基于Android的智能健康养生点菜软件设计
2018-05-18卢颖仪张艳玲
卢颖仪,张艳玲
(广州大学计算机科学与教育软件学院,广州 510006)
0 引言
随着生活质量的提高,如今人们越发关心起了“怎么吃”才健康这个问题。然而,不是每个人都是专家,那么,针对没有研究过健康养生知识的普通人,“怎么吃”就成为了一个值得探讨的问题。因此,本文设计了一款“智能健康养生点菜系统”来为人们提供健康点菜服务。
近年来,营养学在国内外都得到了很大的发展,许多国家的营养学专家或团体先后制定发布了《膳食营养素参考摄入量(DRIs)》。中国营养学会于2013年完成了《中国居民膳食营养参考摄入量》的修订,为中国居民提供了一系列营养成分的每日摄入量的参考标准[1]。根据该文献提出的几个参数标准,不同属性的人群可以针对自身情况选择不同的饮食方式,以养成更为健康的饮食习惯。另外,合理地摄取营养素、养成健康的饮食习惯,甚至对某些疾病具有改善病情的作用。曾经有学者在美国康涅狄格州、新泽西州以及华盛顿州针对食管癌与胃癌患者,进行了一项营养素摄入量与发病率的关系的研究,研究结果表明,部分营养素的摄入量与癌症发生的风险是负相关的,另外一部分则是正相关[2]。日本消化外科名医济阳高穗先生经过40年临床研究以及14年追踪调查,为癌症病人独创了济阳式食疗法,该食疗法治疗有效率高达64.5%,其中完全治愈病例30例,改善病例106例[3]。中国营养专家李卉与肝病专家、肠胃病专家王伟岸,共同编制了针对肝病患者、肠胃病患者的健康饮食指南,从各个方面提出了针对不同患者的食疗法,为不同患者提出了不同的饮食禁忌及建议。数据表明,有七成以上的脂肪肝、酒精肝患者通过合理膳食得到了明显的改善,同样地,有九成以上的人群通过饮食远离了肠胃病[4-5]。中国中医诊断学博士、中西医结合临床博士后王志国则针对糖尿病患者、高血压患者编写了饮食指南,详细介绍了各种食材、菜品及按摩穴位、运动方式,将患者的日常饮食和居家调养方式以简明易懂的方式介绍给广大患者及其家属。通过日常饮食调养,九成以上的患者的病情都能轻松得到控制[6-7]。
本文通过对文献[1-7]的研究,设计了一套健康搭配食材的算法,实现一款由系统进行数据处理、直接搭配食材的软件。再利用关联规则挖掘算法中的FPGrowth算法对搭配算法进行优化,通过关联规则获取用户喜好的食材搭配信息,为用户提供更好的服务。
本系统最重要的创新点就是能够根据用户需求直接为用户推荐一系列搭配在一起较为健康的食材,再由用户根据个人喜好从中选择一部分作为最终菜单。这将大大减少用户自行选择食材的复杂性,为用户提供便利。
1 营养素与人体、食材、疾病的关系研究
本文结合文献[1]提出的几个参数以及对文献[3-7]的研究,得到了4个将会使用到的参数(参数名称为文献[1]中确定的名称):推荐摄入量(以下简称RNI),适宜摄入量(以下简称AI),宏量营养素可接受范围(以下简称AMDR),预防非传染性慢性病的建议摄入量(以下简称 PI)。
