大数据时代心理学文本分析技术
——“主题模型”的应用*
2018-05-14任志洪林秀彬升赖丽足江光荣
曹 奔 夏 勉 任志洪 林秀彬 徐 升赖丽足 王 琪 江光荣
(1华中师范大学心理学院暨湖北省人的发展与心理健康重点实验室,青少年网络心理与行为教育部重点实验室,武汉 430079)
(2福州大学应用心理学系,福州 350108)
(3 Department of Counseling Psychology,University of Wisconsin-Madison,Wisconsin 53703,USA)
人的语言活动包含复杂的心理过程,并且语言也参与诸如知觉、记忆和思维等许多复杂的心理活动(王甦,汪圣安,2006),因此词汇和语言是人们将自己的内心想法和情感转化成其他人能理解的内容最普遍且可靠的方式,是认知、人格、临床和社会心理学家试图了解人类的重要媒介(Tausczik &Pennebaker,2010)。通过语言文字研究人类的心理活动,伴随着心理学发展的整个过程。
但利用传统方法对大文本进行研究面临困境,需要新的研究手段。比如,长期以来心理咨询领域积累的大量咨询逐字稿文本没有被利用(Greenberg&Newman,1996),从上世纪40年代罗杰斯第一次对心理咨询过程进行录音以来,对心理咨询评估的方法就没有什么改变(Weusthoff et al.,2016)。此外,随着互联网技术的发展,人们在社交网络中发表了大量包含各种思想、情感、观点的文本信息,这些文本包含着丰富的心理学含义(乐国安,董颖红,陈浩,赖凯声,2013)。面对大规模富含研究价值的文本数据,使用传统的心理学研究处理方法将带来巨大的人力与时间消耗(朱廷劭,2016)。可喜的是,随着计算机文本挖掘技术及其与统计技术的结合,所发展的计算机化文本分析技术(Computerized Text Analysis)为研究者提供了新的文本研究工具,使得大规模的文本数据研究变得可行(Graesser,McNamara,&Kulikowich,2011;Tausczik&Pennebaker,2010)。
“主题模型” (Topic Model)是计算机化文本分析的重要方法之一,也被称为隐含的狄利克雷分布(Latent Dirichlet Allocation,LDA;Blei,Ng,&Jordan,2003;Griffiths,Steyver &Griffiths,2007),由于对大文本具有强大的分析与建模能力,目前在计算机科学、语言学、管理科学等领域得到了广泛的应用,在心理学领域也有诸多的研究与应用(Kosinski,Wang,Lakkaraju,&Leskovec,2016;Lee et al.,2017)。本文在对主题模型的原理进行阐述的基础上,对国内外心理学领域利用主题模型开展的研究及其局限进行系统梳理,并对未来的研究方向作展望。
1 主题模型
1.1 主题模型的发展
计算机化文本分析主要基于两个层面,第一个层面是基于词频统计与情感倾向分析对文本特征进行提取,这种分析方法的思想认为人的词语语言的使用是其特质和心理过程的反映,通过对词语的量化统计来探索语言词语的使用和心理过程之间的关系。目前在心理学领域应用较广的是Pennebaker等人在上世纪 90年代开发的“语言探索与字词计数”软件(Linguistic Inquiry and Word Count,LIWC;Pennebaker,Chung,Ireland,Gonzales,&Booth,2007),LIWC在人格特征、注意指向、思维方式、亲密关系、社会关系、情绪与心理健康等众多研究领域有着大量的应用(Tausczik &Pennebaker,2010)。参照LIWC和我国台湾学者编制的能够处理繁体中文文本的CLIWC,国内研究者高锐等人(2013)开发了“文心” (TextMind)中文语义分析系统,其词库、文字和符号等处理方法专门针对简体中文语境,词库分类体系也与LIWC兼容一致(朱廷劭,2016)。虽然基于词频统计和情感倾向的文本分析方法取得了很多成果,但是以心理词典为基础的文本分析只是在处理词语的阶段,对文本的分析也只能受限于词典所创建的词汇类别,并且词典也无法理解语境、反话、同义词对于语义的影响,更无法从句子、段落等更高的意义单元来理解文本(Pennebaker,Mehl,&Niederhoffer,2003;Imel,Steyvers,&Atkin,2015)。
为了从更高的意义单元理解文本,获取准确的语义信息,需要结合文本背景信息探索文本语义结构,这也是计算机化文本分析的第二个层面,这种方法源于Deerwester,Dumais,Furnas,Landauer和Harshman (1990)提出潜在语义分析(Latent Semantic Analysis,LSA),该方法认为可以从整个语言的统计分布中学习单词的含义,并提出了类似于“主题”的“人工概念” (artificial concept)。目前 LSA 在心理学领域有诸多应用,例如它是语义空间研究的主要方法之一(鲁忠义,孙锦绣,2007),但由于一个词语只能属于一个人工概念,LSA无法解决“一词多义”的问题(Deerwester et al.,1990;Abdi &Williams,2010)。并且LSA提取的人工概念可理解性较差,最为重要的是LSA无法加入文本元数据(作者信息、文本发表时间、学术论文间的引用、论文发表会议名称等)和领域知识(其他文本研究领域的研究成果,如人工定义的语义概念的层次结构),这就使得LSA的灵活性差,应用范围相对狭小(丁轶群,2010)。
第一个真正意义上的主题模型是概率性潜在语义分析(Probabilistic Latent Semantic Analysis/Indexing,PLSA/PLSI;Hofmann,1999),它借鉴了LSA方法的长处,并且LSA的三个问题在PLSA中都得到了解决,PLSA图模型图1所示。
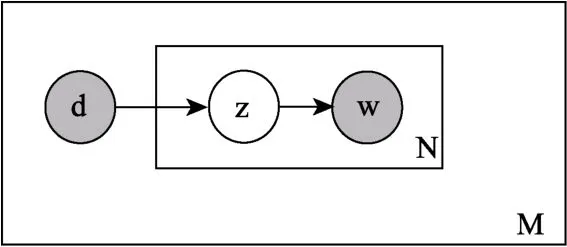
