一种基于样本选择和在线字典学习的域适应图像分类算法
2018-05-26张旭,刘韬,杜跃
张 旭,刘 韬,杜 跃
(苏州市职业大学 a.电子信息工程学院;b.计算机工程学院,江苏 苏州 215104)
经典图像分类任务假设训练数据和测试数据源于同一个域,具有相同的分布形式,然而真实应用情况往往无法满足该假设,测试数据和训练数据常具有较大类内差距,即具有不同的分布形式,如在人脸识别过程中,将采用具有良好分辨率的正面人脸图像训练获取的识别模型应用于侧面人脸图像或模糊人脸图像中,由于域间差异的存在,使得人脸识别的正确率大幅下降。针对此问题,学者提出了众多解决方法,其中域适应方法[1]最具代表性。域适应方法主要包括源域和目标域两个概念,并且源域和目标域中的数据具有不同的分布形式。域适应方法可被划分为两大类,无监督域适应方法和半监督域适应方法,在半监督域适应方法中目标域中的样本包含少量的类别标签,而在无监督域适应方法中目标域中的样本不包含任何类别标签的信息。
由于目标域中的样本不具有类别信息,因此相比于半监督域适应方法,无监督域适应方法更具挑战性和实用性。无监督域适应方法的一类常用做法,是基于源域和目标域构建域适应的子空间。该类方法将源域和目标域中的样本,通过变换和投影操作映射到一个公共子空间中,旨在减少样本之间的分布差异[2-4]。无监督域适应方法的另一类常用做法,是对源域中的样本进行加权或筛选,使得源域和目标域中的样本分布差异尽量减少[5-6]。上述方法充分利用了源域中样本的类别标签信息,但是很少有算法在分类过程中充分利用目标域样本所蕴含的判别性信息。由于源域和目标域中样本分布差异性的存在,因此仅利用源域中样本的类别信息并不能保留目标域中的判别性信息。
基于自扩展的域适应图像分类方法直接使用源域所训练获取的分类模型对目标域中的样本进行预测分类,并将该部分样本添加至源域中再进行分类模型训练。但该类方法需要设置启发式阈值决定适应过程何时终止,该类方法另一个局限性是无法保证每次迭代是否有效地减少了域间的差异性。S.Bendavid等[7]实验结果表明,直接将测试样本应用于具有不同分布形式的训练样本所训练的分类模型中,分类性能较差,源域和目标域之间的差异性是导致该类问题的主要原因。因此,基于域适应解决该类问题的核心是如何保证在域适应过程中减少域间的差异性。
真实的高维数据往往可以用低维的子空间近似表示。稀疏表示理论认为,通过选择合适的过完备字典,存在于同一子空间中的数据信号可以表示为少量几个原子或基的线性组合。字典学习广泛应用于图像分类和域适应算法中并表现出了良好的性能。本文基于在线字典学习提出一种无监督的域适应图像分类方法,算法假设在源域和目标域之间存在若干个中间域子空间,并使用字典表征各域子空间。在此过程中充分利用目标域中的样本数据,在每次迭代过程中使得源域和目标域之间的差异性不断减少,并将最终获取的分类模型应用于目标域。