加入用户对项目属性偏好的奇异值分解推荐算法
2018-05-16魏港明刘真李林峰张猛
魏港明, 刘真, 李林峰, 张猛
(北京交通大学计算机与信息技术学院, 100044, 北京)
基于矩阵分解的推荐算法是应用广泛的协同过滤推荐技术[1-3],具有良好的推荐准确性,并能有效处理大规模的用户项目评分数据。在Netflix Prize大赛中,矩阵分解算法产生了PMF、ASVD和SVD++等算法[4-6],这些算法能够充分挖掘用户项目的隐类信息,具有很好的推荐效果。但是,矩阵分解推荐算法存在冷启动问题,对于评分较少的用户或新项目,不能有效挖掘其隐类信息,越来越多的社会化网络、用户的人口统计学信息、项目的描述信息等[7-8]信息源被加入到矩阵分解的框架中,这在一定程度上解决了冷启动问题。
目前,大多数工作集中在用户冷启动的问题,而忽略了项目冷启动问题。MarCelo提出了在推荐中应用项目元数据的gSVD++算法,融入用户隐式偏好,同时充分考虑了项目的属性信息的作用,提高了推荐的准确度[9-10];Qin等提出了基于项目类别权重的协同过滤推荐算法,同时考虑了项目的类别信息和用户的属性信息,提高了推荐的准确[11];Yu等提出了在矩阵分解算法中融入项目属性信息的改进算法[12],一定程度上解决了项目冷启动问题。矩阵分解协同过滤算法只考虑了项目属性的影响,并未考虑用户对项目属性的偏好信息。用户对项目类别的契合在某种程度上体现了用户本身性格偏好,因此需要考虑这方面的信息。
基于此,本文提出了加入项目属性和用户对项目属性偏好的UC-SVD矩阵分解算法,将用户的评分信息、项目的属性信息以及用户对项目属性的偏好信息应用到矩阵分解算法中,对矩阵分解中隐类的分解起到增强效果,解决项目冷启动问题,同时提高推荐的质量。
1 传统的矩阵分解算法
在现实中,用户和项目都有很多的偏好特征,如果用户的特征向量和项目的特征向量相吻合,那么两向量的内积就是用户的对项目的评分,从矩阵分解的角度来看,就是将评分矩阵分解为用户特征矩阵P和项目特征矩阵Q的乘积[13],即
(1)
如果考虑整体用户和项目的偏差,则可得用户u对项目i的预测评分
(2)
如果能最小化训练集T的预测误差,那么也可以最小化测试集的预测误差。为了防止过拟合,加入正则化项L2,λ为正则化参数,定义损失函数为
λ(‖pu‖2+‖qi‖2+‖bu‖2+‖bi‖2)
(3)
要最小化式(3)所示的损失函数,可利用随机梯度下降最优化方法进行求解,通过调整参数,可求出预测评分。
2 项目属性和用户对项目属性的偏好
2.1 项目属性
考虑m个用户和n个项目的评分矩阵,评分矩阵R中包含的用户集合为U={u1,u2,u3,…,um},被评价的项目集合为I={i1,i2,i3,…,in},rui表示用户u对项目i的评分。项目i的属性集合为G(i)={g1,g2,g3,…,gs},其中s为项目属性个数,G(i)表示项目i的各个属性信息,如果i存在某属性,则该属性为1,否则置为0。
2.2 用户对项目属性的偏好

3 改进后的模型和算法
3.1 加入项目属性因子
考虑到项目的属性信息对项目特征矩阵的增强作用,将项目属性信息加入到SVD模型当中,加入因子后的评分预测公式为
(4)
式中:bui=u+bu+bi。通过每个项目i的G(i)属性集用来调整每个属性g的相关特征权重,并通过已知的用户评分矩阵学习得到。
3.2 加入用户对项目属性偏好因子
由于用户对项目属性的偏好并未直接在数据集文件中给出,因此首先需要构造用户对项目属性的偏好矩阵Z,构造如下算法1。
算法1构造用户对项目属性的偏好矩阵
输入:用户项目评分矩阵R,项目属性矩阵G,属性选择个数T。
输出:用户对项目属性偏好矩阵Z。
(1)Iu←GetEachUserItem(R);/*对于用户u,根据评分矩阵R取得u评分过的项目集合Iu={i1,i2,i3,…,ik}*/。

