基于数据挖掘中文书目自动分类算法
2018-05-23,,
,,
(海军航空大学 舰面航空保障与场站管理系,山东 青岛 266041)
0 引言
文本数据[1]挖掘(Text Mining)是数据挖掘的主要分支之一,是从海量文本数据中抽取有价值的信息和知识的计算机处理技术,在图书分类检索、企业情报分析、搜索引擎等领域都有广泛应用[2]。文本数据挖掘方法主要包括文本分类、文本聚类、信息抽取、摘要和压缩等。其中,文本分类是文本数据挖掘的主要研究方向。文本分类依据文本之间的差异性特征实现不同类别文本的分类,一般包括文本预处理、统计和特征抽取、分类器设计等步骤。首先在预处理阶段将原始语料转换为结构化数据,然后统计词频等特征,采用诸如信息增益、互信息等特征提取方法提取文本描述特征,接着采用诸如支持向量机、神经网络等机器学习方法构建特征的分类器,实现特征的分类[3-9]。在现代图书馆管理领域,目前逐渐开始使用文本数据挖掘技术来实现图书的管理,如采用机器学习架构实现中文书目的自动分类。该技术主要包括文本预处理、特征提取和机器学习三个部分,目前已经有一些成熟的方法[10-14]。如文献[12]利用ICTCLAS分词系统对书名和摘要信息进行中文分词,为标题和摘要的特征词赋予不同的权重,采用词频-逆向文件频率提取特征,采用支持向量机进行特征分类。文献[13]同样采用ICTCLAS分词系统对书名和摘要信息进行中文分词,为每个书目构建书目+关键词的二元关联矩阵,分别采用支持向量机和BP神经网络进行特征分类。文献[14]采用概率主题模型表示书目信息,克服因文本短小而产生的特征稀疏问题;依据书目信息体例结构和类目区分能力等先验知识构建复合加权特征,结合概率主题模型实现中文书目信息分类。这些方法在中文书目自动分类领域都有有益的效果,然而分类准确率还有待进一步提高。
1 中文书目自动分类框架
在机器学习阶段,首先需要对中文图书的书目数据进行分析,抽取中文书目内容特征和中图法类目信息;然后对中文书目内容特征进行预处理,得到中文书目内容所包含的词条信息,将非结构化的文本信息转换为结构化的词条信息;接着依据词条信息提取能够描述不同类别中文书目内容的特征向量;最后,结合数据库中各个中文书目所对应的特征向量以及中图法类目信息组建训练数据集,选择合适的机器学习算法进行学习和训练,构建中文书目类目分类器。
在类目分析阶段,对于待分类的中文书目,首先抽取中文书目内容特征,然后进行预处理,得到词条信息;接着提取特征向量;最后将特征向量送进中文书目类目分类器,得到中文书目分类结果。
可见,基于机器学习的中文书目自动分类系统架构涉及的关键技术主要有三个部分:文本预处理、特征提取和机器学习,简要描述如下。
1.1 文本预处理
该部分主要任务是将非结构化的文本数据转换为结构化的词条信息。对于中文书目分类而言,目前大多是采用中国科学院计算机研究所开发的ICTCLAS分词系统来进行文本预处理工作。该系统对中文书目目录的各个著录项的文本进行分词操作,这样将中文书目目录信息转换为词条信息的集合;然后,将词条集合中的冗余词条(如停用词、部分高频词和低频词等)删除。这样,对于任意一条中文书目,可以依据是否包含词条来构建一个词条向量,表示为:
q=[o1,o2,…,on]T
(1)
其中:n表示词条的数量。元素oi;i=1,2,…,n表示第i个词条在中文书目内容中是否出现,出现则值为1,否则为0,也即:
(2)
这样,非结构化的中文书目文本数据转换为结构化向量数据。
1.2 特征提取
