Defining Embedding Distortion for Intra Prediction Mode-Based Video Steganography
2018-06-01QiankaiNieXubaXuBingwenFengandLeoYuZhang
Qiankai Nie, Xuba Xu, Bingwen Feng, and Leo Yu Zhang
1 Introduction
Steganography is a technique on secret communication, where a sender embeds secrets into covers, such as videos, audios, images, etc. and does not allow the others to detect the embedding event, except for the recipient. For the steganalysis, the main task is to detect whether in the carrier a secret message is hidden or not. With the rapid popularity of multimedia, compressed video has become one of the most popular carriers for information hiding. Therefore, a series of video steganographic schemes have been proposed, which also buoys the development of video steganalytic methods.
In recent years, adaptive stego-coding technique such as wet paper codes (WPCs)[Fridrich, Goljan, Lisonek et al. (2005)] and Syndrome-trellis code (STC) [Filler, Judas and Fridrich (2011)] have been presented. STC is regarded as the most effective coding method for steganography, because it separates the distortion definition and the distortion minimization. Furthermore, the recipient can extract the secret data without the knowledge about the definition. By applying these mature coding techniques, video steganography can focus on defining the distortion function. Cao et al. [Cao, Zhang, Zhao et al. (2015)] defined the distortion function by considering the motion vector (MV)’s local optimality. Wang et al. [Wang, Zhang, Cao et al. (2016)] combined motion characteristics of video content, MV’s local optimality and statistical distribution together to define the distortion function.
Video steganographic methods can be studied according to different modification such as motion vectors, quantized DCT coefficients, variable length codes and intra prediction modes (IPMs). Intra prediction mode-based video steganographic method can preserve the video quality perfectly [Bouchama, Hamami and Aliane (2012)]. The early IPMsbased approaches [Hu, Zhang and Su (2007); Xu, Wang and Wang (2012)] only modulate the intra prediction modes of qualified intra 4×4 luminance blocks for data hiding. In order to improve the embedding capacity, Yang et al. [Yang, Li, He et al.(2011)] introduced matrix coding to hiding two bits information by modifying one IPM.Bouchama et al. [Bouchama, Hamami and Aliane (2012)] increased the capacity by grouping the IPMs and modifying them within the same group. However, in these methods, non-optimal selection rules destroy the optimalities of IPMs seriously, which was easily detected by Zhao et al.’s [Zhao, Zhang, Cao et al. (2015)] IPMs calibration(IPMC) steganalytic method. Machine learning has been widely used as an effective detection method [Chang and Lin (2011); Gurusamy and Subramaniam (2017)],especially in steganalysis.
This paper proposes a video steganographic scheme by embedding message bits into intra predictions of video encoding. Inspired by the prediction mode reversion phenomenon caused by increasing the SAD value, the SAD prediction deviation (SPD) is considered in defining the distortion function. Moreover, mapping rule is introduced to expand the range of selectable modes for each block. In this way, we can preserve the optimality of IPMs is maximally preserved at a given embedding rate during the embedding process,which can effectively resist the detect by Zhao et al. [Zhao, Zhang, Cao et al. (2015)].
The rest of this paper is organized as follows. In Section 2, we describe the framework of the distortion minimization for IPMs-based steganograpy. The proposed distortion function and mapping rule are elaborated in Section 3. The practical implementation is presented in Section 4. The experimental evaluation is shown in Section 5. In the end,conclusions and future works are given in Section 6.
2 Framework of distortion minimization for steganography
The minimal-distortion steganographic schemes focuse on the definition of distortion function and the choice of cover. The following is a common framework.
In the coding process, the cover sequence is denoted by, and theis an integer, such as the mode value of an intra-block. What is more, non-negative additive distortionsare defined for each cover element in advance, whereis the i-th element in the stego vector. Assuming thatbits secret binary message e is to be embedded with the payload, STCs (Syndrome-Trellis Codes)[Filler, Judas and Fridrich (2011)] perform the embedding operation as the kernel of this framework:

