基于模块化聚类的标签弹性推荐
2018-05-15徐汉青滕广青王东艳韩尚轩
徐汉青 滕广青 王东艳 韩尚轩

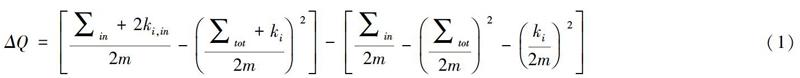
〔摘 要〕[目的/意义]社会化标注系统为用户检索提供便利的同时也面临一些困扰,标签推荐研究有助于解决资源检索中精确度与召回率之间的两难抉择。[过程/方法]借助网络科学的理论与方法,通过对标签网络的模块化聚类处理获得主题聚类,采用度数中心度对主题聚类内部标签进行排名,根据特定规则选取Top-N标签数量。[结果/结论]实验结果显示,研究中提出的模块化Top-N标签推荐方法,具有可逐层细化的精确度和良好的召回率。该方法的弹性机制可为不同的检索要求提供差异化服务。
〔关键词〕社会化标注;标签推荐;模块化聚类;标签排序
DOI:10.3969/j.issn.1008-0821.2018.04.008
〔中图分类号〕G254.97 〔文献标识码〕A 〔文章编号〕1008-0821(2018)04-0058-07
〔Abstract〕[Purpose/Significance]Social tagging system is also facing some inconvenience while facilitating the retrieval of users.Tag recommendation research can help solve the dilemma between the accuracy and the recall rate in resource retrieval.[Process/Method]With the theory and method of network science,the topic clusters were obtained through the modularity clustering on tag network,the degree centrality was used to rank the tags in the topic clusters,the numbers of the Top-N tags were selected according to a specific rule.[Results/Conclusions]The experimental results showed that the modularity Top-N tag recommendation method had the accuracy of level-by-level refinement and the good recall rate.The flexible mechanism of this method could provide differentiated services for different retrieval requirements.
〔Key words〕social tagging;tag recommendation;modularity clustering;tag rank
Web2.0环境下,网络用户不仅是信息的接受者,同时也成为信息的组织者与架构者。文献网站、社交网站、图片网站、音乐网站等各种类型的网站纷纷采用社会化标注资源组织模式,允许并鼓励用户对网络资源进行标注,并根据标签向用户提供检索服务,从而使得社会化标注系统在互联网上迅速蔓延。与此同时,广大用户在享受社会化标注系统所带来的福利的同时,不得不面对其平层结构在资源检索中所造成的困扰。因此,以资源精确定位和有效覆盖为目的的社会化标注系统中的标签推荐研究引起了学术界的关注,并尝试建立多种推荐方法以满足上述目标及要求。
本研究采用网络科学的理论和方法,基于标签之间的关联关系构建标签网络。结合网络模块化聚类和中心度排序,生成主题聚类并提取不同主题聚类中的推荐标签。同时对该方法的弹性机制与资源覆盖率进行了解析与测度,以期建立一种能够适应不同检索需求的具有可调整性的弹性标签推荐方法。
1 研究工作综述
