基于改进Faster R-CNN识别深度视频图像哺乳母猪姿态
2018-06-01薛月菊朱勋沐杨阿庆涂淑琴杨晓帆陈鹏飞张南峰
薛月菊,朱勋沐,郑 婵,毛 亮,杨阿庆,涂淑琴,黄 宁,杨晓帆,陈鹏飞,张南峰
(1. 华南农业大学电子工程学院,广州 510642;2. 广东省现代养猪数据化工程技术研究中心,广州 510642;3. 广东省农情信息监测工程技术研究中心,广州 510642;4. 华南农业大学数学与信息学院,广州 510642;5. 广州出入境检验检疫局,广州 510623)
0 引 言
母猪的母性行为及健康和福利状况,直接影响养猪场的经济效益。母猪姿态自动识别是母猪高危动作预警[1]、母猪筑巢行为自动分析[2]、哺育仔猪自动监测及健康与福利状态评估的重要基础[3]。
用计算机视觉自动监测猪,不仅成本低、效率高、无损伤,且可避免采用传感器监测方法引起的猪的应激反应,被逐渐应用到猪的站、坐、卧、跪等姿态识别[4],饮食行为[5]、躺卧行为[6-7]、爬跨行为[8]、母猪分娩行为[9]与运动状态监测[10],及生猪活体特征预测等[3]。如Nasirahmadi等[8]采用椭圆拟合定位视频图像中的猪,通过计算猪的头、尾到椭圆两边的欧式距离及猪的身体比例,检测爬跨行为;Kashiha等[10]用 Otsu阈值分割及椭圆拟合识别母猪姿态,检测猪的“运动”(走、跑等)与“非运动”(躺、坐等)。为克服光线的影响,研究者开始用Kinect传感器采集深度视频图像来进行猪的信息获取。如Lao等[4]计算限位栏中哺乳母猪躯体多个区域的深度像素平均值,识别母猪的卧、坐、站和跪姿态及饮食行为;刘波等[11]用生猪深度图像序列建立行走运动模型等。
哺乳母猪的非刚性躯体,小猪与母猪之间的相互粘连、遮挡,热灯光照,特别是夜间猪舍光线昏暗,使得用彩色图像的全天候自由栏中母猪姿态的自动识别面临着极大的挑战。
卷积神经网络CNN(convolutional neural networks)在目标检测任务上表现出优越的性能[12-16]。CNN检测的框架主要包括基于区域的方法与基于回归的方法[13]。其中,以R-CNN[14]和Faster R-CNN[15]为代表的基于区域的方法,检测精度高于基于回归方法。Faster R-CNN将区域生成网络(region proposal networks, RPN)[15]和Fast R-CNN[16]检测网络融合,实现了高精度的实时检测,受到极大的关注。随着Faster R-CNN使用的CNN网络结构层数由浅到深,包括 ZF[17]、VGG[18]、GoogleNet[19]和ResNet[20]等,尽管更深的网络可能带来更高的精度,但会导致检测速度降低。因此,对于具体问题,研究合适的基础网络结构和训练方法以保证较高精度的同时确保实时性,是目前CNN的主要研究方向之一[20-21]。
为解决自由栏猪舍场景下,昼夜交替环境光线和热灯光线变化、母猪与仔猪粘连给哺乳母猪姿态识别带来的困难,本文采用Kinect2.0传感器拍摄的深度图像作为研究数据,引入残差结构[20]和Center Loss监督信号[22-23],提出基于改进Faster R-CNN的母猪识别方法,即通过端对端的训练网络,同时实现哺乳母猪的检测及其站立、坐立、俯卧、腹卧和侧卧[24]5类姿态的分类。
1 试验数据
1.1 试验数据采集
