基于随机森林算法的Android恶意代码特征分析
2018-05-23刘贺翔李英娜张长胜任小波
刘贺翔,李英娜,张长胜,任小波,李 川
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
随着手机逐渐成为人们生活中必不可少的产品。恶意代码开发者利用Android开放性平台开发出许多恶意代码,进而对用户手机进行非法干扰。智能手机终端一经被恶意代码感染,攻击者(“黑客”)就可以通过恶意代码的方式非法获取到用户大量的隐私信息[1](包括用户帐号与密码信息、用户手机号码信息等),甚至进行截断短信、删除用户移动终端中的应用程序等恶意行为,从而导致一系列严重事件发生。因此,对Android恶意代码的特征分析具有重要的实际意义。
恶意代码检测效率的主要因素之一是特征的描述能力,如何更为有效地检测恶意代码是目前恶意代码防御的热点。中国科学院的王蕊,冯登国等人[2]提出了一种基于语义的恶意代码行为特征提取及检测方法,从而提高对恶意代码变种的检测能力。西安交通大学智能网络与网络安全教育部重点实验室的胡文君,赵双等人[3]提出了一种针对Android平台恶意代码的检测方法及系统实现,同时免费提供分析检测服务,所提检测方案具有较高的检测率和较低的误报率。
本文采用随机森林算法(Random Forests Algorithm,RF)对应用特征进行匹配训练,从原始训练集中有放回的抽取一定数量的样本,作为根节点并开始不断进行训练,直到所有节点都被遍历,或者训练结束,从而实现特征叶子节点与案例库中的特征匹配。
1 Android权限特征的提取
权限特征是对应用程序恶意行为的一种描述,在检测移动终端恶意代码的时候,可以根据权限特征对良性应用和恶意应用做出区分。安卓应用程序在安装及运行的时候,它所申请的权限序列被保存在安卓应用程序配置文件AndroidManifest.xml中。为了安卓权限特征的提取,第一步需要针对安卓应用程序包的APK文件做出反编译处理的操作,得到配置文件AndroidManifest.xml,提取AndroidManifest.xml配置文件中的权限特征序列。目前,反编译预处理操作应用最多的就是apktoolkit反编译工具。经过运用apktoolkit反编译操作的指令,获取得到APK文件的源码[4]。在特征权限的提取过程中,主要关心的是经过反编译安卓APK文件之后获得的配置文件AndroidManifest.xml 。配置文件前几行展示了安卓应用程序屏幕设置的信息、版本的信息等等。从配置文件中,可以得到该移动终端安卓应用程序所申请的权限信息,该安卓应用程序基本上所申请的权限有NAPS_RECEIVE、RED_GSERUICES、CANERA、VIBARTE、CALL_PHONE、CACCESS_BOOT_COMPLETED、WRITE_EXTERNAL_STORAGE、WAKE_LOCK、READ_PHONE_STATE、ACCESS_WIFI_STATE、GET_TASKS等。
2 随机森林算法的特征分析与应用