RNI与AI指的是人体每日需要摄取营养素的一个标准,即可以满足某一特定年龄、性别及生理状况群体中绝大多数个体对于某种营养素的需要量的摄入水平。两者不同的是AI是通过观察或实验所获得的,当研究资料不足,无法推算出RNI时,才使用AI作为参考摄入量。AMDR指的是人体新陈代谢的三大基础营养素蛋白质、脂肪、碳水化合物的理想摄入量范围。PI是针对某些疾病对不同营养素提出的一个建议摄入量。而本文将文献[1]中的PI值与文献[3-7]所得数据结合,得到针对肠胃病、糖尿病、肝病、高血压或癌症患者的适宜、禁忌营养素。
以上参数针对不同年龄层、不同性别、不同生理状况的人群都有不同的标准,而本系统假设主要使用人群为18-50岁的健康人群或特殊疾病人群(癌症、糖尿病、高血压、肠胃病或肝病患者),将以上参数的具体值整理归纳并简化为针对特定年龄层的群体的标准,并将营养素的摄入含量标准定义为高、中、低3个级别。
1.1 营养素与人体
为了维持生命的需要,人体每日需要均衡摄取一定量的不同营养素。对于蛋白质、脂肪、碳水化合物这三种提供能量的营养素而言,人体每日需要摄取足够的量,才能支持人体新陈代谢的需求。对于其他的维生素和矿物质,摄取不足或过多都可能导致某些疾病的发生,或是造成代谢紊乱。
本文综合RNI值、AI值与AMDR值,总结了共33种人体需要摄取的营养素及其每日需要摄取的高低值。这33种营养素包括蛋白质、脂肪、碳水化合物、多种维生素以及多种矿物质。
1.2 营养素与食材
人体是通过食物来摄取营养素的,而不同的食材所含有的营养素种类或含量都有所不同。本文从文献3-7]中总结出共110种食材及其含有的营养素含量,根据同种类食材之间的对比,将所含营养素的含量定义为“高”、“中”、“低”三个含量标准,从而作为判断人体每日摄取营养素多少的依据。
除去营养素含量不同,食物还存在着相生相克的说法。相生,指两种或多种食物搭配在一起,起到了相辅相成的作用,更具营养价值。相克,指两种或多种食物搭配起来会破坏营养成分,引起人体不适,造成生病甚至中毒死亡。本文整合了上述110种食材的相生相克食材,以此作为生成推荐菜单的依据之一。
1.3 营养素与疾病
对于不同疾病而言,都有其饮食禁忌规范,这种规范就包括营养素种类及其摄取量。也就是说,每一种疾病都有其适宜或禁忌的营养素。适宜营养素为对该疾病有益的必备营养素,禁忌营养素为可能加重病情的营养素。对于特殊疾病人群,推荐食用富含适宜营养素的食材,反对食用富含禁忌营养素的食材。
本文通过对文献[1-7]的研究,得到了针对肠胃病、肝病、糖尿病、高血压以及癌症这5类疾病的PI值,即这些疾病的适宜营养素集合与禁忌营养素集合,作为生成针对特殊疾病人群的推荐菜单的依据之一。
2 健康菜单生成算法设计