试验数据采集于广东佛山市三水区乐家庄养殖场,于2016年11月至2017年4月间分4次采集28栏猪的视频图像,其中一栏为全天24 h的数据,其他栏为不同时段数据,时长1~12 h不等。猪栏大小约为3.8 m×2.0 m,每栏内包含1只哺乳母猪和8~10头日龄2~21天的仔猪。为保证新生猪仔的成活率,大多数时段使用热灯保持温度。利用Kinect2.0传感器垂直向下以5帧/s的速度获取哺乳母猪RGB-D图像,距离地面高度为200 cm~230 cm。其中深度图像分辨率为512×424像素,用于网络模型的训练和测试。
1.2 深度图像数据预处理
Kinect2.0传感器拍摄的深度图像,用中值滤波器去除大量干扰噪声,用限制对比度自适应直方图均衡化[25]对深度图像进行增强,以提高对比度。此外,图像边缘角落存在白色空洞,而在自由栏猪舍中,母猪大部分时间靠墙活动,常会出现在图像的边缘区域,故难以用固定比例批量裁剪白色空洞区域。试验发现,保留图像边缘的白色空洞区域对本文的目标识别影响很小,因而不对其进行裁剪处理。
1.3 训练集和测试集准备
本文研究哺乳母猪 5类姿态的识别,姿态的定义见表1。图1为5种姿态对应的RGB图像、深度图像以及预处理后的深度图像,其中第一列和第五列为局部过亮及昏暗场景下的RGB-D图像,深度图像表现了较强的鲁棒性。
对采集的不同时段不同栏的RGB-D视频图像,为避免时序相关性,从每个姿态视频段中随机抽取一张深度图像,分别获取站立、坐立、俯卧、腹卧和侧卧姿态图像2 415、2 461、2 488、2 519和 2 658张。首先,手工标注母猪边界框和姿态类别。然后,从每类图像中随机选择1 000张,总计5 000张图像,作为测试集,用于模型性能评价。其余站立1 415、坐立1 461、俯卧1 488、腹卧1 519和侧卧1 658张,总计7 541张图像作为原始训练集。最后,对原始训练集的深度图像进行水平镜像、垂直镜像翻转以及顺时针90°、180°和270°旋转扩增,形成扩增后的训练样本集,共计45 246张图像。

表1 哺乳母猪五类姿态Table 1 Five postures of lactating sow

图 1 自由栏猪舍场景和哺乳母猪5类姿态图Fig.1 Scene of loose pig pen and five postures of lactating sow
2 哺乳母猪姿态识别模型
本文利用Faster R-CNN实现哺乳母猪目标的定位和5种姿态的分类。Faster R-CNN是由RPN网络[15]和Fast R-CNN检测网络融合后,共享了卷积层的多类目标检测算法,其框架如图 2所示。区域生成网络 RPN(region proposal networks)利用锚点(anchor)在单一尺度的特征图上,高效地生成多种尺度和多种长宽比的感兴趣区域。Fast R-CNN通过卷积和池化层提取每个感兴趣区域特征,并输入后续的全连接层,分别实现类别预测和位置回归。
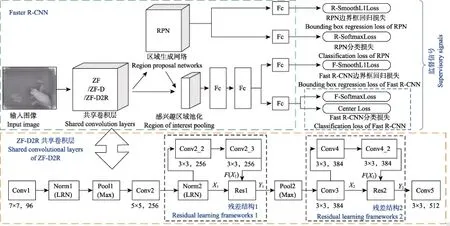
图2 改进的Faster R-CNN网络结构Fig.2 Improved Faster R-CNN network structure
