基于应用技术实现语言处理研究
2018-05-13郭建伟燕娜陈佳宇
郭建伟,燕娜,陈佳宇
(北京市科学技术情报研究所信息资源部,北京 100044)
互联网搜索的查询被划分成少数几个关键词而不是以自然语言表述的实际的问题。人们可以用基于社区的问答系统通上下文获得更为明确的理解而给出更好的回答。相比而言,一个互联网搜索引擎对于一段很长的查询只能给出很差的返回结果或不返回任何有价值的东西。人们只能将他们的问题转化成一个或几个贴切的关键词去尝试相对贴切的回复。信息检索研究的长期目标是开发检索模型来为更长、更专门的查询提供精确的结果。因此需要更好的理解文本信息。严格来说,自然语言处理[1][2](Natural Language Processing),包括自然语言理解和自然语言生成两部分。
一、语言处理
自然语言就是人交流用的语言。自然语言处理的研究方向包括以下几种[2]:
规则方法:可以用规则的方法预先准备好一些先验知识。然后用统计的方法来处理未知的情况。把些人工经验放入规则库。很多时候,人讲话并不是按概率来的,除非是随便说说。比如说,怎么减肥,只能说吃那么几样减肥的食品。
统计方法:语料库就是一个文档的样本库。需要有很大的规模,オ有概率统计的意义,可以假设很多词和句子都会在其中出现多次。
计算框架:算法设计是一件非常困难的工作,需要有很好的数据结构基础,采用的算法设计技术主要有迭代法、分治法、动态规划法等,互联网搜索经常面临海量数据,需要分布式的计算框架来执行对网页重要度打分等计算。
语义库:自然语言中的语义复杂多变,如:在“买玩偶送女友”中,“送”这个词不止一个义项,Opence 提供了OWL 格式的英文知识库。
二、语言文法分析
自动句法分析[3]主要有两种模式:一是短语结构语法,二是依存语法,依存语法更能体现句子中词与词之间的关系。StanfordParser 实现了一个基于要素模型的句法分析器,其主要思想就是把一个词汇化的分析器分解成多个要素(factor)句法分析器。Stanford Parser 将一个词汇化的模型分解成一个概率上下文无关文法(PCFG)和一个依存模型,Sharpnlp 可以图形化显示句法树,它是用C#实现的,可以利用依存关系改进一元分词,也可以利用依存关系改进二元分词等。
三、语言文档排重
互联网给人们提供了数不尽的信息和网页,其中有许多是重复和多余的,这就需要文档排重[4]。比如,央行的征信中心会收到来自不同银行申请贷款的客户资料,需要合并重复信息,并整合成一个更完整的客户基本信息,这就可以通过计算信息的相似性合并来自不同数据来源的数据。文档排重的方法中语义指纹是可行的方法之一。在具体的针对句子做抄袭性检测的实践中,可以按句子生成Simhash,然后根据生成的文档指纹信息对文档分类。
同义词替换:“年糕”也叫作“切糕”,如果有人听不懂某个词,可以换个说法再重复一遍。需要把说法统一,例如把“国家税务局”替换成“国税局”,“国税局”是“国家税务局”的缩略语企业的简称和全称可以看成是语义相同的。一般来说,可以用长词替换短词。在地址方面有时会有各种不同的写法和行政区域编码,这时同义词替换的方法之一是可以把门牌号码中文串转成阿拉伯数字。例如:“甘家口一号楼”转换成:“甘家口1 号楼”。汉语中构造缩略语的规律很诡异,目前也没有一个定论。初次听到这个问题,几乎每个人都会做出这样的猜想:缩略语都是选用各个成分中最核心的字,比如“海关检查”缩成“海检”“人民法官”缩成“法官”等。不过,反例也是有的,“邮政编码”就被缩成了“邮编”,但“码”无疑是更能概括“编码”一词的。当然,这几个缩略语已经逐渐成词,可以加进词库了。
四、信息抓取
信息抓取(Information Extraction,IE),是把文本里包含的信息进行结构化处理[5],变成表格一样的组织形式。在信息抓取系统中,输入的是原始文本,输出的是固定格式的信息点。这些被抓取的信息点以统一的形式集成在一起。这就是信息抽取的主要任务。例如草莓价格上涨,樱桃价格下跌,语义标注出草莓和樱桃都是水果,得到关键词“水果”。信息抽取技术并不试图全面理解整篇文档,只是对文档中包含相关信息的部分进行分析。在信息抽取中,要完成指代消解的任务,从网页中如何抓取有用的信息并将其归类的方法。比如,如何从一个大的正确词表中找和输入词编辑距离小于k 的词集合,使用了两个有限状态机求交集的方法。

图1 关键词提取流程图
关健词提取是文本信息处理的一项重要任务,例如可以利用关键词提取来发现新闻中的热点题。和关键词类似,很多政府公文也有主题词描述,上下文相关广告系统也可能会用到关键词提取技术,统计词频和词在所有文档中出现的总次数。TF(Term Frequence)代表词频,IDF(Invert Document Frequence)代表文档频率的倒数。比如说“的”在100文档中的40 篇文档中出现过,则文档频率DF(Document Frequence)是40,IDF 是140。“的”在第一篇文档中出现了15 次,则TFWIDI(的)=15*140-0.375。另外一个词“反腐数”在这100 篇文档中的5 篇文档中出现过,则DF 是5,IDF 是15。“反腐败”在第一篇文档中出现了5 次,则TF*IDF(反腐败)=5*1/5=1,结果是:TF*DF(反腐败)TF+DF(的)。