系统首先获取用户设置的基本信息,即用餐人数、患病信息、主要菜品,再根据一定的算法,由用餐人数计算出较为合适的荤素菜个数,由患病信息、主要菜品得到营养素、相生相克食材的信息,从而筛选出一系列符合条件的不同种类食材,作为推荐菜单展示给用户。
2.1 菜品个数的推荐
根据用餐人数的不同,菜品个数以及荤素搭配也有所不同。此处设置菜品个数比用餐人数多1个,分为素菜和荤菜,具体的食材则由用户自己决定。计算的流程图如图1所示。
图1是获取推荐菜品个数的处理流程图,推荐菜品个数比用餐人数多1个。当用餐人数为单数时,荤菜与素菜的个数相同;当用餐人数为双数时,设置荤菜数量为用餐人数的一半,而素菜比荤菜多1个。由于本系统推荐的只是一餐中的食材搭配,因此,最终食材的做法,以及具体搭配成菜的食材,还是由用户自己决定。
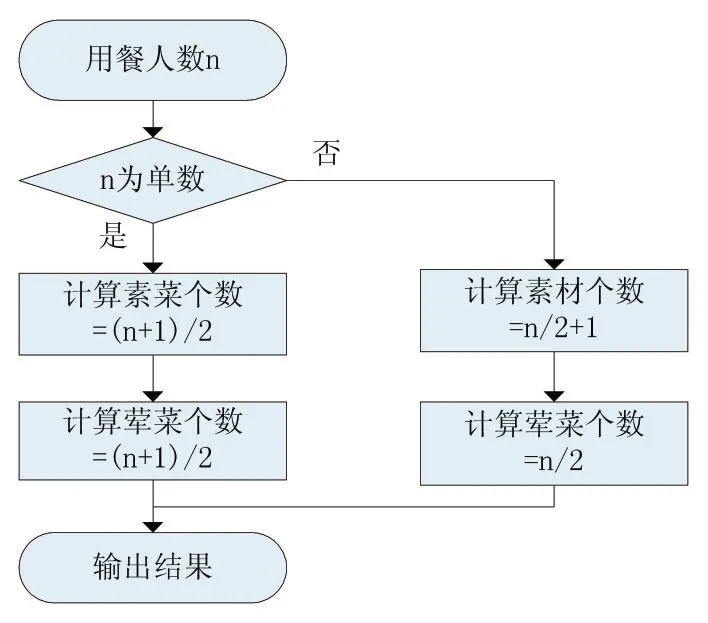
图1 推荐菜品个数处理
2.2 具体食材的推荐
(1)数据表的建立及与代码的映射
要获得最终的推荐菜单,首先要对食材信息等进行基本的处理。建立一个合理、简洁的数据库,并在代码中形成与数据表对应的简单Java类[8]。
Android使用的是轻量级的嵌入式关系型数据库SQLite。在Android中,数据库保存在默认目录data/data/包名/databases下,程序运行时,将apk中的数据库复制到该目录下,再由系统对数据库进行访问。访问数据库时,系统首先利用Android提供的类SQLiteOpenHelper,对数据库进行创建、打开等操作,之后则利用SQLiteDatabase类获取数据库,并对表进行增、删、改、查等操作[9]。
在本系统的数据库food.db中,一共包含了7张数据表。其中,前4张为实体表,后3张为关系表,如图2所示。
(1)表 FoodType(FTid、FTname):食物种类表,记录食物种类的编号与名称。
(2)表 Food(Fid、Fname、FTid、Fdescription):食物基本信息表,记录食材的基本信息,包括编号、名称、种类编号、功效。
(3)表Nutrient(Nid、Nname、Nneed):营养素基本信息表,记录营养素的编号、名称、每天需要摄入量(3、2、1 分别表示“高”、“中”、“低”)。
(4)表 Sickness(Sid、Sname):疾病表,记录疾病的编号与名称。
(5)表 FN(Fid、Nid、FNcontent):食物营养素关系表,记录每个食材对应每种营养素的含量高低。
(6)表 SN(Sid、Nid、SNsuit):疾病营养素关系表,记录每种疾病的适宜、禁忌营养素。
(7)表Effect(Fid_1、Fid_2、good、effect):相生相克食物表,记录每种食材的相生相克食材及其产生的影响。
由此,得出了从图 2(a)到(b)的映射。在图 2(b)中,每个类的属性都对应其数据表中的字段,这样,在查询数据库的时候,就可以将查询到的每一条数据包装成一个对象,在进一步处理时可以被更方便的使用。