在每次迭代过程中从目标域中寻找符合预设条件的支持向量样本,将该部分样本用于字典更新,将支持向量样本添加至源域中进行模型训练。一方面,支持向量样本的类别标签错误率低,利用该部分样本训练分类模型使得模型错误率低;另一方面,基于SVM原理和理论,支持向量样本距离源域最近,因此最具适应性,这有利于减少源域和目标域之间的差异性,支持向量样本所具有的这两个属性对于域适应的图像分类方法至关重要。另外,合适的终止准则在域适应过程中同样具有关键性,本文基于域间相似性作为每次迭代过程的终止准则,这保证了在每次迭代过程中源域和目标域之间的差异性能够单调减小。
1 相关工作
域适应在模式识别与机器学习(如自然语言处理)等领域中被广泛研究和应用,近年来该方法吸引了越来越多计算机视觉研究者的关注。本文所提算法与基于自扩展的域适应图像分类方法[8]具有较强的相似性。该类方法首先基于源域样本训练分类模型,然后基于该分类模型对目标域样本进行分类识别,然后从中选取分类正确率较高的样本添加至源域中用于重新进行分类模型训练。L.Bruzzone等[8]选择距离分类器边界最近的样本作为候选样本添加至源域中,然而该算法可能由于目标域中样本标签的错误致使后续分类模型性能降低。针对此问题,C.W.Seah等[9]在后续分类模型学习过程中增加了一个正则化项,但该过程需要基于人工经验对大量启发式阈值进行调节与修正,使得该类算法使用性和泛化性差,并且该类算法没有对源域和目标域之间的相似性进行约束,即在每次迭代过程中无法确保源域和目标域之间的差异性单调递减。
字典学习同样广泛应用于域适应图像分类方法中。J.Ni[10]假设在源域和目标域之间存在若干个中间域子空间,并且基于最小化重构误差,通过表征各子空间的字典可以将源域和目标域平滑连接,该算法没有充分利用源域中样本的类别信息。S.Shekhar等[11]基于源域和目标域学习两类投影矩阵和一个公用字典,并将源域和目标域的样本嵌入到低维空间中。为了增加字典的判别性能,该算法在字典学习过程中利用了源域中样本的类别信息,但在低维空间中并没有减少域间的差异性,并且该方法并没有利用目标域中的判别性信息。
2 本文算法
本文提出一种无监督的域适应图像分类方法,基于目标域中的支持向量样本和在线字典学习,将源域和目标域相关联并减小域间差异性。假设NS和NT分别为源域和目标域中样本的个数,d为样本的维度,j表示源域样本的类别标签,j=1,2,…,C。基于源域样本构建的初始字典表示为D(0),表示第j类样本所对应的子字典,K为子字典中原子的数目。定义置信矩阵 P ∈RNt×C中的元素 pij∈ (0,1)表示目标域中的样本隶属类别j的概率。定义标记矩阵中的元素 Wij∈ (0,1)表示目标域中的样本是否为支持向量样本,特别地,在第k次迭代过程中上述各变量表示为X(k),D(k),P(k),W(k)。