图1 PLSA示意图
图中的白色圆圈代表隐藏着的随机变量,一般是指主题等潜在语义结构,灰色的圆圈代表我们可观测到的文本,M代表文档数,N代表文档的长度,d代表文档,z代表隐含的主题,w代表单词,在PLSA中文本生成过程如下:
(1)随机选择一个文档d~p (d);
(2)根据p (z|d)选择一个隐含的主题;
(3)根据主题选择w~p (w|z),直至文档中所有单词重复上述过程。
由于 PLSA模型中单词可以以概率的形式在多个主题中存在,所以一词多义的问题得到了解决(Hofmann,1999)。此外PLSA以贝叶斯网络为理论基础,元数据和领域知识可以作为额外的随机变量添加至模型中,并且 PLSA提取的主题比人工概念更容易理解(Cohn &Hofmann,2001)。但由于在PLSA中隐含的主题中p (z|d)的参数没有生成的方法,而是直接以模型参数的方式表达,所以PLSA 并没有被认为是完整的概率性文本生成模型(徐戈,王厚峰,2011)。直至 Blei,Ng和Jordan (2003)提出隐含的狄利克雷分布(Latent Dirichlet Allocation,LDA),第一个完整的概率性语义生成模型正式出现,现在主题模型一般都指LDA模型。
1.2 主题模型的含义
LDA模型通常也被称为语义模型(Semantic Model),以及在LDA模型基础上的扩展模型。它是利用无监督的机器学习(Unsupervised learning)程序在一系列文档中发现隐含语义结构的一种统计模型,隐含语义结构由一组相关的主题构成,而文本以概率抽样的方式从该潜在语义结构中生成(Blei et al.,2003;Griffiths et al.,2007)。LDA 模型可以用贝叶斯网络进行表达,具体如图2所示。
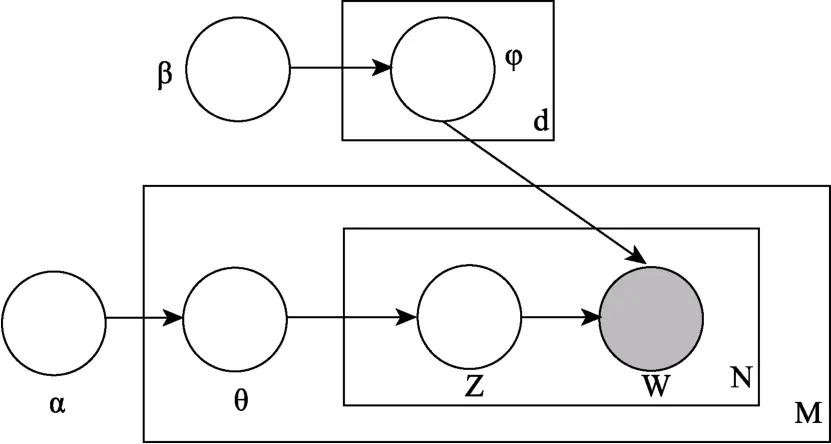
图2 LDA模型示意图
图中圆圈的含义与图1相同,φ代表主题k中词项的概率分布,θd代表文档 d的主题概率分布,两者还作为多项式分布的参数分别生成主题和单词。M代表文档数,N代表文档的长度,K代表主题数。wd,n代表第d篇文档中的第n个单词,zd,n代表第d篇文档中的第n个主题。α和β是狄利克雷分布的参数。文本由抽样的方式从LDA模型生成,文本集合D中长度为N的某文本d生成过程如下:
(1)从泊松分布Poisson (ξ)随机抽样长度为N的文档d,
(2)从狄利克雷分布 Dirichlet(α) 中抽样文本和各主题之间的联系θd,
(3)对文本d中的每一个单词wd,n∈,n{1,2,…,Nd}依次进行如下操作:
a 从多项分布Multinomial (θd)抽样单词wd,n的主题zd,n;
b 从多项分布 Multinomial (wd,n|zd,n,φ)中抽取单词wd,n。
可以看出在文本生成之前会有一个表示文本和主题关系的θd先生成,它是一个代表K个主题的K维向量,其中的元素值之和为1,每个元素值表示该主题在文本中出现的概率,接着是文本中单词wd,n的生成,先抽取单词wd,n所属的主题zd,n,然后再从该主题中抽取单词 zd,n,然后重复以上过程直至抽取文档中的所有单词。主题模型的参数有多种估计方法,如变分贝叶斯推断(Variational Bayesian Inference,VB;Blei,Ng,&Jordan,2003),目前最常用的方法是Gibbs抽样法。
1.3 主题模型的优点
1.3.1 突出的数据降维能力
有效的计算机化文本分析技术需要能够对文本进行高质量的降维,LDA是常用的降低大数据集维数的方法之一,其他的降低数据维数的方法还包含主成分分析(Principal Component Analysis,PCA)以及奇异值分解(Singular Value Decomposition,SVD)等(Kosinski,Matz,Gosling,Popov,&Stillwell,2015;Park et al.,2015)。由于大数据集中通常存在着比用户数更多的变量,在这种情况下减少数据的维度就显得十分的必要,因为大多数统计分析要求变量数小于样本量,并且即使是样本量大于变量的情况,降低数据维度会降低数据过度拟合的风险,提高统计检验力;其次,通过对数据进行分组,可以消除数据中的多重共线性和冗余(redundancy)问题;第三,一个小的维度或集群的数据,比成百上千的独立变量更容易对问题进行解释;最后,降低维度数能够减少进一步分析所占用的内存以及计算时间(Kosinski et al.,2016)。另外和 PLSA模型一样,主题模型解决了一词多义的问题,并且对数据的降维也自动解决了多词一义的问题。
1.3.2 灵活的模型扩展能力
由于主题模型以贝叶斯网络为理论基础,因此元数据和领域知识可以作为额外的随机变量添加至模型中,也能够把不同的主题模型合并形成一个新的主题模型(丁轶群,2010)。自第一个LDA模型提出来以后,众多研究人员根据不同研究的需要,在主题模型中成功加入了各种元数据信息从而构建出了不同的主题模型,如相关主题模型(Blei &Lafferty,2005)、时间主题模型(Wang,Blei,&Heckerman,2012)等,这些扩展模型极大的丰富了主题模型的应用范围。
另外研究人员通过在 LDA模型中加入单词之间的关系、语法知识等信息,在一定程度上能够克服词袋模型(bag of words)带来的问题。词袋模型将文本看作是独立词语的集合,而不考虑词语出现的顺序,也不考虑文本的句法和语义信息,虽然极大的提高了文本分析的效率,但是也存在明显的缺陷,因为词汇的分布顺序、词的结构以及语法信息都会影响对词汇含义的理解(Wallach,2006)。将这些词汇信息加入到主题模型能够帮助我们获取更准确的语义。例如 Andrews和 Vigliocco(2010)提出隐含马尔科夫主题模型(Hidden Markov Topic Model,HMTM),通过关注句子之间顺序和一般语法关系,从语言中获取语法和语义相关性,从而对语义做出更为有效的推断。Body-Graber和 Blei (2009)将语法树结构加入到主题模型中构建了语法主题模型(Syntactic Topic Models,STM)。虽然不同的扩展模型之间存在差异,但它们都应用于文本主题识别以及文本主题之间关系的研究(丁轶群,2010)。