(2)对用户自选食材的处理
用户在Android端自行选择一个或几个主要菜品,添加到自选食材菜单中,由系统对食材进行处理。处理流程如图3所示。
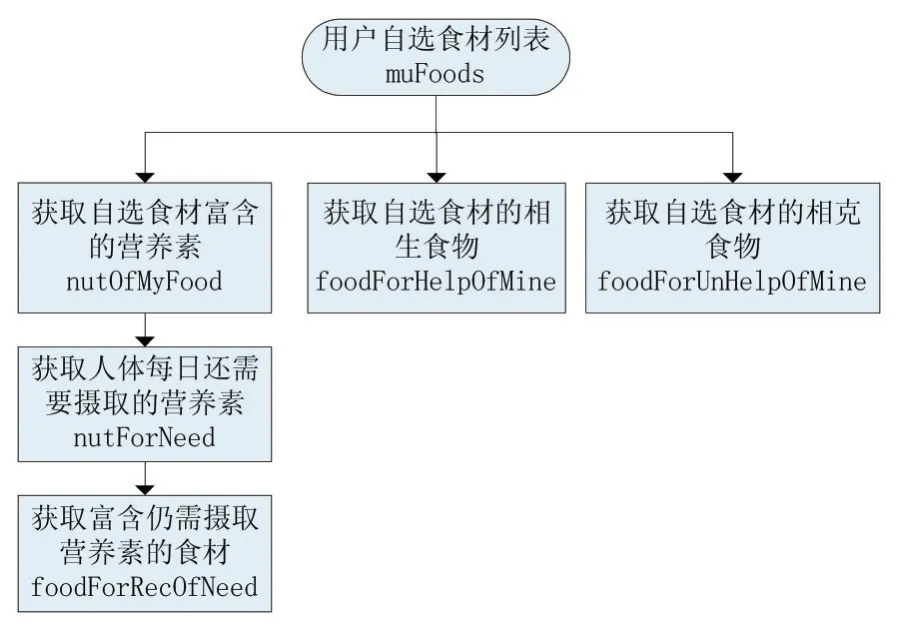
图3 用户自选食材处理流程
(3)对用户患病信息的处理
用户在Android端根据自身情况选择是否患病、患的是何种病,确认后保存下来,由系统对疾病信息进行处理。
处理流程如图4所示。
结果将对图3与图4产生的食材列表进行整合,去除重复元素保存在List中,待前台调用。
(4)算法流程
此部分的输入信息包括用户自行选择的一个或几个主要食材,以及用户自行选择的患病列表。本算法对这两部分的输入信息进行处理,整合获取的推荐食材,再去除不推荐的食材,得到最终的推荐菜单。
由类RecommendService对算法进行处理,用到的变量说明如表1所示。
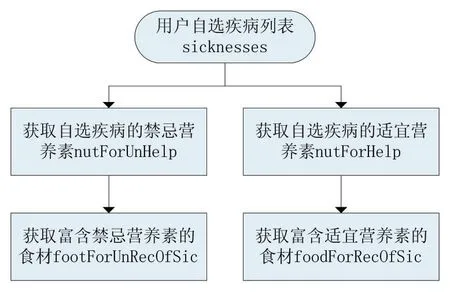
图4 用户患病信息处理流程
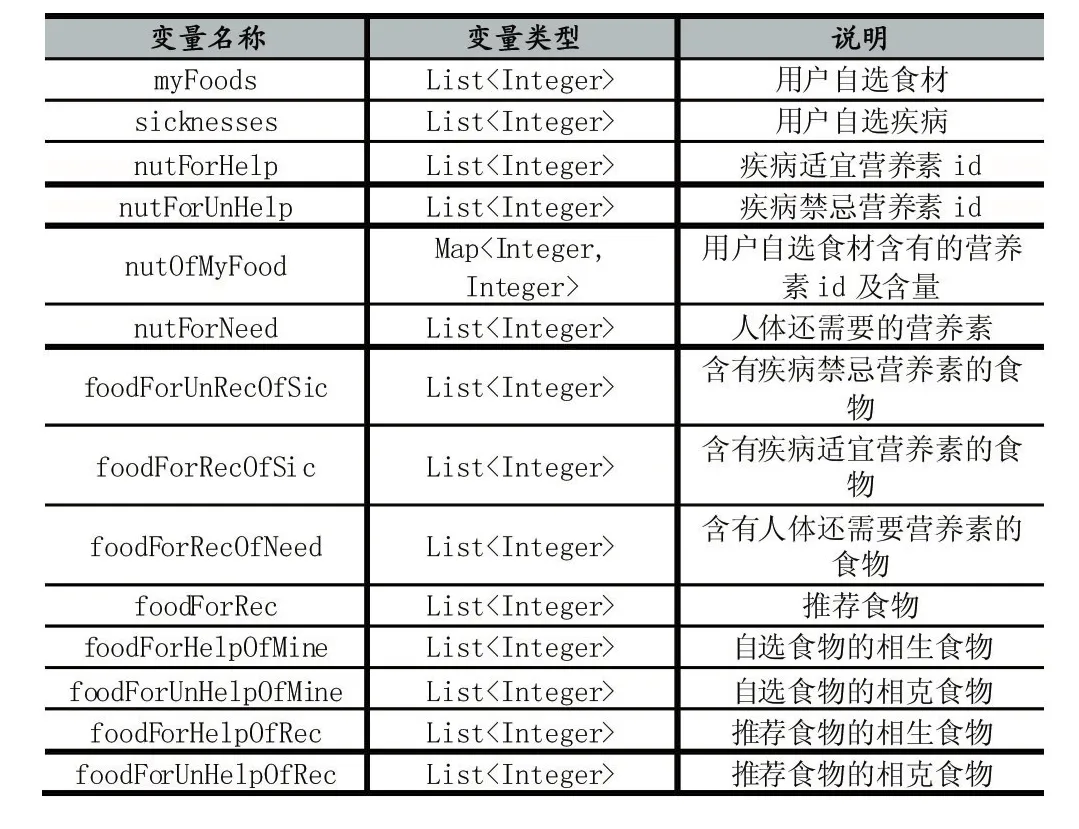
表1 变量说明表
根据图3与图4,对用户自选食材的处理过程分为以下几个步骤。
(1)用户设置基本信息
在程序运行时,Android端将弹出两个对话框,由用户输入用餐人数、选择是否患病,程序将记录用户输入的信息。假设用户设置用餐人数为4人,患有糖尿病、肠胃病。
(2)用户选择食材
用户通过选择食物种类,进入不同种类的食物名称列表,再选择具体名称,查看食物信息,并点击添加按钮将该食物添加到用户自选菜单中。
在进行步骤1、步骤2的时候,系统将保存用户输入的信息,在生成推荐菜单时由类RecommendService调用,整合成List型变量myFoods与sicknesses。
2 系统推荐食材搭配
(1)获取疾病适宜、禁忌营养素:通过调用SicknessDao接口中的findNutForHelp()方法,设置其参数snsuit为1或0,利用HashSet去除重复元素,最后传递到变量nutForHelp、nutForUnHelp中。
推荐食材时,富含禁忌营养素的食材将作为不推荐的部分,若用户选择了此部分食材,系统提醒用户,建议不要继续选择添加。
(2)若用户并没有选择添加食材,即myFoods列表为null,则忽略此步骤;反之,获取自选食材含有的营养素:用户的自选食材列表中,可能存在不止一个的食材,而这些食材可能含有相同种类、不同含量的营养素。这里利用HashMap的特性去除重复的营养素,并更新重复营养素的含量。nutOfMyFood数据类型为Map<Integer,Integer>,其 key值为营养素 id,value值为营养素含量(3、2、1表高、中、低)。当两种食物中含有相同的营养素,将比较其含量,含量相同且其值小于3,则将map中对应key的value值加1,若含量不同,则将value值更新为两者营养素含量中较大的一方。