该部分主要任务是从中文书目对应的词条向量中抽取具有区分能力的特征。常用的文本特征提取方法有:词频(Word Frequency)、文档频次(Document Frequency)、词频-逆向文件频率(Term Frequency-Inverse Document Frequency, TF-IDF)、互信息(Mutual Information)、期望交叉熵(Expected Cross Entropy)、信息增益(Information Gain)、文本证据权(The Weight of Evidence for Text)。不同特征提取方法对不同的文本数据的表达能力不同,需要依据数据的分布来选择最合适的特征提取方法。在中文书目分类领域,词频特征和词频-逆向文件频率特征应用较多[12]。
1.3 机器学习
中文书目数据对应的特征向量需要经过机器学习方法构建的分类器来进行分类。目前,机器学习方法很多,如Adaboost、决策树(Decision Tree)、随机森林(Random Forest)、人工神经网络(Nerve Net)、支持向量机(Support Vector Machine,SVM)、朴素贝叶斯(Naive Bayes)、深度网络(Deep Net)等。下面简要介绍中文书目分类领域常用的决策树、人工神经网络和支持向量机方法。
1.3.1 决策树
决策树以信息增益为训练依据,对训练样本集中的特征向量进行学习,构建由内部节点和节点组成的二叉树或多叉树结构。其中,每一个节点都包含一个逻辑判断函数,可以对输入该节点的特征进行判决,为其选择合理的分录路径。
1.3.2 人工神经网络
人工神经网络通过模拟人脑思维设计学习框架,以错误率为训练依据对网络中的权重和偏移量参数进行调整,寻找错误率最低时的网络参数来构建,可以对大规模样板数据充分学习,从而实现对未知数据的分类和预测。
1.3.3 支持向量机
支持向量机是建立在统计学习理论和结构风险最小原理基础上的一种机器学习方法,主要优点是可以实现小样本集的学习,泛化能力强,其决策函数仅由少数的支持向量确定,而不是样本空间的维数,这样不仅可以避免“维数灾难”,而且计算复杂度小,是目前应用范围较广、具有较好识别能力的机器学习方法。
2 改进的支持向量机中文书目自动分类
本文仍采用上述的基于机器学习的中文书目自动分类系统架构。与之相比,本文主要在文本特征提取部分进行改进,主要改进在于,将现有方法中常用的词频特征和词频-逆向文件频率特征进行融合,提高特征区分能力。并采用奇异值分解方法将特征矩阵变换到语义空间,增强特征的稳健性,最终提高中文书目分类的准确率。另外,在机器学习部分,针对中文书目分类的多元性,在现有二元SVM分类器的基础上设计联合SVM分类器,实现多类中文书目的自动分类。下面首先介绍本文方法涉及的基本理论,然后介绍本文方法的实现方法。
2.1 基本理论
本文方法涉及的基本理论主要有两个:奇异值分解和支持向量机,简要介绍如下。
2.1.1 奇异值分解
在线性代数中,奇异值分解(Singular Value Decomposition,SVD)是一种非常重要的矩阵分解,可以看作是正规矩阵酉对角化的推广。其数学公式为:
X=LSRT
(3)
其中:L和R分别表示左奇异向量矩阵和右奇异向量矩阵,S表示奇异值的对角矩阵。S的对角元素按从大到小的顺序进行排列。其中,奇异值越大,说明对应向量越重要。
奇异值分解与潜在语义索引(Latent Semantic Indexing)关系密切,对于词条和语料的关联矩阵,如果进行一次SVD分解,那么可以实现相似词条和语料的分类,同时得到词条和语料之间的相关性。因此,SVD也可称为语义空间变换。通过语义空间变换,将高维的文本数据转换为较低维度的隐含语义空间。
2.1.2 支持向量机
SVM的主要设计思想是寻找一个最优的分类超平面,使得分为不同类别的数据点之间的间隔最大。令{x1,x2,…,xn}表示样本数据集,则SVM分类超平面可以表示为:
wTx-b=0
(4)
其中:w表示分类超平面的法向量,b表示偏移量,x表示分类超平面上的点。
寻找在两个类别的数据集上与分类超平面平行的两个超平面,表示为:
(5)
(6)