总的来说,LDA模型在目前看来是一种较为优秀的计算机化文本分析方法。一方面,LDA模型在一定程度上克服了基于词频统计和情感倾向分析的计算机化文本分析方法的局限性;另一方面,由于LDA模型在LSA以及PLSA的基础上发展而来,能够从更高的语义层面进行文本分析的同时,也在一定程度上克服了LSA及PLSA的不足。
2 主题模型在心理学文本分析领域的具体应用
由于主题模型强大的文本分析能力,目前在文本分析领域有着丰富的研究与应用。近年来,主题模型在心理学文本分析领域的应用也逐渐增多,我们可以将目前主题模型在心理学领域的应用,分为利用心理咨询文本研究和网络行为数据研究。接下来结合具体研究应用分别进行介绍。
2.1 心理咨询领域的研究
在心理咨询领域,主题模型被用作无监督或监督的学习模型(John Lu,2010)。主题模型本身是一种无监督机器学习的统计模型,无监督的机器学习是指通过数据内在的一些属性和联系,将数据自动分类;此外机器学习还有监督学习(Supervised Learning)和半监督学习(Semi- Supervised Learning)。监督学习是指在知道数据包含类别情况下,我们可以先对一部分数据(训练数据)标注类别,并将此通过算法推广到剩余数据中;半监督学习是指利用大量的无标注数据来改进监督学习,利用观察数据(包括已标识数据和未标识数据)及相关的知识对未标识的观察数据的标识做出适当合理的推断,从而训练出更好的分类器(陈凯,朱钰,2007)。
作为无监督学习模型,主题模型主要用于探索性资料分析,该模型利用提供的咨询逐字稿的文本,来探索、发现和总结文本中讨论的主题类型;而监督学习模型,主要是利用主题模型来预测一些变量,例如利用标记主题模型(Labeled Topic Model)将行为编码分配至不同的咨询文本之中(Weusthoff et al.,2016)。
2.1.1 心理咨询文本的探索性研究
主题模型的分析结果通常描述了咨询过程中咨询师和来访者之间的会谈主题,它通过统计单词之间的共现(co-occurrence)关系将单个单词与主题相关联,和其他单词共同出现的词往往被放在同一主题中,即主题由单词列表的形式呈现。Atkins等人(2012)第一次利用主题模型对约有650万字的夫妻治疗逐字稿进行主题抽取,研究发现诸如“家人、关系、经济、性、工作、交通”六个主题会在夫妻治疗中经常出现。与此类似,Imel等人(2015)利用主题模型对 1,533次咨询会谈进行相似主题提取,模型确定了咨询过程中发生的一些主题,例如关系类主题(包含家庭角色、性、亲密关系等子类别)、治疗类主题(包含行为模式、药物、目标设定等子类别)、情绪类主题(包括焦虑、抑郁、享受等子类别)及其他类别。
利用主题模型可以发现咨询过程中的特定内容,例如特定干预或重要话题、药物和酒精使用等(Weusthoff et al.,2016)。由于在不同的会谈水平,如谈话轮(talk turns)或整个会谈(session),主题模型的结果会以概率分布的形式呈现,因此可识别具有特定内容(例如特定干预或重要主题)的单个谈话轮,例如Gaut,Steyvers,Imel,Atkins和Smyth(2017)使用主题模型对咨询逐字稿谈话轮水平进行主题抽取,发现主题模型能够较好的提取关于“物质使用”等主题。
在拥有健康体魄的基础上,应对儿童进行各种训练,使其适应抗战建国的需要。1938年,赖学文和林仲恺都强调对儿童进行精神训练、体魄训练、技能训练、生活训练、知识训练等。其中,精神训练是培养儿童以爱护民族国家为重,培养其爱国观念,启发其民族意识;体魄训练以体育锻炼为主,培养儿童身强体健,精神焕发;技能训练主要是让儿童熟练应付抗战时期的基本技能,比如防毒、消防、救护、宣传、侦查等等;生活训练是培养儿童在生活中形成守纪律、尚礼貌、吃苦耐劳、互相合作的品德;知识训练是给儿童灌输战时知识,明了国内的形势、抗战的局势,认识国际关系以及国际现状等[18]。
另外可以利用主题模型比较不同心理治疗方法的语言相似性(Rubin,Chambers,Smyth,&Steyvers,2012)。Imel等人(2015)利用主题模型对4种不同疗法的咨询逐字稿(N = 1,553)主题提取结果对每个会谈进行比较,这 4种疗法分别是药物疗法、心理动力学疗法、认知行为疗法和人文/存在疗法,结果发现尽管每种疗法内部存在某些差异,但是相同的治疗方法在语言上倾向于相似。
2.1.2 行为编码
标记主题模型是一般主题模型的一种扩展形式,可以利用它来预测行为编码(Atkins,Steyvers,Imel,&Smyth,2014;Gaut et al.,2017)。目前对于心理治疗的有效成分的研究并不直接依靠咨询过程中的语言,而是主要依靠来访者或治疗师的自我报告或者行为编码系统来量化会谈信息。一方面利用编码手册对咨询文本进行编码相当耗时,并且扩大咨询会谈评估规模意味着更大的人力投入,例如随着咨询文本长度的增加,人工编码耗时也会成倍的增加。另外一方面建立一套编码系统通常面临几个限制,首先由于人工编码会花费大量的时间和精力;其次人工编码经过了事先定义,难以发现文本中新的内容;并且非标准化编码系统无法扩展到更大的数据集;从编码者角度来看,编码者的主观性难以避免,并且他们评定消极色彩的文本时情绪可能会受到干扰,评分者信度也难以保证(Tucker &Rosenberg,1975;Tausczik&Pennebaker,2010;Atkins et al.,2012;Gaut et al.,2017);此外,行为编码系统一般不能跨文化直接使用,这也阻碍了人工编码系统的运用和推广(Zimmermann,Baucom,Irvine,&Heinrichs,2015)。由于主题模型的结果并不是直接能够得到的编码,但主题与行为或内容编码(如症状)或潜在的背景编码相对应,因此可以利用标记主题模型学习单词与主题之间的相关,并利用编码表示咨询谈话轮或会谈的内容,这样可以在一定程度上能够代替人工编码,节省人工编码的人财物消耗。