为进一步提高Faster R-CNN的检测精度,一些更深层的网络 VGG[18]、GoogleNet[19]和 ResNet[20]等被作为基础网络。但深层网络多层的结构和大量的参数,会消耗过多的计算资源和存储资源,影响其实时性。为此,在母猪姿态识别实际应用中,需要设计同时能保证识别精度和识别速度的卷积网络结构。本文主要改进:1)将残差结构引入ZF网络[17],设计ZF-D2R网络,以便在获得更高识别精度同时保持识别的实时性;2)将Center Loss监督信号引入Faster R-CNN训练中,以增强类内特征的内聚性(intra-class compactness),提升识别精度。
2.1 网络结构改进
对CNN浅层网络堆叠卷积层,通常能提升图像识别精度[18]。但由网络深度增加带来的精度增益受限于网络结构、有限的数据集和反向传播训练算法等,甚至随着网络加深而快速衰减。深层CNN网络中残差结构的应用能在几乎不增加计算成本的条件下,有效缓解深层网络训练的梯度消失和训练退化的问题,从而提升网络收敛性能,提高识别精度[20]。为提高母猪姿态识别精度并保持实时性,本文以实时性较强的浅层网络——ZF网络为基础,引入残差结构,设计新的ZF-D2R(ZF with deeper layers and two residual learning frameworks)网络。残差结构函数公式

式中X为输入残差结构的卷积特征, ()FX 为被捷径连接(shortcut connections)跳过层的卷积特征输出,为残差结构的输出。如图2中的残差结构1和2所示。其中X与 ()FX 需满足输出特征维度大小相等,即两者输出特征图的通道数量与尺寸大小一致。
ZF-D2R网络结构设计如下(如图2的ZF-D2R共享卷积层所示):
1)ZF网络中Conv2和Conv4的通道数量分别为256和384,为满足残差结构中X与 ()FX 的设计条件并尽量少地增加卷积层,故在Conv2和Conv3之间增加卷积核大小为 3×3、输出通道为 256的卷积层 Conv2_2和Conv2_3,在Conv4和Conv5之间增加卷积核大小为3×3、输出通道为384的卷积层Conv4_2。相比其他尺寸的卷积核,3×3大小的卷积核具有参数少、速度快等优点,已广泛应用于各大主流CNN网络[17-20]。新加卷积层的步长设置为 1,并进行 1个像素边界的 0像素填充(zero-padding),以保持新加层卷积后输出特征图尺寸不变。
2)将Conv5层的通道数由256扩大为512,以向后传递更丰富的特征信息,形成 ZF-D(ZF with deeper layers)网络。
3)ZF-D网络中,Conv2_2和Conv2_3两个卷积层及Conv4和Conv4_2两个卷积层由捷径连接跳过构成残差结构,使得这两层在输入和输出之间进行残差学习,构成ZF-D2R网络。
2.2 引入Center Loss监督信号
在哺乳母猪深度图像中,由于母猪的非刚性形变,母猪 5类姿态,特别是坐立、俯卧和腹卧姿态深度图像特征类间差异不大,而类内差异相对较大,影响识别精度。Wen等[22]提出Center Loss监督信号,通过减小深层卷积特征与其对应类别中心的距离,提高了人脸识别精度。Faster R-CNN是将多类别目标检测任务转换为感兴趣区域生成及其分类任务,即 Fast R-CNN检测器利用softmax对RPN生成感兴趣区域特征进行分类,实现多目标检测。如图2所示,本文引入Center Loss监督信号,将其与Fast R-CNN的F-SoftmaxLoss监督信号联合构建分类损失函数,并通过联合训练来减小RPN生成的感兴趣区域特征与其对应类别特征中心的距离,增大类间的特征差异,加强类内特征内聚性,降低不同姿态之间特征相近带来的错误识别。联合分类损失函数