s.t.
whereis the stego embeded with secret message, φ(e)is the coset corresponding to syndrome e and the overall distortion. At the extractor, the operation is simply computing.
3 Proposed approach
3.1 Mode prediction
Video compression can effectively compress a raw video into a smaller compressed one by using coding techniques, which facilitates the transmission on the network as well as storage on hardware [Wiegand, Sullivan, Bjontegaard et al. (2003)]. The compression technique mainly uses the redundancy of a video frame and the high similarity between adjacent intra-macroblocks. In this paper, intra-44 blocks (intra-4B) are used as carriers for the data embedding, while those intra-1616 blocks are not changed because they are used for coding smooth regions that are not suitable for modification. H.264, a state-ofthe-art video coding standards, contains 9 intra prediction modes based on prediction direction shown as Fig. 1.

Figure 1: Intra 44 prediction modes
Since the SAD is determined by the original pixels of the macroblock and the reconstruction pixels, choosing the mode of the minimum SAD (Sum of Absolute Difference) [Kim and Jeong (2012)] to code can minimize the bit rate and ensure the quality of video compression. The SAD of i-th intra-4B in t-th intra-frame is given by:

where B is the current intra-4B. Oi,t(x, y) respents the original value of the pixel (x, y) and Ri,t(x, y) is the reconstruction pixels associated with prediction mode.
3.2 SAD prediction deviation
Calibration-based steganalysis [Fridrich and Kodovsky (2012)] reconstructs an estimation of the cover from the stego object and draws features based on the difference between the two, which can achieve a high detection accuracy. Zhao et al. [Zhao, Zhang, Cao et al.(2015)] proposed the IPMC features based on the calibration method, which is sensitive to the non-optimal IPMs. During the intra-frame coding process, intra-4B will select the minimum SAD mode to code, so the intra-4B’s SAD will also be changed when we modify the intra-frame optimal prediction mode for the embedding target. After the calibration process, the non-optimal prediction modes will tend to restore the original optimal value, implying that the block is not coded according to the optimal prediction mode. In addition, based on the prediction mode reversion phenomenon, our study has observed the fact that different degrees of changing the prediction SAD lead to different reversal probabilities.
An example is illustrated as in Fig. 2. In order to take a look at the reversion phenomenon of modified intra-4Bs, a test sequence “Coastguard.yuv” (CIF, 352288) from video database [YUV (2008)] is used to calibrate with a customized H.264 codec named x264[x264 (2010)]. Modifying rate (MR) 0.35 and 0.5 represent modifying 35 percent and 50 percent of the total number of blocks, respectively. At the encoder, these specified original blocks are first coded with the optimal prediction mode with minimum SAD.Then, the second and third best modes are used instead of the optimal one for comparison.At the decoder, these modified blocks are reconstructed and then undergo recompression with the standard prediction method. It can be seen from Fig. 2 that a lower level mode,which yields a larger change on SAD, makes the reversion phenomenon more frequent.

Figure 2: Reversion phenomenon of (a) 0.35 modifying rate and (b) 0.5 modifying rate on different mode level
Fig. 2 indicates that the SAD change of prediction mode is a key factor to construct the distortion function. If a candidate modeis given during intra predition, the SAD prediction deviation (SPD) is formulated as

whereis the prediction SAD of the optimal modeassociated with the ith prediction block in the t-th key frame.
When steganalyzer utilizes calibration to determine whether a sequence is stego object,the SAD prediction deviation (SPD) indeed increase the probability of reversion phenomenon. Through the above analysis, the smaller SPD the reselected mode has, the more suitable it can be used for modification.
3.3 Mapping rule
We use STC as the practical steganographic method. Seeking for an appropriate pattern should traverse the entire pattern space as shown in Fig. 1 as much as possible. Thus we herein introduce a mapping rule between prediction modes and groups of modes to complete the traverse. Many state-of-the-art schemes use mapping rules to represent the secret information [Cao, Zhou and Sun (2018)], which indeed improves coding efficiency.