目前利用标记主题模型进行行为编码有诸多研究,越来越多的研究结果表明利用标记主题模型等方法能够有效的预测咨询会谈中的行为编码(Tanana,Hallgren,Imel,Atkins,&Srikumar,2016)。Atkins等人(2014)基于动机式访谈技巧编码手册(MISC,Motivational Interviewing Skills Code;Miller,Moyers,Ernst,&Amrhein,2008),利用人工编码的方式对 899个动机式访谈的会谈随机抽取的148个进行编码,然后利用标记主题模型学习一部分被编码的会谈。使用ROC曲线(AUC)下的面积来评估标记主题模型正确识别人造编码的能力,其中 AUC取值范围为 0.5(机会性能)至 1(完美预测),模型结果(AUC = 0.75)明显优于机会性能(AUC = 0.5),在几个编码上(如 Complex Reflections,Information Giving)模型的可靠性与人相当,但对于其他编码(如Change Talk,Sustain Talk)人的可靠性明显优于模型的性能,如果将人工编码误差考虑进去,在某些编码项目上标签主题模型的编码方法会对人工编码的方法产生很大的挑战。Gaut等人(2017)利用标记主题模型学习咨询会谈中的“焦虑、抑郁、愤怒、低自尊、情绪易感染”五个症状类主题,将标准机器学习分类器−套索逻辑回归(Lasso Logistic Regression,LLR)作为对标记主题模型进行比较的基准模型,结果显示两种模型的编码预测结果都优于随机编码水平,标记主题模型显示出比 LLR模型更高的预测精度,并且准确度接近受训的人工编码者。
2.2 社交媒体与心理健康
网络对我们的生活造成了不可逆转的影响,每天数 10亿的用户在网络上留下的痕迹会产生海量数据,将这些数据记录保存下来可以用于探究用户在互联网使用中的相关心理因素(朱廷劭,汪静莹,赵楠,刘晓倩,2015)。很多心理障碍患者需要长期持续的支持系统来提供帮助,利用网络进行社交对于与心理障碍长期斗争的人来说具有独特的价值,他们会在社交网络上发表自己的言论并寻求各种信息,因此社交媒体被认为是一些心理健康调查资料来源的新场所(de Choudhury,Gamon,Counts,&Horvitz,2013)。主题模型也因此也被用于探索他们的语言使用特点、捕捉他们行为和心理特征。
2.2.1 探索心理健康内容
利用不同心理障碍人群在社交媒体上发布的信息,可以获得他们关注的问题,也能够帮助我们获得关于不同心理障碍的见解。对抑郁症患者在社交网络上发布的信息进行主题提取,Preotiuc-Pietro等(2015)发现抑郁症患者的语言内容清晰的与郁抑症症状标准相映射;刘郁文(2017)使用主题模型对中国台湾地区三个医疗网站和一个线上同侪支持性论坛上关于抑郁症的文本资料进行文本分析,发现医患之间主要讨论的是抑郁症状、药物使用、治疗方式和家庭相关的4个主题,同侪之间的讨论则与负面情绪发生原因、压力来源、非药物治疗、同侪支持与鼓励以及医疗资讯共享五个主题相关。Mitchell,Hollingshead和Coppersmith (2015)通过对174个精神分裂症患者在Twitter上发表的内容进行主题建模,发现精神分裂症患者Twitter内容会包含其他心理健康问题,这与我们知道的精神疾病之间通常存在着共病的认识相一致。
另外通过将文本内容与元数据统一起来进行主题建模,能够帮助我们在获得某一类精神障碍患者言谈主题的同时也能够更好地理解他们的活动模式。Ji等人(2014)使用阿斯伯格综合症论坛的29,947个帖子,并将972个用户信息以及1,939个帖子和作者之间的关系的线程结构(Thread Structure)作为元数据构建主题模型。之后,模型结果发现,他们对心理健康和社会福利等问题有较多的担忧,会更多的讨论如何生活得更好的策略等。另外由于元数据的加入,主题提取结果也提供了更多有利于深入理解症状的细节,比如,涉及具体个人卫生相关的主题(例如如何刮胡子,这对于阿斯伯格综合症患者而言是困难的,因为他们可能会被剃须刀产生的声音和震动吓倒)。
2.2.2 识别精神障碍
主题模型对于社交媒体中的文本进行分析,能够发现包含心理障碍的各类疾病,此外利用主题模型的提取结果能够有效区分健康人群和精神障碍患者。Paul和Dredze (2014)对2011年至2013年的1.44亿条Twitter消息自动提取健康主题,结果表明主题模型可以发现许多身心疾病(如焦虑、抑郁症、流感、肠应激综合征等),这些疾病与真实监测和调查数据显著相关。Preotiuc-Pietro等人(2015)对选取的包含抑郁症、PTSD患者以及健康人群(对照组)的 1,145名 Twitter用户的内容进行主题提取,利用提取主题结果构建标签训练了三个标准机器学习的二进制分类器,使用ROC曲线(AUC)下的面积评估标记主题模型正确区分不同精神障碍的能力,抑郁症组和控制组、PTSD组和控制组、抑郁症组和PTSD三组的AUC值分别是0.871、0.883、0.801。Nguyen,Phung,Dao,Venkatesh和Berk (2014)通过抓取在线抑郁社区及控制组社区的网络文本,利用 LIWC及主题模型对这两个文档集进行分析,利用 LIWC比较两个人群的使用区别,并构建一个主题数为50的主题模型分别对文本进行主题抽取。为比较哪些特征对抑郁症社区有更好的预测力,文中使用正规化的回归模型Lasso分别对1,000名抑郁患者和1,000名控制组被试进行区分,发现 LIWC和主题模型提取结果都能有效的区分这两类人,但是主题模型结果(93%)略优于LIWC的结果(88%)。
