利用K-SVD去噪提高车辆检测率的方法∗
2018-05-29张尤赛王亚军
周 旭 张尤赛 王亚军
(江苏科技大学电子与信息学院 镇江 212003)
1 引言
实时交通检测是智能交通系统[1]中的重要环节,而基于视频图像的车辆检测[2]则是实时交通检测环节重点研究的技术。基于视频图像的车辆检测技术是建立在对视频图像信息提取的基础上所做的研究。然而由于受到外部条件的影响,视频图像的获取和传输过程中不可避免地混入各种噪声,给视频图像的分析带来不利影响。为此,去噪成为车辆检测过程中的一个重要步骤。
监控视频在获取和传输过程中产生的噪声主要是由椒盐噪声和高斯噪声组成。目前车辆检测技术中最常用的去噪方法主要有中值滤波[3]、维纳滤波和小波去噪等。中值滤波对椒盐噪声有很好的去除性能,但对于幅值近似正态分布的高斯噪声,去噪效果较差。维纳滤波[4]是一种能够使原始图像和其恢复图像之间的均方误差最小的一种复原图像的方法。能够较好恢复含有高斯噪声的图像,但是很难处理非平稳的随机的噪声比如椒盐噪声。小波去噪[5]对于椒盐和高斯两种噪声都能较好的去处,但是小波去噪认为噪声能量主要集中在高频区间,而重要的图像信息主要分布在低频区间内,忽略了高频区间除了噪声,还分布了图像边缘、细节、纹理特征等很多重要的信息,因此在滤除高频信息的同时难免不伤害到这些有用信息;另外,噪声在低频也有一定的分布,简单地滤除高频成分无法去除这部分噪声分量。基于稀疏表示[6~7]的图像去噪,主要是根据干净的图像信号具有结构性和原子性,而噪声是随机的,不相关的不具备结构性这一区别,利用正交匹配追踪算法[8](Orthogonal Matching Pursuit,OMP)将图像在过完备字典上进行稀疏分解,再根据数据在字典上是否具有稀疏表示,将图像信息与噪声区分,完成去噪。图像的稀疏表示,研究的着重点是字典的设计。2006年,Aharon[9]等利用 K-奇异值分解(K-Singular Value Decomposition,K-SVD)算法来完成字典更新,取得较好的去噪效果。通过对过完备稀疏表示的研究,K-SVD算法依据误差最小化的原则,对误差项SVD分解,经过不断迭代得到最优解。误差越小,越能更好地保留图像信息。
含有较多噪声的交通视频,常用的去噪方式已经不能满足对车辆检测准确率的要求。因此本文提出了一种利用K-SVD去噪算法来提高车辆检测率的方法,并应用于光流法、帧差法和背景差分法等三种车辆检测算法中,通过与中值滤波、维纳滤波和基于小波的滤波方法的性能比较,证明了该方法在视频图像去噪、保留图像信息和提高车辆检测率方面都具有更优的性能。
2 稀疏表示的图像去噪
2.1 图像的稀疏表示
首先建立噪声图像的数学模型:

式中x为干净图像,H为噪声,Φ为含噪图像。
图像稀疏模型可以表示为

式中 D为字典(D∈RN*L),当 N<<L时 D为过完备字典,di为原子,α表示图像的分解系数。
当系数向量α中非零向量最少时,可将式(2)转为式(3),将式(3)再转为式(4),转化的本质就是转为稀疏逼近问题求近似解:

或

式中‖‖0表示l0范数,用来计算矩阵中的非零元素。
通过对图像稀疏表示以及噪声图像模型的描述,可以得到噪声图像的稀疏表示模型:

根据贝叶斯最大后验估计,可建立 α̂模型:

而去噪后的图像为 x̂=Dα̂。
利用拉格朗日乘子法,将约束项转为惩罚项:

式中,μ为拉格朗日乘子也称为惩罚因子,用来平衡保真项和稀疏先验项。在合适的 μ下,(6)、(7)两式是可以等价转换的。
2.2 K-SVD去噪算法
K-SVD算法是一种经典的字典训练算法,依据误差最小的原则,对误差项进行奇异值分解(Singular Value Decomposition,SVD),选择使误差最小的分解项作为更新的字典原子和对应的原子系数,经过不断的迭代从而得到优化的字典D。
将图像x拆分,差分后的图像仍满足上述系数模型,将式(7)转为