社会化标注系统中的相关资源都被赋予了不同的用户标签,通过标签能够直接引导用户直接到达资源层。尽管检索行为的最终标的物是目标资源,但是真正起到推荐作用的则是各类标签,而且其中的标签来源于用户的标注行为,又直接面对用户的检索行为。因此,学术界对于借助标签实现和辅助资源检索的标签推荐问题展开了相关研究,并在近年来取得了较为丰富的成果。
德国学者I.Peters和W.G.Stock[1]在对标签网络的测量中发现了标签节点度值的幂律分布规则,在此基础上利用切断文档精确标签长尾部分中的标签形成搜索标签。研究表明,搜索标签与一般的大众分类和传统知识组织系统兼容,并且可以通过长尾标签限制点击量,提高了信息检索结果的精确度。K.Yi[2]等人通过研究发现资源的URL与标签之间在排名和频率方面存在幂律关系。通过对网页资源主题标签的调查显示,主题标签可以被用作相同资源的同现网址的索引词,从而能够基于幂律分布的主题标签对资源推荐产生影响。J.J.Jung[3]采用朴素贝叶斯和支持向量机的数据挖掘方法,通过每个类目中标签术语的使用频率对所收集的资源进行分类。该方法应用于标记社交网络服务上的未标记资源,能够提升资源获取的广度。J.Mao[4]及其合作者基于标签同现关系构建标签网络,采用PageRank和HITS方法利用链路对节点加权,通过将权重转换为资源的推荐分数的方式,将标签网络向“标签——资源”网络扩展。测试结果显示,该方法相比基于标签协同过滤的方法在精度和召回度方面都能够得到改善。S.Yamamoto[5]等研究者以时间序列为基准,采用余弦相似度、朴素贝叶斯和TF-IDF相结合方法计算用户和主题标签之间的分数,以此来发现具有相似兴趣的用户,并且能夠评估用户的兴趣爱好进行推荐。M.F.Alhamid[6]等人则提出一种新的语境感知推荐模型,利用标签计算用户对其他类似语境的潜在偏好,通过查找用户语境以及语境与资源之间的相似性,确定对特定语境有吸引力的资源。并根据该特定用户的语境映射,推荐适合用户需求的最相关的资源。
近年来,国内学术界也在标签推荐方面积累了一定的研究成果。陈丽霞和窦永香[7]等人通过构建标签本体展示平层外表下的标签层级关系,借助标签本体实现基于标签语义关联关系的标签推荐。曾子明与张振[8]基于“用户——资源——标签”三元关系分别提取用户聚类和标签聚类,通过每个聚类所对应的标签集的相似性提供个性化推荐。该方法在召回率方面表现出一定的优势。张亮[9]则采用LDA主题模型抽取文献资源中的内容特征和关键标签,并据此构建标签推荐模型。测试结果显示,该模型在准确率、召回率等方面均有较好的表现。熊回香和杨雪萍[10]采用K-means等多种方法分别进行资源聚类、用户聚类和标签聚类,通过对3种聚类结果的分析,总结出单一视角下标签推荐的局限性,进而提出了资源重组加维度结合的标签推荐方法。武慧娟[11]等人在以往静态分析的基础上,尝试将标签推荐的过程和行为因素引入推荐模型,并基于网络分析的方法对聚类内部和聚类之间的偏好信息进行了分析。此外,国内学者在基于用户认知的标签推荐[12]以及基于文本挖掘的标签推荐[13]等方面也取得了相应的进展。
综上所述,随着Web2.0环境下网民用户参与度的不断提高,社会化标注系统中标签推荐的相关研究已经成为学术界的研究热点。领域本体、网络分析、数据挖掘、语义认知等学科领域的理论与方法纷纷融入到标签推荐研究中。然而,任何一种标签推荐方法在面临实际检索任务的需求差异时,都难以避免地在精确度与召回率之间面临两难的选择。因此,有必要通过构建具有弹性的标签推荐方法,以适应实际检索任务的不同需求。有鉴于此,本研究采用网络科学的思维与方法,基于标签网络的模块化聚类方法生成主题聚类,采用度数中心度对主题聚类内部标签进行排序,并以改进后的普赖斯方法按特定比重选取不同主题聚类中的推荐标签数量,尝试建立一种可根据具体检索需求进行调整的、具有弹性的标签推荐方法。
2 相关理论框架
2.1 社会化标注
2.2 社会网络分析
