基于修改日志克隆代码跟踪及演化模式识别
2018-06-01葛广帅刘东升张丽萍包萨仁娜
葛广帅,刘东升,张丽萍,侯 敏,包萨仁娜
GE Guangshuai,LIU Dongsheng,ZHANG Liping,HOU Min,BAO Sarenna
内蒙古师范大学 计算机与信息工程学院,呼和浩特 010022
College of Computer and Information Engineering,Inner Mongolia Normal University,Hohhot 010022,China
1 引言
为了使软件更具竞争力,在软件初始版本完成之后,仍然需要新功能扩充、问题修复等后期维护活动。有研究表明[1],软件维护约占软件总劳动成本的80%左右。
软件的维护成本受多种因素影响,其中一个重要因素就是克隆代码。在软件开发维护过程中,开发人员为了提高开发速度、节约时间成本,经常使用“复制-粘贴-修改”操作,导致系统中产生大量的克隆代码。此外,由于设计模式、相似API等的使用,也会产生克隆代码。有研究表明[2],克隆代码在软件系统中普遍存在,并且占据了相当大的比例。
克隆代码在软件开发维护方面具有双重影响。一方面,有些克隆代码是有益的,例如某代码片段经过测试无任何缺陷,那么复用该代码片段可以节省开发时间,避免未知风险[3]。另一方面,有些克隆代码是有害的,例如复用了未经测试的代码片段,可能使得潜在的缺陷大量繁殖,并且开发人员对一段克隆代码修改时也必须对相关的克隆代码进行相应修改,增加了维护成本[4]。
为了更好地进行克隆代码分析和管理,不仅要检测出软件系统中的克隆代码,还需要了解克隆代码随版本迭代的演变情况[2]。研究者们通过分析克隆代码在版本升级过程中的变化特点,为程序员理解、管理克隆代码提供帮助。
2 相关研究工作
2.1 克隆代码
克隆代码(clone code)[2]是指软件源码中的一些代码片段,它们之间存在着相同或相似的语法或语义特征,这些代码片段被称为克隆片段(clone fragment)。两个相同或相似的克隆片段称为克隆对(clone pair),所有相同或相似的克隆片段的集合称为克隆群(clone class)。
现有研究中主要采用两种方式定义克隆,根据代码片段粒度,将克隆代码分为语句克隆、块克隆、函数克隆、类克隆、文件克隆五种类型[3];根据文本及功能相似度,将克隆代码分为Type-1克隆、Type-2克隆、Type-3克隆、Type-4克隆四种类型[3]。
图1展示了Type-1、Type-2、Type-3、Type-4四种克隆类型的具体样例。Type-1克隆( CF1与CF2):除了空格、制表符、回车换行和注释外完全相同的代码片段;Type-2克隆(CF1与CF3、CF5与CF6):除了空格、制表符、回车换行、注释、标识符、类型外句法结构完全相同的代码片段;Type-3克隆(CF1与CF4、CF3与CF4):除了空格、制表符、回车换行、注释、标识符、类型外句法结构基本相同,但含有少量语句的增加、修改、删除的代码片段;Type-4克隆(CF1与CF5):功能相似或相同但句法结构不同的代码片段[2]。

图1 四种克隆类型源代码示例图
2.2 克隆检测
克隆检测是指从源码中找出克隆代码,是克隆代码研究的基础工作。目前研究学者已提出多种克隆检测方法,每种方法都有优缺点。
Johnson[5]使用基于文本的方法进行克隆检测,首先将代码片段哈希,然后使用增量哈希函数识别具有相同哈希值的代码片段即为克隆代码。该方法时空复杂度低,但是只能用来检测Type-1克隆,对于其他类型克隆查全率较低。Baker[6]使用基于Token的方法进行克隆检测,首先使用词法分析工具将代码片段转化成Token串,然后使用后缀树算法计算Token串的相似性得到克隆代码。该方法能够有效检测Type-1、Type-2克隆,但是对于Type-3克隆查全率、查准率都不高。Baxter等人[7]使用基于抽象语法树的方法进行克隆检测,首先将源代码解析成语法树,然后将子树哈希到N个桶中,对同一个桶中的子树比较相似性得到克隆代码。该方法能有效地处理Type-1、Type-2、Type-3克隆,但时空复杂度太高。Krinke[8]使用基于程序依赖图的方法进行克隆检测,首先将程序根据语句之间的数据流和控制关系建立程序依赖图集合,然后在程序依赖图中寻找同构子图,同构子图所对应的代码片段即为克隆代码。该方法能获得程序的语义信息,可以处理顺序被打乱的克隆代码,但建立程序依赖图和寻找同构子图代价太高,很难应用在中大规模软件。Roy等人[9]基于文本检测的方法,同时集成了源代码转化、敏捷语法分析等技术,开发了一款克隆检测工具NiCad,该工具能检测C、Java等主流开发语言的Type-1、Type-2、Type-3克隆代码,并且具有较高的查全率和查准率,时空复杂度较低。更多关于克隆代码检测研究可参见综述性文献[10-12]。