Table 1: Average SPD caused by replacement of optimal mode m and candidate mode m’
Since a mode will not change to those modes in the same group, we divide the modes with large SPD into the same group to reduce the probability of selecting a large distortion mode. We observe the SPD generated when the optimal modes is replaced with the other 8 candidate modes, respectively. Assuming that the total number of intra-4Bs with the optimal mode 0 is K, then the average SPD for each intra-4B is. The experimental results of three video sequences, i.e. “akiyo.yuv”, “Mobile.yuv” and“Waterfall.yuv” are shown in Tab. 1. It can be seen that 9×8=72 replacement results, in which the maximum SPD is bolded to indicate that this pair of modes is more suitable to be placed in the same group. These groups of modes can be defined as follows:
If the block uses the 4×4 prediction:
Group 1: Modes 0, 1 and 4.
Group 2: Modes 3, 5 and 8.
Group 3: Modes 2, 6 and 7.
本次数据显示,肝硬化组、肝癌组、慢性肝炎组、急性肝炎组对比参照组,肝硬化组对比肝癌组、慢性肝炎组、急性肝炎组,统计学具有数据分析意义。表示,肝硬化患者的血清胆碱酯酶活性最低,其次为肝癌。A级和C级比较、A级和B级比较、B级和C级比较,差异具有统计学意义(P<0.05)。证实肝功能Child分级和血清胆碱酯酶水平之间呈现出正相关性。
The block uses the 1616 prediction:
Group 0:Modes 0, 1, 2 and 3.
Here, the group 0 belonging to 1616 block does not make any changes. The original group gi,tcontains the original modemi,t, wheregi,t∈{0,1,2,3}. In candidate group g′i,t,the mode of the minimum SAD is stored as m'i,tand before the STC embedding is executed, each group’s m'i,tis known. At this point, we get the mapping table MT,which records the optimal mode for each group in all blocks. As shown in (Fig. 3), the modes 1, 5 and 6 are the minimum SAD modes of the groups 1, 2 and 3 in an intra-4B,respectively.

Figure 3: An example of mapping rule
From this point of rule, the SAD prediction deviation of different candidate groups(SPDG) can be denoted by

whererepresents the prediction SAD change of candidate mode in the group. Andis chosen from the candidate group setusing STCs-basedembedding.
Applying the mapping rule can effectively expand the search range because these 3 groups are handled as an input set instead of 9 prediction modes. In Section 4, we would describe the implementation of mapping rule in detail.
3.4 The definition of distortion function
As introduced in Section 2, accumulating the non-negative additive distortions introduced by independent modifications can obtain the overall embedding impact. Therefore the overall distortion sumDtof all intra-4Bs in t-th key frame should be minimized by steganographic codes, which Dtcan be calculated by following formulas.

4 Practical implementation
±1 STC is used as the practical steganographic method for the secret message embedding and extraction. In addition, both the sender and the receiver should know the mapping rule. The proposed steganographic method is divided into the following three phases.
Embedding Distortion Definition:Before embedding the data, we measure the distortion value of each intra-4B using the distortion function in key frames. Firstly, each key frame uses the mapping rule to obtain the original group matrix Gtand the mapping table. For each intra-4B, the distortionis defined in Eq.8. Secondly, save all the defined distortion in. Assuming that group 1 is suitable as a modification group, the appropriate mode m′i,twithin group 1 can be obtained by mapping table MTt.
Data Embedding:In this step, after obtaining, the original group matrixis applied inSTC for embedding to get the modified group matrix, and then the suitable mode matchingis found in the mapping table. Suppose that T is the total number of key frame in the cover sequence anddenotes the binary length of cover sequence. Then we use STC to embed anbits message e with a given embedding raterepresenting the average embedded bits per prediction mode (bppm), and make the overall embedding impact minimal:

whereis the group vector, and D is the distortion vector
After executing STC, the modified group vectoris obtained to find the appropriate modes for modifying according to the. Finally, the stego sequence can be generated by H.264 codec.
Data Extraction:For the recipient, all prediction mode values is obtained by using a customized decoder, and then the G′is reconstructed by MT easily. Now the secret messages can be extracted by using STC, which can be denoted as