(3)buk←SortAndTakeT(Cu)/*对步骤(2)中评分次数ci(i=1,2,…,s)进行降序排序,取评分次数靠前的T个属性,将其结果置为1,其余置为0(如果不为0项小于T,则全部取为T),得到用户u的项目属性偏好向量buk(k=1,2,3…,s)*/。
(4)遍历所有用户,重复步骤(1)~(3),得到所有用户对项目属性的偏好矩阵Z。
在算法1中,用户对项目属性评分次数在统计意义上反映了用户u对项目各属性的偏好信息。由于整个评分矩阵中,用户间对项目评分数量差距较大,不能统一按照某个阈值进行属性选择处理,因此只利用用户对项目属性的二元偏好而不使用对电影属性评分次数,这样有效避免了不同用户评分对项目各属性次数相差过大的问题,从而得到了用户u对项目属性的偏好向量。把用户对项目属性的偏好信息加入到式(4)中,用户对相关属性偏好的权重可以通过用户评分信息学习到,加入用户偏好后的评分预测公式为
(5)
在式(5)中,与传统矩阵分解算法相比,分别对qi、pu进行改进,加入项目属性偏好特征和用户对项目属性偏好特征,算法改进示意图如图1所示。

图1 算法改进示意图
模型建立后,可得评分预测损失函数
(6)
通过算法更新可以得到用户的特征矩阵P、项目的特征矩阵Q、用户对项目属性偏好特征矩阵PF及项目属性特征矩阵QF。δ、φ根据属性信息进行调整:如果项目存在相关属性信息,则δ设置为1,否则为0;如果用户存在对项目属性偏好信息,则φ设置为1,否则设置为0,其余的相关参数将通过在训练集中最小化损失函数学习到,参数的更新算法如算法2所示。
算法2参数更新算法
输入:用户对项目的评分矩阵R,项目的属性矩阵G,用户对项目的属性偏好矩阵Z;
输出:返回List列表,包括用户和项目偏差bu和bi,用户和项目特征矩阵P和Q,用户对项目属性偏好特征矩阵PF和项目属性特征矩阵QF。
(1)List[bu,bi,W,H]←Initialize(Double);
PF,QF←Initialize(Gaussian);/*以Double数据类型初始化bu、bi,P和Q,并以高斯分布(加速收敛)初始化用户对项目属性偏好特征矩阵PF和项目属性特征矩阵QF*/。
(2)bu←bu-γ1bu;bi←bi-γ1bi;P←P-γ1P;
Q←Q-γ1Q;PF←PF-γ2PF;QF←QF-γ2QF;
/*利用式(5)进行评分计算初始的预测评分,
然后
根据式(6)及评分矩阵R,项目属性矩阵G,用户对项目属性偏好矩阵Z,利用SGD随机梯度下降法更新矩阵P、Q、PF和QF,直至预测误差基本不再变化*/。
(3)Return List[bu,bi,P,Q,PF,QF]/*参数列表*/。
3.3 UC-SVD算法流程
综合算法1、2,得到整体的UC-SVD算法框架如图2所示。

图2 UC-SVD算法框架
算法3UC-SVD算法
输入:用户对项目的评分矩阵R,属性矩阵G。
输出:用户的推荐列表List[Item]。
(1)Z←Process(R,G);/*对用户对项目评分矩阵R和项目的属性偏好处理,得到用户对项目属性偏好矩阵*/。
(2)List[bu,bi,P,Q,PF,QF]←OverallUpdate(R,G,Z,bu,bi,P,Q,PF,QF);/*利用SGD进行全局参数更新,直到参数最终达到收敛*/。
(3)R’←PreRate(bu,bi,P,Q,PF,QF)/*使用最优参数进行评分预测,预测评分矩阵R’*/。
(4)List[Item_K]←RecommendK(R’)/*利用预测评分矩阵,对用户未评分过项目的预测评分进行排序,将前K个项目推荐给用户*/。
4 实验和结果分析
4.1 实验数据及实验环境
实验采用Movielens[14]的两个数据集,Movielens100KB的数据集包括943个用户对1 682个项目的100 000条评分数据和相关电影的属性信息,该数据集的评分稀疏度为93.70%;Movielens 1MB的数据集包括6 040个用户对3 952个项目的1 000 209条评分数据和相关电影的属性信息,该评分数据集的稀疏度为95.53%。首先对Movielens 100KB、Movielens1MB数据集的评分数据和电影类别数据进行处理,由于Movielens100KB数据集中存在无效类别,为防止其对结果产生干扰,将其剔除,这样可以得到的电影类别为18项。通过实验,选取用户的类别偏好属性个数为7,其余11个属性置为0,处理后的电影类别文件Category和用户对电影属性的偏好文件Preference存储在数据文件中,可提高算法效率。实验中采用的基准算法为RSVD算法和ALS推荐算法,数据集的80%为训练集,20%为测试集,结果取平均值。
本文实验环境为:Win8.1操作系统,8 G内存,Intel(R) Core(TM) i5-6300HQ CPU @ 2.30 GHz,实验程序使用Scala2.11.7编写。
4.2 算法评价指标
在实验中,采用常用的均方根误差和平均绝对误差,计算公式为
(7)
(8)
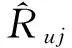
4.3 实验结果及分析
对相关参数进行选取,选择使UC-SVD算法Er、Em最优的参数值。更新过程中的主要参数为梯度下降速率γ1、γ2,对速率进行实验并选取最优值,结果如表1、2所示。对式(6)中的正则项λ进行实验并选取最优值,结果如表3所示。

