基于Spark的改进K-means快速聚类算法
2018-05-09徐健锐詹永照
徐健锐, 詹永照
(1. 江苏大学 计算机科学与通信工程学院, 江苏 镇江 212013; 2. 江苏联合职业技术学院 镇江分院, 江苏 镇江 212016)
聚类分析是数据挖掘领域重点研究的方向之一,其中经典的K-means聚类算法[1]得到了广泛的研究和使用.但是,近几年来随着大数据、云计算等新技术的发展,普通规模的数据都达到了TB级[2],而且数据特征越来越复杂,脏数据也越来越多.在这种背景下,对聚类分析算法的性能要求越来越高.经典的K-means聚类算法虽然得到了广泛应用,但是它过分的依赖算法初始K个中心点的选择[3],初始点选择不合适,就很容易导致最终解局部最优,使算法的迭代次数增加,特别是算法处理的数据量很大时,执行效率的缺陷就更明显[4].因此,随着待处理数据量的不断增加,有必要对K-means聚类算法的缺陷进行改进,并进行大规模快速K-means聚类算法的研究.
基于内存的分布式[5]计算框架Spark是继分布式计算框架Hadoop之后又一个被广泛应用的主流大数据处理和计算平台[6].它采用内存式数据存储方式,而不需要将计算过程产生的中间数据转存到磁盘当中,极大地减少了计算过程中与磁盘的数据交换次数[7],从而提高了数据的处理速度.相对于Hadoop分布式计算框架而言,Spark在处理同一数量级数据时,处理速度有百倍的提高.Spark的内存分布式计算建立在一种叫做弹性分布式数据集[8](resilient distributed dataset,RDD)的数据抽象基础之上.通过这种数据抽象,可在本地服务器上操作集群上其他服务器上的数据集,非常适合于大规模数据多次迭代计算的优化.在Spark内存分布式框架基础上开发的机器学习算法库[9](machine learning library,MLlib)可作为算法基础,针对基础应用进行扩展,广泛应用的算法主要包括聚类分析、分类以及多种回归算法.
Spark内存分布式框架基础上开发的机器学习算法库不仅能够实现不同规模集群间的分布式计算,并且很好地将矩阵的转置、相乘、相加以及求和等基础操作融合到计算过程中.通过对原始待计算数据进行矩阵划分,既可以利用矩阵基础算法提高计算速度,又可以减少不同结点之间的数据交换.针对K-means算法因初始聚类点选择不当导致局部最优、迭代次数增加而无法适应大规模数据聚类的问题,通过预抽样和最大最小距离相结合对K-means算法进行改进.
文中将改进的K-means算法和分布式计算框架Spark结合提出大数据下的快速聚类算法Spark-KM,既弥补经典K-means算法的不足,又发挥了Spark分布式计算处理速度快的优势;并通过单机和集群环境的试验对比,证明算法在大数据规模下的可扩展性和有效性.
1 相关研究
1.1 K-means算法
K-means算法[10]从待聚类的原始数据集中随机选择K个数据点作为初始聚类中心,然后根据特定的距离算法计算非中心点到聚类中心的距离,进行初步的聚类划分.最后计算每个聚类中到中心点的平均距离,并调整聚类中心,经过多次迭代最终使得聚类中元素最相似,类间的元素不相似.
具体的算法如下.输入:聚类中心的初始个数K和待聚类的数据集S.输出:最终的聚类结果,即K个类簇.详细步骤: ① 从待聚类的数据集S中随机选择K个对象作为初始聚类中心; ② 计算非中心点到每个聚类中心的距离,将该点回归到距离最短的那个聚类中心所在的类簇中; ③ 计算每个类簇中距离的平均值作为新的聚类中心; ④ 根据每个非中心点到中心点的距离最小原则,对数据集进行重新聚类; ⑤ 重复步骤③,④,直到聚类簇不再变化,或者达到设定的迭代次数就结束算法.
K-means算法的主要缺点[11]: ① 算法对初始聚类中心的选择和待处理数据点的输入次序敏感,也就是说,选择不同的初始聚类中心,不同的待处理数据点输入次序,对应的最终聚类结果差别很大; ② 如果初始聚类中心靠近某个最小值,经过多次迭代之后,很容易陷入局部最优解的情况,这样会增加算法的迭代次数,随着迭代次数的增加,算法在处理大数据时时间效率将会非常低; ③ 原始数据中存在孤立点时,算法的聚类准确性很难保证.