有些精神障碍(例如,抑郁症)是随着时间而变化的连续结构,而不仅仅只是诊断有或者没有这种障碍,Schwartz等人(2014)利用 n-gram主题模型(Wang,McCallum,&We,2007)的结果及词语使用对28,749位Facebook用户的不断更新的状态构建回归模型并预测用户的抑郁症状与时间变化之间的关系,利用模型来估计用户在不同季节的抑郁变化,发现与文献研究一致(Golder &Macy,2011),用户的抑郁程度从夏季到冬季的时间段内通常会提高。
2.3 人格计算
主题模型也被应用于人格研究之中。人格是心理科学领域的一个基本研究范畴,目的是探索共同的心理现象在个体身上表现的差异性,传统人格测量一般通过自陈式量表或者投射测验的方法进行,早期研究发现词汇使用具有稳定的个体差异且人格与自陈式报告可靠相关(Pennebaker &King,1999)。但由于自陈量表需要人工填写,难以有效实现针对大规模用户的实时测量,因此需要进一步完善(朱廷劭,2016),社交媒体上的文本数据通常是个体在自然的社会环境中书写的关于自己真实生活内容的表达(Back et al.,2010),因此社交媒体上的语言是研究人格特征的一个非常丰富的数据库,近年来利用社交媒体针对大规模人群的人格研究内容十分丰富(Hughes,Rowe,Batey,&Lee,2012;Quercia,Lambiotte,Stillwell,Kosinski,&Crowcroft,2012;Schwartz et al.,2013;Ortigos,Carro,&Quiroga,2014),并且有研究比较人类和利用计算机模型的人格判断的准确性,结果表明计算机预测(r = 0.56)比参与者的Facebook好友使用人格问卷预测(r = 0.49)结果更准确(Wu,Kosinski,&Stillwell,2015)。
在人格研究领域主题模型最初用于探索主题使用和人格之间的关系。Schwartz等人(2013)第一次利用 LDA提取的主题特征来构建大五人格特征的函数,发现诸多关于人格特征与主题使用之间的联系,例如情绪稳定的人提到更多的体育和生活活动,外向的人更多的和派对相关联等。随着研究的发展,人格主题模型也被不断提出来。Liu,Wang和Jiang (2016)建立PT-LDA模型用来预测社交网络用户的个性特征,模型假设主题的选择决定了人格类型。Hu,Liu,Zhang和Xu (2017)提出一个新的人格主题模型,和 PT-LDA相反,该模型假设人格类型(Personality)决定了主题的选择,主题是服从高斯分布的人格特点(Personality Traits)的集合,人格特点又通过服从多项分布的单词来表现,模型利用MyPersonality dataset进行测验,结果表明该模型对于人格有良好的预测。
2.4 主题模型的扩展
近年来面对不同的需要,结合具体文本背景信息的主题模型在心理学领域有着诸多应用。例如许多语义认知心理学理论认为概念通过特征来表示,但由于人类提取特征的经验过程依赖于明确判断,这限制了利用特征表示概念的范围,Steyvers,Smyth和Chemuduganta (2011)将De Deyne等人(2008)研究的特征规范(feature norms)添加到主题模型中,模型结果表明利用特征信息能更准确的推断文档中的新概念。Steyvers等(2011)利用人工定义的语义概念的层次结构与主题模型相结合,从而构建了概念层次结构主题模型,该模型结果表明当有额外的背景信息时,模型结果的解释能力增强。Griffiths,Steyvers和Tenenbaum (2007)通过对1967年以来的《心理评论》(Psychological Review)中所有的文章摘要构建层次主题模型,准确地还原了 40年间在该期刊上发表文章的主题之间的层次化关系以及研究主题。Priva和Austerweil (2015)对《认知》(Cognition)期刊中1980~2014年间发表的3,014篇文章的摘要进行主题建模,并加入文章发表时间元数据,以此跟踪道德认知、语言加工、青少年发展等5个研究主题随着时间的变化的冷热程度,此外还发现认知心理学的研究随着时间的推移,从注重建立抽象理论转向更多实验研究。
总之,目前在心理学领域,研究人员利用主题模型开展了较为丰富的研究。这些研究探索了大规模的心理咨询文本、社交媒体数据;结合具体文本背景信息的主题模型在心理学领域也有着诸多应用。这些研究拓展了心理学的研究范围,丰富了文本分析研究方法的研究内容,在一定程度上克服了传统文本分析方法难以开展大文本分析的局限。
3 主题模型自身局限、改进及应用促进
3.1 主题模型自身局限及改进
作为一种实用的计算机化文本分析方法,主题模型虽然在众多领域得到了应用,但是它并不是一种可以开箱即用的工具,主题模型配置的复杂性和主题质量问题是目前主题模型使用者遇到的一个普遍性问题。首先,对于非专家而言,主题模型很多配置可能难以理解。参数设置上,对于狄利克雷分布参数α和β的取值一般为α = 50/K,β = 0.01,其中K代表主题数,这样取值是为了起到平滑数据的作用,在一些情况下,也可以使用语料对α和β进行经验贝叶斯估计(徐戈,王厚峰,2011)。对于主题数的确定,经验的取值方法一般是设置为20、50、100、200等数值,然后在每个主题下提取 10个关键词(刘郁文,2017),但对于不同的文本如何确定合适的主题数并没有明确的解决方法。
另外为生成高质量的主题,使用者先要对文本做很多预处理,例如删除停止词、抽取短语(Chunking)(Lee et al.,2017)。针对这些问题,领域专家在不断优化算法、扩展主题模型形式的基础上,也在为使用主题模型的用户提供更便利的操作方法来帮助用户,如果对主题模型提取的结果不满意,用户在不重新配置或者重新建模的基础上也可以通过一些优化策略来改进结果。例如允许用户直接在主题下面添加、删除或者突出显示单词(Hu,Boyd-Graber,Satinoff,&Smith,2014),也可以在主题中调整单词的权重、合并或者分割主题并创建新的主题(Choo,Lee,Reddy,&Park,2013),Lee,Kihm,Choo,Stasko 和 Park (2012)则允许用户将文档重新分配给其他主题。在对以往主题模型操作改进方法进行总结的基础上,Lee等人(2017)通过设计实验考察了非专家对主题模型的感知及对主题模型结果的优化策略的选择,帮助非专家更好的使用主题模型。
