基于Word2vec和SVM的微博情感挖掘与仿真分析
2018-05-23缪广寒
缪广寒
(无锡城市职业技术学院 实训基地管理中心,江苏 无锡 214000)
随着社交网络和计算机技术的不断发展,更多的人借助博客、微博来发表观点、表达情感[1]。微博具有互动性、原创性、便捷性、内容碎片化和传播速度快等特点[2-3],其逐渐成为热门话题以及事件讨论的重要平台[4]。微博通常带有一定的感情倾向,使用数据挖掘技术来分析微博所表达的情感、了解事件的动态,已成为诸多学者、专家和科研机构的研究方向[5-7]。
微博情感分析,即分析微博内容中的文本和表情符等所表达出的主观信息以及说话人的态度[8]。不同于传统文本分类的是,该种文本分析的对象是一些主观因素而不是客观内容[9]。目前,情感分析的主要研究方法可以分为基于机器学习的方法和基于情感词典与规则的方法。如文献[10]使用标签传播算法构建中文情感词典,来进行文本情感分析;文献[11]构建了一种基于SVM和情感词特征的情感分类模型;文献[12]使用SVM和N-Grams模型对情感分类;文献[13~14]使用多种特征融合的方式来分类中文情感。然而,这些文献并未过多考虑不同情感词汇的重要性,忽略了不同情感词汇对分类精度的影响。因此,本文提出了一种基于词频重要性加权Word2vec[15]的特征和SVM[16]的微博情感分析模型。
1 基于重要性加权的Word2vec特征
Word2vec是谷歌公司在2013年开源的一款将文本词汇表示为向量的工具。其可以将文本内容转化为词向量,并将文本语义上的相似度转换为求解向量空间上的相似度。Word2vec模型可以充分提取相互独立、毫无关联的文本词汇的上下文语义信息,从而可以为文本数据挖掘更加深层次到特征表示。
Word2vec包含Skip-gram 和Continuous Bag of Words(CBOW)两种训练模型。其中,CBOW的数学表示为P(Wt|Wt-k,Wt-k-1,…,Wt+k-1,Wt+k), 表示语料词汇。CBOW的目的是,通过上下文相邻的k个词来预测给定词Wt出现的概率。Skip-gram的数学表示为P((Wt-k,Wt-k-1,…,Wt+k-1,Wt+k|W)),其则是根据给定词 来预测上下文的信息。然而,Word2vec模型并不能区分文本中不同词汇的重要程度。因此,本文提出使用词频的方法计算微博文本中词汇的权重。
词频(Term Frequency,TF)即某一给定词汇ti在文档dj中出现的频率,计算公式为
(1)
其中,词汇ti出现的次数为ni,j,所有词出现的总次数为∑knk,j。
Word2vec模型能较好地建立上下文间的关系,但忽略了不同词汇的权重;而基于词频的方法只考虑了词汇出现的频率而并未考虑文本的上下文关系。因此,本文采用基于词频加权的Word2vec模型来更有效地挖掘文本更深层的特征。
假设获取到的训练语料词典为Vocab,文档为〈w1,w2,…,wj〉,词向量维度为N
Vocab={ti|i∈1,…,N}
(2)
首先,使用默认的Skip-gram模型训练语料数据集,得到Word2vec模型。并使用该模型获得文档中每个词汇的词向量,累加这些词向量得到文档dj的向量表示R(dj)为
R(dj)=∑iWord2vect(t) ,wheret∈dj
(3)
其中,词汇t的Word2vec词向量表示为Word2vect(t)。
然后,统计文档dj中每个词汇出现的频率,并将该词汇的Word2vec词向量与词频相乘,得到加权Word2vec词向量。再累加这些加权词向量得到文档dj新的词向量为
W_R(dj)=∑iWord2vect(t)×tfi,j, wheret∈dj
(4)
最后,将加权Word2vec词向量作为SVM分类器的特征向量,并训练得到SVM模型。
2 SVM分类器
支持向量机(Support Vector Machine,SVM)是由Vapnik等基于结构风险最小化原则和统计学习理论提出的一种新的机器学习算法。其本质为核方法,在解决非线性、小样本和高维模式识别问题中表现出了诸多优势。本文将SVM分类器用于微博情感分类问题中,将微博分为积极和消极两种情感。
SVM通过非线性变换φ(·)将低维空间的输入数据映射到高维特征空间中,实现低维线性不可分的数据在高维空间的线性可分。从而得到最大间隔分类超平面f(x)=ωTφ(x)+b,其优化目标为
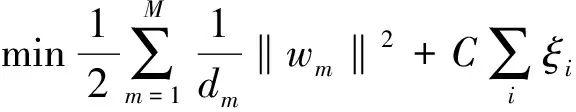
(5)
经过对偶变换等方式后,可以得到SVM的决策分类函数为