首先,基于源域样本构建初始字典D(0),选择目标域中的支持向量样本并将该部分样本视为动态数据序列;然后,基于在线字典学习的方式,获取各中间域子空间对应的字典D(0),D(1),…,D(n)。在当前迭代过程中,仅从目标域中选择新的支持向量样本添加到源域中,即前次迭代过程所选择的支持向量样本应予以丢弃,并且在每次迭代过程中,对源域中的各类别均添加相同数量的支持向量样本以保证类别之间的均衡。基于此,从源域中选择置信度最大的样本作为支持向量样本用于更新当前字典D(k)直至满足迭代终止条件,以使样本的重构误差最小。
2.1 置信矩阵更新
给定当前字典对第k+1迭代过程中置信矩阵P(k+1)采用如下方式进行更新:
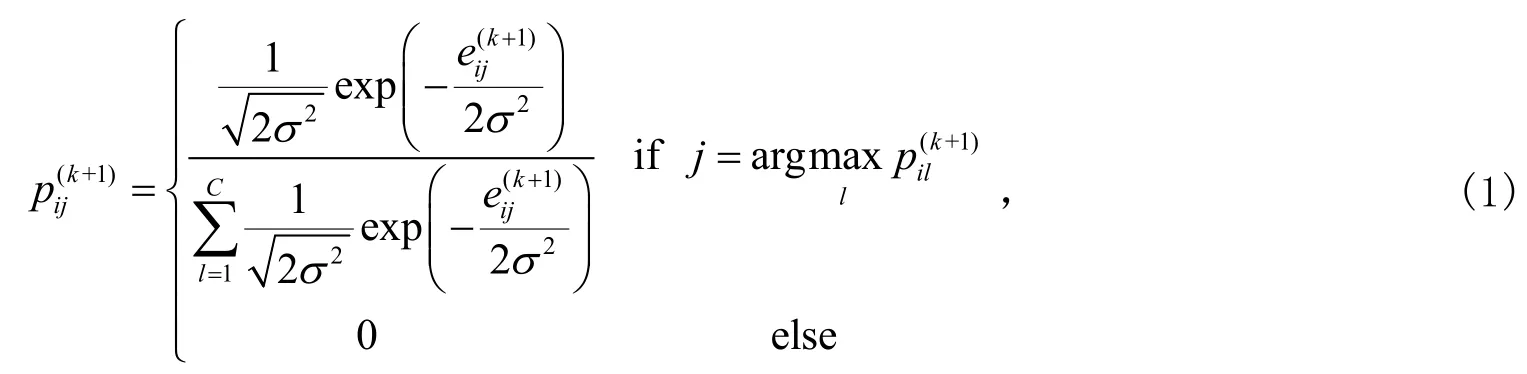
式(1)中:σ2为归一化参数;eij表示目标域中样本基于字典的重构误差,

式中为稀疏编码的系数。当样本i以较大概率隶属于类别j时,有p(k+1)≠0。ij
2.2 支持向量样本选择
在每次迭代过程中,根据标记矩阵W(k+1)从目标域中选择支持向量样本用于更新字典,并将支持向量样本添加至源域中,标记矩阵采用如下方式进行更新:
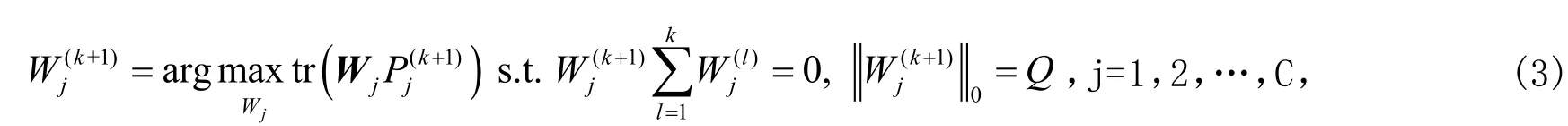

由于支持向量样本的类别标签存在一定的错误率,因此将各个支持向量样本基于置信概率进行加权处理之后再添加至源域,以增强模型的正确性和稳健性。
2.3 字典更新
本文采用在线字典学习的方式对字典进行更新,与传统批处理字典学习算法不同,在线字典学习算法在每次迭代学习过程中处理一个样本或者少量的样本,进而实现动态更新字典,字典更新过程为[12]
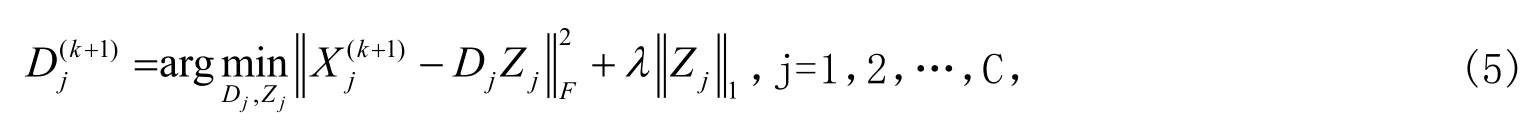
式中λ为正则化参数,控制编码系数的稀疏性。在字典更新过程,第k+1次迭代中采用第k次迭代过程中的字典作为初始字典。
2.4 域间相似性度量
当测试样本和训练样本源于不同域时,将测试样本应用于训练样本所获取的分类模型,分类正确率较低,产生该问题的主要原因在于源域和目标域之间存在较大的差异性,因此采用域适应解决该类问题的一个主要目标是如何衡量域间的差异性并在适应过程中减少域间的差异性。为了衡量域间的差异性,本文采用B.Lu[13]提出的方法基于域间相似性度量域间的差异性,域间相似性越高,域间差异性越小,反之亦然。源域Xs和目标域Xt间的相似性定义为

本文算法描述如下:
输入:初始化字典,目标域样本Xt,源域和目标域之间的相似性φ(Xs,Xt),目标域中每类别中支持向量样本的数目Q,参数λ;
输出:目标域中样本的类别标签;k=0;
Repeat:
1) 对输入样本基于式(2)计算样本的重构误差,根据式(1)对置信矩阵 P(k+1)进行更新;
2) 对于目标域中的各类别样本,基于最大化式(3)求解选择固定数目的支持向量样本;
3) 对支持向量样本进行加权处理并根据式(4)构建增广源域
4) 根据式(5),采用在线字典学习的方式,在每次迭代过程中采用目标域中的支持向量样本更新初始字典并作为后续学习的初始字典,分别记为D(1),D(2),…,D(k)。