s.t.yi(ωTxi+b)≥1i=1,2,3,…,n
(7)
其中:yi表示样本数据xi的类别标签。当xi为正样本时,yi=1;否则,yi=-1。
通过最优化求解,可以得到最优的参数w和b。这样,对于新输入的数据x,计算wTx-b的值,如果该值大于0,则判定该数据为正样本,否则判定为负样本。
SVM对于小样本数据的处理性能好,泛化能力强。
2.2 实现方法
本文方法的实现主要包括三个环节:文本预处理、语义空间变化和语义特征向量提取、联合支持向量机分类。详细介绍如下。
2.2.1 文本预处理
本文仍采用ICTCLAS分词系统来进行文本预处理。与文献[12]不同的是,本文在进行文本数据结构化转换时,更注重词条出现频率信息而不是词条是否存在信息,这样利于更充分描述文本数据。具体地,对于任意一条中文书目d,记录每一个词条出现的频率,可以得到一个向量f=[f1,d,f2,d,…,fn,d]T。其中,元素fi,d;i=1,2,…,n表示第i个词条在中文书目d中出现的次数。这样,非结构化的中文书目文本数据转换为结构化向量数据。
在机器学习阶段,整个训练样本集中的所有中文书目文本数据可以转换为一个维数为n×m的矩阵F,其中,m表示中文书目的数量。矩阵F可以表示为:
(8)
其中,矩阵中任意元素fi,j;i=1,2,…,n;j=1,2,…,m;表示第i个词条在中文书目j中出现的次数。
2.2.2 语义空间变换与语义特征向量提取
一般地,词条与语料库之间存在隐含语义关系,本文通过挖掘两者之间隐含的语义空间,来描述词条与语料库之间的联系。本文采用常用的TF-IDF方法进行文本数据的转换。该方法在数据挖掘和信息检索领域应用广泛,其主要设计思想是:某一个词条在某文档中出现的频率越高,而在语料库的其他文档中出现的频率越低,则该词条对于该文档而言的重要程度越高。给定语料库D,词条t和中文书目d,d∈D。则中文书目d的权重可以表示为:
tt,d=ft,d×log(|D|ft,D)
(9)
其中:ft,d表示词条t出现在中文书目d中出现的次数,|D|表示语料库中中文书目的数量,ft,D表示语料库D中出现词条t的中文书目数量。
这样,对于任意一条中文书目,采用TF-IDF方法可以得到一个特征向量t=[t1,d,t2,d,…,tn,d]T。
在机器学习阶段,整个训练样本集中的所有中文书目文本数据可以采用TF-IDF方法转换为一个维数为n×m的矩阵T,表示为:
(10)
也即,用每一个词条对语料库中每一个文档的权重来构建矩阵T,将非结构化的文本数据转换为结构化数据。
然而,当词条出现频次过大时,TF-IDF方法得到的权重会下降,影响特征区分能力。为此,本文融合词频和TF-IDF特征,构建的特征矩阵可以表示为:
X=λF+(1-λ)T
(11)
其中:λ表示加权权重。
类似地,特征向量之间的融合公式为:
q=λf+(1-λ)t
(12)
为了特征矩阵的冗余,尽可能地反映词条与文档之间的原始关系,本文采用SVD方法对特征矩阵X进行分解,如公式(3)所示。奇异值的对角矩阵S的对角元素按从大到小的顺序进行排列。奇异值越大,说明对应的词条向量越重要,词条与文本的关联性越强。可见,采用SVD分解之后的三个矩阵能反映词条与语料库之间语义联系。因此,本文将上述变换过程称之为语义空间变换。考虑到奇异值下降速度非常快,前10%的奇异值的和通常可以达到全部奇异值之和的99%以上了。因此,本文采用前k个奇异值来近似描述矩阵。简化后的矩阵记为:
Xk=LkSkRkT
(13)
其中:与S相比,矩阵Sk中只保留对角元素的前k个奇异值,其他位置的奇异值置为0。与L和R相比,矩阵Lk和Rk中只保留前k行向量,其他行的元素都置为0。
这样,可以通过语义空间变换,将高维的文本数据转换为较低维度的隐含语义空间。具体地,对于任意一个中文书目所对应的特征向量q,可以通过语义空间的变换将其转换为语义空间中相同维度的语义向量qk,表示为:
qk=Sk-1LkTq
(14)
本文将语义向量作为文档的特征向量,据此进行文档的分类。
2.2.3 联合支持向量机分类
基于机器学习的书目分类方法通常需要构建分类器来完成文档所对应特征向量的分类任务。考虑到支持向量机泛化能力强,计算复杂度样本空间维数关联小的特点,本文选择支持向量机方法进行特征向量的学习与分类。
由前面介绍可见,SVM分类器是一个二元分类器,分类结果只有正样本和负样本两类。对于书目而言,类别数肯定不止两类。为了实现多类书目数据的分类,本文设计联合SVM分类器,为每一个书目类别构建一个SVM分类器,通过各个SVM分类器的投票来得到最终的分类结果。在训练每一个书目的SVM分类器时,将训练数据集中该书目的数据看作正样本,而将其他书目的数据看作负样本,来训练SVM分类器。假设书目类别总数为C,那么可以得到C个SVM分类器,记为:
SVMi={wi,bi|i=1,2,3,…,C}
(15)
在分类时,对于输入数据x,可以计算C个分类得分,记为:
si=wiTx+bi
(16)
本文选择分类得分最大的类别作为数据x的分类类别,表示为:
(17)
在本文中,用于SVM训练和测试的数据为每一个文档所对应的语义向量qk。
3 实验与结果分析
本文通过中文书目的自动分类实验来验证本文所述的基于语义空间变换的中文书目数据挖掘方法的有效性。首先,我们从学校中文书目馆随机抽取了5个大类的中文书目作为实验数据集,包括D类书目3 364条,F类书目5 482条,I类书目3 638条,K类书目2 874条,T类书目4 877条,共计20 235条中文书目信息。一般地,中文书目信息包括书号、价格、书名、分卷号、分卷名、作者、版本项、出版地、出版社、出版时间、页码、开本、内容摘要、读者对象、分类号等字段信息。本文与文献[12]一样,选取书名和内容摘要这两个字段作为实验的测试语料,因为这两个字段能有效反映中文书目的主题。考虑到基于机器学习的中文书目自动分类方法一般包括机器学习和类目分析两个阶段,这里将中文书目数据集分为两个子集,一个为训练数据子集,另一个为测试数据子集。其中,训练数据子集是从每一类书目中随机抽取一半书目条目构成的,剩下的一半放入测试数据子集。下面首先介绍本文方法的实验情况,然后再与现有中文书目分类方法进行性能对比,验证本文方法的优势。
3.1 本文方法实验分析
本文方法的训练步骤如下。
Step1:文本预处理,构建矩阵F;
Step2:TF-IDF特征提取,构建矩阵T;
Step3:特征融合,构建特征向量q和矩阵X;
Step4:语义空间变换,得到矩阵Lk、Rk、Sk和Xk;
Step5:语义向量生成,得到语义向量qk;
Step6:机器学习,对不同类别的语义向量进行训练,为每一类中文书目构建一个SVM分类器。
本文方法的测试步骤是:
Step1:文本预处理,得到向量f;
Step2:TF-IDF特征提取,得到向量t;
Step3:特征融合,得到特征向量q;
Step4:语义向量生成,得到语义向量qk;
Step5:特征分类,得到对每一个类别的分类得分;
Step6:选择分类得分最大的类别作为分类结果。
本文方法涉及两个参数,分别是特征融合阶段的权重参数λ和SVD分解阶段的参数k。下面通过实验来选择最优的参数。
图1给出了参数λ取值不同时本文方法的分类准确率分布情况(此时SVD阶段不进行约简)。当λ=0时表示仅使用TF-IDF特征,当λ=1时表示仅使用词频特征。由图1可见,当参数λ取值为0.3时中文书目的分类准确率最大。这说明,TF-IDF特征的分类效果优于词频特征,融合TF-IDF特征和词频特征的分类效果优于单独采用一种特征的分类效果。
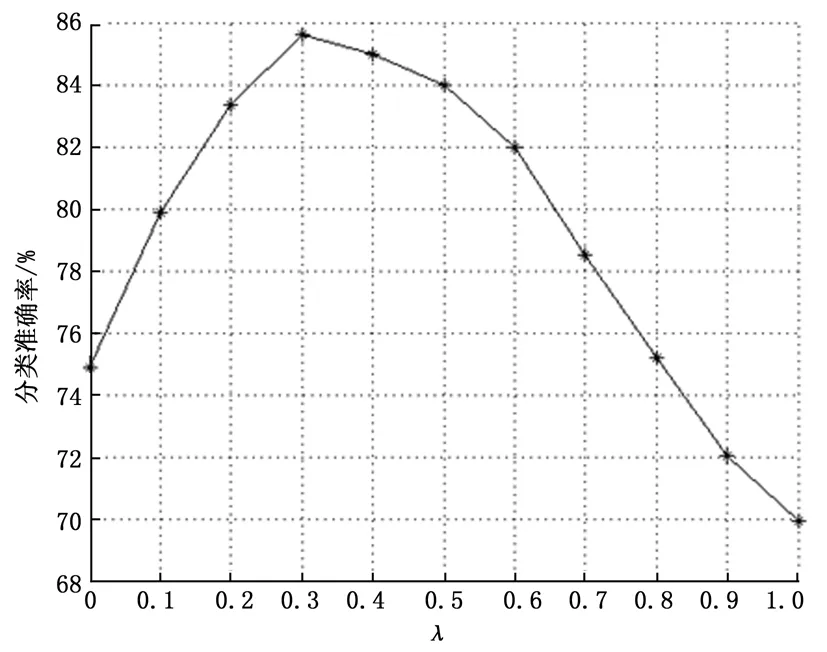
图1 参数λ取值不同时分类准确率分布曲线
