个体差异对Python爬虫获取教育大数据的影响研究*
2018-06-01王世纯许新华张洪春黄嘉成
王世纯 ,许新华 ,2,张洪春 ,黄嘉成
(1.湖北师范大学 研究生院,湖北 黄石 435000;
2.湖北师范大学 教育信息与技术学院,湖北 黄石435000;
3.湖北职业技术学院 信息学院,湖北 孝感 432000)
一、引言
伴随着“互联网+”、物联网、云计算时代的到来,大数据在我们的生产生活中扮演着越来越重要的角色,可以说大数据已经渗透到每一个行业。联合国在2012年发布的大数据白皮书 《Big Data for Development:Challenges&Opportunities》中指出大数据的出现将会对社会各个领域产生深刻影响。[1]在教育领域,每天都会产生海量的教育大数据,[2]获取教育大数据的途径也有很多,例如线下调查、在线搜索、网络调查问卷和网络爬虫等等。本研究为了探究个体差异对教育大数据获取途径的影响,对计算机、统计学相关专业师生的编程能力、Python技术掌握程度以及获取教育大数据的途径进行了调查。
Python是一种面向对象的解释性计算机程序语言,其实它问世的时间并不长,但它以其简洁的语法、丰富的标准库和强大的第三方库,已经完全能够和C、C++等语言轻松联结,并重写封装为可用的标准类库,易于扩展。[2]Python现已逐渐取代其他大多数计算机编程语言,成为现在网络爬虫和机器学习的主流工具。
教育大数据为教育信息化的发展带来了新的机遇,[3]传统的数据收集方法已不能满足日新月异的现代化发展需求,随着网络爬虫和Python语言的发展,网络教育数据的获取越来越容易,越来越方便,速度越来越快,但对计算机语言使用的熟悉程度也有一定的考验。那么如何在大量的教育数据中获取我们所需要的、有用的信息是每一个教育研究者应该考虑的问题。
二、相关概念
1.网络爬虫
网络爬虫(又称网络蜘蛛、网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。[4]网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。[4]实际的网络爬虫是由几种爬虫技术结合实现的。随着“互联网+”的发展,网络信息量呈现出爆发式增长,仅仅只用搜索引擎已经不能快速、准确地获取到我们所需要的信息,并且会附带着额外的我们不需要的广告信息,因此,网络爬虫应运而生。
2.教育大数据
教育大数据分为广义和狭义,广义的教育大数据泛指所有来源于日常教育活动中人类的行为数据;狭义的教育大数据是指学习者学习的行为数据。[5]也有学者认为教育大数据指整个教育活动过程中所产生的以及根据教育需要采集到的,一切用于教育发展并可创造巨大潜在价值的数据集合。[6]教育,体现的是一种共享的思想,通过各种技术实现教育数据的收集,本研究主要是了解网络教育数据的获取。
三、研究过程
1.研究目标与假设
本研究是为了了解计算机、统计学相关专业Python爬虫技术掌握情况以及常用的获取教育数据的方式,比较不同个体之间获取教育大数据的区别,从而探究不同个体Python掌握程度、学习编程年限、主观因素对获取教育大数据的影响。
Python语言虽然得到极大的发展,但全国很多高校并没有把Python语言作为一门课程,学生对之了解太少,技术掌握不够,爬虫技术也不是每一个计算机专业的人都会掌握。因此,我们大胆假设:近几年获取教育大数据的主要途径还是在线搜索,并且学生与老师之间存在显著差别。
2.研究问卷的设计
(1)设计过程
问卷调查为本文的主要研究方法,为保证本研究的公正、客观,在进行调查问卷设计之前,笔者查阅了相关文献,之后初步编写了适合本研究的调查问卷,随后请老师对本问卷进行评价,给出了宝贵的意见,并对问卷的内容进行适当的修正;之后进行小范围的前测,删除其中信度和效度较低的题项,最终形成了完整的问卷。