5) k=k+1;Until φ(X(k+1),Xt)≤φ(Xk,Xt)或目标域中不存在符合条件的支持向量样本。
6) 目标域中的样本表示为形如的增广特征向量,并通过PAC操作生成最终用于分类识别的图像特征。
3 实验与分析
采用域适应图像分类方法中常用的Office & Caltech图像集验证本文提出的算法,该图像集由Office和Caltech-256图像集构成,Office数据集包含了Amazon、DSLR和Webcam图像子集,Amazon中的图像成像条件好、质量较优,dSLR中的图像由数字SLR相机在现实自然光照条件下所拍摄获取,Webcam中的图像由Web相机所拍摄,分辨率较低、具有大量的噪声干扰。Amazon、dSLR以及Webcam均包括31个类别,分别包含2 790、423以及795幅图像。Caltech-256图像库包含256个类、共30 607幅图像,每类最少包含80幅图像。因此Office & Caltech图像集包含了四个相互独立的域:Amazon、dSLR、Webcam和Caltech(见图1),由于dSLR子集包含的图像数目较少,并且与Webcam具有比较高的相似度,因此在本实验中没有考虑dSLR子集。选择Caltech(C)/Amazon(A)/Webcam(W)图像子集分别作为源域和目标域,因此共构建6对不同的源域和目标域组合,实验中在C、A和W域中各个类别分别随机选取300、300和100个样本并构建源域和目标域。

图1 Office & Caltech示例图像
分别与两种传统的图像分类方法即没有考虑域间样本分布的差异性和四种常用的域适应方法进行对比,其中BoVW&1-NN[14]和NBNN[15]是两种传统的图像分类方法,SIDL(subspace interpolation via dictionary learning)[10]、SGF(sampling geodesic flow)[16]、GFK(geodesic flow kernel)[14]和DA-NBNN[17]为四种无监督域适应图像分类算法。BoVW&1-NN算法采用BoVW模型表示图像信息,采用最近邻分类器对图像进行分类决策;NBNN算法基于图像—类别距离度量方式避免了特征量化所引起的量化误差,具有较好的泛化性能。SIDL算法同样采用字典学习的方式表征源域与目标域之间的中间子空间,但该方法采用目标域中的全部样本进行字典学习。SGF算法用采样测地流表示源域和目标域之间的潜在子空间,GFK算法进一步扩展了SGF算法,在SGF算法的基础上提出了测地流核,并且在子空间学习过程中融合几何特征及统计特征。DA-NBNN是种自扩展域适应方法,在NBNN算法的基础上不断从目标域中选择符合既定条件的样本更新源域,并进行Mahlanobis距离学习。