图2给出了参数k取值不同时本文方法的分类准确率分布情况。可见,前期随着k的增加,分类准确率提升。当k=80时分类准确率增加不再明显,当k=120时分类准确率反而下降。这说明,词条与文档之间的关联关系主要体现在前80个奇异值上,后面的奇异值所含噪声偏多,不利于分类。
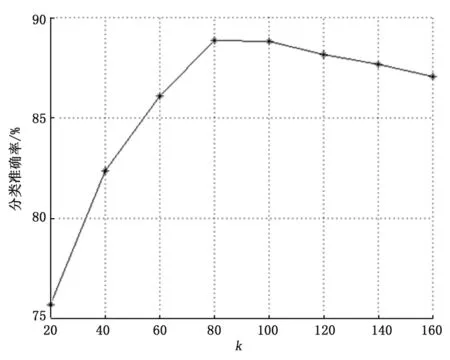
图2 参数k取值不同时分类准确率分布曲线
3.2 不同方法对比分析
下面将本文方法与文献[12-14]所述的三种中文书目分类方法进行实验对比,具体结果见表1。其中,文献[12]所述方法中特征选择混合特征,特征权重参数为0.5。文献[13]所述方法中分类器选用其实验性能更优的SVM分类器。本文方法的实验参数为:λ=0.3、k=80。四种方法所用的实验环境相同,计算机平台性能参数为:Intel I7 CPU、DDR3 16 G内存。软件开发环境为Matlab 2012。机器学习模块使用MATLAB自带的开发包。分词系统都采用ICTCLAS分词系统。
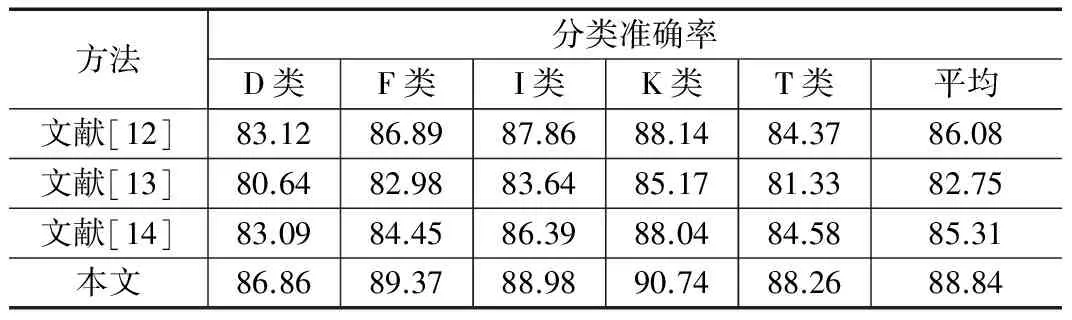
表1 不同方法分类准确率对比(单位:%)
下面对实验结果进行具体的分析。本文方法与文献[12]所述方法都使用了词频和TD-IDF特征,不过本文方法没有区分特征在标题或者摘要中的差异,而是通过两类特征的加权融合以及语义空间变换来生成文本表示特征。这样可以去除冗余,增强特征的稳健性,提高分类准确率。由表1可见,本文方法在D、F、I、K和T五类书目的分类准确率都高于文献[12]方法,且平均分类准确率高于文献[12]方法2.76%。与文献[13]方法相比,本文方法也使用了SVM分类器。然而在特征提取阶段,文献[13]中单独使用TD-IDF特征,而本文方法在此基础上融合了词频特征,特征区分能力增强。另外,本文方法在分类时构建联合SVM分类器,这也优于文献[13]方法使用的级联SVM分类器。因为使用级联分类器时如果某一层分类错误,那么分类结果就是错误的。而联合SVM分类器相当于每一个分类器都对分类结果进行投票,选择投票分数最高的类别作为最终的分类结果,这明显优于选择某一层分类结果。因此本文方法在五类书目上的分类准确率也都高于文献[13]方法,且平均分类准确率高于文献[13]方法6.09%。文献[14]所述方法与本文方法和文献[12-13]所述方法差异都较大,该方法的主要特点是构建复合特征,但在特征构建时使用了一些先验知识,导致特征的主观性较强,对数据的鲁棒性差。因此,在本文的测试数据下,该方法的分类准确率不高,在某些领域可能分类准确度较高,在五类书目上的分类准确率都低于本文方法,且平均分类准确率低于本文方法3.53%。总的来说,本文方法对五类中文书目的分类准确度都高于其他三种方法,平均分类准确率高于其他方法2.76%以上。
4 结束语
本文提出了一种基于语义空间变换的数据挖掘方法,主要设计思想是:融合词频和TF-IDF两种特征描述文本数据,结合奇异值分解实现语义空间变换,生成用于文本表示的语义向量,设计联合SVM分类器实现语义向量的学习与分类。通过进行中文书目自动分类实验,验证了本文方法能够提高中文书目分类的准确率。类似地,本文方法还可以用于其他文本分类与检索领域,有益于挖掘文本数据信息。
参考文献:
[1] Wu D, Olson D L. A TOPSIS Data Mining Demonstration and Application to Credit Scoring[J]. International Journal of Data Warehousing & Mining, 2017, 2(3):16-26.