随机森林算法包括许多决策树分类器,各个决策树之间没有关联。算法工作原理为:随机森林算法随机并且有放回的从给定训练样本集合S中重复抽选出N个子样本,组合成新训练样本集,将这个样本集组成的分类树合起来成为随机森林。一旦有新的样本数据,随机森林算法中的各个决策树(DecisionTree)将会分别进行判断工作。随机森林算法中每一个DecisionTree都拥有一样的属性分布,一个DecisionTree的分类能力效果可能不好,但是在通过随机产生很多DecisionTree之后,经过统计一个个DecisionTree的分类结果以后,就可以对新样本特征数据进行分类[5-6]。
2.1 DecisionTree
DecisionTree的功能就是分类器,其结构是树状的。经过训练样本数据,构造出DecisionTree,分类新的样本数据,效率较高。
2.2 分裂属性
分裂属性两个重要信息[7],信息增益和基尼指数。
2.2.1 信息增益
随机森林算法的模型样本分类期望信息数学表达形式
I(S1,S2,…,Sm)=-∑Pilog2(pi),i=1,…,m
(1)
式中,S代表数据的集合;m代表S的分类数量P≈|Si/S|;Ci代表某个分类的标号;Pi代表任意样本所属于Ci的概率;Si代表Ci上的样本所具有的数量。
I(S1,S2,…Sm)越大,S1,S2,…,Sm越乱,越无序,分类得到的效果越不好。I(S1,S2,…,Sm)越小,S1,S2,…,Sm越纯,越有序,分类得到的效果越好。
参照A属性,进而划分出子集的熵值
E(A)=∑(S1j+…+Smj)S×I(S1j,…,Smj)
(2)
式中,A代表属性,拥有V个不一样的取值集合,通过A将S划分成为数量为V个子集,S1,S1,…,Sv,Sij表示子集Sj中类Ci的样本数量。
信息增益为
Gain(A)=I(s1,s2,…sm)E(A)
(3)
分裂属性的选择规矩:选取拥有最大信息增益的属性为分裂属性。
2.2.2 基尼指数
Gini指标代表Pj类别j出现的频率;倘若集合T被分成m个部分N1,N2,…,NM。把这个被分成m个部分的Gini用公式表示
(4)
随机森林每一棵分类树都是二叉树结构,分类树从根节点处开始按顺序对训练样本集进行训练。在分类树中,该节点分裂为两个节点,右节点和左节点,两节点分别代表样本训练数据的子集,按照一样的方式不断分裂下去,直到满足分支终止条件为止。随机森林算法训练具体流程如图1所示[8]。

图1 基于随即森林算法的恶意代码分类流程图
第一步原始训练集用S表示;测试集用T表示;特征维数用F表示;
If 分类树的数量用T表示,每棵分类树的深度用d表示;每个节点使用特征数量用f表示。
End 在节点上,最少的信息增益用m表示;最少样本数量用s表示;第1-t棵树时,i=1-t。
第二步有放回的从训练集S中抽取数量为S(i)的样本,作为根节点并开始进行训练的操作;
第三步倘若当前节点未能符合end结束条件,则从F维特征中不放回的随机性的选择f维特征。倘使节点符合了end结束条件,当前节点就认为是叶子节点,概率p为C(j)占当前样本集的比例,继续训练其他节点;