式中:Qij是用于提取图像块取样的矩阵。
对于式(8),倘若字典D已知,式中所包含的稀疏系数α̂ij和图像x都是未知量。初始化x=Φ,利用正交匹配追踪算法,针对提取出来的大量图像块,分别求解如下模型,得到图像块的稀疏表示:

得到每一个图像块对应的稀疏系数α̂ij。再在得到稀疏系数α̂ij的基础上用K-SVD算法更新字典D;最后,当稀疏系数α̂ij和字典D满足要求,根据式(8)就可以得到求解原始图像x̂的模型:

然而,从式(9)、(10)可以看到,K-SVD 算法是基于重建误差平方和作为保真项求解,可以使误差降到最小,能够更好地保留图像的特征信息。
3 车辆检测的算法
目前常用的基于视频的车辆检测方法主要划分为两类:基于运动信息的车辆检测和基于特征信息的车辆检测。其中,光流法、帧差法和背景差分法是基于运动信息的车辆检测方法中最具代表性的三种方法,本文将K-SVD去噪算法应用于上述三种检测方法来检测算法的改进性能。
3.1 车辆检测基本算法对噪声的鲁棒性
基于视频的车辆检测的最终目的是检测出视频中的车辆,因此车辆检测算法的选择尤为关键。因此需对三种基本算法对噪声的鲁棒性做分析。
光流法的基本思想是:基于当前帧图像与其前后帧图像的信息,把图像中的每一个像素点赋予一个速度矢量,建立图像的二维运动场。通过判断图像中像素点的光流矢量达到运动目标检测的目的。因此,光流法适合做精确分析,可解决检测时出现遮挡,重叠的问题。但是算法运算量大,难以满足实时性要求,同时由于采用假设的局限性使得光流法对噪声特别敏感,容易发生错检。
帧差法的基本思想是:在视频序列图像中如果一个物体发生位移变化,那么它所在区域对应像素点的灰度值将会产生显著变化;在其它没有运动物体目标的图像区域中,像素点的灰度值则不会产生显著变化。因此将视频的前帧与后帧相减的值,就是运动目标的区域。因此,帧差法复杂度低,计算量小,实时性较高,且不惧光照的变化和背景的干扰。但是由于噪声的干扰,易将噪声点误为运动目标的像素点提取,并遗漏正确的目标像素点,造成车辆的错检和漏检。
