基于频率敏感三维自组织映射的立体视频视差估计算法
2018-05-30程福林黎洪松
任 云,程福林,黎洪松
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
0 概述
传统视差估计算法有2种思路[1-2],一种是基于区域,另一种是基于特征。前者的基本思想是以图像中的某点或某块作为一个单位,在参考图像中搜索与其相对应的点或块,从而得到各个点或各个块的视差,利用这种算法计算得到的视差估计都非常集中、稠密。根据选取的不同的匹配策略,基于区域的视差估计还可以分为[3]局部法[4-6]及全局法[7-8]。代表性的局部法是基于块[9-10]的算法,实现复杂度低,有广泛的应用。典型的全局算法有动态规划法、图割法[11]和置信度传播法等[12-13],均可得到较好的估计效果,但由于其计算复杂,因此硬件难以实现。基于特征的视差估计[14-16]的基本原理是匹配图像自身的特征,一般其特征提取过程都比较复杂,且只能得到稀疏的视差估计。
三维自组织映射算法[17]模拟人脑对特定现象兴奋的特征,在许多方面得到了应用,特别在模式识别[18]、数据挖掘等领域更是发挥了不容忽视的作用[19-21],是一种高效的数据聚类算法。
本文提出一种基于频率敏感三维自组织映射的视差估计算法(Frequency Sensitive-3DSOM-DPR,FS-3DSOM-DPR)。将输入视差图像进行分类,即低亮度区域、高亮度区域,分别对这2个区域进行训练,得到高低亮度2个模式库,最后在编码时将训练图像区域根据一定的阈值决定用哪个模式库进行预测。在训练模式库的过程中引入频率敏感算法,从而减少模式库中的无效模式。
1 基于模式识别的立体视频视差编码方案
图1给出了FS-3DSOM-DPR视差编码方案的框图。
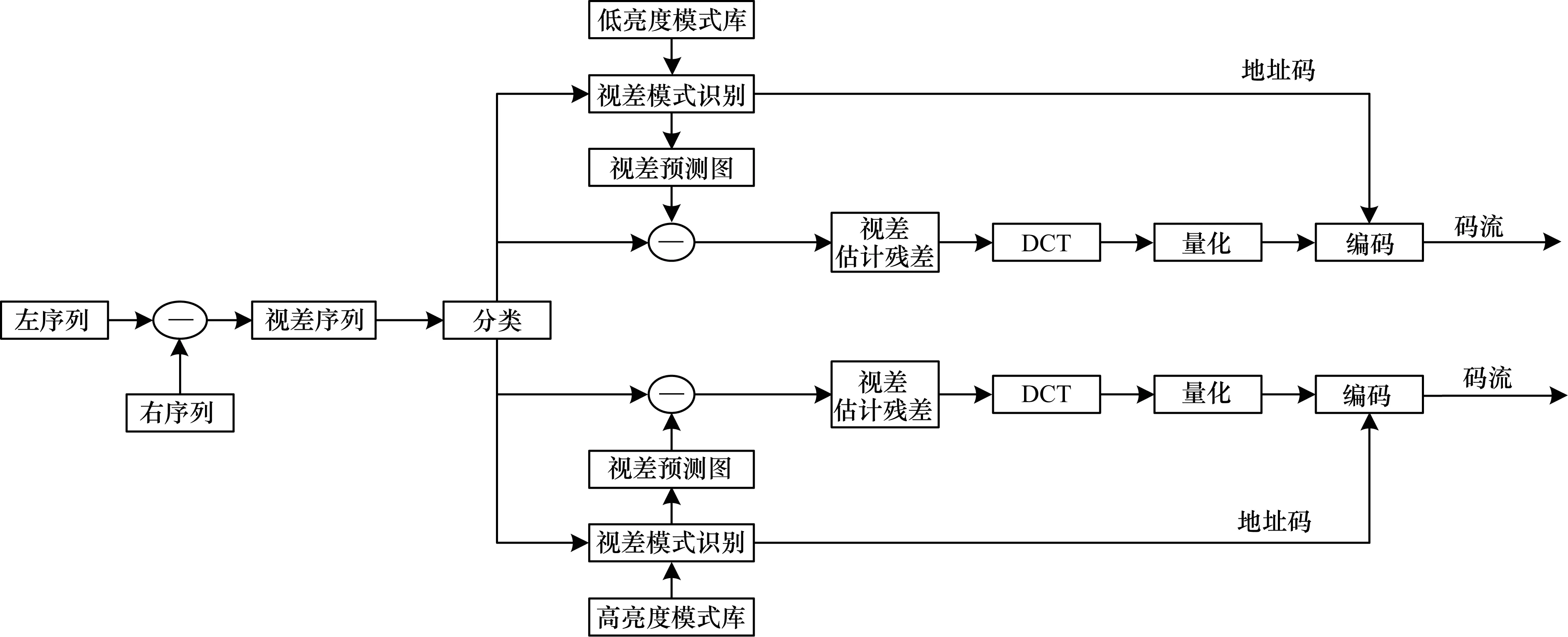
图1 FS-3DSOM-DPR视差编码方案
其编码步骤如下:
步骤1对立体视频视差序列每帧分块(一般取8×8或16×16),并对每帧取亮度均值,将均值中间值看作是分类阈值,将均值大的块归类于高亮度块,将均值小的块归类于低亮度块,最后形成高低亮度两个集合。
步骤2采用FS-3DSOM算法对步骤1所得到的高低亮度2个集合进行学习训练若干次,最后形成最优的高亮度模式库,以及低亮度模式库。
步骤3输入训练序列,并将每帧按照8×8或16×16的模板划分为块,计算得到每块所对应的方差值。用以上步骤得到的阈值与之相较,给每块划类,并选择相应的模式库,运用FS-3DSOM算法对输入模式矢量进行视差模式识别,最终获得其所对应的预测模式矢量。