where H is parity-check matrix employed by both the sender and recipient.
5 Evaluation
5.1 Experiment setup
The video database [(Yuv (2008)] containing 25 standard 4:2:0 YUV sequences in CIF format (CIF, 352×288) is used to test, as shown in Fig. 4. The number of frame ranges from 100 fps to 400 with 30 fps frame rate. The 25 standard sequences are divided into 120 subsequences without overlapping, and each subsequence contains 60 frames. In order to obtain sufficient samples, the maximum interval of the intra frame is set 10,which does not degrade the compression quality. Besides, x264 executes the embedding scheme and the LibSVM toolbox [Chang and Lin (2011)] with the polynomial kernel is employed for classiflcation. For performance comparison, Yang et al.’s [Yang, Li, He et al. (2011)] method and Bouchama et al.’s [Bouchama, Hamami and Aliane (2012)]method are also implemented.
In this experiment, two bit-rates(BR) of the compressed sequences, 0.5 Mbit/s and 1 Mbit/s, with various embedding rates(ER) ranging from 0.125 to 0.5 are considered, in which the embedding rate(ER) indicates the average embedding bit length of available intra-4Bs and it can be calculated as

where L denotes the length of the binary message embedded in the t-th frame, and theis the total number of intra-4Bs in t-th key frame.
According to the difference in the embedding rate(ER), the theoretic value of embedding capacity can be calculated as

where Inrepresents the number of intra-frames, h and w represent the height and width of the video sequence, respectively. If the embedding rate(ER) is set to 0.5 and the number of intra-frames is 20, the theoretic embedding capacity will be 63360 bits.
5.2 Steganalysis result
Steganalysis is the most important measure of the security of steganography. The recently proposed IPMC [Zhao, Zhang, Cao et al. (2015)] feature has achieved the most effective detection performance against the IPMs-based Video steganography scheme. IPMC extracts a 13-dimension feature from each intra-frame according to the recovery phenomenon of the intra prediction modes.
In our test, 80 video subsequences are randomly selected for training, and the remaining 40 video subsequences are used for classification. The experiment was repeated 10 times to calculate the average detection performance evaluated by the minimum average classification error probability [Kodovsky, Fridrich and Holub (2012)]. Three different steganographic schemes are shown in Fig. 5 and Tab. 2. All schemes have a slightly worse performance at bit-rate 1.0 Mbit/s than at 0.5 Mbit/s, because higher bitrate leads to lower loss and the greater difference between the stego and the cover. In addition, our method is much better than Yang et al.’s method [Yang, Li, He et al. (2011)]and Bouchama et al.’s [Bouchama, Hamami and Aliane (2012)] method at low embedding rates. As the embedding rate increases, the performance gap becomes smaller,but our method is still best, which indicates higher steganographic security level.
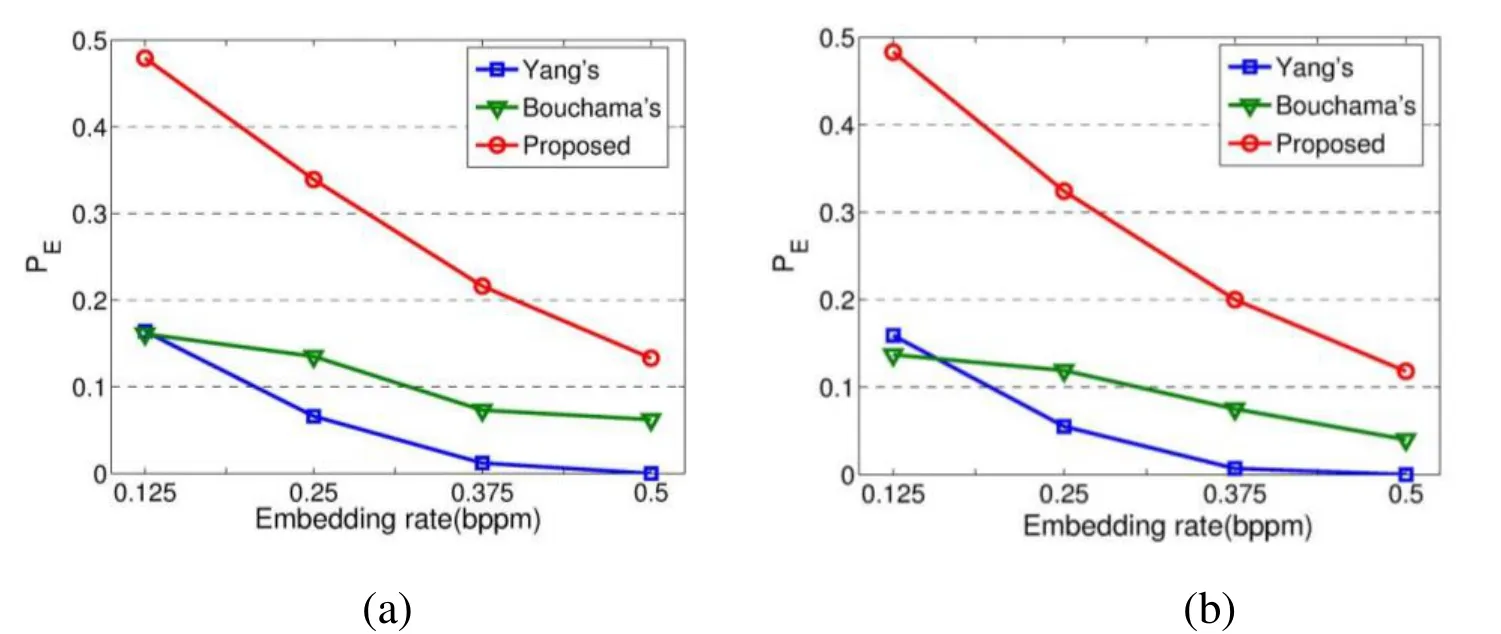
Figure 5: Reversion phenomenon in case of (a) BR=0.5 Mbit/s and (b) BR=1.0 Mbit/s on different mode levels