背景差分法的基本思想是:用当前帧减去实时更新的背景模型,通过相减后图像的像素值与设定的阈值判断该像素点是否为运动目标的区域。算法复杂度较低且易于实现,重点是建立及时更新的背景模型。但是,因为在噪声干扰下,很难得到干净的背景模型,势必影响运动区域的判断。
三种基本的车辆检测算法,噪声对其检测率都有较大的影响,因此,去噪方式的选择对车辆检测率有着较大的影响。
3.2 四种去噪方法在车辆检测算法上的应用
针对目前常用的中值滤波、维纳滤波和小波去噪的局限性,凸显本文提出的K-SVD去噪的性能优势。
本文的算法步骤如下:
1)对同一张图片加入噪声(不同σ高斯噪声、椒盐噪声、不同σ的高斯和椒盐的混合噪声),用四种不同算法去噪,对比去噪后的视觉效果和信噪比。
2)四种去噪算法在三种基本车辆检测算法上的应用,并统计检测率,其算法的框架图如图1所示。
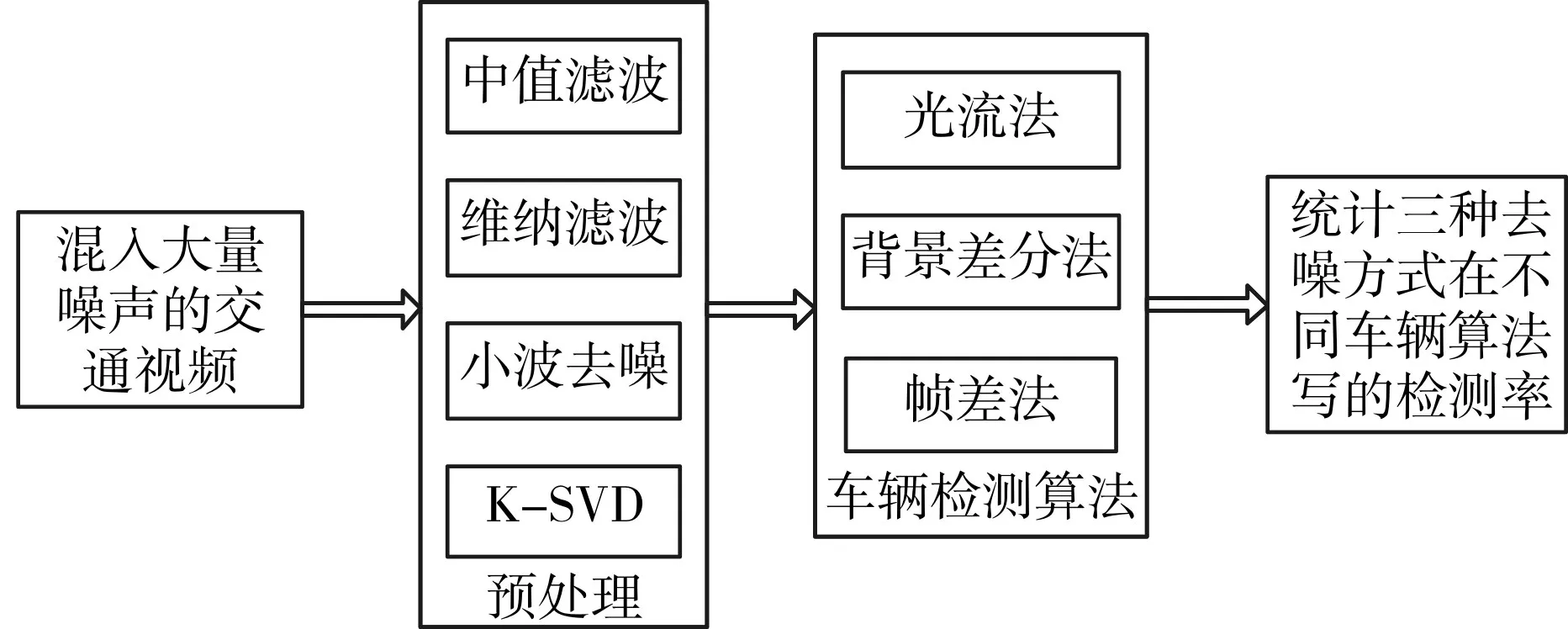
图1 车辆检测算法框图
实验结果表明,本文提出的K-SVD去噪算法相比于其他三种算法,具有更好的去噪能力,更好地保留图像信息和较高的车辆检测率。
4 实验结果分析
实验中,对车辆图片分别加入标准偏差σ=15、20、25、30、35的高斯噪声、椒盐噪声、混合噪声(不同σ的高斯和椒盐的混合噪声),分用中值滤波、维纳滤波、基于小波变换和基于K-SVD的四种去噪方法对噪声图像进行处理,通过去噪后的信噪比(Signal-Noise Ratio,SNR)、去噪后图像的视觉效果图以及在光流法、帧差法和背景差分法三种车辆检测方法中的车辆检测率等指标来分析本文方法的性能。
表1给出了中值滤波、维纳滤波、基于小波变换和基于K-SVD的四种去噪方法在不同标准偏差σ下对高斯噪声、椒盐噪声、混合噪声去噪后的SNR。
图2、图3和图4则分别给出了上述四种去噪方法针对含高斯噪声、椒盐噪声、混合噪声的车辆图像的去噪结果。其中,图1、图2和图3分别是表1中加入σ=30的高斯噪声和加入椒盐噪声以及加入混合噪声(σ=30的高斯噪声和椒盐噪声)的去噪图像。图5是检测期间出现的部分错检和漏检对应于表2的错检和漏检。