2.3 克隆跟踪及演化模式
克隆检测结果仅仅提供了克隆代码的位置及克隆关系,克隆代码跟踪可以提供克隆代码在版本迭代过程中变化的线索,克隆演化模式可以体现克隆代码的变化特点。利用演化模式研究克隆变化,受到了学者的广泛关注。
Kim等人[13]首次提出克隆谱系的概念,并利用版本管理工具中的修改日志信息,推算版本间的变化,实现克隆跟踪,并且定义了六种克隆群演化模式描述相邻版本克隆代码变化情况,分别是:无变化、增加、去除、一致变化、不一致变化和位移演化模式。但是他们只对第一版本进行克隆检测,不能分析后期版本新产生的克隆,并且定义的演化模式不分视角,区分不明确。Saha等人[14]首先进行函数映射,在此基础上再进行克隆映射,最终实现克隆代码跟踪,研究开发了一款克隆谱系提取工具gCad,并将克隆谱系分为活谱系、死亡谱系、句法相似谱系、一致变化谱系四种类型,并且分析了它们所占的比例。但是如果函数重命名或者被移动,将影响克隆跟踪效果。Bakota[15]使用基于抽象语法树的克隆检测工具从每款软件中提取克隆代码,然后结合文件名、位置信息等度量实现相邻版本克隆片段映射,并且研究了四种不同的克隆片段演化模式,包括:消失克隆、发生克隆、移动克隆、迁移克隆。但是大规模软件中克隆片段数量较多,时间复杂度过大,并且如果演化过程中发生文件重命名或克隆漂移,将导致克隆片段映射失败。慈萌等人[16]改进克隆区域描述符(CRD)实现相邻版本克隆映射,然后使用二元关系合成克隆谱系,最终实现在多版本跟踪克隆。但是如果代码某些部分被修改,将导致CRD失效,影响克隆跟踪。Göde等人[17]利用增量算法将克隆检测和克隆映射相结合实现克隆跟踪,虽然时间复杂度和空间复杂度都很低,但是不能将后期版本中新产生的克隆群包含进来。Barbour等人[18]以克隆对为单位开展了后期演化模式的研究,根据克隆对分离、合并过程中克隆片段修改情况将后期演化模式分为八种类型,并分析了它们所占的比例。张久杰等人[19]基于主题信息实现相邻版本克隆映射,并在克隆群生存视角和克隆片段数量视角研究九种短期演化模式,发现超过90%的克隆代码稳定演化,但该研究使用的是软件的发布版本,克隆代码开发过程中的变化被忽略。更多关于克隆演化的研究可以参见综述性文献[10,20]。
2.4 总结
通过以上对“克隆检测”、“克隆跟踪及演化模式”国内外研究的分析,可以发现:
(1)克隆代码检测技术已经非常成熟,并且NiCad是一款非常优秀的检测工具。
(2)克隆代码跟踪不够细化,大多克隆演化研究都基于发布版本,忽略了开发过程中克隆代码的变化情况。
(3)克隆跟踪效果不好,相邻版本克隆映射时间复杂度高或准确率低。
(4)克隆演化模式区分不明确、不分视角,并且大多研究都基于传统的演化模式定义或研究部分演化模式。
针对当前研究存在的不足,本研究提出一种基于修改日志克隆代码跟踪的方法,实现了更细致的克隆代码跟踪,并分视角识别了克隆演化模式。创新点包括:基于版本管理资源库,将每次提交作为一个小版本,充分考虑每次修改变化;克隆检测使用NiCad检测工具检测每一个小版本,避免丢失对新增克隆群的研究;相邻版本基于“克隆群初步映射-克隆片段精准映射-克隆群映射修正”策略,快速准确地实现克隆跟踪;克隆演化模式识别分克隆群、克隆片段、克隆代码内容三种视角。
3 基于修改日志克隆代码跟踪及演化模式识别
本文提出的基于修改日志克隆代码跟踪及演化模式识别分为五个步骤:(1)克隆代码检测;(2)基于Token编辑距离相似度克隆群映射;(3)基于修改日志克隆片段精准映射;(4)基于克隆片段映射结果修正克隆群映射;(5)分视角克隆演化模式识别。整个方法的工作流程如图2所示。
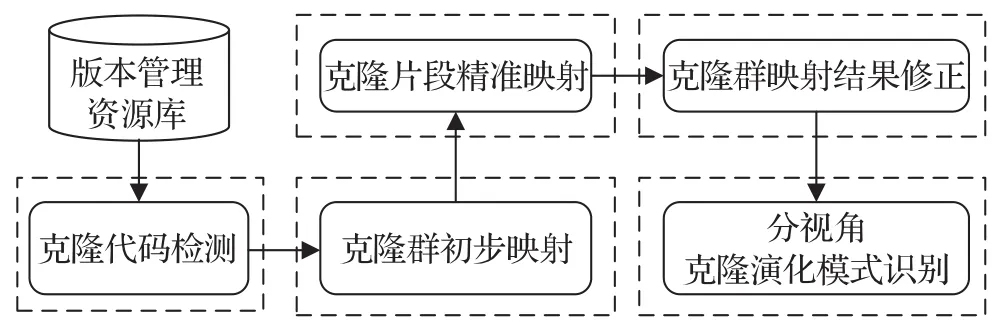
图2 整体工作流程图
3.1 克隆代码检测
克隆代码检测是研究克隆的基础工作,并且克隆检测结果直接影响后期克隆跟踪、演化模式识别等研究,所以本研究使用目前较成熟的克隆检测工具NiCad进行克隆检测。NiCad检测工具是由Queen’s University开发的克隆检测工具,适用于C、java等主流开发语言,能够检测Type-1、Type-2、Type-3的克隆代码,具有较高的查全率和查准率,而且时空复杂度很低。NiCad检测工具可以设置functions和blocks两种粒度进行克隆检测,由于blocks更具一般性,因此本研究将检测粒度设为blocks,其他设置还有rename为blind,threshold为0.3。