(3)获取还需要的营养素:此处认为nutForNeed=人体所需营养素(所有)-nutForUnHelp-nutOfMy-Food。通过接口NutrientDao中的findAll()方法,可获取数据库中人体每天所需的所有营养素,首先通过List提供的remove()方法去除疾病禁忌营养素,得到剩下的营养素列表及摄取量高低。再比较该列表与nutOfMyFood,若nutOfMyFood中某营养素的含量大于列表中的推荐摄取量,则表示不再需要该营养素,不添加到nutForNeed中;反之,表示需要,添加到nutForN-eed中。
在下面的步骤中,将会找到富含列表nutForNeed中营养素的食材,作为推荐食材的一部分。
(4)获取富含疾病适宜营养素、疾病禁忌营养素、人体还需要营养素的食物列表:三个列表都通过调用NutrientDao中的findFoodById()方法得到,输入数据为nutForHelp、nutForUnHelp、nutForNeed,得到变量 food-ForRecOfSic、foodForUnRecOfSic 以 及 foodForRecOf-Need。其中,foodForRecOfSic与 foodForRecOfNeed整合去除重复元素,得到推荐食物列表foodForRec以及疾病不推荐食物列表foodForUnRecOfSic。
可以看到,在用餐人数较少,选择食材较少的情况下,得到的推荐食物非常多,几乎包含了数据库中保存的所有食材,这是本算法的一个没有实现好的地方。而富含疾病禁忌营养素的食物,是不推荐用户食用的。
(5)获取相生相克食材列表:输入数据为myFoods、foodForRec,根据接口 FoodDao 中的 findFoodForHelp()方法,设置其参数good为1或0,获取自选食材、推荐食材的相生相克食材列表,输出为foodForHelpOfMine、foodForUnHelpOfMine、foodForHelpOfRec、foodForUn-HelpOfRec。
此步骤得到的是相生相克食材,在最终的推荐列表中,不会出现相克食材,而且,当用户自己选择添加食材时,若选择了已添加食材的相克食材,系统会提醒用户,并建议不要继续选择添加。
(6)结果整合:设置 List<Integer>变量 list暂时存放结果,将 foodForRec、foodForHelpOfMine以及 food-ForHelpOfRec添加在list中,再去除foodForUnRecOf-Sic、foodForUnHelpOfRec、foodForUnHelpOfMine,得 到结果,再通过食物种类,将不同种类的食物通过分类ListView,最后显示在推荐菜单上。
4 基于FP-Growth算法优化推荐菜单