(2)设计结果
经过上述步骤,制定了“基于Python爬虫的教育大数据获取调查问卷”。本问卷总体设计为三个维度,分别为:基本信息、Python爬虫了解程度和技术掌握、获取教育大数据的现状。共包括16个题项,为了方便统计,问卷主要设置为单选题;但为了解Python掌握程度和获取教育大数据途径,本问卷还设计了多选题和一个主观题。
3.问卷数据的收集
(1)被试分析
由于本问卷是基于Python和网络爬虫,所以对被试的专业和编程能力有一定的要求。参与本问卷的对象皆来自教育技术学、现代教育技术、通信工程、信息工程、网络工程、数字媒体技术、计算机科学与技术、计算机应用、数学与统计等专业,部分非计算机和统计相关专业的问卷已剔除。填写问卷的学生或老师来自云南、湖北、湖南、四川、福建、广东 、浙江等省份,具有一定的代表性。
(2)问卷的发放与回收
本问卷通过问卷星进行发放与回收,调研开始于2017年10月25日,截止于2017年11月2日。共回收问卷120份,其中106份为有效问卷,有效率为88.3%,达到预期数据需求。
在回收的106份有效问卷中,男性36人参与问卷,占总人数的33.96%,女性70人,占总人数的66.04%;老师31人,占29.25%,学生66人,占62.26%,还有部分已毕业但未从事教育行业的计算机相关专业的人参与了问卷;其中教育技术学专业为66.98%,信息工程为10.38%,计算机科学与技术为10.6%,其余小部分为其他专业;其中本科生51人,研究生14人,已参加工作41人。
4.信效度分析
本文采用SPSS19.0进行问卷信度和效度的分析。本问卷的Cronbach alpha系数为0.748,表明此问卷的内部一致性良好。本问卷对结构效度进行了检验,进行探索性因子分析,KMO值为0.717,Bartlett球体检验结果显示显著性水平为0.000,小于0.001,满足了统计学意义,该问卷结构效度良好。
四、研究结果
1.获取教育大数据的差异特征
不同的个体获取教育大数据方法各不相同,为探讨不同性别、年级、职业对教育大数据获取途径的影响,本文采用描述性统计和独立样本T检验以及单因素方差分析等统计学方法进行统计分析。
通过独立样本T检验可知,F值为1.955,对应的概率P值(Sig.=0.165),大于显著性水平0.05,因此,两总体方差无显著差异,应看第一行的t检验结果,等方差假设下的Sig为0.092,,大于0.05,因此,两总体均值无显著差异,即,获取教育大数据的途径与性别无关。
年级对教育大数据获取途径的影响用单因素方差分析,结果显示,显著性水平为0.063,大于0.05,因此认为各个年级获取教育大数据途径无显著差异。
按照上述方法,本研究通过独立样本t检验分析可知,职业对教育大数据获取途径的影响无显著差异。结果显示,p值为0.9,明显大于0.05,因此认为职业对获取教育大数据的途径无显著影响。
2.Python爬取教育大数据的影响因素
(1)面向对象编程经验对Python技术掌握的影响
每一门编程语言都有它自己独特的特点,本文为探究不同的编程语言对Python技术掌握和用Python进行网络爬虫的影响,利用统计学相关分析作为分析方法。
经过分析,面向对象编程经验对Python技术掌握在0.01水平(双侧)上显著相关,Pearson相关系数为0.835,说明面向对象编程语言的学习对Python技术掌握有较大影响。
(2)学习编程年限对Python爬取教育大数据的影响
在本研究中,学习编程年限与Python爬取教育数据的Pearson相关系数为0.414,在0.01水平(双侧)上显著相关。说明学习编程年限越长,Python掌握情况越好,学习编程年限对Python爬取教育大数据有较大影响。