3.2 基于Token编辑距离相似度克隆群映射
克隆群是克隆片段的集合,对于Type1、Type2类型克隆,同一个克隆群内所有克隆片段的Token串完全相同;对于Type3类型克隆,同一克隆群内克隆片段的Token串之间也只是包含少量的增加、删除或修改。本研究使用任意一个克隆片段的Token串代替其所在的克隆群,将克隆群映射转化成Token串相似问题。通过计算Token串编辑距离相似度,实现克隆群映射。
首先,将克隆群中一个克隆片段源码Token化。本研究参考了前期研究中Token化方法[21],又考虑了克隆代码类型定义、程序语言特征及源码完整性,制定Token化规则主要包括:(1)去掉源码中的空白符、注释等非代码部分;(2)关键字(除int、float等基本数据类型)替换成其大写字母,例如if用I替换、For用F替换;(3)所有变量及数据类型用V替换;(4)浮点数、整数等数字使用D替换;(5)保留基本符号,例如{、}、=、(、)。
然后,计算Token串编辑距离相似度。公式(1)描述了计算Token串T1、T2编辑距离相似度的具体方法,其中 Levenshtein(T1,T2)表示 T1、T2的编辑距离,|T1|、|T2|分别表示T1、T2的长度。
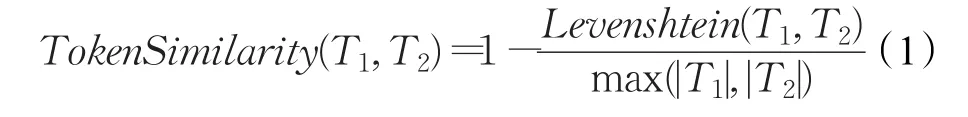
相邻版本的两个克隆群,计算它们的相似度Token-Similarity,值越大表示它们的相似度越高,它们之间存在映射关系的可能性越高;值越小表示它们的相似度越低,它们之间存在映射关系的可能性越低。本研究根据实验结果分析设定阈值为0.6,当两个克隆群的相似度TokenSimilarity大于等于0.6时,将这两个克隆群建立映射关系,加入到克隆群映射候选集合。
3.3 基于修改日志克隆片段映射
在克隆群映射的基础上,结合版本修改日志实现克隆片段映射,既不会丢失克隆跟踪信息,又减少了无关克隆片段匹配,大大提高了映射速度。
版本V(i)经过一次commit,修改了部分代码,演变成版本V(i+1),本研究使用正则表达式从修改日志中提取代码变化情况,作为计算版本V(i)的克隆片段在版本V(i+1)中位置区域的依据。表1是jabref软件的一次版本提交(commitid:11e4d9c)引起的代码位置变化情况,例如第一条变化记录“文件路径:/src/…/JabRef-Preferences.java、代码范围:48~53、对应范围:48~54、行增加数:1”表示文件/src/…/JabRefPreferences.java的48~53行进行了修改与下一版本的48~54行相对应,有1行的增加。代码范围为“0~0”表示该文件是此次提交新增文件,对应范围为“0~0”表示该文件被删除。
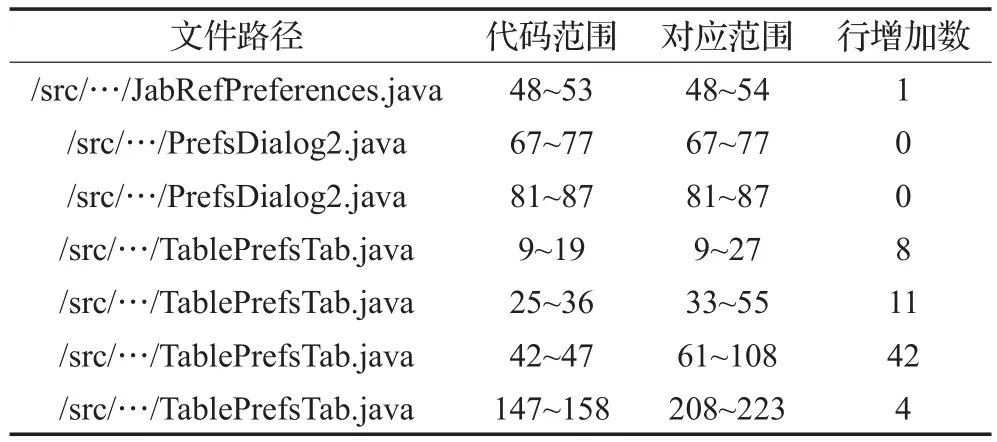
表1 commit引起的代码位置变化示例
算法1位置区域起始行计算算法
函数功能:计算克隆片段在后期版本中位置区域的起始行
输入参数:克隆片段、同文件代码位置变化列表
输出参数:克隆片段在后期版本中位置区域的起始行

算法2位置区域结束行计算算法
函数功能:计算克隆片段在后期版本中位置区域的结束行
输入参数:克隆片段、同文件代码位置变化列表
输出参数:克隆片段在后期版本中位置区域的结束行

对于版本V(i)中克隆群CG的一个克隆片段CF,在相邻后期版本V(i+1)中寻找映射克隆片段的过程如下:首先将版本V(i+1)中与克隆群CG存在映射关系的所有克隆群组成集合mappingCGSet。如果克隆群集合mappingCGSet为空,代表克隆群CG在下一版本消失,克隆片段CF在版本V(i+1)中自然不存在映射对象,结束程序。如果克隆群集合mappingCGSet不为空,那么使用修改日志信息计算克隆片段CF在版本V(i+1)中的位置区域,如算法1和算法2所示分别计算得到起始行和结束行。然后将mappingCGSet中所有克隆群包含的克隆片段汇集成候选克隆片段集合candidateCFSet。最后计算candidateCFSet中与CF同文件路径的克隆代码位置和CF在版本V(i+1)中位置区域的位置重叠率,找出最优匹配的映射克隆片段。当位置重叠率相同时,与CF的代码编辑距离最小的胜出。位置重叠率计算如公式(2)所示,其中candCF.s、candCF.e分别表示候选克隆片段的起始行、结束行,CF.mbs、CF.mbe分别表示CF在版本V(i+1)的位置区域的起始行、结束行。

