问答系统中基于语义核函数的问题分类算法
2018-05-14江龙泉张波胡志鹏丁峻宏刘波
江龙泉 张波 胡志鹏 丁峻宏 刘波


摘要:
提出一种基于语义核函数的问题分类算法,该算法基于问题的语法结构构建支持向量机(SVM)核函数.首先,将给定的问题解析为语法树结构,用语法树的子树表示该问题;然后,从词法、语法、语义三个层面提取问题的特征,构成更加丰富的特征空间;接着,基于问题的语法树构建核函数;最后,使用潜在语义索引方法并结合问题的词法、语法以及语义特征,通过语义核函数将特征空间映射到更有效的空间中进行问题分类.TREC数据集上的实验结果表明,通过词法、语法以及语义增强的问题特征空间可以提高分类准确率.
关键词:
问答系统; 监督学习; 支持向量机; 问题分类; 语义核函数; 特征空间
中图分类号: TP 391文献标志码: A文章编号: 1000-5137(2018)01-0053-04
A semantic kernel function based question classification algorithm in
question answering system
Jiang Longquan1, Zhang Bo1*, Hu Zhipeng1, Ding Junhong2, Liu Bo2
(1.The College of Information,Mechanical and Electrical Engineering,Shanghai Normal University,
Shanghai 200234,China; 2.Shanghai Super Computing Technology Co.Ltd.,Shanghai 201203,China)
Abstract:
A question classification algorithm based on semantic kernel function is proposed.This algorithm constructs Support Vector Machine (SVM) kernel function based on the grammatical structure of the question.Firstly,the given question is parsed into syntactical structural tree,and then sub-trees of syntactical tree are used to represent the question.Secondly,features are extracted from three aspects of the question:lexical,syntactical and semantic,to form a richer feature space.Thirdly,the kernel function is constructed based on syntactical structural tree of the question.Finally,using the potential semantic indexing method and the lexical,grammatical and semantic features of the question,the feature space is mapped into a more efficient space by the semantic kernel.The experimental results on the TREC dataset show that the classification accuracy can be improved by lexical,grammatical,and semantic enhancement.
收稿日期: 2017-07-10
基金項目: 国家自然科学基金(61572326,61702333);上海市教育科学规划项目(C160049);上海市科委地方院校能力建设项目(17070502800)
作者简介: 江龙泉(1991-),男,硕士研究生,主要从事自然语言处理、智能问答系统、机器学习方面的研究.E-mail:longquan.jiang@yahoo.com
导师简介: 张波(1978-),男,副教授,主要从事智能信息处理、智能数据分析、语义计算、可信计算方面的研究.E-mail:zhangbo@shnu.edu.cn
*通信作者
引用格式: 江龙泉,张波,胡志鹏.问答系统中基于语义核函数的问题分类算法 [J].上海师范大学学报(自然科学版),2018,47(1):53-56.
Citation format: Jiang L Q,Zhang B,Hu Z P,et al.A semantic kernel function based question classification algorithm in question answering system [J].Journal of Shanghai Normal University(Natural Sciences),2018,47(1):53-56.
Key words:
question answering; supervised learning; SVM; question classification; semantic kernel function; feature space
开放领域的问答系统应该能够像人类一样对用自然语言描述的问题作出回答.许多情况下用户只需要一条特定的信息而不是许多篇文档,系统只需要给用户一个简短的答案而不必让用户读懂整篇文档[1].
Mishra等[2]提出了一种基于问题语法子树的最大熵分类方法,将问题解析成语法树结构,其子树被当做问题分类的特征.Li等[3]采用Winnows离散网络(SNoW)学习问题分类器,他们工作的最大特色是引入了一种层级结构的分类器,先给问题分配一个粗粒度的标签,然后使用该标签与其他特征一起作为下一层分类器的输入特征.Silva等[4]使用线性核函数的支持向量机(SVM)算法进行分类.然而,上述研究虽然在问题分类任务上取得了不错的效果,但所选取的特征空间较为单一,无法表现问题更深层次的特点.