(3)主观因素对获取教育大数据途径的影响
通过相关分析,Python掌握程度与被试主观意愿的Pearson相关系数为0.048,显著性水平为0.624,不应该拒绝原假设,因此认为两总体零相关。由此可见,虽然有些人掌握了Python语法,能利用Python进行编程并且能进行网络数据的爬取,但他们还是不愿意用Python网络爬虫爬取数据。
五、结论
1.不同个体获得教育大数据途径不同,但以在线搜索为主
经过上述分析,不同性别、职业、年级获取数据方式无显著差异,总体来说,65.09%的表示获取数据主要是用在线搜索,用网络爬虫获取数据的只有少数,如图1所示。因此,研究结果与研究假设一致,近年来获取教育大数据的主要途径还是在线搜索。且本研究发现,职业因素对教育大数据获取途径影响不大,这与研究假设不一致,原因是本研究的调查对象有很多是刚毕业的师范生,他们毕业后也成为了老师,与已经工作很多年的老师没有进行区分,这也是本研究不足的地方。
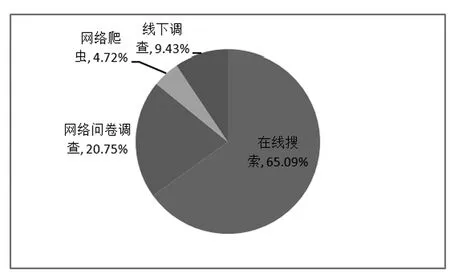
图1 教育大数据获取途径来源图
2.Python技术普及度不够,这是Python网络爬虫应用不广泛的主要原因
掌握Python基础语法、能利用Python进行简单的编程、了解网络爬虫是基于Python爬虫获取数据的基础。本次调研的大学生或老师表示,有46.23%的人虽然为计算机相关专业,但从来没有听说过网络爬虫,更不要说用爬虫技术来获取教育大数据。且经过交叉分析(见表1),女生中没听过网络爬虫的有54.29%,男生仅为30.56%;且选择这项的大一、大二本科生较多,他们刚进入大学的象牙塔,没听说过网络爬虫也是情有可原。且有83.96%的人表示从来没学过Python,90.57%的表示不会利用Python进行编程,更不要谈利用Python获取数据。因此,技术掌握不到位,进行网络爬虫的基础就没有,这是网络爬虫应用不广泛的主要原因。

表1 交叉分析
3.编程经验和年限对Python爬虫获取大数据途径有显著影响 ,但主观因素影响不大
Python语法简洁,在拥有了其他面向对象语言编程经验(比如Java)的基础上再来学习Python相对来说会容易很多,学习时间也会少很多。学习编程年限越长,Python掌握程度越好,也越具备Python爬虫获取数据的条件,但学习技术也有一个过程,可能有些学生目前正在学习技术,却还没有达到能够编写程序获取数据的水平;但也不排除有些人有足够的技术,却不愿意利用爬虫技术获取数据。笔者通过调查,发现虽然有时在线搜索结果不准确,但对于大多数人来说,获取普通数据在线搜索能够满足需求,不需要再额外花时间去编写爬虫程序。
[1]Big Data for Development:Challenges&Opportunities[DB/OL].2012-05-01.http://www.unglobalpulse.org/sites/default/files/BigDataforDevelopment-UNGlobalPulseJune2012.pdf.
[2]郭丽蓉.基于 Python的网络爬虫程序设计[J].电子技术与软件工程,2017(12):248-249.
[3]顾小清,郑隆威,简菁.获取教育大数据:基于xAPI规范对学习经历数据的获取与共享[J].现代远程教育研究,2014(5):13-23.
[4]范传辉.Python爬虫开发与项目实战[M].北京:机械工业出版社,2017(3):69-72.
[5]杜婧敏,方海光,李维杨,仝赛赛.教育大数据研究综述[J].中国教育信息化,2016(19):11-17.
[6]杨现民,唐斯斯,李冀.发展教育大数据:内涵、价值和挑战[J].现代远程教育研究,2016(1):50-61.