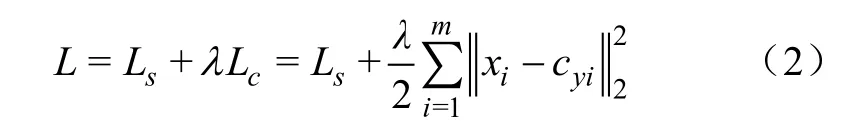
式中Ls为F-SoftmaxLoss函数,Lc为Center Loss函数,由于 Lc的值远大于Ls的值,故用参数λ平衡2个损失函数,试验中设置为0.01。 xi∈ Rd表示第 yi类的第i个感兴趣区域的特征, m为训练过程中小批量(mini-batch)数据的数量, cyi∈ Rd表示第 yi类的特征的中心。
特征中心cyi由RPN生成的感兴趣区域的第 yi类特征的均值计算获得。在每小批量数据训练中,特征中心cyi仅更新一次。为避免由少量错误感兴趣区域特征给cyi带来的较大波动,使用标量权值参数 α ∈ [0 ,1]控制 cyi的学习率进行更新,试验中固定α=0.5。更新公式

式中 t表示为第 t次迭代,同时当条件(yi=j)成立时δ(yi=j ) = 1,否则δ(yi=j)=0, cj表示第j类的特征中心。
由于 CNN的训练过程是一个损失函数的最优化过程。故Center Loss函数(≥0)的值将随着网络的训练逐渐减小,即特征xi的分布将逐渐接近特征中心cyi。因此,随着不断的迭代训练,每一类特征的分布向其对应的特征中心聚集,从而增加了类内特征的内聚性,扩大了类间特征的差异性,有益于分类器正确分类。
引入Center Loss后,Faster R-CNN在端对端(end-toend)的训练中,对于 RPN,用分类损失函数(R-SoftmaxLoss)指导判断生成框是否包含目标物体,用回归损失函数(R-SmoothL1Loss)[15]指导回归微调生成框,以生成感兴趣区域;对于Fast R-CNN检测器,以F-SoftmaxLoss与Center Loss联合的分类损失函数来指导网络训练,对生成的感兴趣区域进行 5类姿态的分类判断,回归损失函数(F-SmoothL1Loss)[16]则指导网络训练对每一个感兴趣区域进行回归微调,如图2监督信号所示。
3 母猪姿态识别试验
3.1 试验平台
试验采用 32 GB内存、Nvidia GTX980Ti型号的GPU、Intel Xeon E3-1246v3型号 CPU的硬件平台和Ubuntu14.04操作系统。在Caffe深度学习框架[26]上,采用Python作为编程语言实现本文改进的Faster R-CNN算法。
3.2 模型训练
本文使用小批量的随机梯度下降法,对Faster R-CNN以端对端的联合方式进行训练,该训练方式比分别训练RPN和Fast R-CNN 2个网络的4步训练法节约25%~50%训练时间,而 2种训练方式结果相近[15]。设置mini-batch大小为256,冲量为0.9,权值的衰减系数为5–4,最大迭代次数为 8×105次,其中前 5×105次学习率为10–4,后 3×105次学习率为 10–5。在 5×105次迭代后,每隔1×105次保存一个模型,最终选取精度最高的模型。在模型的初始化中,对共享的卷积层以 Xavier[27]进行随机初始化,而RPN特有的卷积层以及网络中的全连接层则以0均值、标准差为0.01的高斯分布随机初始化。对RPN网络,在每个滑动窗口位置,分别取3种面积尺度{962, 1922, 3842}及3种长宽比{1∶1, 1∶3, 3∶1}的9个锚点,以实现母猪多方向和多尺度的姿态识别。