1.2 Spark
Spark是近几年开始流行的基于内存的分布式计算框架[12],它和分布式计算框架Hadoop相比,共同点在于均利用了MapReduce的思想,所以Spark具有Hadoop的所有优点.但是,因为Spark是基于内存的,也就是说计算过程的中间结果存储在内存中,而不需要将其转存到磁盘,这样就减少了输入输出的时间消耗,所以较Hadoop更适合于大数据量、多次迭代的计算.
Spark是一个集成了多个计算组件的统一软件栈.通过计算引擎,Spark可以协调和调度运行在多个工作机器或计算机集群上的计算组件.Spark的生态系统主要包括结构化数据、实时计算、机器学习和图计算几个部分,其各个组件见图1.
Spark SQL是一种可以用来操作结构化数据的程序集合[13].在Spark SQL基础上可以利用SQL或者Apache Hive的SQL对数据进行查询操作.Spark streaming 是Spark提供的可以对实时数据进行流式计算的组件,适合于处理网络服务器日志、网络实时更新的消息队列等流式数据.MLlib集成了常用的机器学习的算法,主要包括协同过滤、回归、分类、聚类等,还提供了对数据模型的评估和数据的导入等额外功能.GraphX主要是用来完成对基于图的模型的操作,比如从社交网络图中挖掘社交关系和常用的图计算.
弹性分布式数据RDD是分布式的元素集合,是Spark对数据的核心抽象.Spark通过创建RDD、转换RDD、以及调用RDD的相关操作,对集群数据结点的操作实现本地化操作,最后将数据分发到集群上,实现操作的并行化.图2给出了RDD的相关操作转换.
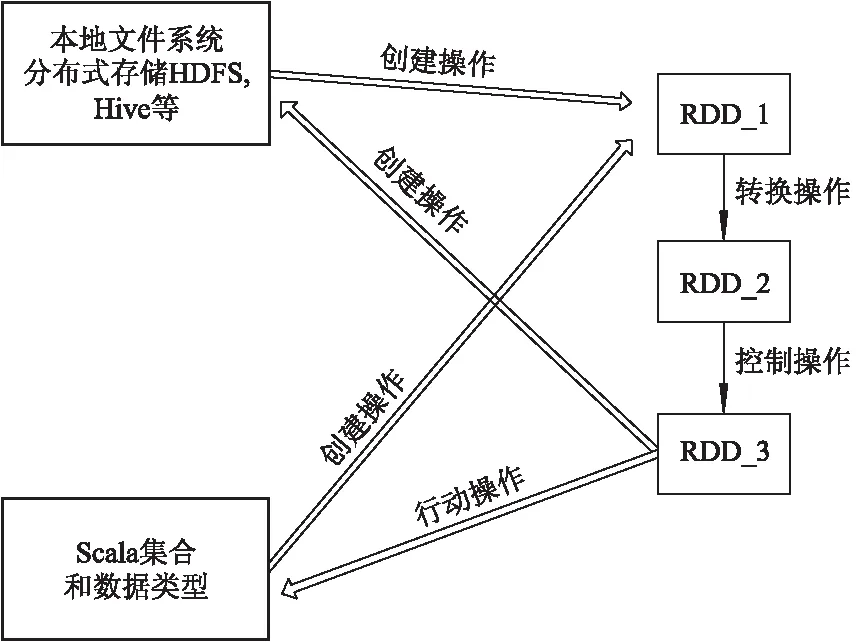
图2 RDD的相关操作转换
2 改进K-means算法
2.1 算法改进思想
在1.1节中分析了K-means算法的主要缺点,下面对如何优化初始聚类中心和并行化提出解决办法.