本研究使用算法1和算法2根据版本修改日志计算克隆片段CF在下一版本位置区域时,将位置区域的范围尽可能小地扩大,例如,假设一个克隆片段文件路径为/src/…/TablePrefsTab.java,起始行为20,结束行为35,由于20大于19且小于25,那么起始行的可能位置为20+8=28;由于35大于等于25且小于等于36,那么结束行的可能位置为55,最终根据Argorithm 1得到该克隆片段在后期版本的位置区域是[28行,55行]。如果克隆片段CF在版本V(i+1)中没有边缘扩展,那么由CF演变而来的克隆片段必定在计算的可能位置之内,使用公式(2)可以算得位置重叠率为1.0。并且本研究所采用的方法对于克隆片段并没有修改,但因其上下文代码修改发生位置偏移的现象,仍然可以以重叠率为1.0的相似度找到其演化克隆片段。经过千余版本实验,人工验证并未发现一例克隆片段边缘扩展,因此本研究不考虑克隆片段边缘扩展现象,将位置重叠率阈值设为1.0,当最优匹配克隆片段位置重叠率等于1.0时,才建立克隆片段映射。
3.4 基于克隆片段映射结果修正克隆群映射
相邻版本克隆映射的准确性直接决定克隆跟踪的效果,也是克隆演化模式识别的基础。相邻版本克隆映射包括克隆群映射和克隆片段映射。传统的相邻版本克隆映射都是先进行克隆群映射,再进行克隆片段映射,而克隆群映射有两种方法:第一种,相邻版本克隆群两两计算相似度,结果在阈值范围之内就建立克隆群映射;第二种,相邻版本中前期版本的克隆群在后期找一个最相似的克隆群建立映射,其他克隆群不再考虑。但是传统的克隆群映射方法都存在弊端,使得最终得到的克隆映射结果不理想。第一种方法对于克隆群发生分离,后期独立演化的情况,由于分离出的克隆群也极其相似,可能会出现多余克隆群映射,即虽然从克隆群角度分析极其相似,但两个克隆群包含的克隆片段却不存在映射关系;第二种方法对于克隆群分离的情况不能处理,即前后版本克隆群真实映射出现1∶n(n>1)的情况,此方法只能将前期版本克隆群与后期版本一个克隆群建立映射关系,丢失映射信息。
图3展示了传统克隆群映射结果与真实克隆映射的对比,由于克隆群B、C、D、E均来源于克隆群A,四个克隆群非常相似,在版本V(i+1)与版本V(i+2)进行克隆群映射时,按照传统克隆群映射方法一,会出现克隆群B与克隆群E、克隆群C与克隆群D的错误映射;从版本V(i)演化到版本V(i+1)过程中克隆群A分离成两个克隆群B和C,按照传统克隆群映射方法二,在版本V(i+1)中只选择最相似的克隆群B与克隆群A建立映射,漏掉克隆群A与克隆群C的映射。
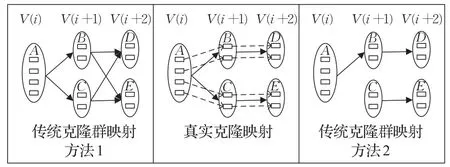
图3 传统克隆群映射结果与真实克隆映射对比
鉴于克隆群粒度太大,本研究以克隆片段映射为基准,根据版本修改日志进行克隆片段精确映射。考虑到软件中克隆片段数量太多,首先采用传统克隆群映射方法一构造克隆群映射候选集合,在此基础上进行细致克隆片段映射,最终根据克隆片段映射结果修正克隆群映射,即检查有映射关系的克隆群包含的克隆片段是否存在映射,如果映射的克隆群包含的克隆片段没有任何关系,将取消克隆群的映射。
3.5 分视角识别克隆演化模式
克隆代码演化模式可用于研究克隆代码在相邻版本迭代过程中演变特点,帮助开发人员及时了解克隆代码动态变化规律。基于已有研究中演化模式识别方法复杂、演化模式分类不清晰、模式识别不全面等问题,本研究在相邻版本克隆映射的基础上分三种视角进行克隆代码演化模式识别,并将演化模式以标签的形式标记在前期版本克隆群上。三种视角分别是:克隆群视角、克隆片段视角、克隆代码内容视角。
3.5.1 克隆群视角短期演化模式识别
根据相邻版本具有映射关系克隆群数量比例及交叉程度,从克隆群角度识别克隆演化模式,可以分为六种演化模式(如图4所示)。
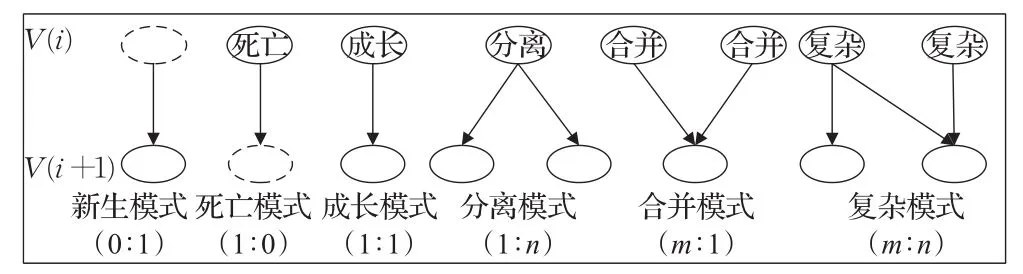
图4 克隆群视角短期演化模式
新生演化模式:版本V(i)与版本V(i+1)之间具有映射关系的克隆群数量之比为0∶1,即版本V(i+1)中有新克隆群产生。
死亡演化模式:版本V(i)与版本V(i+1)之间具有映射关系的克隆群数量之比为1∶0,即版本V(i+1)中有克隆群消失。
成长演化模式:版本V(i)与版本V(i+1)之间具有映射关系的克隆群数量之比为1∶1。
分离演化模式:版本V(i)与版本V(i+1)之间具有映射关系的克隆群数量之比为1∶n(n>1)。
合并演化模式:版本V(i)与版本V(i+1)之间具有映射关系的克隆群数量之比m∶1(m>1)。
