基于多元回归分析方法的颜色与物质浓度辨识建模
2018-05-16田茹会
田茹会
(陕西能源职业技术学院基础课教学部,陕西咸阳,712000)
0 引言
采用比色法检测一种物质浓度,其原理就是把待测物质制备成溶液后滴在特定的白色试纸表面,等让其在白色试纸上充分反应后获得一张有颜色的试纸,再与标准比色卡进行对比,就可确定待测物质的浓度档位。由于人对颜色认知都有差异,其敏感程度不同就使其观测产生误差。随着照相技术和颜色分辨率的提高,希望建立颜色读数和物质浓度的数量关系,即只需输入照片中的颜色读数就可获得待测物质的浓度。试根据题中提供的有关颜色读数和物质浓度数据对下面几题进行求解。
问题一:由附件1[1]所给出5种物质在不同浓度下的颜色读数,讨论从给出的这5组数据中能否确定颜色读数与物质浓度间关系,并用一些准则来评价这5组数据的优缺点。
问题二:对附件2中的数据,建立颜色读数和物质浓度的数学模型,并给出模型的误差分析。
问题三:讨论数据量和颜色维度对模型的影响。
1 模型分析与建立
1.1 问题一的模型建立与求解
依题意,五种物质在不同的浓度下多组数据进行对比,将各组数据进行整合处理,得出不同浓度与颜色读数的线性关系。将浓度设为纵轴,将蓝色、绿色、红色,设为横轴。利用Excel画出散点图,确定拟合函数的趋势线,求出颜色读数与物质浓度的关系式和可决系数,评测五组数据的优劣。
由组胺的不同颜色读数与其浓度的拟合趋势图,建立多元线性回归模型[2]进行数据分析,得出关系式为:y=182.3872-0.17185x1-2.28877x2+0.651217

图1 组胺的拟合趋势图
该函数的拟合函数可决系数[3]R2=0.9951,随着颜色读数的增大,其浓度不断减小。两者呈负相关。
做出溴酸钾的不同颜色读数与其浓度的拟合趋势图,建立多元线性回归模型进行数据分析,得出关系式为:y=210.0542-1.143744x1+7.35832x2-7.46947x1
该函数关系式可决系数R2=0.9146,说明该函数拟合程度高,与真实情况接近。
做出工业碱的不同颜色读数与其浓度的拟合趋势图,建立多元线性回归模型进行数据分析,得出关系式为:y=15.60879+0.07411x1+0.04693x2-0.011609x3
该函数关系式可决系数R2=0.8856,说明该函数拟合程度高,与真实情况接近。
做出硫酸铝钾的不同颜色读数与其浓度的拟合趋势图,建立多元线性回归模型进行数据分析,得出关系式为:y=7.84906+0.035596x1-0.10072x2+0.00295x3
该函数关系式可决系数R2=0.5035,说明该函数拟合程度不是很高,与真实情况有一定差距。
奶中尿素的数据中存在一组使拟合曲线出现误差较大的值,所以将浓度为5时的点剔除,得出奶中尿素的不同颜色读数与其浓度的拟合趋势图,建立多元线性回归模型进行数据分析,得出关系式为:y=10862.5-103.777x1+29.68822x2+16.5644x3
其可决系数为R2=0.9102,说明最接近与真实情况,拟合程度最好。
由以上结论得出在颜色读数不断增大的过程中其浓度不断减小,两者成反比关系。根据五组数据中得出的拟合线性关系,由可决系数得出各组数据中的优劣如下。
组胺:绿色读数最接近真实值,红色读数与蓝色读数也较为真实,整体较为真实。
溴酸钾:蓝色读数较为接近,但是红色读数误差较大。整体接近真实值。
工业碱:红色读数较为真实,蓝色读数误差较大,整体略有偏差。
硫酸铝钾:三种颜色读数都误差较大。整体误差很大。
奶中尿素:蓝色读数较为真实,剔除其中一组数据后,其它两组拟合度越高,其整体误差略小。
1.2 问题二的模型建立与求解
建立多元回归模型,得到颜色读数和物质浓度的数学模型,通过附件2中数据的处理研究分析,选取了3个变量:蓝色颜色值x1,绿色颜色值x2,红色颜色值x3作为自变量(i=1,2,3),浓度为因变量y,以下为处理附件2之后的数据。

表1 二氧化硫数据的处理
建立线性回归模型可表示为:y=β0+β1*x1+β2*x2+β3*x3
利用散点图绘制图2。

图2 颜色读数与浓度关系散点图
其中横轴为颜色读数,纵轴为物质浓度。
其可决系数R2=0.921198,其数值接近真实值,拟合出的较真实。
利用excel处理数据得出残差图。
如图在残差图中的散点在中轴上下两侧分布,则拟合直线就是合理的,说明预测有时多些有时少些,总体是符合趋势的。