改进算法的思想如下:设原始数据集Y={y1,y2,…,yn},且yi∈Rd,其中:n是数据集中的数据个数;yi代表d维向量.改进算法首先从原始数据集Y中随机抽取一个较小的数据集Y′,令|Y′|=|Y|×s,其中:|Y′|,|Y|分别代表数据集Y′和Y的元素个数;s为抽样调和数,s的取值通常在1%~20%内(即从原始数据集中抽取1%~20%的数据),具体大小根据原始数据的数据量确定.然后根据最大最小算法抽取聚类中心C1,再将C1作为初始聚类中心C.每次计算新的聚类中心时,聚类都可以独立进行,所以可以使用MapReduce分布式计算框架进行并行化计算,从而提高计算效率.根据相应的距离计算方法计算新聚类中心与初始聚类中心的距离,如果该距离小于设定的阈值,则算法迭代结束,返回新的聚类中心和聚类的结果,否则用新的聚类中心更新初始聚类中心,直到满足阈值条件.
大数据的聚类容易因孤立点对聚类准则函数造成影响,所以将聚类准则函数,即加权的聚类准则函数Jc改进为
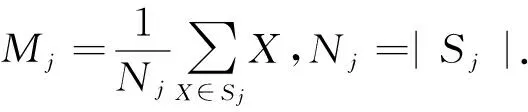
改进算法的时间复杂度为o(nk(s+t)/(M×N)),其中:n为数据集中的数据个数;k为聚类个数;t为算法的迭代次数;M为Map作业的个数;N为进行计算的集群中结点个数.
2.2 改进算法的执行过程
聚类个数为k,阈值设定为T,则改进算法步骤如下:
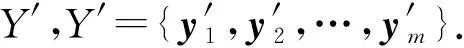
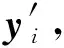
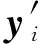
3) 将C1作为初始聚类中心C,使用Spark分布式并行计算新的聚类中心C′.
4) 计算C与C′的距离,并与阈值T比较:如果小于,则返回聚类中心C和聚类结果,否则用C′作为新的聚类中心重新迭代计算,直到满足阈值条件.
3 Spark矩阵操作定义
Spark以弹性分布式数据集为核心数据抽象,为方便程序的开发,提供了创建、转换和动作等基础操作[14].但是,通常情况下需要组合使用这些操作,特别是对矩阵的处理,相应的专用操作比较少,这就导致很多算法只能在本地操作,而不适用于运行效率更高的分布式操作.为此,文中给出基于Spark平台常用矩阵操作的分布式计算方法.
3.1 矩阵操作定义
定义1矩阵Am×n表示有m行n列的数值矩阵,即
在Spark-KM算法中,对原始数据采用矩阵划分的方式,利用IndexedMatrix对矩阵划分后的原始数据进行矩阵存储,从而充分利用集群中分布式内存的优势,使算法可以用于大规模的数值计算[15].IndexedMatrix在集群中的分布如图3所示.
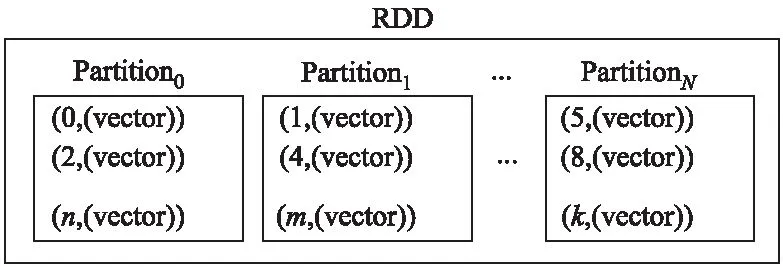
图3 RDD矩阵存储
由图3可见,一个RDD包含多个Partition,每个Partition由多个行向量组成,每个行向量又包含一个索引和本地向量vector.
定义2矩阵转置如下:定义1中矩阵对应的转置矩阵是一个n×m矩阵,用AT表示,即
Spark通过flatMap,reduce等操作完成矩阵转置.图4通过具体实例来说明RDD的转换过程,数据的行向量(i,Vi)集合表示矩阵.