复杂演化模式:版本V(i)与版本V(i+1)之间具有映射关系的克隆群数量之比m∶n(m>1且n>1)。
为了方便演化模式存储,将演化模式以标签的形式标注在前期版本克隆群上,且新生模式是一个克隆群从无到有,并不包含其修改变化信息,本研究不予考虑,只标注死亡、成长、分离、合并、复杂五种演化模式。对版本V(i)中的克隆群CG从克隆群角度识别短期演化模式,添加群标签步骤如下:
第一步:如果克隆群CG无后继,即版本V(i)迭代到版本V(i+1)过程中由于修改或删除使得克隆群CG不再存在,发生了死亡模式,则为克隆群CG添加“死亡”标签。
第二步:如果克隆群CG只有一个后继,并且该后继克隆群只有一个前驱(肯定是克隆群CG),那么发生成长模式,则为克隆群CG添加“成长”标签。
第三步:如果克隆群CG存在多个后继,但是所有的后继克隆群都只有一个前驱(肯定是克隆群CG),那么发生分离模式,则为克隆群CG添加“分离”标签。
第四步:如果克隆群CG只有一个后继,并且该后继克隆群有多个前驱(即除了克隆群CG还有其他克隆群),但是所有前驱克隆群都只有一个后继(肯定是克隆群CG的后继),那么发生合并模式,则为克隆群CG添加“合并”标签。
第五步:如果经过前四步克隆群CG依然没被标注,那么发生了复杂模式,则为克隆群CG添加“复杂”标签。
3.5.2 克隆片段视角短期演化模式识别
根据相邻版本迭代过程中克隆片段延续性,从克隆片段角度识别短期演化模式,可以分为三种演化模式(如图5所示)。
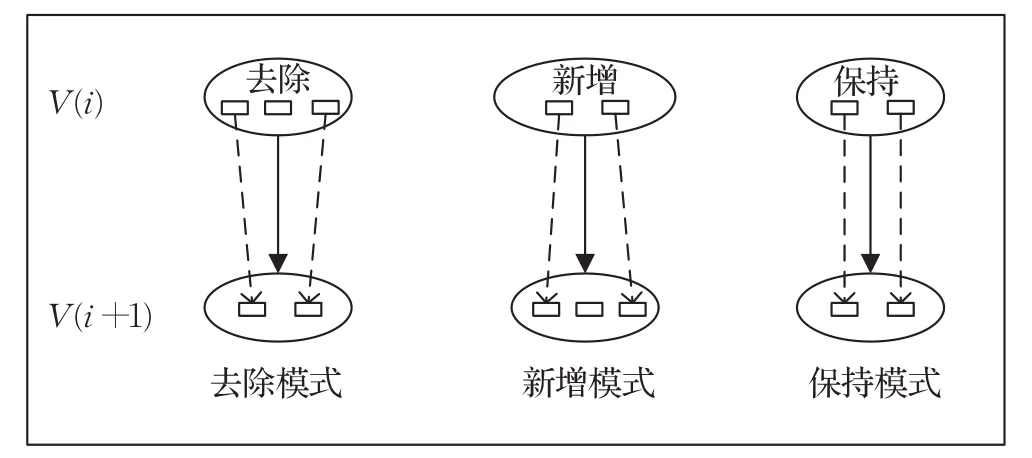
图5 克隆片段视角短期演化模式
去除演化模式:版本V(i)到版本V(i+1)的过程中,版本V(i)的克隆群中包含无后继的克隆片段。
新增演化模式:版本V(i)到版本V(i+1)的过程中,版本V(i+1)的克隆群中包含无前驱的克隆片段。
保持演化模式:版本V(i)到版本V(i+1)的过程中,版本V(i)的克隆群包含的所有克隆片段都有后继,版本V(i+1)的克隆群包含的所有克隆片段都有前驱。
克隆片段视角分析克隆演化模式,实际就是将克隆片段演化规律标注在其所在的克隆群上。因此片段标签与群标签不同,一个克隆群上可能同时出现两个片段标签,例如,一个克隆群在演化过程中删除了一个克隆片段同时在其他地方又新增一个克隆片段,这种情况更应该值得关注。对版本V(i)中的克隆群CG从克隆片段角度识别短期演化模式,添加片段标签步骤如下:
第一步:如果克隆群CG包含的克隆片段存在一个无后继的,即版本V(i)迭代到版本V(i+1)过程中一个克隆片段从克隆群CG中消失。那么发生了去除模式,为克隆群CG添加“去除”标签。
第二步:如果版本V(i+1)中与克隆群CG有映射关系的克隆群包含无前驱的克隆片段,那么该克隆片段为新增的,发生了新增模式,为克隆群CG添加“新增”标签。
第三步:如果经过前两步克隆群CG没有被标注“去除”、“新增”标签,那么它包含的所有克隆片段都被完好地保持了下来,为克隆群CG添加“保持”模式。
3.5.3 克隆代码内容视角短期演化模式识别
根据克隆代码修改影响,从克隆代码内容角度识别短期演化模式,可以分为三种演化模式(如图6所示)。
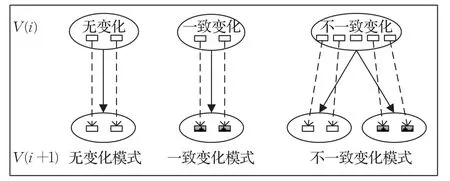
图6 克隆代码内容视角短期演化模式
无变化演化模式:版本V(i)到版本V(i+1)的过程中,克隆群中包含的克隆片段均无变化。
一致变化演化模式:版本V(i)到版本V(i+1)的过程中,克隆群中包含的克隆片段有变化,但所有克隆片段仍在一个克隆群中。
不一致变化演化模式:版本V(i)到版本V(i+1)的过程中,克隆群中包含的克隆片段有变化,克隆片段不完全在同一个克隆群中。
克隆代码内容视角分析克隆演化模式,主要考察克隆群包含的克隆片段是否被修改,被修改之后引起什么影响,同在一个克隆群的克隆代码经过修改之后是否还在同一克隆群中。对版本V(i)中的克隆群CG从克隆代码内容角度识别短期演化模式,添加内容标签步骤如下:
第一步:如果克隆群CG包含的所有克隆片段均未被修改,那么为克隆群CG添加“无变化”标签。
第二步:如果克隆群CG包含的克隆片段有修改,但是在版本V(i+1)中依旧保持在同一个克隆群中,那么为克隆群CG添加“一致变化”标签。
第三步:如果克隆群CG包含的克隆片段有修改,并且克隆群CG包含的克隆片段在后期版本V(i+1)中不再属于同一个克隆群,那么为克隆群CG添加“不一致变化”标签。
4 实验与分析
4.1 实验数据