社会网络分析(Social Network Analysis)[15]也被称为网络分析、结构分析。是相关学者主要利用图论、矩阵代数、概率统计、计算机编程等方法所形成的定量分析方法。近年来,社会网络分析凭借其在结构关系揭示方面的优势,已经被引入到图书情报学领域的诸多信息分析研究中,并得到了学术界的普遍认可。本研究中,将首先构建标签网络,在此基础上主要将社会网络分析中基于模块度(Modularity)[16]的聚类方法和度数中心度(Degree Centrality)[17]方法相结合用于标签推荐。模块度是近年来常用的衡量群簇聚类质量的标准,采用该方法能够识别出标签网络中具有高聚类质量的主题群簇,为用户的检索行为带来极大的便利。度数中心度则能够识别网络关系中处于核心地位的标签节点,基于度数中心度对主题聚类中的标签进行排序,能够获得关系地位处于核心位置的标签,而不是以往标签集合中使用频次最高的标签。因此,两种社会网络分析方法的引入,不但体现了本研究中标签推荐方法的创新性,而且将标签推荐从外在表象的使用频次推进到本质内含的关联程度,进而实现标签的弹性化推荐。
3 研究方法
3.1 研究数据
本文以citeUlike网站为基础数据源,该网站提供社会化标注系统组织与架构知识资源,允许用户组织、标注、分享学术文献资源。研究中以“Social Network”为检索词,采用自主研发的爬虫工具,抓取相关文献资源及其标签作为原始数据集。共获得文献资源1 001篇,相关标签3 496个。表1为对原始数据集中文献资源拥有标签情况的统计结果。
表1中的数据显示,原始数据集中有大约85%的文献被网络用户进行过标注,大约60%的文献被超过2个以上的标签标注,平均每篇文献被标记的标签个数为3.5个。就单篇文献拥有标签数量的平均水平来讲,与单篇文献拥有关键词数量的平均值比较接近。
3.2 研究流程与方法
3.2.1 数据清洗
由于社会化标注行为的开放性,原始数据集中不可避免地存在未被标注的文献,以及标注不规范的标签。因此在正式进行分析之前首先需要对数据进行清洗。研究中,首先清洗没有标签或者被标记“no-tag”标签的文献,由此得到相关文献844篇。在此基础上,进一步从标注规范性的角度出发对相关标签进行清洗,包括去除符号、去除编号、词形转换等。主要的清洗规则如表2所示。
清洗后的数据集包括有效文献844篇,有效标签1 001个。在清洗后的数据基础上,根据文献资源与标签之间的对应关系构建标签网络。
3.2.2 标签网络构建
首先,根据清洗后的数据确立资源与标签之間的隶属关系。如果文献R1拥有标签T1,则文献R1与标签T1具有隶属关系。其次,确立标签与标签之间的邻接关系,本研究中也称为标签关联关系。如果同一篇文献R1拥有标签T1和T2,则标签T1和标签T2具有邻接关系(关联关系)。隶属关系与邻接关系的确立如图1所示。
图1中,3篇文献资源(R1、R2、R3)分别被网络用户赋予4个标签(T1、T2、T3、T4)。文献资源与标签之间的隶属关系以实线表示,标签与标签之间的邻接关系以虚线表示。其中,如果两个标签共同标注一篇文献,则两个标签邻接关系的频度(关联频度)为1(图1中标签T2和标签T3共同标注过1篇文献R2,故该关系频度为1。);
如果两个标签共同标注两篇文献,则两个标签邻接关系的频度(关联频度)为2(图1中标签T1和标签T2共同标注过2篇文献R1和R2,故该关系频度为2。),以此类推。
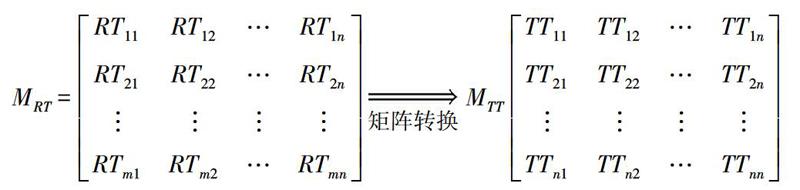
根据图1所示的隶属关系构建隶属矩阵MRT。隶属矩阵中文献资源Ri与标签Tj如果具备隶属关系则隶属关系RTij取值为1,反之为0。在此基础上,将隶属矩阵MRT转换为邻接矩阵MTT,转换后的矩阵为方阵。邻接矩阵中标签Ti与标签Tj如果具备邻接关系,则邻接关系TTij取值为该邻接关系的频度值(参见图1),反之取值为0。转换过程如下所示。
由网络科学[18]的理论可知,矩阵是网络的一种表现形式。因此,根据转换后得到的标签邻接矩阵可以生成多值标签网络。以标签为网络节点,以邻接关系(关联关系)为网络连线,生成的标签网络中共有标签节点1 001个,标签关联关系连线6 731对(条)。其中,最大关联频度为428,最小关联频度为1。