模糊匹配问题:从用户查询词中挖掘正确提示词表,一般不需要提示没有任何用户搜索过的词,可以输入任何词,然后自动机可以基于是否和目标词的编辑距离最多不超过给定距离从而接收或拒绝它。而且,由于FSA 的内在特性,可以在O(n)时间内实现。这里,m 是测试字符串的长度。而标准的动态规划编辑距离计算方法需要O(m*)时间,这里m 和n 是两个输入单词的长度。因此编辑距离自动机可以更快地检查许多单词和一个目标词是否在给定的在最大距离内。
五、语言自动摘要
所谓自动摘要,就是利用计算机自动地从原始文献中提取摘要[6]。比如,手机显示屏的大小是有限的,因此智能手机上显示新闻的短摘要。对于论坛中长篇的帖子,有的网友会求摘要。最简单的自动生成摘要的方法是返回文格的第一句,稍微复杂点的方法是首先确定最重要的几个句子,然后根据最重要的几个句子生成摘要。
六、语义文本分类
文本分类就是让计算机对一定的文本集合按照一定的标准进行分类。比如,小李是个足球迷,喜欢看足球类的新闻,新闻推荐系统使用文本分类技术为小李自动推荐足球类的新闻。文本分类程序把一个未见过的文档分成已知类别中的一个或多个,例如把新闻分成国内新闻和国际新闻。利用文本分类技术可以对网页分类,也可以用于为用户提供个性化新闻或者垃圾邮件过滤把给定的文档归到两个类别中的一个叫作两类分类,例如垃圾邮件过滤,就只需要确定“是”还是“不是”垃圾邮件。分到多个类别中的一个叫作多类分类,例如中图法分类目录把图书分成22 个基本大类文本分类主要分为训练阶段和预测阶段。训练阶段得到分类的依据,也叫作分类模型。预测阶段根据分类模型对新文本分类。训练阶段一般先分词,然后提取能够作为分类依据的特征词,最后把分类特征词和相关的分类参数写入模型文件。提取特征词这个步骤叫作特征提取。早期经常采用朴素贝叶斯的的文本分类方法,后来支持向量机方法成为首选。除此之外,还可以对人的行为聚类。90 年代末期,美国S.Reis 教授通过对2300 多名被试者的300 多种行为所做的因素分析表明,人类的所有行为可以聚类为15 种行为。
七、语音类型识别
语音识别技术[7],也被称为自动语音识别(Automatic Speech Recognition,ASR),它是一种交叉学科,与人们的生活和学习密切相关,其目标是将说话者的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。比如,将来打银行的客服电话,可以直接和银行系统用口语对话,而不是“普通话请按1”这样把人当成机器的询问,实现语音交互。初学者不会写代码,有经验的程序员可以口述代码,然后让初学者把代码敲进去,为了节约程序员的时间,可以用语音识别代码根据语音翻译成文字,进一步,还可以根据识别出的文字识别语意,这样可以让机器和人交流。儿童识别图片后,可以说出这个图是老虎还是大象。系统使用语音识别技术判断孩子回答是否正确。对于不正确的,系统自动给出提示。开放式语音识别做好不容易,可以辅助人工输入字幕,类似语音输入法。Julius是日本京都大学和一家日本公司开发的大词汇量语音识别引弊,是一种高性能、与语音相关的研究和开发的解码器软件,基于字的N-gram 和上下文相关的HMM 模型,目前已经应用于日语和汉语的大规模连续语音识别。在Juis 系统中存在连个模型:语言模型和声学模型。
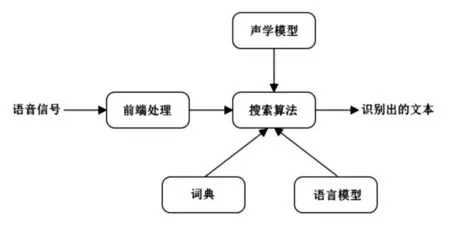
图2 语音识别结构
八、总结
自然语言处理技术包括很多方面,如文本分类、对话系统、机器翻译等。人们经常用到的查询功能使用的是搜索引擎技术,用户在搜索引擎中输入较长的问题时,计算机要能够给出准确的答案。在几乎是所有的我们从电影或电视上看到的未来,搜索引擎已经进化到类似人类助手一样能回答针对任何事物的复杂问题的程度。然而,尽管互联网搜索引擎能够导航非常巨大的知识范围,但是我们要达到智能助手的能力还很远。
猜你喜欢
杂志排行

中阿科技论坛(中英文)的其它文章
- The Potentials,Challenges and Path for Achieving Science and Technology Cooperation between China and Arab States under the Background of the Belt and Road Initiative
- Enterprise Asset-backed Securitization:Legal Structure Is Not So Vulnerable
- Development of Automatic Transfer Device for Tie Line between Substation Areas in View of Carrier Communication
- Computer Aided Design of Straw Checkerboard Sand Barriers Paving Machines
- Research on Abnormal Increase of Metro Track Potential
- Analysis of Reasons on Tripping of Electrolysis Series Causing by Misoperation