图3 残差图
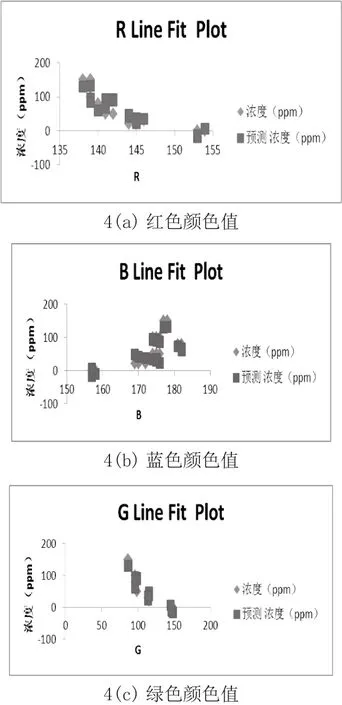
图4 线性拟合图
以上数据和图表证明其符合多元线性回归,其回归方程为:
y=628.755+6.63834x1-5.67807x2-5.23354x3
误差分析如表2所示。

表2 误差分析
1.3 问题三模型的建立与求解
1.3.1 数据量对模型的影响
针对问题中的数据量对模型的影响,做出小组数据与大数据的对比,对数据中的二氧化硫进行分析对比如下。
根据问题二可得出二氧化硫不同颜色读数所对应的浓度值,现将所给数据中的色调与饱和度加入数据进行拟合得出新的线性回归关系,其中横轴为读数,纵轴为浓度。

图5 二氧化硫浓度图
得出其拟合可决系数为R2=0.948456,说明最接近与真实情况,拟合程度最好。利用excel处理数据得出残差图。
如图在残差图中的散点在中轴上下两侧分布,则拟合直线就是合理的。得出其多元线性回归关系为:
y=2846.291+0.647167x1-19.9277x2+5.272859x3-4.89616x4-10.3539x4
大类数据中会存在一定误差,用excel对给出的数据进行误差分析。
在小组数据中可决系数R2=0.921198;在大数据中可决系数R2=0.948456;从中可以直观看出大类数据更为精确,其对模型的影响更小,在误差分析中,小组数据中的误差波动范围较广,在[-17.5978,131.6014]之间,整体影响较大,在大类数据中误差波动范围为[-14.1767,21.3614]1,在其范围内也更加直观的看出大类数据更为精确,所以,数据量的多少对其模型的影响很大,数据量越多,越能直观反应整体情况。

图6 残差图
1.3.2 颜色维度对模型的影响
由附件中二氧化硫的数据进行分析和估算,首先利用色调和饱和度对物质浓度的影响进行分析,得出两种量与浓度的线性关系,再由此衍生出三种颜色中每一种颜色分别与色调和饱和度的关系,进一步分析两种颜色分别与色调和饱和度的线性关系,更加直观的得出颜色维度对模型的影响。其中y4为色调读数,y5为饱和度读数,分析结果如下。

表3 颜色维度对模型的影响
将以上数据处理,利用excel将一种颜色值和两种颜色值进行误差分析,建立数学模型,再将一维模型与二维模型进行对比。得出色调和浓度之间不成线性关系,距离真实值有很大差距,预测值和数据给予的值也存在很大误差,所以不能推断出色调与颜色和浓度之间模型相互的线性比例关系,而在饱和度与颜色和浓度的关系中,得到饱和度和浓度的拟合值很高,而且在各种颜色读数中数据和饱和度也可以拟合出很精确的值,但是当颜色超过一种进行拟合时,可决系数很小,远离真实值,因此得出结论:在颜色维度中,可以由一维模型利用线性关系得出其饱和度,再由饱和度利用其关系求得浓度,得到的数据接近真实值,将数据代入二维模型中,由于颜色读数项目太多时其结果距离真实值较远,所以一维模型对整体数据影响较小,二维模型对整体影响较大,误差也越大。
2 结论
在处理数据方面,利用excel详细处理了附件当中所给的数据,用这些数据通过excel做出其拟合趋势图、残差图,这些图能直观反应其关系的走势,数据所产生的误差也清晰的表现了出来。
在求解第一、二问的过程中,建立了线性回归模型,该模型将整体走势表现了出来。
在数据量小的情况下,利用excel处理所计算出的数据误差比数据量大时的误差大,不能精确化。
参考文献
[1]全国大学生数学建模竞赛.2017年高教社杯全国大学生数学建模竞赛赛题[EB/OL].[2017-9-14].http://www.mcm.edu.cn.
[2]韩中庚.数学建模方法及其应用[M].北京:高等教育出版社,2009.
[3]陈义华.数学模型[M].重庆:重庆大学出版社,1995.