出于对用户检索行为支持的目的,标签网络体现的关联关系首先要具有显著性。单一频度的关联关系在开放的社会化标注环境下不可避免地含有偶然性,因此在资源检索中不考虑向用户推荐。此前已经有研究证明,基于关联频度提取的层次知识网络不但具有更高的统计显著性,而且与原始知识网络相比在网络拓扑结构及属性特征方面具有等效性[19]。因此,进一步以2为关联频度阈值,提取层次标签网络。提取获得的层次标签网络显然获得了更高的统计显著性,拥有标签节点282个,标签关联关系连线723条。事實上,在实际执行当中可以根据需求动态调整阈值,以使层次标签网络更具有弹性。
3.2.3 标签模块化聚类
传统社会化标注系统中,海量的标签无法通过长篇累牍的标签列表为用户提供有效的检索服务。基于词频的标签云(Tag Cloud)只能根据标签的使用频次提供高频标签,无法展示标签之间的关联关系。此前的层次标签网络共计获得具有显著性的关联标签282个,如果不分巨细地推荐给用户,必然对用户的信息检索行为造成困扰。为了能够给用户提供方便高效的检索服务,提供有价值的标签推荐,需要将文献资源借助标签的关联关系展现给用户。研究中具体采用V.D.Blondel[20]等人提出的基于模块度衡量的且支持层级性的聚类算法,基于标签关联关系将网络中的标签进行模块化聚类。具体算法如公式(1)所示。
公式(1)中,ΔQ是标签i划入模块(聚类)M后所产生的收益,如果ΔQ﹥0,则该标签i被归入模块M,或者说标签i分配至模块M的效果最好。∑in是模块M内部标签之间关联关系的权重之和;ki,in是标签i与模块M内各标签关联关系的权重之和;∑tot是模块M内各标签与其他标签之间的所有关联关系(包括模块M内部标签与模块M外部标签的关联关系)的权重之和;ki是标签i与其他标签的所有关联关系(包括模块内部与模块外部)的权重之和;m是标签网络中所有关联关系的权重之和。采用公式(1)的算法将层次标签网络划分为9个模块(聚类),如图2所示。
图2中,模块A~I代表着层次标签网络中的9个主题聚类。其中标签“Social Network”包含在模块E中。如果单独向用户推荐模块E(同时舍弃了其他模块)的标签,则包括代表社会网络应用领域的规模最大的模块D也将被舍弃,检索结果的覆盖范围就会萎缩,召回率则必然难以得到保证。如果向用户推荐全部9个模块的所有标签,则标签关联范围足够广泛,检索精确度反而无法得到保证。因此,研究中结合覆盖范围与目标靶向两方面的因素,进一步筛选各个模块中最具有代表性的核心标签推荐给用户。
3.2.4 Top-N标签选取
S.Brin和L.Page[21]提出的PageRank算法能够很好地通过排序将与检索标签关联的Top-N标签向用户推荐。但是采用PageRank算法选取Top-N标签时,如果N取值较大,则结果范围宽泛,会直接影响检索的精确度。如果N取值较小,则对照标签的模块化聚类可以发现,Top-N标签往往只分布在几个大规模的标签模块之内,削弱检索的召回率。这样的做法还会使得在向用户进行标签排序展示时,许多小规模标签模块或者潜力标签模块被排序规则置于非常靠后的位置,甚至被“忽略”。这会造成给用户的推荐信息中部分相关信息的缺失,这部分信息所对应的相关文献资源也会因此而沉没,从而导致检索结果会出现局部性偏差。
本研究考虑到对于标签网络中形成的每个标签模块都应该有一定的机会或比例展示给用户,因此通过对每个模块内部标签基于度数中心度指标形成标签模块内部排序,提供给用户相关的推荐信息。另一方面,完成内部排序的标签模块是经过模块化聚类处理的具有主题代表性的标签集,能够最大化地将各个主题聚类(标签模块)内部处于核心地位的标签展现给用户。通过这种方式,可以根据用户的检索标签,快速提供给用户检索领域的全部主题聚类的核心标签,以供用户进行精确检索。通过对标签网络中每个标签模块的Top-N核心标签的展示推荐,可以让用户了解到每个标签主题聚类(标签模块)的核心内容。可以让用户更方便地了解到基于检索词生成的标签网络中更加全面的知识内容,以及每个标签模块的核心主题。研究中,具体采用标签节点的度数中心度进行模块内标签排序。对于每个标签模块的Top-N范围的确定,则通过对P.D.Allison和D.de S.Price[22]等人的方法进行改进来完成,具体算法如公式(2)所示。
