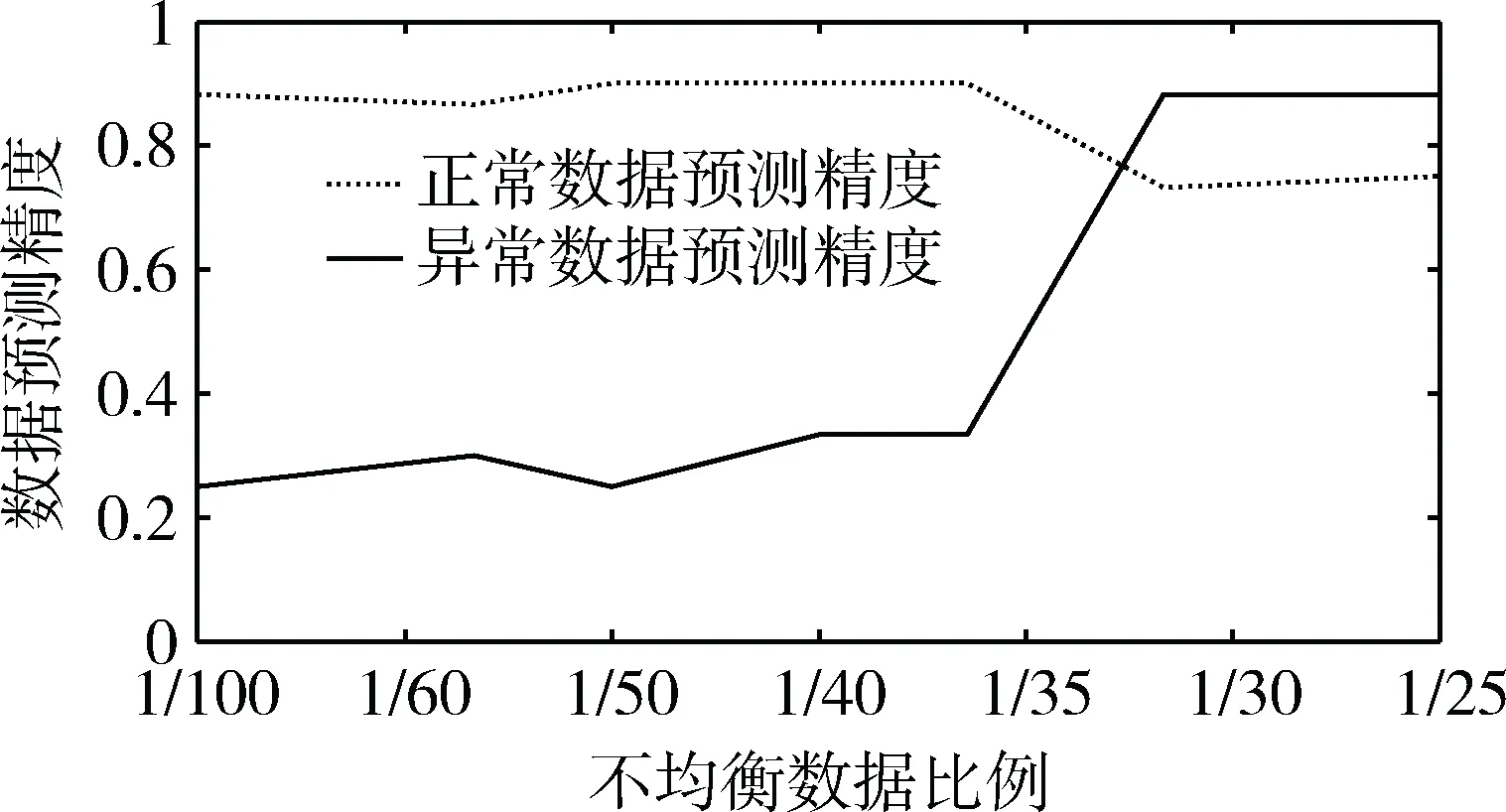
图7 不同均衡数据比例正常与异常数据预测精度
从实验结果图7看出,当正常类样本与异常类样本比例1/100时,识别模型对正常类(多数类)数据的预测精度在90%,而此时对异常类(少数类)数据预测精度在30%~40%之间。随着两类数据比例减小,识别模型对正常类数据预测精度有一定下降,在1/25时下降到78%,下降了12%;对异常数据预测精度大幅提高,在1/25时升高到88%,升高了50%。
计算参数改进前的F-Measure值和G-Mean值,如图8所示。
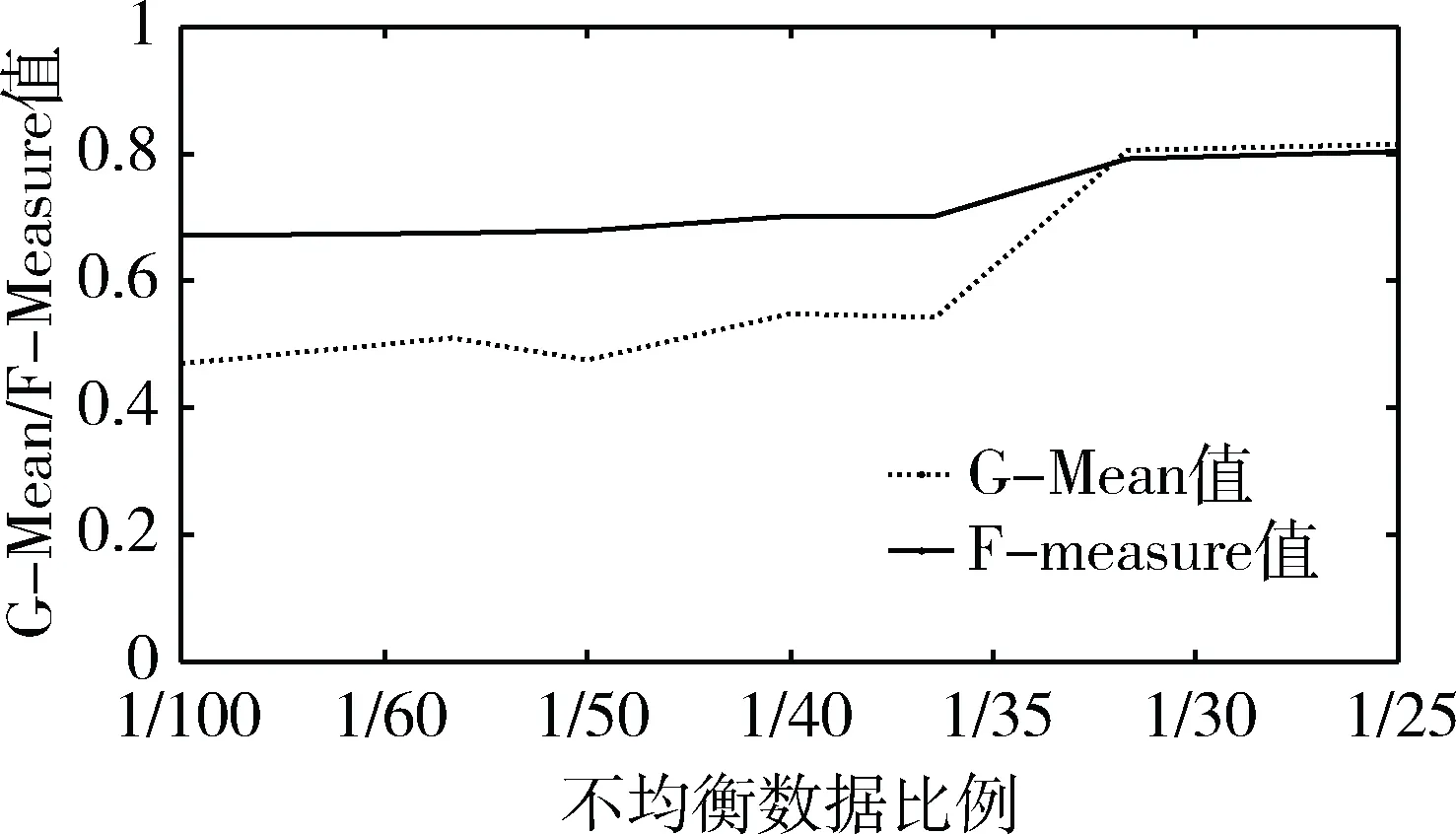
图8 不同均衡数据比例G-Mean和F-Measure值
从图8得知,在多数类和少数类比例逐渐减小时,模型整体性能G-Mean值和代表少数类预测性能的F-Measure值都有显著提高。
最后将改进网格搜索后优化的C和gamma参数导入LIBSVM,计算F-Measure值和G-Mean值与改进前对比结果如图9和图10所示。
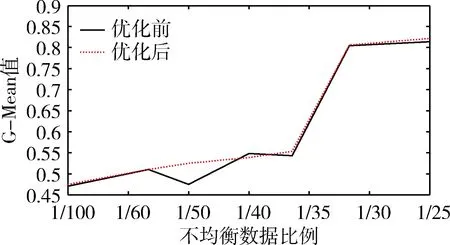
图9 模型参数优化前后G-Mean值对比
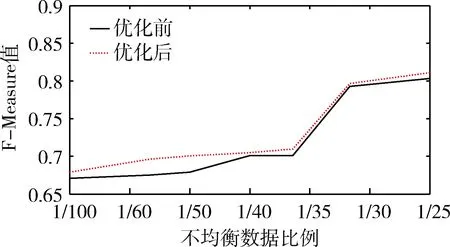