推荐菜单虽然已经经过筛选,但其生成的食材数量还是会比较多,而每次由用户自己再在推荐菜单中选择,会造成一些不便。因此,对推荐菜单进行优化处理。
在数据挖掘中的关联规则领域里,有一个关联分析的非常经典的实例——购物篮分析。在超市的购物数据中,关联分析可以发现顾客频繁地同时购买的商品,通过这种规则对超市商品进行陈列,会为超市带来更大的收益[10]。
本文所实现的推荐菜单,其实可以被称为购物篮事务(market basket transaction),每一个成功的推荐案例,对应一个事务。通过对成功案例数据的关联分析,可以找到食物之间的关联性,即用户在选择某样食材时,会比较喜欢与哪些其他食材进行搭配。
本文使用FP增长算法来发现频繁项集与关联规则。
4.1 FP-Growth算法简介
在关联规则挖掘算法中,使用支持度和置信度作为关联规则强度的度量[11]。首先给出FP-Growth算法的几个定义。
定义1令I={i1,i2,…,id}是输入数据中所有项的集合,T={t1,t2,…,tN}是所有事务的集合,每个事务ti所包含的项集都是I的子集。
定义2如果项集X是事务ti的子集,则称事务ti包含项集X。项集X的支持度计数为:

定义3对于两个不相交项集X、Y,关联规则表示形如:X→Y。则该关联规则的支持度指项集X与Y的的并集在所有事务中出现的频繁程度,形式定义如公式(2)所示。置信度则是项集Y在包含X的事务中出现的频繁程度,形式定义如公式(3)所示。

FP-Growth算法是关联规则挖掘算法中对于算法Apriori算法的改进[12]。FP-Growth算法使用FP树的数据结构来组织数据。首先计算输入的事务数据集的每一个项的出现频数,去除低于最小支持度的项,并将其他频繁项按频数由大到小的顺序排列。将事务数据集的每一行数据(可以来自数据库)逐个读入,每一个事务映射到FP树中的一条路径。对于整个事务数据集,系统将逐条读入数据,对FP树进行扩充。FP树的每一个节点记录了一个项的标记以及计数。在读入数据时,可能会遇到重叠的路径,此时将路径上对应节点的计数值加1。
构造出FP树之后,FP-Growth算法以自底向上的方式探索树。首先根据FP树,找到每个项集作为结尾的前缀路径,通过处理每个项集的路径,得到新的事务数据集,更新前缀路径中的支持度计数并删除非频繁的项,递归构建条件FP树,直到事务数据集为空。最终得到输入的事务数据集的频繁模式项,再由此计算出关联规则及其支持度与置信度。
4.2 利用关联规则优化推荐菜单
每个频繁k-项集可以产生最多2k-2个关联规则。通过FP-Growth算法产生频繁模式集后,根据得出的频繁模式集,可以得到每个项之间的关联规则,并根据公式(2)、(3)计算出各个规则的支持度与置信度。支持度指的是项集X与Y同时出现在一个事务中的可能性,置信度指在X存在的条件下,Y产生的概率。