4 结果与分析
4.1 改进模型的识别结果分析
表2为不同基础网络的Faster R-CNN模型以及其他方法的识别性能对比,本文提出的方法(ZF-D2R+Center Loss),对站立、坐立、俯卧、腹卧和侧卧5类姿态的平均准确率(average precision,AP)分别达到 96.73%、94.62%、86.28% 、89.57%和99.04%,5类姿态的平均准确率均值(mean average precision,mAP)达到93.25%,识别速度达则到0.058 s/帧,具有较高的识别精度和较强的实时性。识别结果图3和表2表明:1)获得精准目标边界框和类别标签;2)场景中热灯光线干扰的影响较低;3)可实现夜间昏暗光线场景下母猪姿态的识别;4)克服了场景中仔猪活动的影响;5)俯卧和腹卧2种姿态识别率较低。上述5点的原因在于:1)在夜间昏暗光线及热灯光线干扰场景下,深度图像质量几乎不受光线影响,为母猪姿态识别提供了对光线具有较强鲁棒性的图像数据;2)本文改进的Faster R-CNN,在融合RPN网络和Fast R-CNN检测基础上,改进了基础网络结构和引入了训练监督信号,可实现高精度的母猪多姿态的在线识别。3)Kinect2.0传感器拍摄的深度图像分辨率较低,可能导致俯卧和腹卧2种姿态差异的细节信息缺乏,影响了这2种姿态的识别率。
表3为ZF-D2R+Center Loss的Faster R-CNN模型的分类混淆矩阵,姿态间的错误分类较多发生在俯卧和腹卧之间,而站立、坐立和侧卧这 3类卧姿仅有较少的错误分类,整体分类精确度较高,表明本文提出的方法对该5种母猪姿态有较强的分类能力。

图3 ZF-D2R+Center Loss的Faster R-CNN模型的哺乳母猪姿态识别结果Fig.3 Recognition results of Faster R-CNN model with ZF-D2R+Center Loss for lactating sow postures
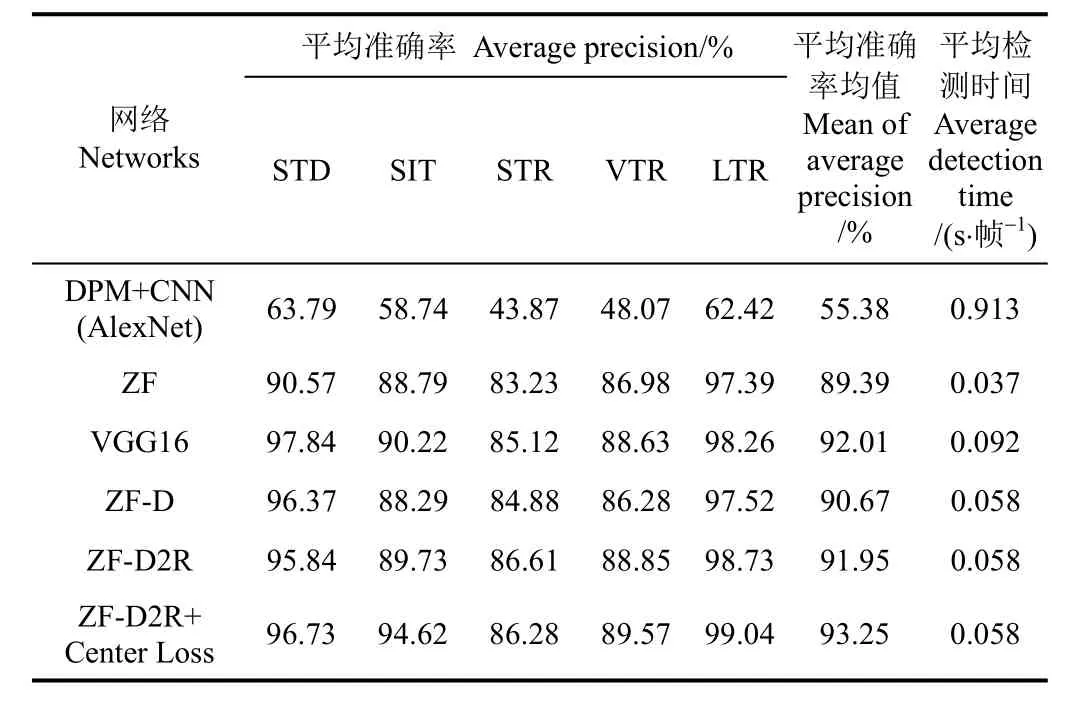
表2 不同基础网络的Faster R-CNN模型及其他方法的识别性能对比Table 2 Comparison of recognition performance of Faster R-CNN models with different basic network and other method
4.2 堆叠网络深度对模型识别精度和速度的影响
表2中ZF模型(5层卷积层)和VGG16模型(13层卷积层)的mAP分别为89.39%和92.01%。所提出的含8层卷积的ZF-D网络模型mAP达到90.67%,相比于ZF模型提高了1.28个百分点。这主要因为在CNN图像识别任务中,往往越深的网络越能训练获得更强表征力的特征,从而获得更高的识别精度,但这种精度的提高是有限的。ZF-D模型速度为0.058 s/帧,虽然慢于ZF模型,但比VGG16模型快,保持了实时性。
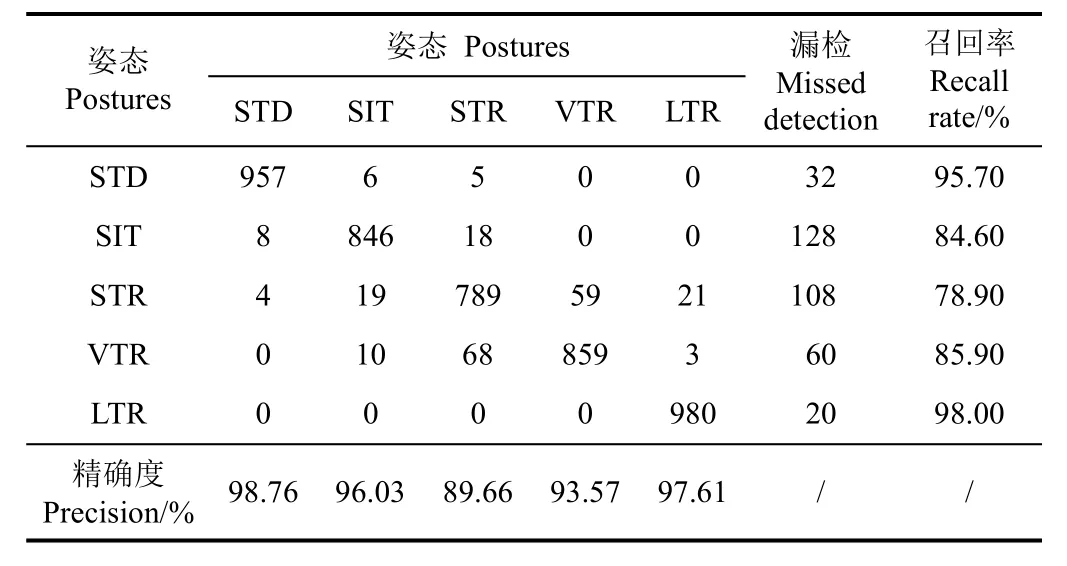