第四步重复第一、第二步,一直到所有节点被标记为叶子节点;
第五步重复第二、第三步,一直到所有节点全都被训练过,结束。
基于随机森林算法的预测过程如下:
第一步从当前树的根节点开始,根据当前节点的阀值a,
第二步重复第一步,直到全部t棵分类树都输出预测值为止。输出结果为对每个C(j)的概率P做累计,即全部分类树中预测的概率之和最大的类。
3 实验数据的设定
针对静态安全测试,本文添加了一些的样本信息。包括良性样本和恶意样本。其中,Android应用恶意代码数据集包括了90个恶意程序家族,并且其中的恶意程序样本数目都不相同,最多的一个含有638个恶意程序样本,所有家族总共含有的恶意程序样本数为1 978个[9-10]。为了更好证明上述方法所达到的成果,在加入Android恶意程序之外,还向数据集中添加了非恶意样本数。根据程序中不同的使用功能,挑出了15个类别,分别有杀毒软件、浏览器、通信软件、生活常用软件及管理类软件等。对每一类别中的前190个热门应用进行下载,共有3 201个良性代码数据集。部分恶意应用代码家族信息如表1 所示。部分良性应用代码家族信息如表2所示。
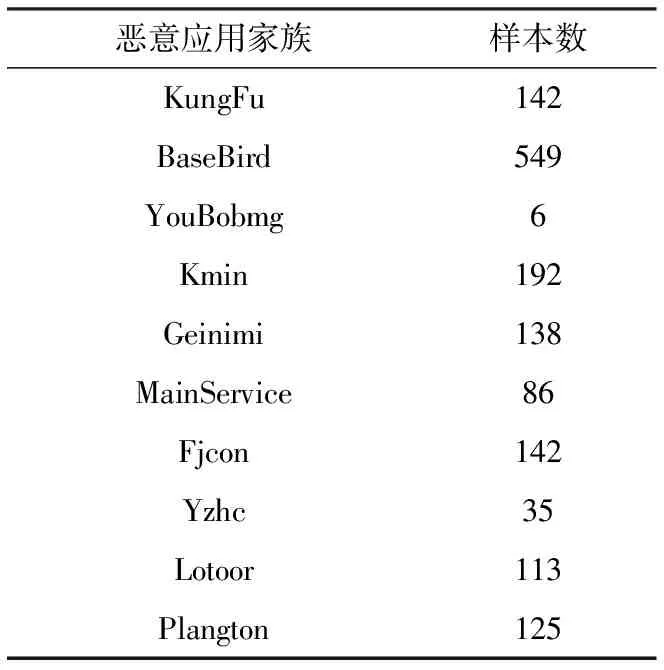
表1 恶意应用代码部分家族列表

表2 良性应用代码部分家族列表
本实验实施过程中,将安卓恶意应用程序说明为正样本,良性应用程序说明为负样本。为检测本文方案的性能以及效果,需要计算Accuracy(准确率),FPR(误报率),FNR(漏报率) 指标。TP 表示恶意样本被正确分类为恶意样本的数量;FN 表示恶意样本被错误分为良性样本的数量;TN 表示良性样本的数量;FP 表示良性样本误报为恶意样本的数量。
准确率的计算公式为
(5)
误报率的计算公式为
(6)
漏报率的计算公式为
(7)
4 实验与分析
在进行权限特征实验之前,需要对权限特征进行分组,根据权限特征在相应数据集上的排序,对权限特征进行分组,梯度为10 个权限特征,一共分了13组,在数据集现有的情况下,分别使用某常用算法、随机森林(RF)做对比实验,实验所采用的数据集合当中良性安卓样本和恶意安卓样本数量都为500[11-15]。针对权限特征在实验数据集上的准确率、误报率、漏报率进行实验结果详细统计。实验结果如表3,表4所示,准确率如图2所示,误报率如图3所示,漏报率如图 4所示。
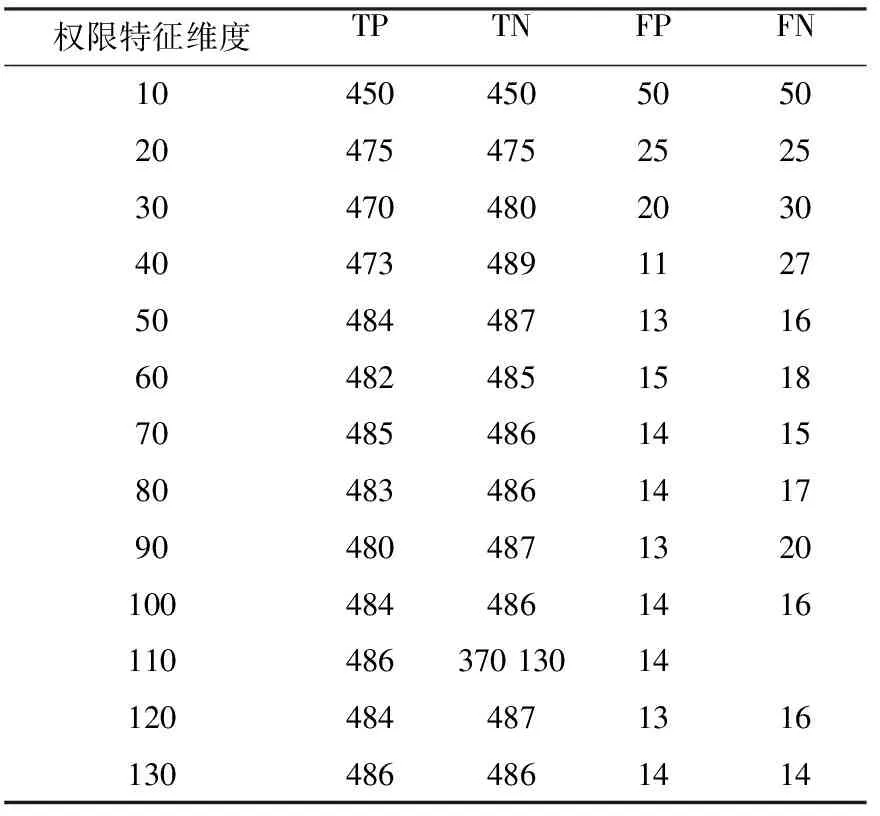
表3 基于某常用算法权限特征

表4 基于随机森林算法权限特征
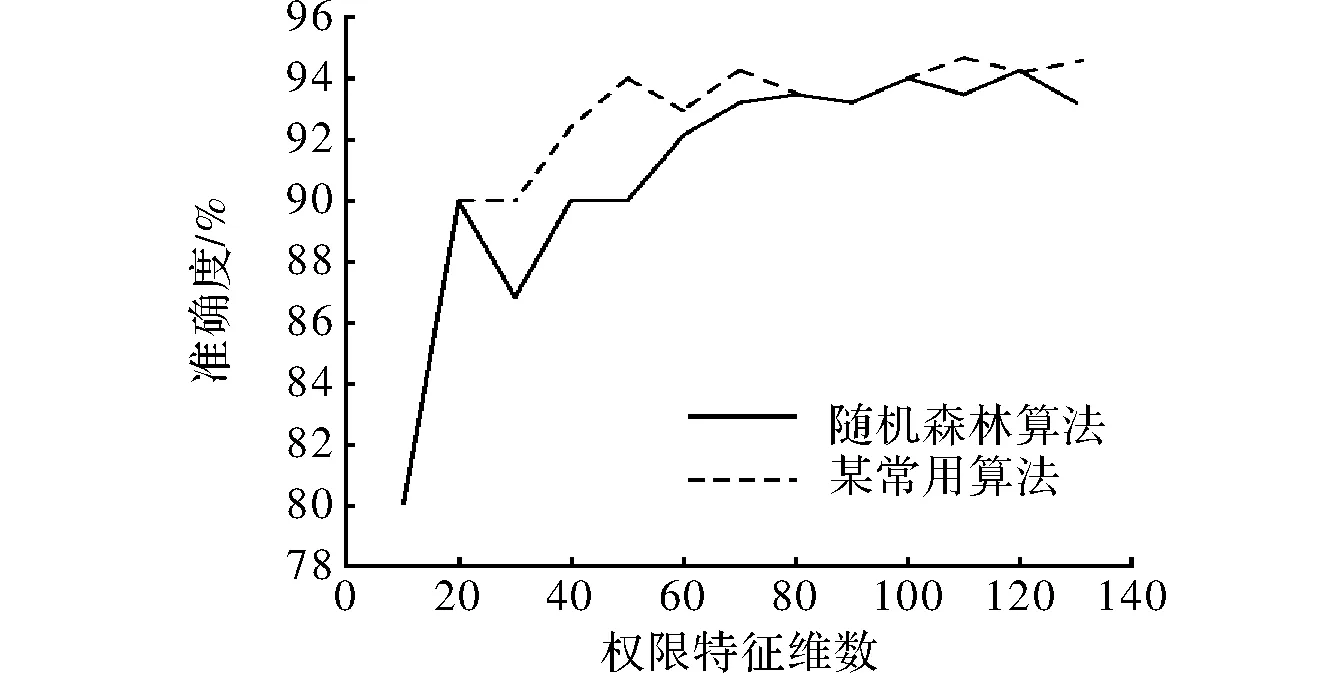
图2 准确率曲线

图3 误报率曲线
从以上3幅图中分析得到:从选择的算法效果来看,图2准确率实验结果表明,在权限特征维度上,随机森林算法(RF)的表现基本都比某常用算法要好;图3表明随机森林算法在误报率上效果都比某常用算法好;图4表明,随机森林算法的漏报率在60维之前略显不足。

图4 漏报率曲线
5 结束语