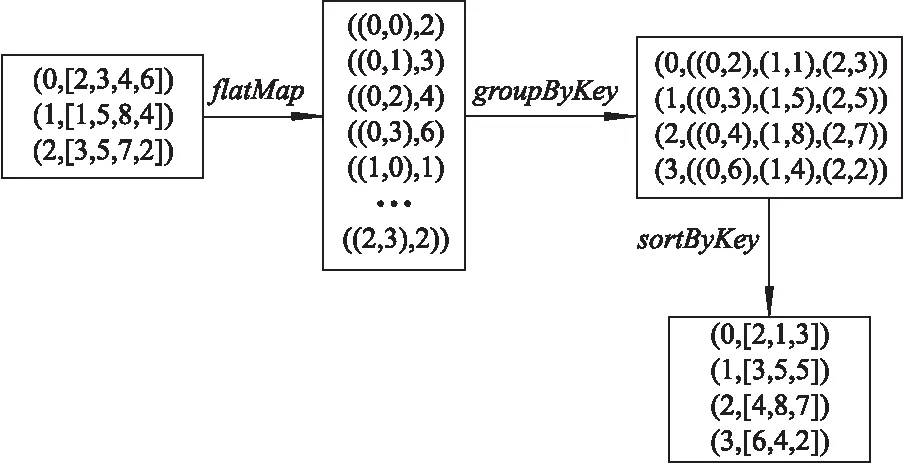
图4 RDD的转换过程
由图4可见,通过flatMap操作将原始数据分解成列与行对应的键值对,然后将列数据通过groupByKey操作分配到同一组,并通过排序操作sortByKey对每个划分内的数据排序,得到最终结果.
转换过程的伪代码如下:
matrixAT=A.map(row=>row.vector.toArray)
.flatMap(vector=>{
vararray=newArray[Double,Int)](vector.size)
for(i<-0 tovector.size-1)
{array(i)=(a(i),i)}
returnarray}).map(v=>(v._2,v._1)).
groupByKey().sortByKey().map(line
=>new
IndexedRow(line._1,Vectors.dense(line._2.toArray)))
定义3矩阵乘法如下:m行n列的数值矩阵A左乘n行l列的矩阵B,得到m行l列的矩阵C,即Am×n×Bn×l=Cm×l.在Spark平台中,通过Map和MapReduce来实现矩阵乘法.
Map矩阵乘法:对于数据量较小并且可以在单节点内存中存放的矩阵,将其广播到集群中的所有节点内,在本地只进行分块乘法,最终计算结果用RDD存放.
文中的矩阵运算以行向量为计算单位,但是,传统矩阵是行与列的组合,不符合文中算法规则.所以,首先通过转置操作将矩阵的乘法转换为行向量相乘,从而充分利用Spark内存计算的特性.用行作为计算单位,可以充分利用行数据在物理存储上的连续性,从而避免传统矩阵列存储不连续性造成的缓存浪费.Map矩阵乘法的RDD变换操作见图5.
Map矩阵乘法伪代码如下:
matrixB=sc.broadcast(BT)
matrixC=A.map(line=>newIndexedRow(
ai.index,(vectorci
for(bi<-B)
{for(i<-0 tovector.size-1)
{ci(i)=ai×bi}}
returnci}))
MapRdduce矩阵乘法:对于两个较大的数据矩阵很难在一个集群节点直接存储的情况,首先把矩阵进行转置,然后计算笛卡尔积和乘积,最后输出计算结果.
MapReduce矩阵乘法的RDD变换操作见图6.

图5 Map矩阵乘法的RDD变换

图6 MapReduce矩阵乘法的RDD变换
MapReduce矩阵乘法伪代码如下:
matrixA=AT
matrixC=B.cartesian(A)
.map(row=>(bj.index,Aj.index),row._1×row._2))
.groupByKey().sortByKey().map()
定义4矩阵加法如下:两个同型矩阵对应元素相加,即
cij=aij+bij,C=A+B.
在Spark中首先通过join连接两个矩阵,然后通过map得到结果.矩阵加法的RDD操作过程见图7.