步骤4将预测模式矢量与原模式矢量作差,得到视差估计残差。
步骤5最后对视差估计残差进行DCT变换,将主要图像信息集中于几个参数上。对变换参数再进行量化,将其进一步进行压缩,最后进行编码形成码流。
步骤6转到步骤3,直至对所有的视差块进行预测编码。
2 FS-3DSOM算法
2.1 频率敏感三维自组织映射算法
传统SOM算法具有一个很大的问题,即在模式库训练过程中每个模式都有可能被调整,但其概率确实不一样的。而最佳模式库要求初始模式库中的每个模式都能得到充分利用,都能以更为合理的概率进行调整,也就是要求每个模式都能自适应信源的输入模式矢量。综上所述,有必要在训练过程中进行人为调节。
针对传统SOM算法存在的不足,本文采用了频率敏感三维自组织映射(FS-3DSOM)算法。记录模式响应次数,引入参数,人为降低响应次数多的模式下一次响应的概率。
基于FS-3DSOM算法的模式库训练步骤如下:
对比两组患者在经过治疗后的临床效果并计算有效率,有效率等于显效人数与有效人数之和与总人数的百分比(评判标准:显效:患者的临床症状明显减轻,病情保持稳定;有效:临床症状有所减轻;无效:临床症状无明显变化甚至症状加重,病情反复不定)。
1)设置自组织特征映射网络的规格为向量(N,M),其中前者为模式库的大小,后者为组成模式库的模式矢量的大小。
2)将视差图划分为矩阵M=8×8大小的图像块,一个图像块称为一个训练矢量,划分后可得到矢量L个训练矢量{X(t),t=0,1,…,L-1}。设置初始化模式库为向量{Wj(0),j=0,1,…,N-1},并将模式矢量排列成的三维立体结构。
3)初始化邻域函数为矢量Nj(0),j=0,1,…,N-1,初始化响应计数器为矢量cj=1,其中,j=0,1,…,N-1。
4)输入训练矢量集{X(t),t=0,1,…,L-1}。
6)以下式为调整公式,调整获胜矢量及其周围邻域的权值:
(1)
其中,矢量Nj*(t)一般取Nj*(t)=A0+A1e-t/T1。A0为初始邻域值,一般取0,A1是邻域所能取的最大值。T1是邻域衰减常数。在训练初期,矢量Nj*(t)取的是A1,但随着训练的推进,邻域慢慢变小。矢量α(cj)=A2e-cj/T2代表的是学习速度函数,A2为初始学习速度,也就是学习速度的最大值,T2代表的是学习衰减函数。
2.2 分类模式库
在训练模式库时,之所以会产生无效模式,是因为差别大的训练模式会给予对方负面影响。比如说高亮度区域的模式与低亮度区域的模式就会相互影响。针对该问题,在模式库训练时,首先利用均值将训练矢量集分为高亮度区域和低亮度区域,分别训练模式库,以保证SOM算法在2个区域上的聚类性能。模式库分类步骤如下:
步骤1将输入的视差图分割为8×8大小的子块,则可分成L块,构成训练矢量集{X(t),t=0,1,…,L-1}。

(2)
进行分类。Th为选定的阈值,它取自所有模式块均方差的中间值,X1代表的是高亮度训练矢量集,X2代表的是低亮度训练矢量集。
步骤3利用FS-3DSOM算法分别对上述2个矢量集进行训练,最后得到所需的高亮度模式库,以及低亮度模式库。
3 实验结果
实验采用标准立体视频测试序列Exit、Vassar的第1、2视点,每个视点再各分解为8帧,共16帧,图像分辨率480像素×640像素。本文实验中对重建图像质量的评价采用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR):
其中,EMSE为原图像与重建图像的均方误差。3DSOM-DPR算法中,图像压缩比为:
其中,矩阵M代表的是模式矢量的维数大小,B0是编码每个像素所需要的比特数,M×B0是编码整幅原图像所需要的比特数,BC代表的是输出的模式矢量地址比特数。实验中矩阵M取8×8,模式库大小为2 048,CR为46.5。在基于块的视差估计算法中,模式矢量维数大小,即块的大小M设置为8×8,另外横向搜索范围设置为[-31,32],纵向搜索范围设置为[-15,16],可实现的压缩率为46.5。
图2给出了FS-3DSOM-DPR算法与基于块的算法的视差预测图像的峰值信噪比分布情况,且采用FS-3DSOM-DPR算法得出的视差预测图像的平均峰值信噪比为34.612 2 dB,采用基于块的算法得出的视差预测图像的平均峰值信噪比为32.824 4 dB,即采用本文算法比原始算法得出的预测图像峰值信噪比提高了1.78 dB。
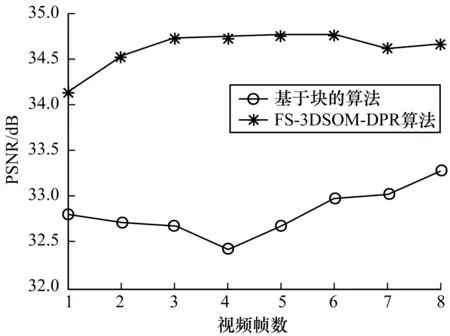
图2 视差预测图像的峰值信噪比分布情况
4 结束语
本文提出一种基于频率敏感三维自组织映射的视差估计算法。视差编码采用基于分类频率敏感三维自组织映射的视差模式识别(FS-3DSOM-DPR)算法,以取代传统基于块的视差估计算法。实验结果表明,该算法视差预测图像的平均峰值信噪比比基于块的算法提高了1.78 dB。下一步的工作是将该算法应用于立体视频编码中,结合实例进行更加深入的研究。
[1] POLLEFEYS M,VAN G L,VERGAUWEN M,et al.Visual modeling with a hand-held camera[J].International Journal of Computer Vision,2004,59(3):207-232.