公式(2)中,Mi,n表示标签模块i中选取的Top-N推荐标签数量n,k为常量表示每个标签模块所选择的标签比例(文献[30]中k值约等于0.749),Mi为每个标签模块内的标签数量,m为层次标签网络中全部标签模块的数量,N表示计划推荐给用户的全部标签模块的Top-N标签数量合计。公式(2)能够适当压缩超大规模标签模块的Top-N标签数量,并适当提升小规模标签模块的Top-N标签数量。采用这种方法,在合理保留大规模标签模块Top-N标签数量的情况下,有利于确保小规模标签模块的Top-N标签数量不会被大规模标签模块的Top-N标签数量完全淹没,从而使得知识资源检索工作能够在主题覆盖面上更加的全面准确。
4 实验结果分析
4.1 标签推荐的弹性机制
标签推荐需要同时兼顾精确度和召回率。本文提出的标签模块化聚类与基于度数中心度Top-N排序相结合的方法(简称“模块化Top-N”方法)能够借助公式(1)算法的层级支持性兼顾推荐标签的精确度和召回率。当用户进行资源检索时,通过对用户所搜索到的标签集合进行模块化聚类处理,形成反映标签主题聚类的标签模块。用户可以通过对多个标签模块(主题聚类)提供的Top-N推荐标签进行选择,保障推荐标签的召回率。也可以采用向下钻取的思路,对某一重要的标签模块进行子模块的划分,提升推荐标签的精确度。以本文选取的检索词“Social Network”为例。在图2中与“Social Network”最相关的标签模块为模块E(标签“Social Network”位于模块E中)。模块E中共包括相关标签29个,其成员的具体构成及其排名如表3所示。
表3的内容显示,尽管模块化Top-N方法已经在保证推荐标签覆盖范围的情况下,实现了比较精准的定位,但是该标签模块中仍然包含29个相关标签。按照排名顺序依次向用户推荐的标签是“Social Network”(社会网络)、“Graph”(图)、“Structure”(结构)、“Recommendation”(推荐)、“Relation”(关系)、“Trust”(信任)等。显然,此时的推荐标签及其所对应的相关文献资源仍然比较松散和宽泛,主题专指性尚不鲜明。有鉴于此,需要再次针对模块E进行模块化聚类处理,以提高推荐标签的精确度。标签模块E经过模块化聚类处理后被划分为5个子标签模块,如图3所示。
图3中,包含“Social Network”的子标签模块为模块E-3。此时,子模块E-3内部排序位于“Social Network”標签之后的3个标签依次是“Method”(方法)、“Social Network Analysis”(社会网络分析)和“Graph Theory”(图论)。显然,这些标签直指社会网络的方法本质。推荐的精确度得到进一步提升。
实际应用中,多个标签模块的Top-N标签是推荐标签召回率的基本保障。而针对某一标签模块的模块化Top-N方法的多次迭代,则可以通过对主题聚类的向下钻取,获得用户满意的精确度。同时,迭代过程的逆序过程也是推荐标签覆盖范围逐渐扩展的过程。显然,模块化Top-N方法是一个具有良好弹性的标签推荐方法,可以根据具体检索任务需求和资源丰富程度的不同,在检索过程中适当选择迭代次数或嵌套层数,以满足不同精确度和召回率的需求。
4.2 推荐效果对比分析
考虑到标签推荐的最终目的在于帮助用户方便地获得有效的文献资源,因此研究中需要从推荐标签和文献资源两个视角分别对标签推荐方法做出测评。出于这一目的,使用真实标签数据,将基于PageRank算法的标签推荐效果与基于模块化Top-N方法的标签推荐效果进行对比分析。
首先,对同等推荐标签数量的两种推荐方法的文献覆盖率进行了对比分析。考虑到实际应用中用户对推荐标签列表的视觉疲劳等因素(众多密集的推荐标签会造成用户的视觉疲劳),对比工作分别选取推荐标签数量为15、25、35、45共4种不同的标签数量水平,对搜索到的文献资源覆盖率进行比较。以推荐标签数量为横轴,以文献资源数量为纵轴,两种方法的比较结果如图4所示。
图4中的结果显示,在4种不同的推荐标签数量水平上,同样的标签数量下模块化Top-N方法都比PageRank方法有更好的表现。模块化Top-N方法能够基于同等数量的推荐标签覆盖到更丰富的文献资源。而且,当推荐标签数量水平较低时,模块化Top-N方法相比PageRank方法在文献资源覆盖率方面的优势会更加明显。这一优势产生的原因主要在于模块化Top-N方法通过标签模块化聚类得到标签主题聚类的同时,将每个主题聚类(标签模块)中处于核心位置的标签按照特定规则的比重(参见公式(2))推荐给用户,增加了有限标签对文献资源的覆盖率。