最后,由于中文的特殊性,中文分词是中文自然语言处理的固有问题。李湘东、高凡和丁丛(2017)比较了目前最广泛使用的三种中文分词方法在LDA模型下对文本分类性能的影响,研究结果显示三种方法都能有效的进行分词,但是对于不同的文本三种方法在分词的准确性上有着差异,并且不同的中文分词方法对文本分类的结果有一定影响。
3.2 主题模型的应用问题及促进
在心理咨询领域,利用主题模型的一个重要的限制可能是转录工作带来的。在使用主题模型之前研究人员需要转录成千上万份的会谈逐字稿,这是一项耗时耗力的工作。但从长远来看这项工作是值得的,因为大型咨询文本数据库的建立对于心理咨询研究的潜在影响是不可估量的,并且随着自动化语音识别技术的发展,转录需要人工参与的部分可能会越来越少。
另外,利用网络数据进行研究一个重要的问题是对伦理隐私的保护。互联网信息技术的发展,使得网络上的个人隐私和非隐私之间的界限似乎变得十分模糊,并且前所未有的数据挖掘、数据预测以及更全面的监控技术的发展,使得对个人隐私的保护也变得更为困难(薛孚,陈红兵,2015)。利用主题模型对各类心理健康问题的识别、监控和预测,或进行人格计算等研究,都需要挖掘相关的网络数据,在互联网信息技术发展带来的变革中,研究者需要在风险和创新之间找到一个平衡点,规避数据隐私伦理问题。
总之,主题模型自身以及应用上目前还存在着诸多局限,尤其在汉语语言背景下,这些局限限制了主题模型在心理学研究领域的使用范围。目前研究者也在不断地在对这些局限进行改进,以提高主题模型的质量及使用范围。另外在目前信息与技术高速发展的时代,也需要我们心理学研究者与其他领域的研究人员开展跨领域合作研究,从而更好地解决我们在研究中遇到的问题。
4 小结与展望
4.1 小结
作为一种计算机化文本分析的方法,主题模型被用来探索心理咨询和社交媒体上人们的语言内容。在心理咨询领域研究人员探索了在咨询过程中来访者和咨询师讨论的主要话题和咨询师的干预措施,区分不同的治疗流派,并尝试利用主题模型进行编码;利用社交媒体上的数据,研究人员探索了不同心理障碍群体主要谈论的内容,探索他们关注的问题,并且利用主题模型的结果对不同的心理障碍进行区分和预测;另外仅仅利用人们在社交媒体上发布的动态,主题模型以高度准确的方式对发布者的人格进行了预测。主题模型在心理学研究中取得了诸多研究成果,但是由于某些局限性使得需要对这一研究方法进行进一步的改进。不过从现有研究结果来看,主题模型在心理学文本分析领域的研究中有着较大潜力,未来也需要我们进一步拓展和使用该方法在心理学领域的研究。
4.2 研究展望
长期以来,本土的心理学重问卷、实验等量化研究,而相对轻文本分析等质性研究的局面一直没有改变,其中一个重要的原因是经济有效的文本分析方法没有被研究者所掌握(张信勇,2015)。一方面在临床心理学、管理心理学等领域存在着大量的咨询会谈或访谈文本记录;另一方面互联网也记录了海量的人类心理和行为的文本数据,但这些富含研究价值的文本资料并没有得到有效的使用。诸如LIWC、潜在语义分析(LSA)和本文提到的主题模型等计算机化文本分析方法并没有在本土心理学的研究中得到广泛的使用。虽然这些研究方法并不完美,但是目前这些方法的使用,对于我们开展心理学中关于文本分析的研究有着重要的价值。
我们通过语言来表达对自我和世界的认识,也通过语言和世界建立联系,正如海格德尔所说,语言是存在的家园,人先天地就被语言所贯穿、所引导(Heidegger,2009),诸多文本中包含着重要的研究价值。为不使明珠蒙尘,在未来的研究中,研究者可以积极利用主题模型开展相关的研究,将主题模型等文本分析工具应用到咨询会谈、访谈文本以及互联网中的各种文本数据中,探索中文环境下不同类型文本的丰富内涵;也可以开展跨文化比较研究,探索中西方文化下不同情境中出现的主题差异及背后的原因;此外,由于主题模型在算法和操作上也在不断的发展,未来可以通过多种途径对主题模型改进,如通过整合关于时间和句法结构的信息等途径(Weusthoff et al.,2016),来改善心理学领域中利用主题模型开展的文本分析。
参考文献
陈凯,朱钰.(2007).机器学习及其相关算法综述.统计与信息论坛,22(5),105–112.
丁轶群.(2010).基于概率生成模型的文本主题建模及其应用(博士学位论文).浙江大学,杭州.
高锐,郝碧波,李琳,白朔天,朱廷绍.(2013).中文语言心理分析软件系统的建立.心理学与创新能力提升——第十六届全国心理学学术会议论文集.南京.
Heidegger,M.(2009).路标 (孙周兴 译) 上海: 商务印书馆.
乐国安,董颖红,陈浩,赖凯生.(2013).在线文本情感分析技术及应用.心理科学进展,21(10),1711–1719.
李湘东,高凡,丁丛.(2017).Lda模型下不同分词方法对文本分类性能的影响研究.计算机应用研究,34(1),62–66.
刘郁文.(2017).忧郁症线上讨论言谈之主题分析 (硕士学位论文).台湾大学,台北.
鲁忠义,孙锦绣.(2007).语义空间的研究方法.心理学探新,27(3),22–28.
王甦,汪安圣.(2006).认知心理学.北京: 北京大学出版社.徐戈,王厚峰.(2011).自然语言处理中主题模型的发展.计算机学报,34(8),1423–1436.
薛孚,陈红兵.(2015).大数据隐私伦理问题探究.自然辩证法研究,31(2),44–48.
张信勇.(2015).LIWC: 一种基于语词计量的文本分析工具.西南民族大学学报: 人文社会科学版,36(4),101–104.朱廷劭.(2016).大数据时代的心理学研究及应用.北京:科学出版社.