本研究选取的6款开源软件分别是jabref、make、nginx、ant、freecol、argouml,这些软件的基本信息见表2所示。
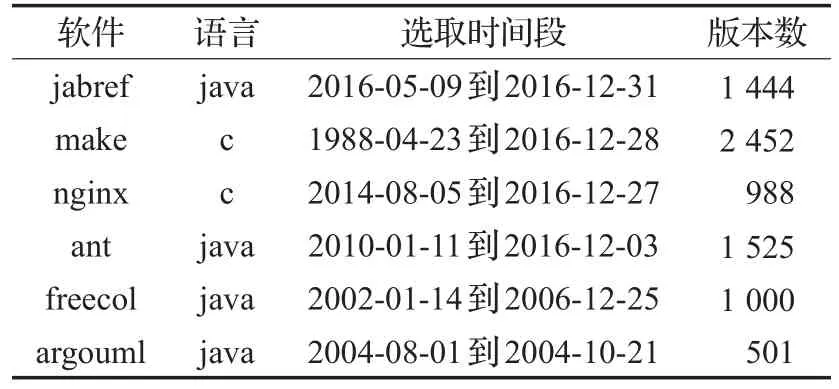
表2 实验软件基本信息
4.2 评价方法
为了验证本研究中关键参数选取及克隆映射同类实验对比的有效性,采用人工验证的方法从查准率、查全率、F 值三方面进行衡量。如公式(3)、(4)、(5)所示,其中TT表示识别的正确映射的数量,(TT+TF)表示识别的所有映射的数量,(TT+FT)表示实际存在的映射的数量。precision表示查准率,recall表示查全率,F-Measure表示F值。

4.3 关键参数选取
本研究实现克隆映射,基于“克隆群初步映射-克隆片段精准映射-克隆群映射结果修正”策略,因此克隆群初步映射的结果直接影响最终克隆映射的效果。克隆群初步映射时,如果Token编辑距离相似度阈值设置过大,会丢失部分克隆群映射,导致克隆跟踪间断,影响克隆的分析结果;如果Token编辑距离相似度阈值设置过小,会使得克隆群映射候选集合过大,不能达到提高克隆映射速度的目的。
通过对表3中四款软件开展相邻版本克隆群映射实验,得到如图7所示选取不同的Token编辑距离相似度阈值时克隆群映射查准率、查全率的变化情况,分析发现:(1)Token编辑距离相似度阈值在0.4到0.7的变化过程中克隆群映射查准率有显著提升;(2)克隆群映射查全率几乎全为1.0,Token编辑距离相似度阈值变化对其影响不大。考虑到研究版本的细化程度,相邻版本间克隆代码变化可能很小,而选取的代表克隆群的克隆片段可能是同一个并且几乎未发生变化,因此出现Token编辑距离相似度阈值变化而克隆群映射查全率始终为1.0的现象。但是在版本演化过程中,可能出现克隆片段被删除,代表克隆群的克隆片段换成了其他克隆片段等情况。基于此,本研究统计每个版本中同一个克隆群所包含的克隆片段之间的最低Token编辑距离相似度,得到同克隆群内克隆片段之间最低Token编辑距离相似度分布如表4所示。通过对表4分析,可以发现:(1)同克隆群内Token编辑距离相似度最低值全部大于等于0.6;(2)同克隆群内Token编辑距离相似度最低值大于等于0.7的超过85%。综合考虑图7和表4的统计数据,在保证克隆群映射查全率为1.0的情况下,尽可能减小克隆群映射候选集合,整体提升相邻版本克隆映射速度,将Token编辑距离相似度阈值设置为0.6。
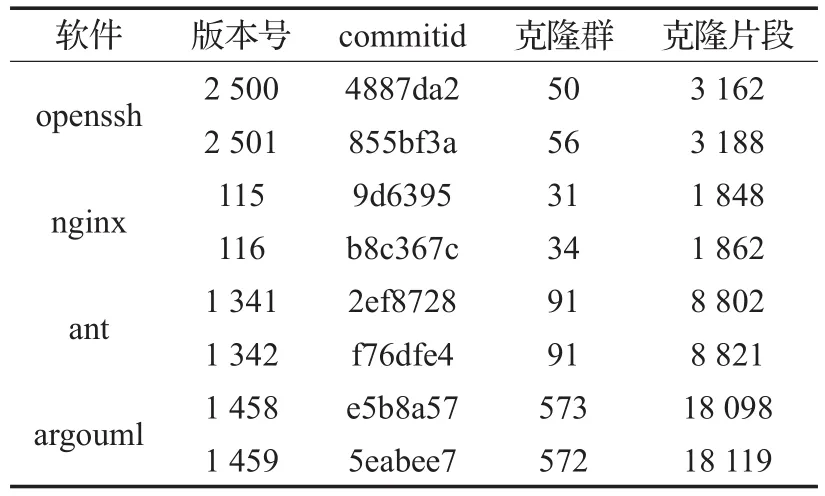
表3 阈值选取实验软件信息
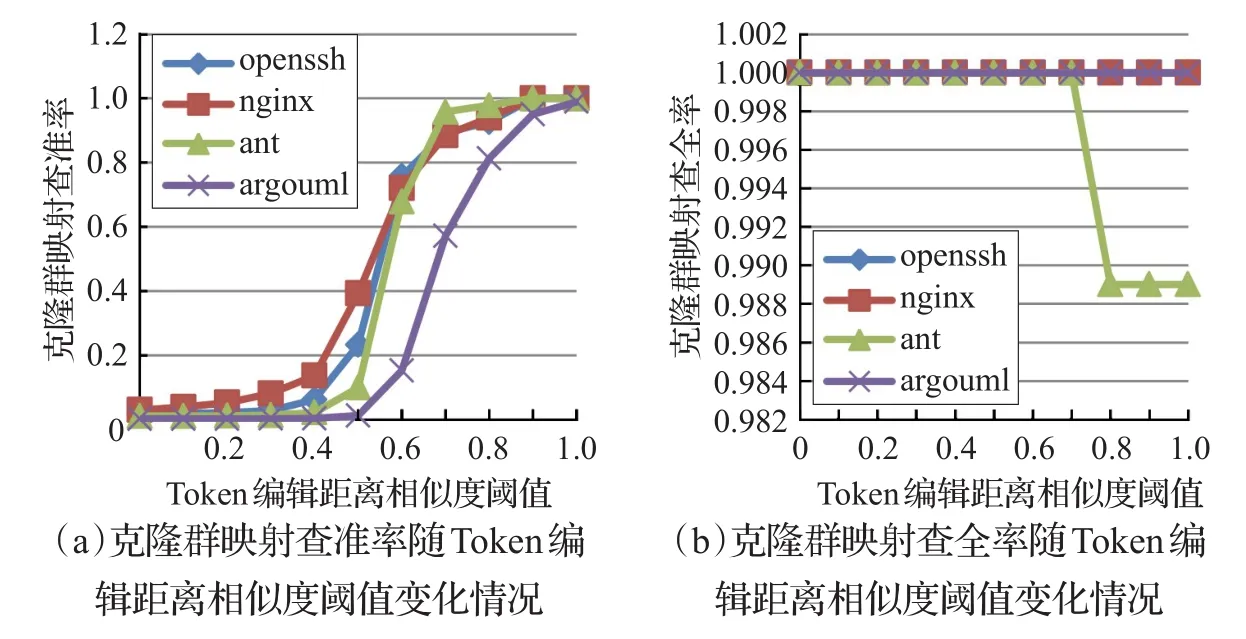
图7 克隆群映射查准率、查全率随Token编辑距离相似度阈值变化情况
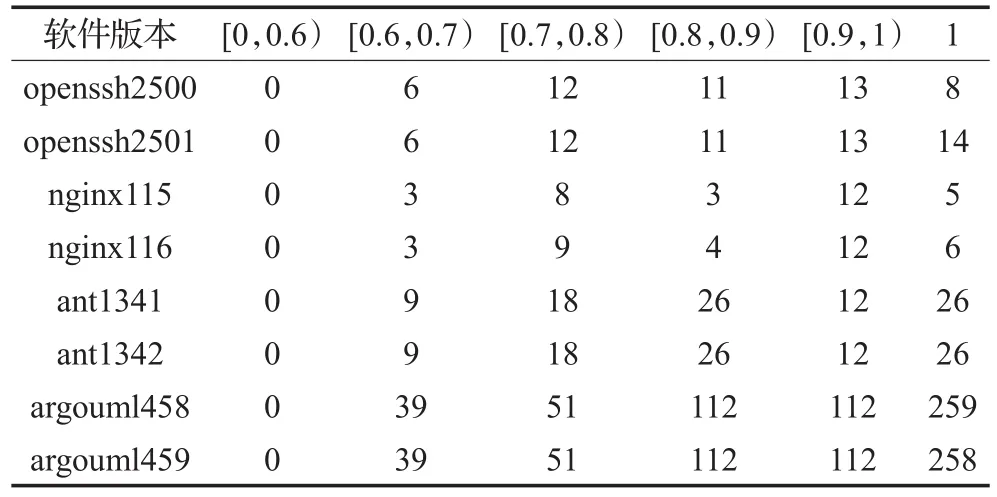
表4 同克隆群内克隆片段之间相似度分布
4.4 同类实验对比分析
目前已有不少克隆跟踪工具被开发,其中Saha等人开发的克隆谱系提取工具gCad影响力最大。鉴于本研究与gCad识别的演化模式不完全一致,仅对克隆映射做对比实验。其中检测阶段都使用NiCad且参数设置相同,实验平台同为操作系统Ubuntu14.04 64位,内存4 GB,CPU 2核。选取的实验软件分别是ant、freecol、openssh,版本信息如表5所示。
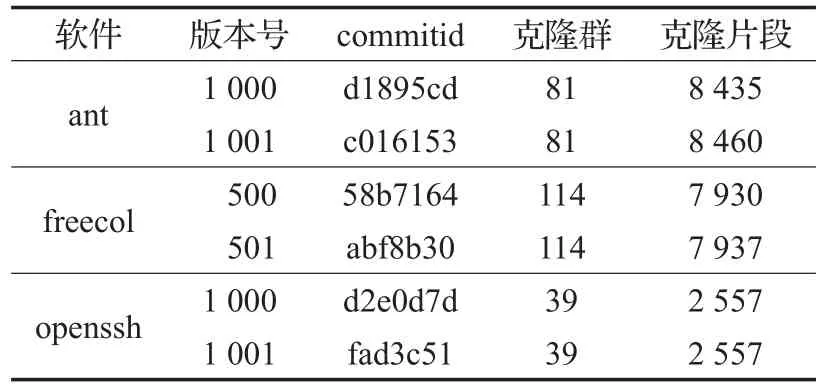
表5 相邻版本克隆映射对比实验软件信息
通过对比实验,配合人工验证,结果如表6所示。从映射结果分析,ant软件相邻版本克隆映射,OurTool和gCad的查全率都是100%,但是由于克隆检测结果中存在两个克隆群非常相似,导致gCad的结果中存在错误映射,查准率降低,而OurTool基于修改日志信息,避免了错误映射。freecol软件相邻版本克隆映射,OurTool依然完美地完成映射,而gCad的结果中出现了错乱映射,导致查全率、查准率都有所降低。openssh软件选取的相邻版本克隆检测结果一致,对比克隆检测结果和修改日志发现克隆代码并没有发生任何修改,OurTool和gCad都非常好地完成了相邻版本克隆映射。从时间分析,在三款软件上,OurTool的速度都要快于gCad,而且克隆群数量越多,效果越明显。综上OurTool的查全率、查准率、F值明显高于gCad,而且运行时间也较短。

表6 相邻版本克隆映射同类实验结果对比
4.5 实验结果及分析
本研究在6款开源软件近8 000个版本进行了克隆代码跟踪实验。下面给出克隆代码各演化模式的统计数据,并进行简要分析。