其次,对形成相同数量主题聚类所需要的标签数量进行对比分析。这部分分析工作的重点在于模块化Top-N方法和PageRank方法形成主题聚类所需要消耗的标签数量差异。以主题聚类(标签模块)数量为横轴,以标签数量为纵轴,两种方法的对比结果如图5所示。
图5中的结果显示,当形成极低数量的主题聚类(检索的领域范围很细小)时,模块化Top-N方法与PageRank方法所需要消耗的标签数量没有显著差异。当主题聚类数量较多时,模块化Top-N方法相比PageRank方法在标签消耗方面的优势就显现出来。同等数量的主题聚类使用模块化Top-N方法仅需要较少的标签,而使用PageRank方法则需要消耗掉更多的标签。显然,推荐导航中的标签数量过多,会降低推荐系统对于用户的感知易用性。模块化Top-N方法按照特定比重原则(参见公式(2))筛选出的Top-N标签,在反映各自所在主题聚类的核心信息的同时,来自于不同标签模块的Top-N标签也代表了检索范围中不同的分支主题。
5 结论与讨论
本研究基于网络科学的理论与方法,针对社会化标注系统中的标签推荐问题,提出模块化Top-N方法实现标签的弹性推荐。该方法对标签网络进行模块化聚类处理,获得以标签模块体现的主题聚类,采用度数中心度排序,根据特定比重选取模块内部Top-N标签作为推荐标签。经过对模块化Top-N方法的推荐效果进行的弹性解析和与PageRank方法的对比测试,研究工作初步得出如下结论。
1)基于模块化Top-N方法的标签推荐具有可逐层细化的精确度。在针对用户检索词构建标签网络后,模块化Top-N方法能够通过模块化聚类处理生成相关的主题聚类(标签模块),并向用户推荐每个主题聚类中最具有代表性的处于核心位置的Top-N标签。用户可以根据检索任务的具体需求,选择不同主题聚类中的推荐标签进行检索。由于该算法自身对层级性的支持,用户可以进一步选择其中的某一主题聚类,将该主题聚类继续划分为子主题聚类(标签子模块),从而使子主题聚类推荐的Top-N标签进一步精细化。这种逐层迭代与嵌套的过程,在该推荐方法的弹性机制解析中已经借助实验数据详细阐述。通过逐层迭代与嵌套获得的推荐标签,能够使推荐标签的精确度逐层细化,实现对文献资源的精准定位。
2)基于模块化Top-N方法的标签推荐具有良好的召回率。召回率好的推荐方法能够使用有限的推荐标签,尽量减少在检索中沉没或者被遗漏的文献资源。通过与PageRank方法的对比分析发现,模块化Top-N方法在同样的标签数量水平上,能够覆盖到更多的文献资源,文献召回数量表现良好。同时,从同等主题聚类数量所需标签数量的情况来看,模块化Top-N方法相比PageRank方法所需要标签数量更少。即模块化Top-N方法仅需要少量的推荐标签就能够覆盖更多的主题聚类。因此,以更少的推荐标签覆盖更多的主题聚类、更大范围的文献资源,最大限度地将相关信息与资源提供给用户进行选择,表现出该推荐方法具有良好的召回率。
本研究针对社会化标注系统中的标签推荐问题展开研究,基于检索目标构建标签网络。借助网络科学的思维与方法,提出模块化Top-N标签推荐方法。研究中的检测分析证明,该方法在精确度和召回率方面都有良好的表现。既能够有效实现文献资源的逐层级精准定位,又能够以最少的成本向用户提供更大范围的资源覆盖。研究工作中也存在尚不完善之处,关于Top-N标签推荐方法的分析与验证,还主要处于静态的研究状态,对于领域知识发展进程中的动态因素的考虑还不周全。后续的研究工作中将注重时间动态因素的影响,考查主题聚类与标签的成长性等因素。从而在保证推荐标签精确度与召回率的同时,为用户提供最具成长潜力的主题聚类和标签,以增加标签推荐的新颖性。
参考文献
[1]Peters I,Stock W G.“Power tags”in Information Retrieval[J].Library Hi Tech,2010,28(1):81-93.