(6)
其中,K为核函数实现低维样本向高维空间的映射。
3 实验与结果分析
3.1 实验数据
本文使用中文维基百科和百度百科下载的常用、未处理的词条作为训练Word2vec模型的训练数据。情感分析使用Coae2014语料集,并各保留3 000条积极微博和消极微博,部分测试数据如下表1所示。为了验证模型的有效性将微博语料分为80%的训练数据和20%的测试数据。

表1 实验数据
3.2 实验结果
本文首先将下载的训练数据进行繁简体转换、噪声过滤等预处理后,经ICTCLAS分词,共提取到762 134个词汇。预训练的Word2vec模型窗口大小为20,包含400维参数向量。同时,微博数据也经过数据清洗、去停用词和分词等预处理以及词频统计后,得到加权后的Word2vec词向量。数据处理流程,如图1所示。

图1 数据处理流程
将词频加权的Word2vec词向量作为SVM分类器的特征向量,来训练分类器。然后,对标注好的测试数据集进行预测。并将实验结果与仅使用Word2vec词向量和基于词频的方法进行比较,其比较结果如表2所示。本文主要比较了基于混淆矩阵的分类准确率、召回率、F值和正确率等性能指标。

表2 实验结果与比较
从表2可以看出,本文所提出的基于词频加权Word2vec特征的微博情感分类模型对积极和消极情感均能获得更好的分类性能。虽然Word2vec模型能较好地建立上下文间的关系,但忽略了不同词汇的权重;而基于词频的方法只考虑了词汇出现的频率而并未考虑文本的上下文关系。因此,本文提出了基于词频加权的Word2vec特征和SVM分类器进行微博情感分类。从实验结果可看出,此方法具有更高的分类准确率、召回率、F值和正确率。
4 结束语
针对微博情感挖掘问题中忽略词汇重要程度和缺失语义关系的问题,本文提出了一种基于Word2vec和SVM的微博情感挖掘方法。该方法使用词频加权的Word2vec特征,能同时考虑词汇出现的频率和词汇上下文间的关系,可以更有效地挖掘文本更深层的特征。同时,使用SVM分类器将微博分为积极和消极两种情感,取得了较好的分类结果,其相比于传统的方法其性能更加理想。
参考文献
[1] 刘龙飞,杨亮,张绍武,等.基于卷积神经网络的微博情感倾向性分析[J].中文信息学报,2015,29(6):159-165.
[2] 王志涛,於志文,郭斌,等.基于词典和规则集的中文微博情感分析[J].计算机工程与应用,2015,51(8):218-225.
[3] 张志琳,宗成庆.基于多样化特征的中文微博情感分类方法研究[J].中文信息学报,2015, 29(4):134-143.
[4] 李阳辉,谢明,易阳.基于降噪自动编码器及其改进模型的微博情感分析[J].计算机应用研究,2017,34(2):373-377.
[5] 苏小英,孟环建.基于神经网络的微博情感分析[J].计算机技术与发展,2015,25(12):161-164.
[6] 刘德喜,聂建云,张晶,等.中文微博情感词提取:N-Gram为特征的分类方法[J].中文信息学报,2016,30(4):193-205.
[7] 何炎祥,孙松涛,牛菲菲,等.用于微博情感分析的一种情感语义增强的深度学习模型[J].计算机学报,2017,40(4):773-790.
[8] 郝志峰,杜慎芝,蔡瑞初,等.基于全局变量CRFs模型的微博情感对象识别方法[J].中文信息学报,2015,29(4):50-58.
[9] 杜亚楠,刘业政.基于修正G2特征筛选的中文微博情感组合分类[J].情报学报,2016,35(4):349-357.
[10] 李天彩,王波,毛二松,等.基于Skip-gram模型的微博情感倾向性分析[J].计算机应用与软件,2016,33(7):114-117.
[11] Rahmawati D, Khodra M L.Word2vec semantic representation in multilabel classification for indonesian news article[C].MA,USA:International Conference on Advanced Informatics: Concepts, Theory and Application,IEEE,2017.
[12] Rachman G H,Khodra M L,Widyantoro D H. Rhetorical sentence categorization for scientific paper using Word2vec semantic representation[C].CA,USA:IEEE Conference on Informations,2017.
[13] 张谦,高章敏,刘嘉勇.基于Word2vec的微博短文本分类研究[J].信息网络安全,2017(1):57-62.
[14] 李锐,张谦,刘嘉勇.基于加权word2vec的微博情感分析[J].通信技术,2017,50(3):502-506.
[15] 陈炳丰,郝志峰,蔡瑞初,等.基于AWCRF模型的微博情感倾向分类方法[J].计算机工程,2017,43(7):187-192.
[16] Lilleberg J,Zhu Y,Zhang Y.Support vector machines and Word2vec for text classification with semantic features[C].Guangzhou:IEEE International Conference on Cognitive Informatics & Cognitive Computing,2015.