表3 ZF-D2R+Center Loss的Faster R-CNN模型分类混淆矩阵Table 3 Classified confusion matrix of Faster R-CNN model with ZF-D2R+Center Loss
4.3 残差结构对模型识别精度和速度的影响
ZF-D2R网络是对ZF-D增加2个残差结构构建的,mAP达到91.95%,比ZF-D模型和ZF模型分别提高1.28和2.56个百分点,已接近 VGG16模型的精度。这是由于,通过对堆叠的卷积层增加残差结构能有效激发深层网络的收敛性能,从而获得更好的识别精度。在识别速度上,对比ZF-D,残差结构的增加几乎不增加新的时间代价,仍为 0.058 s/帧,比 VGG16模型识别速度快了0.034 s/帧。由于残差结构并不增加模型参数,故几乎不增加计算代价。
4.4 Center Loss对模型的影响
将测试集图像分别送入 ZF-D2R网络和 ZF-D2R+Center Loss网络,提取每张图像在这2个网络的Fc7层的特征向量,每类姿态构成1个特征向量集。对5个姿态的 5个特征向量集使用标准欧氏距离进行统计分析。表4为 ZF-D2R与ZF-D2R+Center Loss的Faster R-CNN模型特征的平均标准欧氏距离对比,主对角线上为类内距离,其他为类间距离。结果表明,网络中加入CenterLoss后类内的平均标准欧氏距离略微减小,即类内特征的内聚性略微提升。而类间特征的距离明显扩大,表明类间特征差异性扩大。
如表2所示,引入Center Loss监督信号后,模型的mAP达到93.25%,带来1.3个百分点的提升。对站立、坐立、腹卧和侧卧姿态,AP分别提高了0.89、4.89、0.72和0.31个百分点。这是因为Center Loss增强了模型提取5类姿态图像类内特征的内聚性,使得分类器更容易区分不同类别,进而使模型精度获得提升。该模型识别精度比经典的ZF模型提升了3.86个百分点,比VGG16模型提升了1.24个百分点,表现出更佳的性能。在识别速度上,仅为0.058 s/帧,较ZF模型检测速度降低0.021 s/帧,但比VGG16模型提升0.034 s/帧,保持了实时性。

表4 ZF-D2R与ZF-D2R+Center Loss的Faster R-CNN模型特征的平均标准欧氏距离对比Table 4 Faster R-CNN models with ZF-D2R and ZF-D2R+Center Loss are compared with the average standard euclidean distance of features
4.5 与其他方法比较
如表2中所示,本文方法(ZF-D2R+Center Loss)与用可变形部件模型(deformable part model, DPM)[28]检测母猪获得母猪位置和边界框、CNN(AlexNet[29])模型进行姿态分类的方法(DPM+CNN(AlexNet))相比,mAP高出37.87个百分点,运行时间减少了0.855 s/帧。原因在于:1)HOG(histogram of oriented gradient)即梯度方向直方图,提取的是目标的边缘信息特征,且不具备旋转不变性,故仅基于HOG特征的DPM目标检测算法,对姿态多变、身躯非刚性的母猪难以获得高精度的目标检测,且 DPM检测时间消耗大;2)由于母猪活动的多样性,检测获得的母猪边界框是多尺寸和多方向的,而缺少空间金字塔池化层[30]的AlexNet,无法有效处理尺寸和方向均有较大差异的图像(将尺度归一化),故难以获得高精度的姿态分类。