[2]Yi K,Choi N,Kim Y S.A Content Analysis of Twitter Hyperlinks and Their Application in Web Resource Indexing[J].Journal of the Association for Information Science and Technology,2016,67(8):1808-1821.
[3]Jung J J.Exploiting Geotagged Resources for Spatial Clustering on Social Network Services[J].Concurrency and Computation:Practice & Experience,2016,28(4):1356-1367.
[4]Mao J,Lu K,Li G,et al.Profiling Users with Tag Networks in Diffusion-Based Personalized Recommendation[J].Journal of Information Science,2016,42(5):711-722.
[5]Yamamoto S,Wakayashi K,Kando N,et al.Twitter User Tagging Method Based on Burst time Series[J].International Journal of Web Information Systems,2016,12(3):292-311.
[6]Alhamid M F,Rawashdeh M,Hossain M A,et al.Towards Context-Aware Media Recommendation Based on Social Tagging[J].Journal of Intelligent Information Systems,2016,46(3):499-516.
[7]陈丽霞,窦永香,秦春秀.利用社会化标签实现P2P语义推荐[J].图书情报工作,2011,55(22):110-113.
[8]曾子明,张振.社会化标注系统中基于社区标签云的个性化推荐研究[J].情报杂志,2011,30(10):128-133.
[9]張亮.基于LDA主题模型的标签推荐方法研究[J].现代情报,2016,36(2):53-56.
[10]熊回香,杨雪萍.社会化标注系统中的个性化信息推荐研究[J].情报学报,2016,35(5):549-560.
[11]武慧娟,秦雯,窦平安,等.社会化标注系统中个性化信息推荐动态模型研究[J].情报科学,2016,34(6):43-46.
[12]林鑫,周知.用户认知对标签使用行为的影响分析[J].情报理论与实践,2015,38(10):85-88.
[13]吕琳露,李亚婷.基于游记主题挖掘与表达的旅游信息推荐研究[J].现代情报,2017,37(6):61-67.
[14]Gupta M,Li R,Yin Z,et al.Survey on Social Tagging Techniques[J].SIGKDD Explorations,2010,12(1):58-72.
[15]Wasserman S,FausT K.Social Network Analysis:Methods and Applications[M].New York:Cambridge University Press,1994:17-21.
[16]Newman M E J,Girvan M.Finding and Evaluating Community Structure in Networks[J].Physical Review E,2004,69(2):026113.
[17]Freeman L C.Centrality in Social Networks Conceptual Clarification[J].Social Networks,1979,1(3):215-239.
[18]Lewis T G.网络科学:原理与应用[M].陈向阳,巨修练,等.译. 北京:机械工业出版社,2011:4-5.
[19]滕广青,白淑春,韩尚轩,等.基于无标度与分形理论的层次知识网络原理解析[J].图书情报工作,2017,61(14):132-140.
[20]Blondel V D,Guillaume J-L,Lambiotte R,et al.Fast Unfolding of Communities in Large Networks[EB/OL].http://cs.gsu.edu/~myan2/communitydetection/13.pdf,2017-12-08.
[21]Brin S,Page L.The Anatomy of a Large-Scale Hypertextual Web Search Engine[J].Computer Networks and ISDN Systems,1998,30(1-7):107-117.
[22]Allison P D,Price D de S,Griffith B C,et al.Lotkas Law:A Problem in Its Interpretation and Application[J].Social Studies of Science,1976,6(2):269-276.
(责任编辑:马 卓)