图10 模型参数优化前后F-Measure值对比
实验结果表明,在使用SVM算法对工控网络数据识别过程,通过样本层面优化对工控样本固有的不均衡性改善可以大幅提升识别模型性能,再通过对模型参数优化,识别模型可以更精确预测工控数据行为。
5 结论
针对人工配置工业防火墙规则受限制,影响工业防火墙性能。本文提出基于SVM的工业防火墙规则自学习方法对工控网络数据深入工业协议内部解析,使用过抽样方法生成异常数据优化训练样本不均衡,使用改进的网格搜索法寻优模型参数,从而使得到的识别模型对正常类与异常类数据都有高预测率,生成过滤工控行为的白名单规则表,提升工业防火墙整体性能。
[1] 尚文利,雷艳晴,万明,等. 基于哈希算法的工业防火墙规则
自学习方[J]. 计算机工程与设计,2016,37(3):613-617.
[2] 尚文利,乔全胜,万明,等. 工业防火墙规则生成与优化的自学习方法[J]. 计算机工程与设计,2016,37(7):1752-1756.
[3] BYOUNG K K, DONG H K, JUNG C N, et al. Abnormal traffic filtering mechanism for protecting ICS networks [C]//18th International Conference on Adcanced Communication, 2016:436-440.
[4] 雷艳晴,尚文利,万明,等. 工业防火墙规则自学习算法设计[J]. 计算机工程与设计,2016,37(12):3141-3145.
[5] 程超. 工业控制网络Modbus TCP协议深度包检测技术研究与实现[D]. 成都:电子科技大学,2016.
[6] 陶新民,刘福荣,杜宝祥. 不均衡数据SVM分类算法及其应用[M]. 哈尔滨:黑龙江科学技术出版社,2011:29-30.
[7] 李琳,尚文利,姚俊,等. 工业控系统PCA-OCSVM入侵检测算法[J]. 计算机工程与设计,2016,37(11):2928-2933.
[8] 王健峰,张磊,陈国兴,等. 基于改进的网格搜索法的SVM参数优化[J]. 应用科技,2012,39(3):28-31.
[9] 陶新民,徐晶,童智靖,等. 不均衡数据下基于阴性免疫的过抽样新算法[J]. 控制与决策,2010,25(6):867-872.
[10] CHANG C C, LIN C J, LIBSVM: a library for support vector machines[C]//ACM Transactions on Intelligent Systems and Technology, 2011,2(3):1-27.