5 结 论
本文提出了适应于猪舍场景下 24 h全天候的改进Faster R-CNN的母猪姿态识别方法。
1)采用深度图像作为哺乳母猪姿态识别的研究材料,克服了环境光线变化影响识别性能的问题,使得24 h的识别应用成为可能。
2)通过在ZF网络中引入残差结构、在Faster R-CNN中引入Center Loss监督信号,在识别精度mAP(mean of average precision)上,本文提出的方法超过ZF模型3.86个百分点,也超过网络结构更深的VGG16模型1.24个百分点。在识别速度上,本文方法在保证较高精度的同时确保实时性。
3)相比DPM(deformable part model)母猪检测且用CNN姿态分类方法,本文端对端的识别方法mAP提高了37.87个百分点,速度提高了0.855 s/帧。
本文研究可为哺乳母猪姿态及行为自动识别提供方法和思路,为后续针对连续视频帧的母猪动态行为分析打下了基础。尽管本文提出的方法获得了性能上的进步,但仍存在:1)模型仍然庞大,压缩模型将更有利于对嵌入式系统的迁移部署;2)识别精度有待进一步提高。白天光线条件好时,考虑融合RGB图像特征来提高识别精度,这是后续研究工作。
[参 考 文 献]
[1] 闫丽,沈明霞,谢秋菊,等. 哺乳母猪高危动作识别方法研究[J]. 农业机械学报,2016,47(1):266-272.Yan Li, Shen Mingxia, Xie Qiuju, et al. Research on recognition method of lactating sows’ dangerous body movement[J]. Transactions of the Chinese Society for Agricultural Machinery, 2016, 47(1): 266-272. (in Chinese with English abstract)
[2] Oczak M, Maschat K, Berckmans D, et al. Classification of nest-building behaviour in non-crated farrowing sows on the basis of accelerometer data[J]. Biosystems Engineering, 2015,140: 48-58.
[3] Nasirahmadi A, Edwards S A, Sturm B. Implementation of machine vision for detecting behaviour of cattle and pigs[J].Livestock Science, 2017, 202: 25-38.
[4] Lao F, Brown-Brandl T, Stinn J P, et al. Automatic recognition of lactating sow behaviors through depth image processing[J]. Computers & Electronics in Agriculture, 2016,125: 56-62.