本文作者针对上述研究的不足,提出了一种基于语义核函数的问题分类算法,主要的创新点在于从词法、语法以及语义三个层面提取问题的特征,定义一种语义核函数,并基于问题的语法结构构建核函数.通过该语义核函数将问题的特征空间减少到更为有效的空间中进行分类.
1基于语义核函数的分类算法
1.1支持向量机
分类器的选择很大程度上影响着最终的问题分类系统性能,支持向量机(SVM)是问题分类中使用最广泛的分类器之一.SVM是用于分类数据的非概率学习模型,它尝试找到一个具有最大边距的用于区分类别的超平面.[5]
假设训练集(xi,yi),i=1,…,n,其中xi=(xi1,…,xid)是一个d维样本,yi∈{+1,-1}是相应的标签.支持向量分類器的任务是找到线性判别函数g(xi)=wTxi+w0(w为权重向量,w0为偏移).对于yi=+1,使得wTxi+w0≥+1成立;对于yi=-1,使得wTxi+w0≤-1成立.因此,寻求解决方案,满足:
yi(wTxi+w0)≥1,i=1,…,n,(1)
通过
min12wTw-∑ni=1αi(yi(wTxi+w0)-1),(2)
得到解:
w=∑ni=1αiyixi.(3)
其中,αi是拉格朗日乘数.
1.2语义核函数
线性分割数据的典型做法是将特征空间映射到高维空间.这种映射由所谓的核函数完成.核函数是一个方程,其从输入空间χ获取2个样本,将其映射到表示其相似性的1个实数.对于任意两个样本xi,xj∈χ,核函数
k(xi,xj)=〈(xi),(xj)〉,(4)
其中,是从输入空间χ到点积特征空间H的显式映射.
为了将核函数应用于SVM分类器,通常求解方程(2)的对偶形式:
max∑ni=1αi-12∑ni=1∑nj=1αiαjyiyjxi·xj,(5)
其中xi·xj是两个样本的内积,它是测量xi和xj之间相似度的隐含核.
在问题分类任务中,通常需要在非常高的维度空间中表示问题,而SVM对高维数据具有良好的性能.问题分类任务中,问题可以表示为:
xi=(wi1,…,wik,…,wiN),(6)
其中,wik表示问题xi中的第k个词的频率,而N是词的总数.
当使用BOW(Bag of Words)表示问题特征时,SVM隐含地使用线性核函数.对于两个问题xi和xj,线性核函数的定义为:
KBOW(xi,xj)=∑Nk=1wikwjk.(7)
虽然使用BOW特征的线性核能够满足问题分类任务中的基本需求,但对于需要更加深入分析问题潜在特征的应用场景,该方法显然不能反映问题与回答之间复杂的隐含关系[6].本文作者提出一种基于问题的语法结构构建的树核函数,首先将一个给定的问题解析为其语法树,然后用语法树的子树来表示该问题.使用潜在语义索引方法,通过潜在语义核将特征空间减少到更有效的空间,通过查看大型语料库中的信息共现来定义词的相似矩阵.
潜在语义核可以使用奇异值分解(SVD)获得.假设D是来自维基百科文档语料库的term-by-document矩阵,其中Di,j表示文档dj中的词wi的频率.SVD将D分解成树形矩阵:D=UQVT,其中U和V分别是DDT和DTD的特征向量的正交矩阵,Q是对角线中包含DDT特征值的对角矩阵.缩小空间中的相似矩阵可以如下获得:
Π=UkQ-1k,(8)
其中Uk是包含k(xi,xj)=〈(xi),(xj)〉的前k列的N×k矩阵,Qk是相应特征值的对角矩阵.相似矩阵Π可以用于定义一个变换:将一个问题xi映射到向量x^i:
π(xi)=xi(WΠ)=x^i.(9)
其中,W是N×N对角矩阵,Wi,i=idf(wi)是词wi的逆文档频率(IDF).通过测量词出现在文档语料库中的频率来反映单词的重要性.假设经常出现的词不太重要,则具有较低的值,而不常出现的词却很重要,则具有较高的值.潜在语义核定义为:
KLS(xi,xj)=〈π(xi),π(xj)〉.(10)
本文作者还基于手动构建的相关词列表定义了语义相关核函数KRel:
KRel(xi,xj)=xiPPTxTj=x^ix^Tj,(11)
其中,P是反映列表中单词之间的相似性的相似矩阵.