表1 K-SVD去噪、小波去噪、维纳滤波和中值滤波的SNR数据对比

图2 σ=30高斯噪声的去噪图像

图3 椒盐噪声的去噪图像

图4 混合噪声(σ=30高斯噪声和椒盐噪声)的去噪图像

图5 含噪视频检测中出现的漏检和错检
表2则给出上述四种去噪方法在光流法、帧差法和背景差分法三种车辆检测方法中的车辆检测率指标。给待检测的视频(总计324辆车)加入σ=30的高斯噪声和椒盐噪声,利用四种去噪方式分别对视频图像去噪,作为车辆检测预处理的去噪部分。假设总计车辆为S,错检为c,漏检为l,错检和漏检都归为误检,检测率则为

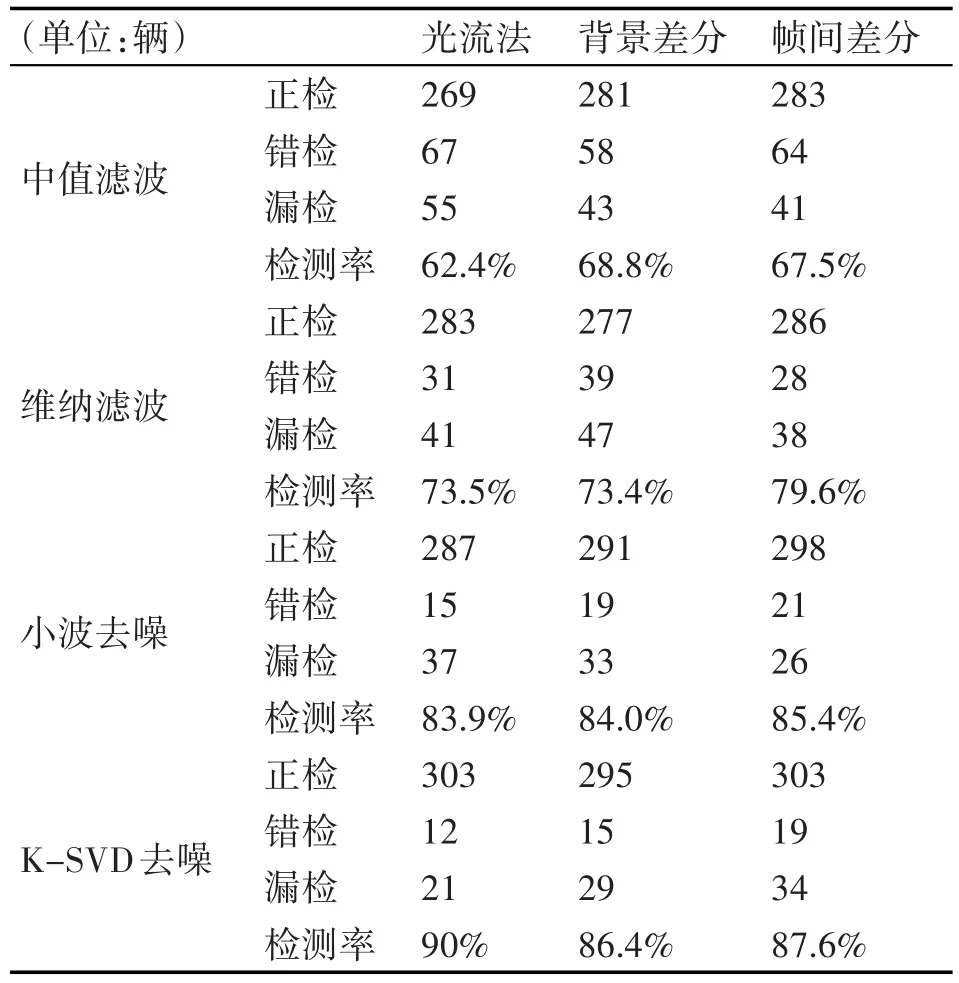
表2 利用K-SVD去噪、小波去噪、维纳滤波和中值滤波的车辆检测数据对比
从表1可以看出,在加入高斯噪声时,维纳去噪的SNR要高于中值去噪和小波去噪。在加入椒盐噪声时,中值去噪的SNR高于维纳去噪和小波去噪。在加入混合噪声时,小波去噪的SNR高于中值去噪和维纳去噪。但无论是针对高斯噪声、椒盐噪声还是混合噪声,K-SVD去噪的信噪比SNR都是最高的。据此可以得出结论:中值滤波能够很好地去除椒盐噪声,维纳滤波在处理高斯噪声时具有较好的性能,小波变换对各种噪声都有着较好的综合去除性能。然而对于加入的无论是高斯噪声,椒盐噪声还是混合噪声,本文提出的K-SVD算法比较其他三种去噪方式,具有更优的去噪性能。图1~3的实际去噪图像从视觉效果上也验证了上述实验数据和结论。
从表2的数据可以看出,基于K-SVD去噪的车辆检测的准确率要明显高于应用其它三种去噪方法的车辆检测率。
论文研究表明,本文提出的利用稀疏表示去噪来提高车辆检测率的方法具有以下优点:
1)更好的去噪效果和视觉效果。对加入不同标准差的高斯噪声、椒盐噪声和混合噪声的图像去噪,稀疏表示去噪的信噪比SNR都远高于其它三种去噪方法。同时对比去噪后的图像,稀疏表示去噪的图像更为清晰,也最接近原图像,这也就意味着稀疏表示去噪能更好地保留图像信息,有利于后续的车辆检测。
2)更高的车辆检测率。在利用四种不同去噪方法的车辆检测中,稀疏表示去噪的检测率远高于其它三种去噪方法。对视频中的车辆进行检测,其实就是对视频图像的信息提取与分析,含噪的视频图像会提供有误的图像信息,引起车辆检测的错检和漏检。例如,中值滤波在光流法的错检率很高,这是因为光流法是通过判断图像中像素点的光流矢量达到运动目标检测的目的,特别易受图像中的噪声影响。
5 结语
目前,车辆检测技术的研究重点大多放在如何更快更准确地识别车辆,忽视了视频中噪声对车辆检测准确率的影响。本文提出了一种基于K-SVD去噪来提高车辆检测率的方法,通过计算加噪图像去噪后的信噪比SNR、去噪后的视觉效果以及统计基于光流法、帧差法和背景差分法三种车辆检测算法的车辆检测率,与常用的小波变换、维纳滤波、中值滤波做对比,验证了基于K-SVD去噪方法能够有效地提高车辆检测率。
稀疏表示的视频图像去噪,需要使用K-SVD算法训练过完备字典,计算量较大,这就意味着在算法效率上有所缺陷,因此优化K-SVD算法,缩短训练时间将是下一步研究的重点。
[1]Melo B J,Naftel A,Bernardino A,et al.IEEE Transactions on Intelligent Transportation Systems[J].Intelligent Transportation Systems IEEE Transactions on,2013,3(1):01.
[2]Wang G,Xiao D,Gu J.Review on vehicle detection based on video for traffic surveillance[C]//IEEE International Conference on Automation and Logistics, 2008:2961-2966.
[3] Justusson B I.Median Filtering:Statistical Properties[M]//Two-Dimensional Digital Signal Prcessing II.Springer Berlin Heidelberg,1981:161-196.