[5] Kashiha M, Bahr C, Haredasht S A, et al. The automatic monitoring of pigs water use by cameras[J]. Computers &Electronics in Agriculture, 2013 (90): 164-169.
[6] Nasirahmadi A, Edwards S, Richter U, et al. Automatic detection of changes in group pig lying behaviour using image analysis[C]// Asabe International Meeting, 2015, 47(1):51-52.
[7] Nasirahmadi A, Richter U, Hensel O, et al. Using machine vision for investigation of changes in pig group lying patterns[J]. Computers & Electronics in Agriculture, 2015,119: 184-190.
[8] Nasirahmadi A, Hensel O, Edwards S A, et al. Automatic detection of mounting behaviours among pigs using image analysis[J]. Computers & Electronics in Agriculture, 2016,124: 295-302.
[9] 刘龙申,沈明霞,柏广宇,等. 基于机器视觉的母猪分娩检测方法研究[J]. 农业机械学报,2014,45(3):237-242.Liu Longshen, Shen Mingxia, Bo Guangyu, et al. Sows parturition detection method based on machine vision[J].Transactions of the Chinese Society for Agricultural Machinery, 2014, 45(3): 237-242. (in Chinese with English abstract)
[10] Kashiha M A, Bahr C, Ott S, et al. Automatic monitoring of pig locomotion using image analysis[J]. Livestock Science,2014, 159(1): 141-148.
[11] 刘波,朱伟兴,杨建军,等. 基于深度图像和生猪骨架端点分析的生猪步频特征提取[J]. 农业工程学报,2014,30(10):131-137.Liu Bo, Zhu Weixing, Yang Jianjun, et al. Extracting of pig gait frequency feature based on depth image and pig skeleton endpoints analysis[J]. Transactions of The Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2014,30(10): 131-137. (in Chinese with English abstract)
[12] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature,2015, 521(7553): 436-444.
[13] Redmon J, Divvala S, Girshick R, et al. You only look once:Unified, real-time object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779-788.
[14] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[J]. Computer Science, 2013: 580-587.
[15] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis &Machine Intelligence,2015, 39(6): 1137‒1149.
[16] Girshick Ross. Fast R-CNN[C]//IEEE International Conference on Computer Vision. IEEE Computer Society, 2015:1440-1448.
[17] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[J]. Computer Science, 2014, 8689:818-833.
[18] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014: 1-14.
[19] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2015: 1-9.
[20] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016: 770-778.
[21] Huang Gao, Liu Zhuang, Weinberger K Q, et al. Densely connected convolutional networks[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2017.
[22] Wen Yandong, Zhang Kaipeng, Li Zhifeng, et al. A discriminative feature learning approach for deep face recognition[C]//European Conference on Computer Vision.Springer International Publishing, 2016: 499-512.
[23] Xiao Jimin, Xie Yanchun, Tillo T, et al. IAN: The individual aggregation network for person search[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[24] Lou Zhensheng, Hurnik J Frank. Peripartum sows in three farrowing crates: Posture patterns and behavioural activities[J]. Applied Animal Behaviour Science, 1998,58(1/2): 77-86.
[25] Zuiderveld K. Contrast limited ldaptive histogram equalization[J]. Graphics Gems, 1994: 474-485.
[26] Jia Yangqing, Shelhamer E, Donahue J, et al. Caffe:Convolutional architecture for fast feature embedding[J].Computer Science, 2014: 675-678.
[27] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[J]. Journal of Machine Learning Research, 2010, 9: 249-256.
[28] Felzenszwalb P F, Girshick R B, Mcallester D, et al. Object detection with discriminatively trained part-based models[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2010, 32(9): 1627-1645.
[29] Krizhevsky A, Sutskever I, Hinton Geoffrey E. ImageNet classification with deep convolutional neural networks[J].Communications of the ACM, 2012, 60(2): 1097-1105.
[30] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis &Machine Intelligence, 2015, 37(9): 1904-1916.