2实验
本文作者采用Text REtrieval Conference(TREC)会议评测数据集,该数据集最初由伊利诺伊大学香槟分校发布,由6 000个已标记的问题组成,其中5 500个用作模型训练集,500个用作测试集.TREC数据集提供了两种不同粒度的问题类别标签,粗粒度描述了广义的问题类别(如动物),而细粒度则描述了狭义的问题类别(如猫、狗等).
通过在输入特征空间应用不同的核函数来对TREC数据集进行实验,不同的核函数在TREC数据集上的实验准确率如表2所示.
表2不同的核函數在TREC数据集上的实验准确率
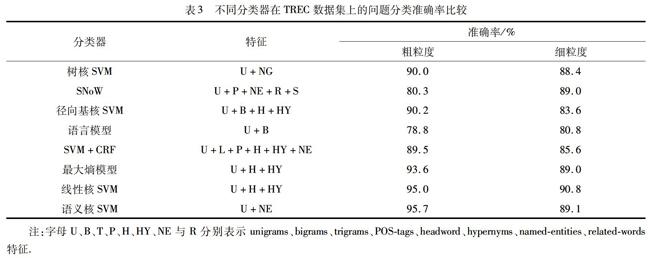
从表1中可以看出,最好的结果是通过所有3个内核的组合获得的.将所提出的语义核函数SVM算法在TREC数据集上的性能与现有的问题分类算法进行了比较(表3).
表3不同分类器在TREC数据集上的问题分类准确率比较
注:字母U、B、T、P、H、HY、NE与R分别表示unigrams、bigrams、trigrams、POS-tags、headword、hypernyms、named-entities、related-words特征.
从表2中的结果可以看出,基于语义核函数的SVM问题分类算法(语义核SVM)在TREC数据集粗粒度类别下的准确率达到最高的95.7%,而在细粒度类别下的准确率达到89.1%.当分类器在更丰富的特征空间上训练时,它们可以提供更好的性能.语法和语义特征通常可以为特征空间增加更多信息,提高分类准确率.由于问题分类中的特征非常具有依赖性,通常将所有特征组合在一起并不是特征的最佳选择,并且根据决策模型,特征的最佳组合可以不同.
3结束语
问答系统中的问题分类是一个难题,实际上,机器需要理解问题并将其分类到正确的类别.这需要通过一系列复杂的步骤才能完成.本文作者详细介绍了基于语义核函数的SVM问题分类方法,通过语法和语义特征增强特征空间可以提高分类准确率.
参考文献:
[1]Liu Y,Yi X,Chen R,et al.A Survey on Frameworks and Methods of Question Answering [C].International Conference on Information Science and Control Engineering.IEEE,2016:115-119.
[2]Mishra A,Jain S K.A survey on question answering systems with classification [J].Journal of King Saud University-Computer and Information Sciences,2016,28(3):345-361.
[3]Li X,Roth D.Learning question classifiers [C].Proceedings of the 19th international conference on Computational linguistics,Taipei:ACM,2002.
[4]Silva J,Coheur L,Mendes A C,et al.From symbolic to sub-symbolic information in question classification [J].Artificial Intelligence Review,2011,35(2):137-154.
[5]Ray S K,Singh S,Joshi B P.A semantic approach for question classification using WordNet and Wikipedia [J].Pattern Recognition Letters,2010,31(13):1935-1943.
[6]Loni B,Tulder G V,Wiggers P,et al.Question Classification by Weighted Combination of Lexical,Syntactic and Semantic Features [M].Berlin:Springer Heidelberg,2011.