[4]Tian C,Li X,Wang P.Research on the Image De-noising Algorithm Based on Wiener Filtering and Edge Modeling[C]//International Conference on Electronic,Mechanical,Information and Management Society,2016.
[5]Naimi H,Adamou-Mitiche A B H,Mitiche L.Medical image denoising using dual tree complex thresholding wavelet transform and Wiener filter[J].Journal of King Saud University-Computer and Information Sciences,2015,2(1):40-45.
[6]张健.基于稀疏表示模型的图像复原技术研究[D].哈尔滨:哈尔滨工业大学,2014:44-52.ZHANG Jian.Research on image restoration based on sparse representation model[D].Harbin:Harbin Institute of Technology,2014:44-52.
[7]李珅.基于稀疏表示的图像去噪和超分辨率重建研究[D].西安:中国科学院研究生院(西安光学精密机械研究所),2015,52(4):943-951.LI Hong.Research on image denoising and super resolution reconstruction based on sparse representation[D].Xi'an:Xi'an Institute of Optics and fine mechanics,Graduate University of Chinese Academy of Sciences,2015,52(4):943-951.
[8]Zhang J,Zhang H,Li Z.A hierarchical structure with improved OMP sparse representation used with face recognition[J].Optik-International Journal for Light and Electron Optics,2014,125(17):4729-4735.
[9]Aharon M,Elad M,Bruckstein A.K-SVD:An algorithm for designing overcomplete dictionaries for sparse representation[J].IEEE Transactions on Signal Processing,2006,54(11):4311-4322.
[10]Koller,D.Heinze,N.,Nagel,H.H.Algorithmic characterization of vehicle trajectories fromimage sequences by motion verbs[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recogni-tion,1991:90-95.
[11]Hong Zheng,Li Pan,Li Li.A morphological neural network approach for vehicle detection from high resolution satellite imagery[J].Neural Information Processing,2006:99-106.
[12]Aniruddha Kembhavi,David Harwood.Vehicle detection using partial least squares[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(no.6):1250-1265.