Table 2: Comparison of different method against IPMC features
5.3 Steganalysis result
The measurement PSNR (dB) is commonly adopted to measure video quality in steganographic scheme. Here, the video quality results of the three video sequences“Coastguard.yuv”, “Mobile.yuv” and “Waterfall.yuv” are shown in Tab. 3 where NO-E(no-embedding) represent the compression without any data embedding. It is observed that our method does not lead to great errors and is closer to the PSNR of NO-E than Yang et al.’s [Yang, Li, He et al. (2011)] methods and Bouchama et al.’s [Bouchama,Hamami and Aliane (2012)] methods. Because our scheme is based on the choice of the smallest SAD block to be embedded, which ensures that the embedded perturbation is slight. Referring to NO-E, we can see that the impact of these three embedding schemes on video quality is slight, with the least impact being our methods.

Table 3: Comparison of PSNR values (dB) using four steganographic schemes at two bit-rates(Mbit/s)
6 Conclusion
In this paper, we present a novel intra prediction mode-based video steganography by minimizing the embedding distortion defined according to SAD. We introduce STC as the practical embedding method, and SAD can be regarded as an important factor to establish the distortion function. Then, we introduce the mapping rule to expand the range of selective modes for each block. The experimental results show that our proposed steganographic scheme outperforms other intra prediction mode-based steganographic schemes in resisting steganalysis and video quality.
In the future work, we will combine SAD and the statistical distribution of frame to construct more effective distortion functions. In addition, the mapping rule is also to be improved to further increase the range of selection. For video steganography, we have to further reduce the computational complexity to accommodate the fast growing of video data.
Acknowledgements:This work was supported by National Key R&D Plan of China(Grant No. 2017YFB0802203), National Natural Science Foundation of China (Grant No.U173620045, 61732021, 61472165 and 61373158), Natural Science Foundation of Guangdong Province, China (Grant No. 2017A030313390), Science and Technology Program of Guangzhou, China (Grant No. 201804010428), Guangdong Provincial Engineering Technology Research Center on Network Security Detection and Defence(Grant No. 2014B090904067), Guangdong Provincial Special Funds for Applied Technology Research and Development and Transformation of Important Scientific and Technological Achieve (Grant No. 2016B010124009), the Zhuhai Top Discipline-Information Security, Guangzhou Key Laboratory of Data Security and Privacy Preserving, Guangdong Key Laboratory of Data Security and Privacy Preserving, the Fundamental Research Funds for the Central Universities.
Bouchama, S.; Hamami, L.; Aliane, H.(2012): H.264/avc data hiding based on intra prediction modes for real-time applications. Lecture Notes in Engineering and ComputerScience, vol. 1.
Cao, Y.; Zhang, H.; Zhao, X.; Yu, H.(2015): Video steganography based on optimized motion estimation perturbation. ACM Workshop on Information Hiding and Multimedia Security, pp. 25-31.