[2] Nassirtoussi A K, Aghabozorgi S, Wah T Y, et al. Text mining for market prediction: A systematic review[J]. Expert Systems with Applications, 2014, 41(16):7653-7670.
[3] Mostafa M M. More than words: Social networks’ text mining for consumer brand sentiments[J]. Expert Systems with Applications, 2013, 40(10):4241-4251.
[4] He W, Zha S, Li L. Social media competitive analysis and text mining: A case study in the pizza industry[J]. International Journal of Information Management, 2013, 33(3):464-472.
[5] Huh J, Yetisgen-Yildiz M, Pratt W. Text classification for assisting moderators in online health communities[J]. Journal of Biomedical Informatics, 2013, 46(6):998-1005.
[6] Lin Y S, Jiang J Y, Lee S J. A Similarity Measure for Text Classification and Clustering[J]. IEEE Transactions on Knowledge & Data Engineering, 2014, 26(7):1575-1590.
[7] D’Aspremont A. Predicting abnormal returns from news using text classification[J]. Quantitative Finance, 2015, 15(6):999-1012.
[8] Sarker A, Gonzalez G. Portable Automatic Text Classification for Adverse Drug Reaction Detection via Multi-corpus Training[J]. Journal of Biomedical Informatics, 2015, 53:196-207.
[9] Uysal A K, Gunal S. The impact of preprocessing on text classification[J]. Information Processing & Management, 2014, 50(1):104-112.
[10] Murtagh F, Kurtz M J. The Classification Society’s Bibliography Over Four Decades: History and Content Analysis[J]. Journal of Classification, 2016, 33(1):6-29.
[11] Weldon S P. Organizing knowledge in the Isis bibliography from Sarton to the early twenty-first century.[J]. Isis;an international review devoted to the history of science and its cultural influences, 2013, 104(3):540-550.