通过实验发现λ的取值大小对于最终的分类正确率影响甚微,这与文献[12]中的结论相一致,一般情况下λ的取值在0.01~0.5。与文献[12]相同,本实验中设置λ=0.02,基于最大似然估计对σ2进行估计,在各个子域中设置σ2=0.05。对于域A,C,W分别设置k的取值为80,80,20。在线字典更新过程中,一般情况下采用一个样本对字典进行更新,即Q取值为1,为了提高算法的运算效率和加快字典学习过程中的收敛速度,实验根据A,C,W各个域的大小分别设置Q取值为8,8,2,具体实验结果如表1所示。
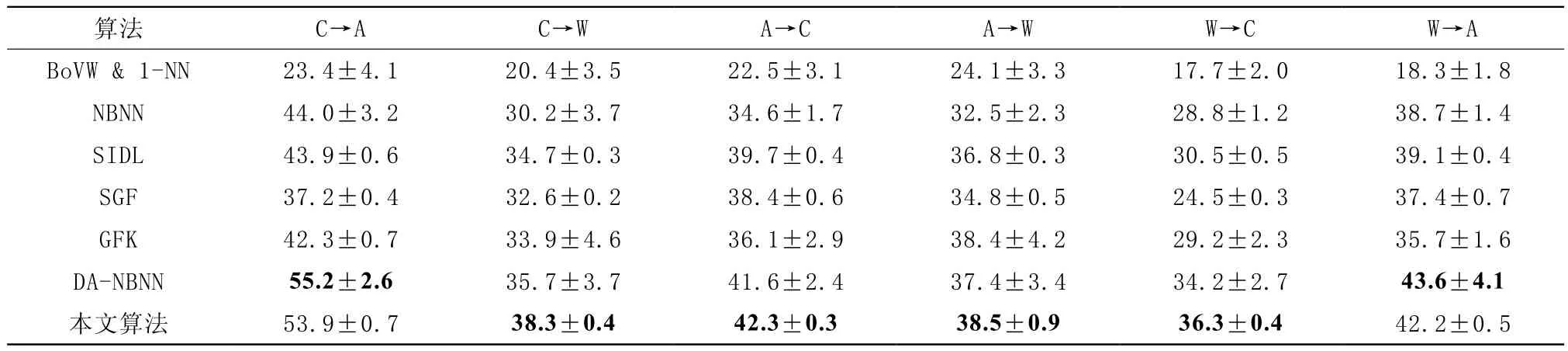
表1 不同域间组合的图像分类正确率
表1为6对不同域组合的实验结果,各列黑色加粗字体部分的数值为各分组实验中最高的分类正确率。由表1中可看出相比于其他算法,本文算法性能较优,特别是在域间差异较大的组中如W→C取得了最高的分类正确率,在C→A和W→A组合中也取得不错的分类正确率。BoVW&1-NN算法基于欧式距离采用最近邻分类器进行分类决策,由于欧式距离度量方式在高维空间中的局限性,因此该类算法在各分组实验中分类效果最差;NBNN算法采用图像—类别距离避免了特征量化所导致的误差,在C→A和W→A实验中表现出了较优的泛化性能。DA-NBNN同样从目标域中选择符合既定条件的样本添加至源域中,基于NBNN算法原理实现自扩展域适应方法,该方法在C→A和W→A实验中取得了最优的分类正确率,但在其余各组实验中劣低于本文算法。本算法与SIDL和GFK具有相一致的思想,特别地与SIDL相似,通过在线字典学习的方式建模源域和目标域之间的中间域,由于本文算法充分利用了源域样本的判别性信息,因此分类性能优于前两者,特别是在W→C实验中分类正确率较SIDL方法提高了近5.8%。
本文算法从目标域中不断地选择支持向量样本添加至源域中,因此在域适应过程中可以不断地减少源域和目标域之间的分布差异性,因此在域间差异较大的各组中本文算法表现更为突出。相反,当初始源域和目标源之间的分布差异较小即域间相似性较高时,添加支持向量样本并没有大幅度减少域间差异,本文算法经过少量迭代便达到终止条件,但仍取得了与其他域适应算法相当的分类正确率。
4 结论
本文基于样本选择和在线字典学习提出一种无监督域适应图像分类算法,为了减小源域和目标域中的差异性,算法通过迭代不断从目标域中选择支持向量样本添加源域中并进行字典学习。支持向量样本一方面减小了域间的差异性;另一方面增加了模型的判别性能,在线字典学习的方式保证了样本的重构误差最小,通过迭代终止准则使得在适应过程中源域和目标域之间的差异性单调递减。在Office&Caltech图像集中本算法取得了较优的分类正确率。
参考文献:
[1]DAUME I N,MARCU D.Domain adaptation for statistical classifiers[J].Journal of Artificial Ietelligence Research,2006,26:101-126.