表1 当γ2不变、γ1变化时的Em、Er值

表2 当γ1不变、γ2变化时的Em、Er值

表3 λ变化时的Em、Er值
由表1、2可知,当γ1=0.001、γ2=0.002时,改进的UC-SVD算法Er、Em取得最优。由表3可知,当λ=0.05时,改进的UC-SVD算法的Er、Em取得最优。
对带有正则化项的矩阵分解推荐(RSVD)算法[15]、基于交替最小二乘的协同过滤推荐(ALS)算法[16]、本文算法等进行了对比实验,并在Movielens的两个数据集上运行这3种算法,各算法Er、Em对比结果如图3所示。

(a)Er (b)Em图3 各算法Er、Em对比
由图3可知,本文所提算法的Er值低于RSVD以及ALS推荐算法的,在Movielens1MB数据集上,UC-SVD算法比RSVD算法下降了2%,比ALS算法下降了约1.8%左右,说明改进算法在预测准确度上优于对比算法的。尤其是在Movielens 1MB数据集实验下,当迭代次数为400、特征因子为20时,Er降低到0.848 7。本文所提算法的Em比RSVD算法的下降了3.1%,比ALS算法的下降了约4%。
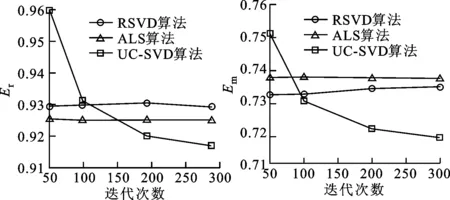
(a)Er (b)Em图4 Movielens100KB数据集Er、Em随迭代次数变化

(a)Er (b)Em图5 Movielens1MB数据集Er和Em随迭代次数变化
为了验证在用户和项目特征因子固定的情况下,各算法的Er、Em随迭代次数变化的情况,在两个数据集下实验对比结果如图4、5所示。由图4可知,当迭代次数小于100时,推荐效果较差;当迭代次数在100~200时,3种对比算法大致相当,当迭代次数大于200时,推荐的效果要好于两种对比算法,当迭代次数大于100时,UC-SVD算法的Er好于两种对比算法。由图5可知:RSVD、ALS算法随迭代次数的增加基本保持不变;UC-SVD算法在迭代次数小于100时,推荐效果较差;在迭代次数大于100时,推荐效果好于其余两种对比算法;在大于50时,UC-SVD算法的Em误差结果好于其余两种对比算法。迭代次数固定时,在两个数据集下各算法的Er值随特征因子k变化的情况如图6、7所示。由图6可知:随着k的增加,UC-SVD算法的Er不断降低,当特征因子大于100后,Er值保持稳定,这说明此时特征因子继续增加不会对推荐产生更积极的影响,整体上UC-SVD算法的Er低于其余两种对比算法;UC-SVD算法的Em误差随着因子的增加逐渐减低,均低于两种对比算法。

(a)Er (b)Em图6 Movielens100KB数据集Er、Em随特征因子k的变化情况

(a)Er (b)Em图7 Movielens1MB数据集Er、Em随特征因子k的变化情况
由图7可知:随着k的增加,UC-SVD算法当k大于30时,Er有所增加,但改进算法的Er在整体上优于其余两种对比算法;UC-SVD算法的Em当k大于30时有所升高,这可能是由于因子的过大对推荐产生负影响,但在整体上远低于两种对比算法。
使用HetRec2011数据集来验证本文所提算法在不同数据集下的表现,该数据集数据稀疏度为96.03%,较MovieLens100KB、MovieLens 1MB数据集更为稀疏。由于属性信息中多了Short、IMAX两项属性,考虑到该属性对类别的影响较小,将其剔除,只保留项目的18个属性,与Movielens100KB数据集保持一致,其余数据处理与上述数据集相同,对比结果如表4所示。由表4可知,在新的稀疏数据集下,UC-SVD算法表现良好,当k=10时,改进算法的Er较RSVD、ALS算法的降低了约3.3%,当k=50时,较RSVD、ALS算法降低了约3.7%,UC-SVD算法在整体上好于其余两种对比算法。