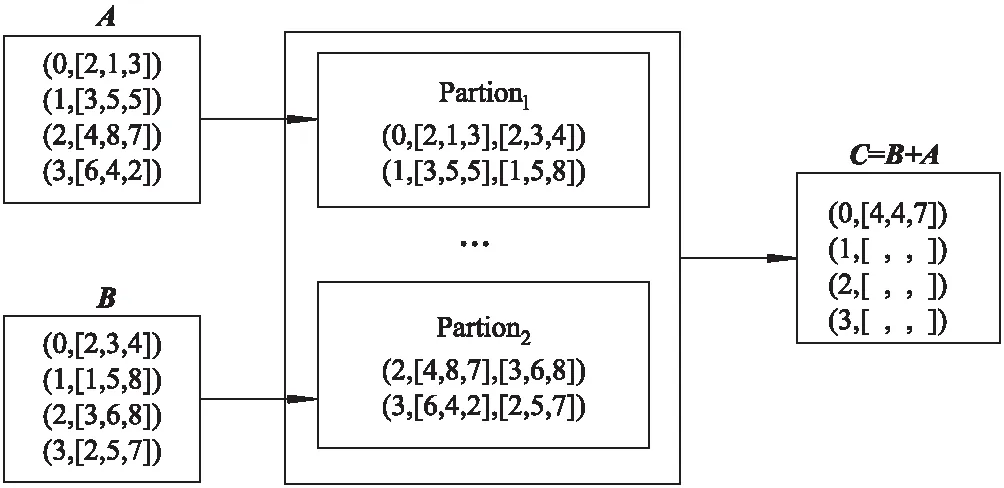
图7 矩阵加法的RDD操作
矩阵加法伪代码如下:
matrixA=AT
matrixC=B.join(A).map(Ai+Bi)
3.2 广播变量
在Spark-KM算法中,把较小的数据集广播到集群中的结点内存,然后相应的map操作进行计算,从而减少reduce过程中数据在结点间的移动次数.算法中定义广播变量Broadcast,在集群节点中只保存一个只读备份,把作业的粒度定义为节点粒度,充分利用内存,同时优化Broadcast,节约节点间的通信开销.
4 Spark-KM算法
基于第2节改进K-means算法和第3节Spark矩阵操作的定义,提出分布式内存计算平台Spark基础上的改进K-means算法Spark-KM算法.该算法避免了传统K-means聚类算法初始聚类中心选择不当而使聚类结果陷入局部最优的不足,通过矩阵运算,不仅提高了运算速度,减少节点间数据的移动次数,还利用分布式特性使算法能够处理大规模数据的聚类问题.
传统K-means算法需要多次迭代计算新一轮聚类的中心、数据点到聚类中心的距离,每一个步骤都需要在集群中的结点间进行数据移动.Spark-KM算法根据RDD数据特点和相关操作,利用广播变量来减少数据在节点间的移动,从而减少节点间通信负担,提高算法的整体效率.
Spark-KM算法的主要步骤如下:
1) 重新计算聚类中心.根据2.2节改进K-means算法执行过程中聚类中心的计算方法,通过Spark定义的矩阵乘法和累加,以及定义的广播变量来实现.将矩阵通过广播变量分布到集群中的所有节点当中,每个结点中单独进行距离计算并更新聚类中心,最终以RDD的形式返回计算结果.
2) 距离矩阵的计算.距离矩阵存放原始数据与聚类中心的距离.在计算过程中,由于聚类中心的数据点个数相对原始数据来说规模较小,所以把聚类中心以广播变量的形式广播到集群中所有的结点,这样就可以实现本地计算,而不需要在节点间移动数据.然后,距离矩阵转置,方便后续操作.
3) 更新隶属矩阵.隶属矩阵表征数据点属于哪个聚类.通过矩阵累加操作,计算每个数据点到聚类中心的距离之和,然后通过广播变量把距离和分发到集群中的所有节点;最终通过map操作得到隶属矩阵,为判断数据点隶属于哪个聚类做准备.
4) 依据初始设定的距离阈值或者迭代次数确定是否继续迭代运算.