[2]BAKTASHMOTLAGH M,HARANDI M T,LOVELL B C,et al.Unsupervised domain adaptation by domain invariant projection[C]//IEEE International Conference on Computer Vision.Sydney:IEEE Computer Society,2013:769-776.
[3]FERNANDO B,HABRARD A,SEBBAN M,et al.Unsupervised visual domain adaptation using subspace alignment[C]//IEEE International Conference on Computer Vision.Sydney:IEEE Computer Society,2014:2960-2967.
[4]SHA F,SHI Y,GONG B,et al.Geodesic flow kernel for unsupervised domain adaptation[C]//IEEE Conference on Computer Vision and Pattern Recognition.Rhode Island:IEEE Computer Society,2012:2066-2073.
[5]TANG S,YE M,LIU Q,et al.Domain adaptation of image classification based on collective target nearest-neighbor representation[J].Journal of Electronic Imaging,2016,25(3):033006.
[6]LI X,FANG M,ZHANG J J,et al.Sample selection for visual domain adaptation via sparse coding[J].Signal Processing Image Communication,2016,44:92-100.
[7]BENDAVID S,BLITZER J,CRAMMER K,et al.A theory of learning from different domains[J].Machine Learning,2010,79(1/2):151-175.
[8]BRUZZONE L,MARCONCINI M.Domain adaptation problems:a dasvm classification technique and a circular validation strategy[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(5):770-787.
[9]SEAH C W,ONG Y S,TSANG I W.Combating negative transfer from predictive distribution differences[J].IEEE Transactions on Cybernetics,2013,43(4):1153-1165.
[10]NI J,QIU Q,CHELLAPPA R.Subspace interpolation via dictionary learning for unsupervised domain adaptation[C]//Computer Vision and Pattern Recognition.Portland:IEEE Computer Society,2013:692-699.
[11]SHEKHAR S,PATEL V M,NGUYEN H V,et al.Generalized domain-adaptive dictionaries[C]//IEEE Conference on Computer Vision and Pattern Recognition.Portland:IEEE Computer Society,2013:361-368.
[12]WRIGHT J,YANG A Y,GANESH A,et al.Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[13]LU B,CHELLAPPA R,NASRABADI N M.Incremental dictionary learning for unsupervised domain adaptation[C]//BMVC.Swansea:BMVA,2015:108.1-108.12.
[14]GONG B,SHI Y,SHA F,et al.Geodesic flow kernel for unsupervised domain adaptation[C]//Computer Vision and Pattern Recognition.Rhode Island:IEEE Computer Society,2012:2066-2073.
[15]BOIMAN O,SHECHTMAN E,Irani M.In defense of nearest-neighbor based image classification[C]//Computer Vision and Pattern Recognition.Anchorage:IEEE Computer Society,2008:1-8.
[16]GOPALAN R,LI R,CHELLAPPA R.Domain adaptation for object recognition:An unsupervised approach[C]//IEEE International Conference on Computer Vision.Barelona:IEEE Computer Society,2011:999-1006.
[17]TOMMASI T,CAPUTO B.Frustratingly easy nbnn domain adaptation[C]//IEEE International Conference on Computer Vision.Sydney:IEEE Computer Society,2013:897-904.