表4 各算法在HetRec数据集下对比
5 结 论
本文考虑了项目属性的重要作用,通过对项目属性、用户评分的综合考虑,得出用户对项目属性的偏好信息,提出基于用户对项目属性偏好的UC-SVD协同过滤推荐算法。先介绍算法的改进思路和算法步骤,通过更新得出算法的最优参数及模型,最后在Movielens100KB、Movielens1MB数据集上,将改进的UC-SVD算法和传统的经典协同过滤算法进行对比。实验结果表明,加入项目属性因子和用户对项目属性偏好信息使得准确度有所提升,Er平均降低3.5%。为了验证模型在更加稀疏数据集上的作用,本文在HetRec2011数据集上进行了算法的对比实验,表明改进算法在更为稀疏的数据集下表现良好。在实际过程数据比较稀疏的情况下,利用项目的属性信息和用户对项目属性的偏好信息,能够解决一定的稀疏性问题,同时提高推荐的准确率。
参考文献:
[1] 赵长伟, 彭勤科, 张志勇. 混合因子矩阵分解推荐算法 [J]. 西安交通大学学报, 2016, 50(12): 87-91.
ZHAO Changwei, PENG Qinke, ZHANG Zhiyong. A matrix factorization algorithm with hybrid implicit and explicit attributes for recommender systems [J]. Journal of Xi’an Jiaotong University, 2016, 50(12): 87-91.
[2] PAN T, LIU Q, CHANG L I U. Ratings distribution recommendation model-based collaborative filtering recommendation algorithm [C]∥ The 2nd International Conference on Software, Multimedia and Communication Engineering. [s.n.]: SMCE, 2007: 378-380.
[3] 燕彩蓉, 张青龙, 赵雪, 等. 基于广义高斯分布的贝叶斯概率矩阵分解方法 [J]. 计算机研究与发展, 2016, 52(12): 2793-2800.
YAN Cairong, ZHANG Qinglong, ZHAO Xue, et al. A method of Bayesian probabilistic matrix factorization based on generalized Gaussian distribution [J]. Journal of Computer Research and Development, 2016, 52(12): 2793-2800.
[4] 吴金龙. Netflix Prize中的协同过滤算法 [D]. 北京: 北京大学, 2010: 25-34.
[5] BAO Y, FANG H, ZHANG J. TopicMF: simultaneously exploiting ratings and reviews for recommendation [C]∥Proceedings of the 28th AAAI Conference on Artificial Intelligence. New York, USA: ACM, 2014: 2-8.
[6] KOREN Y. Factor in the neighbors: Scalable and accurate collaborative filtering [J]. ACM Transactions on Knowledge Discovery from Data, 2010, 4(1): 1-24.
[7] GUO G, ZHANG J, YORKE-SMITH N. TrustSVD: Collaborative filtering with both the explicit and implicit influence of user trust and of item ratings [C]∥Proceedings of the 29th AAAI Conference on Artificial Intelligence. New York, USA: ACM, 2015: 123-129.
[8] JAMALI M, ESTER M. A matrix factorization technique with trust propagation for recommendation in social networks [C]∥ACM Conference on Recommender Systems. New York, USA: ACM, 2010: 135-142.
[9] MANZATO M G. gSVD++: supporting implicit feedback on recommender systems with metadata awareness [C]∥ACM Symposium on Applied Computing. New York, USA: ACM, 2013: 908-913.
[10] MANZATO M G. Discovering latent factors from movies genres for enhanced recommendation [C]∥Proceedings of the 6th ACM Conference on Recommender Systems. New York, USA: ACM, 2012: 249-252.
[11] QIN J, CAO L, PENG H. Collaborative filtering recommendation algorithm based on weighted item category [C]∥Control and Decision Conference. Piscataway, NJ, USA: IEEE, 2016: 2782-2786.
[12] YU Y, WANG C, WANG H, et al. Attributes coupling based matrix factorization for item recommendation [J]. Applied Intelligence, 2016, 46(3): 1-13.
[13] 项亮. 推荐系统实践 [M]. 北京: 人民邮电出版社, 2012: 186-195.
[14] HARPER F M, KONSTAN J A. The MovieLens datasets: history and context [J]. ACM Transactions on Interactive Intelligent Systems, 2016, 5(4): 19.
[15] CARAGEA C, SILVESCU A, MITRA P, et al. Can’t see the forest for the trees?: a citation recommendation system [C]∥Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries. New York, USA: ACM, 2013: 111-114.
[16] WINLAW M, HYNES M B, CATERINI A, et al. Algorithmic acceleration of parallel ALS for collaborative filtering: speeding up distributed big data recommendation in spark [C]∥21st IEEE International Conference on Parallel and Distributed Systems. Piscataway, NJ, USA: IEEE, 2015: 682-691.