朱廷劭,汪静莹,赵楠,刘晓倩.(2015).论大数据时代的心理学研究变革.新疆师范大学学报: 哲学社会科学版,(4),100–107.
Abdi,H.,&Williams,L.J.(2010).Principal component analysis.Wiley Interdisciplinary Reviews: Computational Statistics,2(4),433–459.
Andrews,M.,&Vigliocco,G.(2010).The hidden Markov topic model: A probabilistic model of semantic representation.Topics in Cognitive Science,2(1),101–113.
Atkins,C.,Rubin,T.N.,Steyvers,M.,Doeden,M.A.,Baucom,B.R.,&Christensen,A.(2012).Topic models:A novel method for modeling couple and family text data.Journal of Family Psychology,26(5),816–827.
Atkins,D.C.,Steyvers,M.,Imel,Z.E.,&Smyth,P.(2014).Scaling up the evaluation of psychotherapy: Evaluating motivational interviewing fidelity via statistical text classification.Implementation Science,9,49.
Back,M.D.,Stopfer,J.M.,Vazire,S.,Gaddis,S.,Schmukle,S.C.,Egloff,B.,&Gosling,S.D.(2010).Facebook profiles reflect actual personality,not self-idealization.Psychological Science,21(3),372–374.
Blei,D.M.,&Lafferty,J.D.(2005).Correlated topic models.In Proceedings of the 18th international conference on neural information processing systems (pp.147–154).Vancouver,British Columbia,Canada: MIT Press.
Blei,D.M.,Ng,A.Y.,&Jordan,M.I.(2003).Latent Dirichlet Allocation.Journal of Machine Learning Research 3,993–1022.
Boyd-Graber,J.L.,&Blei,D.M.(2009).Syntactic topic models.In Advances in Neural Information Processing Systems 26 (pp.185–192).Lake Tahoe,Nevada,USA:MIT Press.
Choo,J.,Lee,C.,Reddy,C.K.,&Park,H.(2013).Utopian:User-driven topic modeling based on interactive nonnegative matrix factorization.IEEE Transactions on Visualization and Computer Graphics,19(12),1992–2001.
Cohn,D.A.,&Hofmann,T.(2001).The missing link-a probabilistic model of document content and hypertext connectivity.In Advances in Neural Information Processing Systems 13 (pp.430–436).London,England: MIT Press.
de Choudhury,M.,Gamon,M.,Counts,S.,&Horvitz,E.(2013).Predicting depression via social media.In Proceedings of the Seventh international AAAI conference on weblogs and social media (pp.128–137).Boston,MA: AAAI Publications.
De Deyne,S.,Verheyen,S.,Ameel,E.,Vanpaemel,W.,Dry,M.,Voorspoels,W.,&Storms,G.(2008).Exemplar by feature applicability matrices and other Dutch normative data for semantic concepts.Behavior Research Methods,40(4),1030–1048.
Deerwester,S.,Dumais,S.T.,Furnas,G.W.,Landauer,T.K.,&Harshman,R.(1990).Indexing by latent semantic analysis.Journal of the American Society for Information Science,41(6),391–407.
Gaut,G.,Steyvers,M.,Imel,Z.E.,Atkins,D.C.,&Smyth,P.(2017).Content coding of psychotherapy transcripts using labeled topic models.IEEE Journal of Biomedical and Health Informatics,21(2),476–487.
Golder,S.A.,&Macy,M.W.(2011).Diurnal and seasonal mood vary with work,sleep,and daylength across diverse cultures.Science,333(6051),1878–1881.
Graesser,A.C.,McNamara,D.S.,&Kulikowich,J.M.(2011).Coh-Metrix: Providing multilevel analyses of text characteristics.Educational Researcher,40(5),223–234.Greenberg,L.S.,&Newman,F.L.(1996).An approach to psychotherapy change process research: Introduction to the special section.Journal of Consulting and Clinical Psychology,64(3),435–438.
Griffiths,T.L.,Steyvers,M.,&Tenenbaum,J.B.(2007).Topics in semantic representation.Psychological Review,114(2),211–244.
Hofmann,T.(1999,August).Probabilistic latent semantic indexing.In Proceedings of the 22nd annual international ACM SIGIR conference on research and development in information retrieval (pp.50–57).Berkeley,California,USA: ACM.
Hughes,D.J.,Rowe,M.,Batey,M.,&Lee,A.(2012).A tale of two sites: Twitter vs.Facebook and the personality predictors of social media usage.Computers in Human Behavior,28(2),561–569.
Hu,Y.N.,Boyd-Graber,J.,Satinoff,B.,&Smith,A.(2014).Interactive topic modeling.Machine Learning,95(3),423–469.
Hu,Z.,Liu,Y.S.,Zhang,C.H.,&Xu,Y.N.(2017,June).The analysis of topic's personality traits using a new topic model.In 2017 2nd international conference on image,vision and computing (ICIVC)(pp.1079–1083).Chengdu:IEEE.
Imel,Z.E.,Steyvers,M.,&Atkins,D.C.(2015).Computational psychotherapy research: Scaling up the evaluation of patient–provider interactions.Psychotherapy,52(1),19–30.
Ji,Y.F.,Hong,H.,Arriaga,R.,Rozga,A.,Abowd,G.,&Eisenstein,J.(2014).Mining themes and interests in the Asperger’s and autism community.In Workshop on computational linguistics and clinical psychology: From linguistic signal to clinical reality (pp.97–106).Baltimore,Maryland USA: ACL.
John Lu,Z.Q.(2010).The elements of statistical learning:Data mining,inference,and prediction.Journal of the Royal Statistical Society: Series A (Statistics in Society),173(3),693–694.
Kosinski,M.,Matz,S.C.,Gosling,S.D.,Popov,V.,&Stillwell,D.(2015).Facebook as a research tool for the social sciences: Opportunities,challenges,ethical considerations,and practical guidelines.American Psychologist,70(6),543–556.
Kosinski,M.,Wang,Y.L.,Lakkaraju,H.,&Leskovec,J.(2016).Mining big data to extract patterns and predict real-life outcomes.Psychological Methods,21(4),493–506.
Lee,H.,Kihm,J.,Choo,J.,Stasko,J.,&Park,H.(2012).iVisClustering: An interactive visual document clustering via topic modeling.Computer Graphics Forum,31,1155–1164.