[2] BROWN M Z,BURSCHKA D,HAGER G D.Advances in computational stereo[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2003,25(8):993-1008.
[3] SCHARSTEIN D,SZELISKI R.A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J].International Journal of Computer Vision,2002,47(1):7-42.
[4] YOON K J,KWEON I S.Adaptive support-weight approach for correspondence search[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2006,28(4):650-656.
[5] HOSNI A,BLEYER M,GELAUTZ M,et al.Local stereo matching using geodesic support weights[C]//Proceedings of IEEE International Conference on Image Processing.Washington D.C.,USA:IEEE Press,2010:2093-2096.
[6] WEI Y,QUAN L.Region-based progressive stereo matching[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2004:106-113.
[7] HONG L,CHEN G.Segment-based stereo matching using graph cuts[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2004:74-81.
[8] SUN J,SHUM H Y,ZHENG N N.Stereo matching using belief propagation[C]//Proceedings of European Conference on Computer Vision.Berlin,Germany:Springer-Verlag,2002:510-524.
[9] HAUBLEIN K,REICHENBACH M,FEY D.Fast and generic hardware architecture for stereo block matching applications on embedded systems[C]//Proceedings of International Conference on Reconfigurable Computing and FPGAs.Washington D.C.,USA:IEEE Press,2014:1-6.
[10] SAHLBACH H,ERNST R,WONNEBERGER S,et al.Exploration of FPGA-based dense block matching for motion estimation and stereo vision on a single chip[C]//Proceedings of IEEE Intelligent Vehicles Symposium.Washington D.C.,USA:IEEE Press,2013:823-828.
[11] WANG Y C,TUNG C P,CHUNG P C.Efficient disparity estimation using hierarchical bilateral disparity structure based graph cut algorithm with a foreground boundary refinement mechanism[J].IEEE Transactions on Circuits & Systems for Video Technology,2013,23(5):784-801.
[12] 赵 戈,蔺 蘭,唐延东,等.一种基于曲率与置信度传播的视差估计方法[J].模式识别与人工智能,2013(12):1154-1160.
[13] 刘 欣.基于立体视觉的公交客流统计方法与实现[D].秦皇岛:燕山大学,2013.
[14] PODDAR S,SAHU H,BANGALE M R,et al.Feature based dense disparity estimation[C]//Proceedings of IEEE International Conference on Industrial Instrumentation and Control.Washington D.C.,USA:IEEE Press,2015:950-955.
[15] KAMENCAY P,BREZNAN M,JELSOVKA D,et al.Sparse disparity map computation from stereo-view images using segment based algorithm[C]//Proceedings of the 22nd International Conference Radioelektronika.Washington D.C.,USA:IEEE Press,2012:1-4.
[16] RAMAN S,KANOJIA G,KANOJIA G,et al.Facial stereo:facial depth estimation from a stereo pair[C]//Proceedings of International Conference on Computer Vision Theory and Applications.Washington D.C.,USA:IEEE Press,2014:686-691.
[17] KOHONEN T.Essentials of the self-organizing map[J].Neural Networks,2013,37:52-65.
[18] LI N,CHENG X,ZHANG S,et al.Realistic human-action recognition by fast HOG3D and self-organization feature map[J].Machine Vision and Applications,2014,25(7):1793-1812.
[19] KAMAL S,MUJEEB A,SUPRIYA M H.Novel class detection of underwater targets using self-organizing neural networks[C]//Proceedings of Underwater Technology (UT),2015 IEEE.Washington D.C.,USA:IEEE Press,2015:1-5.
[20] PARK S,RYU S,CHOI Y,et al.A framework for baseline load estimation in demand response:data mining approach[C]//Proceedings of IEEE International Conference on Smart Grid Communications.Washington D.C.,USA:IEEE Press,2014:638-643.
[21] MCLOUGHLIN F,DUFFY A,CONLON M.A clustering approach to domestic electricity load profile characterisation using smart metering data[J].Applied Energy,2015,141:190-199.