对于维度不一样的权限特征的选择,以及不同的算法的选择,当特征维数约达到 60维时,无论是某常用算法还是RF算法,其准确率、误报率、漏报率所对应的数值都接近收敛。所以,在建立基于权限特征的安卓恶意代码检测模块的时候,选择前60维的权限特征。综上所述,为了构建权限特征的检测模块,最终选择RF算法和后60维的权限特征。
参考文献
[1] 张嘉宾.Android应用的安全性研究[D]. 北京:北京邮电大学,2013.
[2] 胡文君,赵双,陶敬,等.一种针对Android平台恶意代码的检测方法及系统实现[J].西安交通大学学报,2013,47(10):37-43.
[3] 王蕊,冯登国,杨轶,等.基于语义的恶意代码行为特征提取及检测方法[J].软件学报,2012(2):378-393.
[4] Jian Feng. SLCRM: subjective logic-based cross-layer reputation mechanism for wireless mesh networks[J].中国通信:英文版, 2012, 9(10):40-48.
[5] Bethany B Cutts, Nicholas Moore, Ariana Fox-Gowda, et al. Testing neighborhood, information seeking, and attitudes as explanations of environmental knowledge using random forest and conditional inference models[J]. Professional Geographer, 2013, 65(4):561-579.
[6] 胡宏,陈彦萍.基于随机森林算法的混合入侵检测系统研究[J].西安文理学院学报:自然科学版,2013, 16(3):68-71.
[7] 韩奕. 基于行为分析的恶意代码检测与评估研究[D].北京:北京交通大学,2014.
[8] 李根. Android系统恶意代码检测技术研究[D].哈尔滨:哈尔滨工业大学,2014.
[9] 韦泽鲲,夏靖波,张晓燕,等. 基于随机森林的流量多特征提取与分类研究[J].传感器与微系统, 2016(12):55-59.
[10] 王闪闪. 基于群智能算法的神经网络建模研究[J]. 电子科技,2017,30(4):56-59.
[11] 毛蔚轩,蔡忠闽,童力. 一种基于主动学习的恶意代码检测方法[J]. 软件学报,2017,28(2):384-397.
[12] 李博亚, 薛质. Android系统中恶意代码的动态检测技术研究[J]. 上海师范大学学报:自然科学版, 2017, 46(1):16-22.
[13] 毛思琪. 安卓手机失窃密隐患展示系统的设计与实现[D]. 北京:北京交通大学, 2016.
[14] 曹正凤. 随机森林算法优化研究[D].北京:首都经济贸易大学,2014.
[15] 董师师,黄哲学.随机森林理论浅析[J]. 集成技术,2013 (1):1-7.