表7是在克隆群视角对克隆演化模式的统计结果,可以发现:(1)克隆代码在相邻版本间几乎都是以成长模式演化的(比重均超过98%)。(2)死亡模式所占的比重均小于2%,发生死亡模式的这些克隆代码在软件开发过程中可能被删除或者大幅度修改,导致不再具备克隆关系。(3)分离模式、合并模式、复杂模式所占的比例小于等于0.01%,甚至有的演化模式在开发过程中并不出现,虽然这些演化模式发生得很少,但由于其不“规矩”,可能与Bugs有关,更应该值得关注。
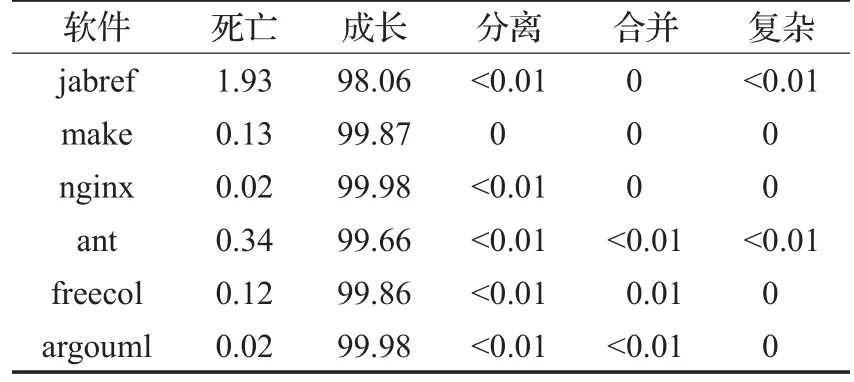
表7 克隆群视角短期演化模式统计结果 %
表8是在克隆片段视角对克隆演化模式的统计结果,去除模式指仅发生了去除,新增模式指仅发生了新增,不包含去除新增同时发生时的数据。分析表8中数据可以发现:(1)保持模式占的比例均超过97%。(2)去除模式、新增模式、去除&新增模式的比例都不高,并且去除模式远远多于其他两种,去除新增同时发生的情况也比仅新增模式略多。说明克隆片段在版本迭代过程中也几乎都被保留了下来,并且克隆代码被再次重用得并不多,反而在演化过程中被修改失去克隆关系的占一定比例。

表8 克隆片段视角短期演化模式统计结果%
表9是在克隆代码内容视角对克隆演化模式的统计结果,可以发现:(1)超过98%的克隆代码在版本迭代过程中均未发生修改。(2)发生一致变化模式和不一致变化模式的克隆代码占比均不高于2%,并且一致变化模式的比例略多于不一致变化的比例。
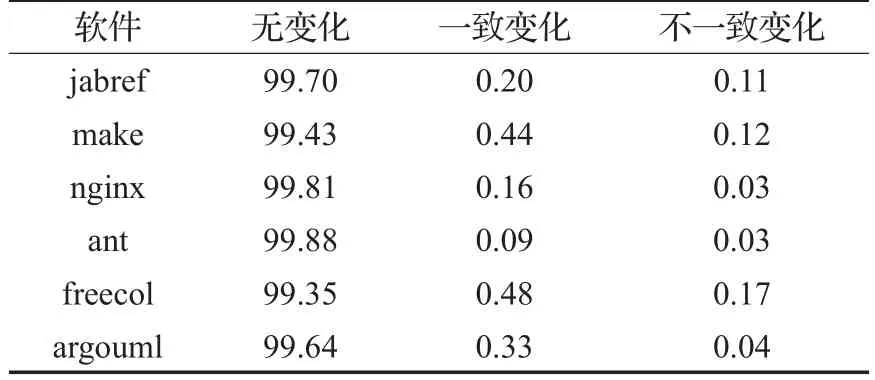
表9 克隆代码视角短期演化模式统计结果%
5 结语
本研究提出一种基于修改日志克隆代码跟踪方法,并分视角识别克隆演化模式,分析了各模式所占比例。发现超过97%的克隆稳定演化,分离演化模式、合并演化模式、复杂演化模式均不超过0.01%,一致变化演化模式、不一致变化演化模式均不超过2%。并且在多款软件上与领域内较优秀的同类工具gCad做对比实验,结果查全率(提高了2%)、查准率(提高了2%)明显高于gCad,而且同环境下速度比gCad快。本文的研究内容与实验仍然存在一些不足之处,例如演化模式以克隆群为粒度太粗。本文在后续研究中陆续改进、完善不足之处,以克隆对为粒度分析克隆演化。
参考文献:
[1]Alkhatib G.The maintenance problem of application software:An empirical analysis[J].Journal of Software Maintenance Research&Practice,1992,4(2):83-104.
[2]Zibran M F,Saha R K,Asaduzzaman M,et al.Analyzing and forecasting near-miss clones in evolving software:An empirical study[C]//IEEE International Conference on Engineering of Complex Computer Systems,2011:295-304.
[3]Roy C K.Detection and analysis of near-miss software clones[C]//IEEE International Conference on Software Maintenance,2009:447-450.
[4]D·张,S·卡恩,党映农,等.代码克隆通知以及体系结构改变可视化:CN,CN 102681835 A[P].2012.
[5]Johnson J H.Identifying redundancy in source code using fingerprints[C]//Conference of the Centre for Advanced Studies on Collaborative Research,Toronto,Ontario,Canada,1993:171-183.
[6]Baker B S.On finding duplication and near-duplication in large software systems[C]//Proceedings of 2nd Working Conference on Reverse Engineering,1995:86-95.