本文以支持度、置信度为主要衡量标准。置信度高表示用户多次在选择了某食材的前提下选择了另外的一种或几种食材作为配菜,支持度高表示用户多次选择了这样的食材组合,说明用户再次选择同样食材组合的可能性会比较大。
但是,根据支持度-置信度框架得到的结论也是具有局限性,可能有意义的模式由于其支持度或置信度较低,会被排出。而随着用户使用软件次数的增加,输入到FP-Growth算法的事务数据集也随着增加,而设置的支持度阈值也慢慢加大,就会得到一个越来越可靠的结果。
因此,随着事务数据集的增多(用户使用软件次数越多,保存在数据库中的训练数据越多),最小支持度也会有所变化。
最小支持度=事务总数/4
而对于置信度,由于用户选择的食材可能会比较分散,系统产生的关联规则计算出的可能会也会偏小,若最小置信度设置的值太大,会将大部分关联规则筛选掉,因此,此处将最小置信度设置为0.4。
优化过程中,系统首先接收到用户输入的自选菜单集(即一个项集),判断该项集的排列组合是否存在于已有关联规则的条件中。若存在,则将结果保存在List中,生成推荐菜单时,将结果输出,表示用户可能会喜欢这样的食材搭配。
5 实验结果与分析
5.1 开发平台
本系统选择Android系统作为软件的开发平台。在开发软件过程中,使用Eclipse ADT作为开发工具,运用Java语言进行开发。开发数据库时,则使用SQLite3作为数据库管理系统。
测试时,首先使用Eclipse的虚拟机进行测试,完成后,再在不同型号、系统的真机上进行测试。测试时使用的机型与测试结果如表2所示:
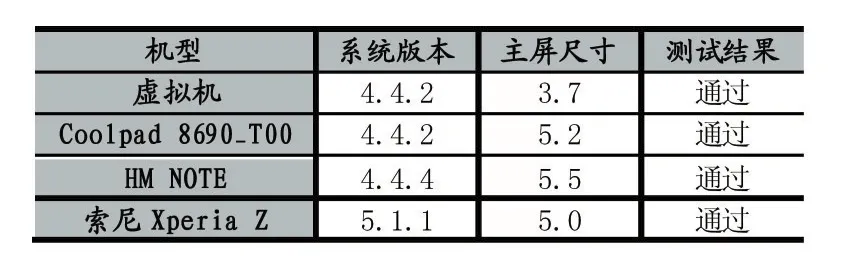
表2 测试机型与测试结果表
5.2 运行结果
打开应用界面,用户首先通过对话框设置用餐人数以及患病信息,如图5、图6所示。
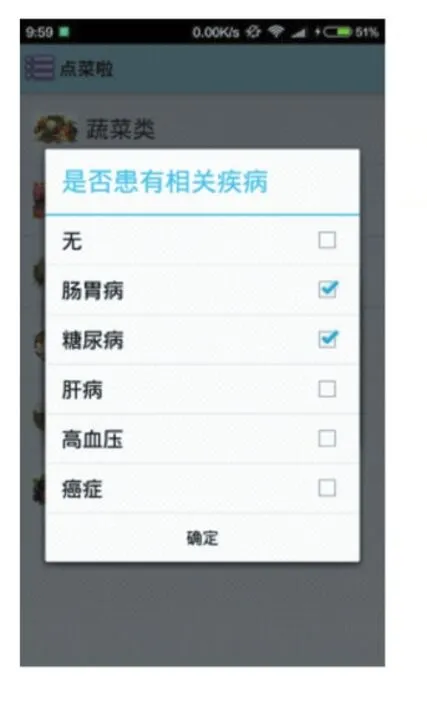
图5 设置患病信息对话框
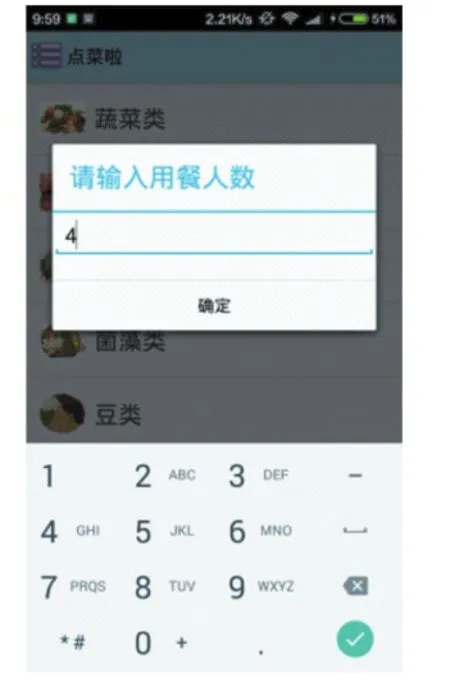
图6 设置用餐人数对话框
此处假设用餐人数有4人,其中一个患有肠胃病,另外一个患有糖尿病。进入系统后,在导航界面可以看到用户设置的基本信息,通过导航进入推荐菜单页,如图7、图8所示。用户可以直接选择推荐菜单里的食材进行添加,或者通过导航栏返回食材的全部分类页,查看所有种类的所有食材,再根据自己的喜好来添加食材。

图7 导航页

图8 推荐菜单
在用户添加食材的过程中,如果选择了其患病不推荐食用的食材,或者是已选择的食材的相克食材,系统会提示用户,并询问是否继续添加。
添加食材完毕,用户可以选择返回,通过导航进入“我的菜单”,或者通过食材信息页、食材列表页右上角的更多按钮,点击进入“我的菜单”。在“我的菜单”中,用户可以查看自己所添加的食材,按需求可进行批量删除操作。
当用户退出应用时,系统将在数据库中自动保存“我的菜单”中的食材,作为一次点菜的成功案例。在用户下一次使用软件时,通过FP-Growth算法挖掘关联规则,获取用户可能喜欢的与已选食材搭配的食材,在推荐菜单中显示给用户。