Cao, Y.; Zhou, Z.; Sun, X.(2018): Coverless information hiding based on the molecular structure images of material. Computers, Materials & Continua, vol. 54, no. 2, pp. 197- 207.Chang, C. C.; Lin, C. J.(2011): Libsvm: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, vol. 2, no. 3, pp. 1-27.
Filler, T.; Judas, J.; Fridrich, J.(2011): Minimizing additive distortion in steganography using syndrome-trellis codes. IEEE Transactions on Information Forensics and Security, vol.6, no. 3, pp. 920-935.
Fridrich, J.; Goljan, M.; Lisonek, P.; Soukal, D.(2005): Writing on wet paper. IEEE Transactions on Signal Processing, vol. 53, no. 10, pp. 3923-3935.
Fridrich, J.; Kodovsky, J.(2012): Rich models for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, vol. 7, no. 3, pp. 868-882.
Gurusamy, R.; Subramaniam, V.(2017): A machine learning approach for mri brain tumor classification. Computers, Materials & Continua, vol. 53, no. 2, pp. 91-109.
Hu, Y.; Zhang, C.; Su, Y.(2007): Information hiding based on intra prediction modes for h.264/avc. IEEE International Conference on Multimedia and Expo, pp. 1231-1234.
Kim, J.; Jeong, J.(2012): Fast intra mode decision algorithm using the sum of absolute transformed differences. International Conference on Digital Image Computing Techniques and Applications, pp. 655-659.
Kodovsky, J.; Fridrich, J.; Holub, V.(2012): Ensemble classifiers for steganalysis of digital media. IEEE Transactions on Information Forensics and Security, vol. 7, no. 2, pp.432-444.
Wang, P.; Zhang, H.; Cao, Y.; Zhao, X.(2016): A novel embedding distortion for motion vector-based steganography considering motion characteristic, local optimality and statistical distribution. ACM Workshop on Information Hiding and Multimedia Security,pp.127-137.
Wiegand, T.; Sullivan, G. J.; Bjontegaard, G.; Luthra, A.(2003): Overview of the h.264/avc video coding standard. IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 7, pp. 560-576.
x264(2010): Videolan. x264. http://www.videolan.org/ developers/x264.html.
Xu, D.; Wang, R.; Wang, J.(2012): Prediction mode modulated data-hiding algorithm for h.264/avc. Journal of Real-Time Image Processing, vol. 7, no. 4, pp. 205-214.
Yang, G.; Li, J.; He, Y.; Kang, Z.(2011): An information hiding algorithm based on intra-prediction modes and matrix coding for h.264/avc video stream. International Journal of Electronics and Communications, vol. 65, no. 4, pp. 331-337.
YUV(2008): Yuv video sequences. http://trace.eas.asu.edu/ yuv/index.html.
Zhao, Y.; Zhang, H.; Cao, Y.; Wang, P.; Zhao, X.(2015): Video steganalysis based on intra prediction mode calibration. 2015 International Workshop on Digital-forensics and Watermarking.
猜你喜欢
杂志排行

Computers Materials&Continua的其它文章
- A Fusion Steganographic Algorithm Based on Faster R-CNN
- Securing Display Path for Security-Sensitive Applications on Mobile Devices
- Verifiable Diversity Ranking Search Over Encrypted Outsourced Data
- Localization Algorithm of Indoor Wi-Fi Access Points Based on Signal Strength Relative Relationship and Region Division
- An Abnormal Network Flow Feature Sequence Prediction Approach for DDoS Attacks Detection in Big Data Environment
- Adversarial Learning for Distant Supervised Relation Extraction