[7]Baxter I D,Yahin A,Moura L,et al.Clone detection using abstract syntax trees[C]//International Conference on Software Maintenance,1998:368-377.
[8]Krinke J.Identifying similar code with program dependence graphs[C]//Eighth Working Conference on Reverse Engineering,2001:301-309.
[9]Cordy J R,Roy C K.The NiCad clone detector[C]//The IEEE International Conference on Program Comprehension,ICPC 2011,2011:219-220.
[10]史庆庆,孟繁军,张丽萍,等.克隆代码技术研究综述[J].计算机应用研究,2013,30(6):1617-1623.
[11]Koschke R.Survey of research on software clones[C]//Proc Duplication Redundancy&Similarity in Software,2006.
[12]曹羽中,金茂忠,刘超.克隆代码检测技术综述[C]//中国计算机学会软件工程专委会2006年年会,2006.
[13]Kim M,Sazawal V,Notkin D,et al.An empirical study of code clone genealogies[J].Acm Sigsoft Software Engineering Notes,2005,30(5):187-196.
[14]Saha R K,Roy C K,Schneider K A.gCad:A near-miss clone genealogy extractor to support clone evolution analysis[C]//IEEE International Conference on Software Maintenance,2013:488-491.
[15]Bakota T.Tracking the evolution of code clones[C]//Sofsem 2011:Theory and Practice of Computer Science,Conference on Current Trends in Theory and Practice of Computer Science,Nový Smokovec,Slovakia,January 22-28,2011:86-98.
[16]Meng C,Su X H,Wang T T,et al.A new clone group mapping algorithm for extracting clone genealogy on multi-version software[C]//Third International Conference on Instrumentation,Measurement,Computer,Communication and Control,2013:848-853.
[17]Göde N,Koschke R.Studying clone evolution using incremental clone detection[J].Journal of Software Evolution&Process,2013,25(2):165-192.
[18]Barbour L,Khomh F,Zou Y.Late propagation in software clones[C]//IEEE International Conference on Software Maintenance,2011:273-282.
[19]张久杰,翟晔,王春晖,等.基于版本间克隆映射的演化模式识别及谱系构建[J].计算机应用,2016,36(7):2021-2030.
[20]Pate J R,Tairas R,Kraft N A.Clone evolution:A systematic review[J].Journal of Software Maintenance&Evolution Research&Practice,2013,25(3):261-283.
[21]张久杰,王春晖,张丽萍,等.基于Token编辑距离检测克隆代码[J].计算机应用,2015,35(12):3536-3543.