Lee,T.Y.,Smith,A.,Seppi,K.,Elmqvist,N.,Boyd-Graber,J.,&Findlater,L.(2017).The human touch: How nonexpert users perceive,interpret,and fix topic models.International Journal of Human-Computer Studies,105,28–42.
Liu,Y.Z.,Wang,J.J.,&Jiang,Y.C.(2016).PT-LDA: A latent variable model to predict personality traits of social network users.Neurocomputing,210,155–163.
Miller,W.R.,Moyers,T.B.,Ernst,D.,&Amrhein,P.(2008).Manual for the Motivational Interviewing Skill Code(MISC).Version 2.1.University of New Mexico,Center on Alcoholism.
Mitchell,M.,Hollingshead,K.,&Coppersmith,G.(2015,June).Quantifying the language of schizophrenia in social media.In Proceedings of the 2nd workshop on computational linguistics and clinical psychology: From linguistic signal to clinical reality (pp.11–20).Denver,Colorado: ACL.
Nguyen,T.,Phung,D.,Dao,B.,Venkatesh,S.,&Berk,M.(2014).Affective and content analysis of online depression communities.IEEE Transactions on Affective Computing,5(3),217–226.
Ortigosa,A.,Carro,R.M.,&Quiroga,J.I.(2014).Predicting user personality by mining social interactions in Facebook.Journal of Computer and System Sciences,80(1),57–71.
Park,G.,Schwartz,H.A.,Eichstaedt,J.C.,Kern,M.L.,Kosinski,M.,Stillwell,D.J.,...Seligman,M.E.P.(2015).Automatic personality assessment through social media language.Journal of Personality and Social Psychology,108(6),934–952.
Paul,M.J.,&Dredze,M.(2014).Discovering health topics in social media using topic models.PLoS One,9(8),e103408.
Pennebaker,J.W.,Chung,C.K.,Ireland,M.,Gonzales,A.,&Booth,R.J.(2007).The development and psychometric properties of liwc2007.Austin,29(11),1020–1025.
Pennebaker,J.W.,&King,L.A.(1999).Linguistic styles:Language use as an individual difference.Journal of Personality and Social Psychology,77(6),1296–1312.
Pennebaker,J.W.,Mehl,M.R.,&Niederhoffer,K.G.(2003).Psychological aspects of natural language use: Our words,our selves.Annual Review of Psychology,54(1),547–577.
Preotiuc-Pietro,D.,Eichstaedt,J.,Park,G.,Sap,M.,Smith,L.,Tobolsky,V.,...Ungar,L.(2015,June).The role of personality,age and gender in tweeting about mental illnesses.In Proceedings of the 2nd workshop on computational linguistics and clinical psychology: From linguistic signal to clinical reality (pp.21–30).Denver,Colorado: Association for Computational Linguistics.
Priva,U.C.,&Austerweil,J.L.(2015).Analyzing the history of Cognition using topic models.Cognition,135,4–9.
Quercia,D.,Lambiotte,R.,Stillwell,D.,Kosinski,M.,&Crowcroft,J.(2012,February).The personality of popular Facebook users.In Proceedings of the ACM 2012 conference on computer supported cooperative work (pp.955–964).Seattle,Washington,USA: ACM.
Rubin,T.N.,Chambers,A.,Smyth,P.,&Steyvers,M.(2012).Statistical topic models for multi-label document classification.Machine Learning,88(1-2),157–208.
Schwartz,H.A.,Eichstaedt,J.C.,Kern,M.L.,Dziurzynski,L.,Ramones,S.M.,Agrawal,M.,...Ungar,L.H.(2013).Personality,gender,and age in the language of social media:The open-vocabulary approach.PLoS One,8(9),e73791.
Schwartz,H.A.,Eichstaedt,J.,Kern,M.L.,Park,G.,Sap,M.,Stillwell,D.,...Ungar,L.(2014,June).Towards assessing changes in degree of depression through Facebook.In Proceedings of the workshop on computational linguistics and clinical psychology: From linguistic signal to clinical reality (pp.118–125).Baltimore,Maryland USA: Association for Computational Linguistics.
Steyvers,M.,Smyth,P.,&Chemuduganta,C.(2011).Combining background knowledge and learned topics.Topics in Cognitive Science,3(1),18–47.
Tanana,M.,Hallgren,K.A.,Imel,Z.E.,Atkins,D.C.,&Srikumar,V.(2016).A comparison of natural language processing methods for automated coding of motivational interviewing.Journal of Substance Abuse Treatment,65,43–50.
Tausczik,Y.R.,&Pennebaker,J.W.(2010).The psychological meaning of words: LIWC and computerized text analysis methods.Journal of Language and Social Psychology,29(1),24–54.
Tucker,G.J.,&Rosenberg,S.D.(1975).Computer content analysis of schizophrenic speech: A preliminary report.The American Journal of Psychiatry,132(6),611–616.
Wallach,H.M.(2006,June).Topic modeling: Beyond bag-of-words.In Proceedings of the 23rd international conference on machine learning (pp.977–984).Pittsburgh,Pennsylvania,USA: ACM.
Wang,C.,Blei,D.,&Heckerman,D.(2012).Continuous time dynamic topic models.arXiv preprint arXiv:1206.3298.Wang,X.R.,McCallum,A.,&Wei,X.(2007,October).Topical n-grams: Phrase and topic discovery,with an application to information retrieval.In Seventh IEEE international conference on data mining,2007 (pp.697–702).Omaha,NE: IEEE.
Weusthoff,S.,Gaut,G.,Steyvers,M.,Atkins,D.C.,Hahlweg,K.,Hogan,J.,...Narayanan,S.(2016).The Language of Interpersonal Interaction: An Interdisciplinary Approach to Assessing and Processing Vocal and Speech Data.The European Journal of Counselling Psychology.
Wu,Y.Y.,Kosinski,M.,&Stillwell,D.(2015).Computer-based personality judgments are more accurate than those made by humans.Proceedings of the National Academy of Sciences of the United States of America,112(4),1036–1040.
Zimmermann,T.,Baucom,D.H.,Irvin,J.T.,&Heinrichs,N.(2015).Cross-country perspectives on social support in couples coping with breast cancer.Frontiers in Psychological and Behavioral Science,4(4),52–61.