6 结语
本文主要研究基于Android的智能健康养生点餐软件,以及在完成推荐菜单的基础上,基于关联规则挖掘算法FP-Growth的优化分类方法。本文首先分析了营养素、食材、疾病与人体的关系,依据养生知识确立了推荐菜单的生成过程,其影响因素有五个方面:人体每天需要摄取的营养素成分高低、用户是否患有疾病或疾病适宜禁忌营养素、用户自己选择的主要食材、食材之间的相生相克、用餐人数。为了使用户得到更好的体验,本文将每次成功的推荐菜单保存为事务数据集,通过FP-Growth算法进行关联规则的挖掘,最后以关联规则及其支持度、置信度为基础,用户再次点菜时,通过查询是否存在关联规则的条件为用户自选菜单,筛选出对应的结果,对推荐菜单进行优化。
参考文献:
[1]程义勇.《中国居民膳食营养素参考摄入量》2013修订版简介[J].营养学报,2014,36(4):313-317.
[2]Mayne S T,Risch H A,Dubrow R,et al.Nutrient Intake and Risk of Subtypes of Esophageal and Gastric Cancer[J].Cancer Epidemiology Biomarkers&Prevention,2001,10(10):1055-1062.
[3]济阳高穗著,鲁雯霏译.癌细胞害怕我们这样吃[M].南昌:江西科学技术出版社,2015.1.
[4]李卉,王伟岸.肝病害怕我们这样吃[M].南昌:江西科学技术出版社,2015.5.
[5]李卉,王伟岸.肠胃病害怕我们这样吃[M].南昌:江西科学技术出版社,2015.5.
[6]王志国.糖尿病害怕我们这样吃[M].天津科学技术出版社,2015.
[7]王志国.高血压害怕我们这样吃[M].天津科学技术出版社,2015.
[8]李兴华.Java核心技术精讲[M].北京:清华大学出版社,2013.10
[9]唐磊.浅谈SQLite数据库技术在Android平台的应用[J].电子世界,2014(9):12-13.
[10]Han J,Kamber M.Data Mining Concept and Techniques[M].2006.
[11](美)谭,(美)斯坦巴赫著.数据挖掘导论[M].范明等译.北京:人民邮电出版社,2006.5。
[12]Sidhu S,Kumar Meena U,Nawani A,et al.FP Growth Algorithm Implementation[J].International Journal of Computer Applications,2014,93(8):6-10.
[13]吕雪骥,李龙澍.FP-Growth算法MapReduce化研究[J].计算机技术与发展,2012(11):123-126