Spark-KM算法伪代码如下:
Spark-KM()
for(i<-0 to maxiter)∥maxiter最大迭代次数
{C=S(X×U)∥broadcast矩阵乘法
D=C×X∥计算距离矩阵
U=D.map()∥更新隶属矩阵
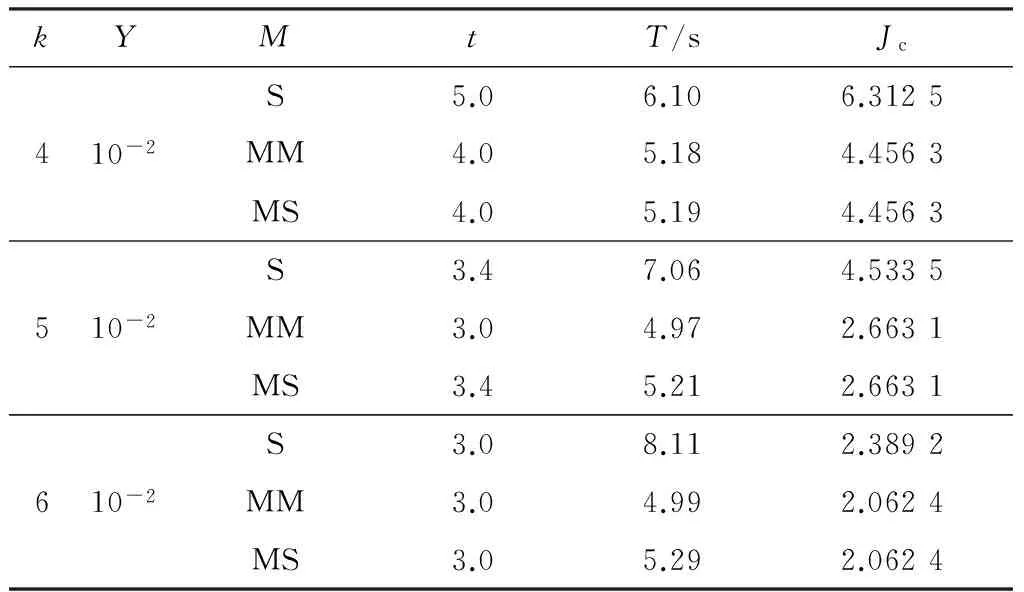
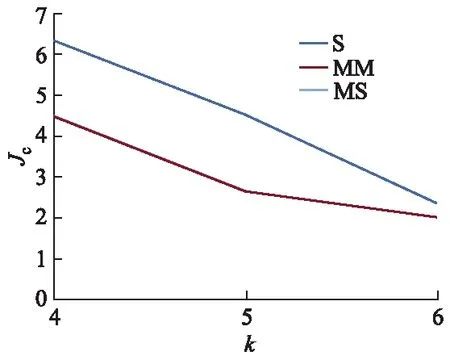
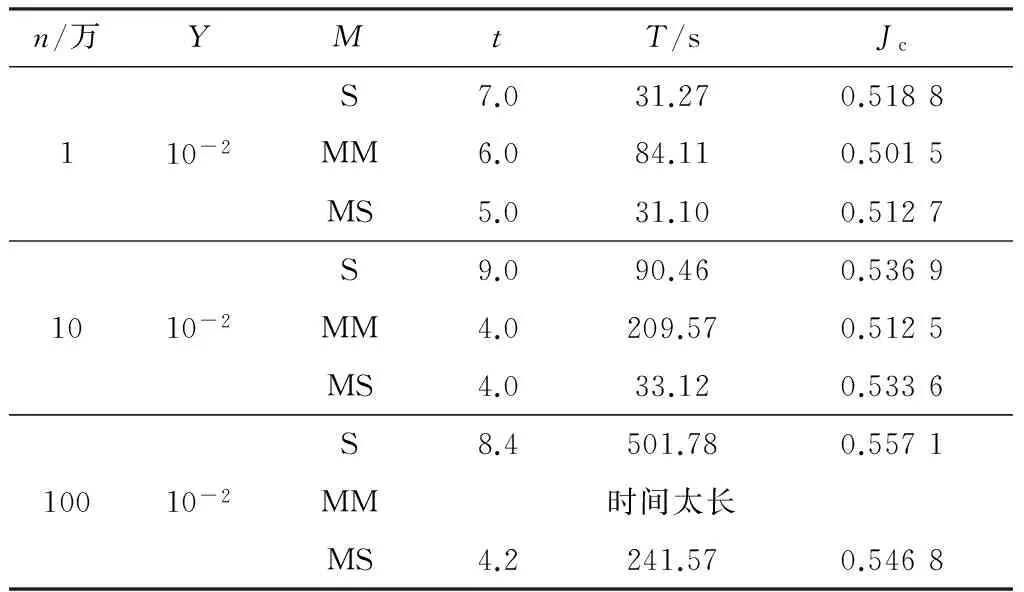
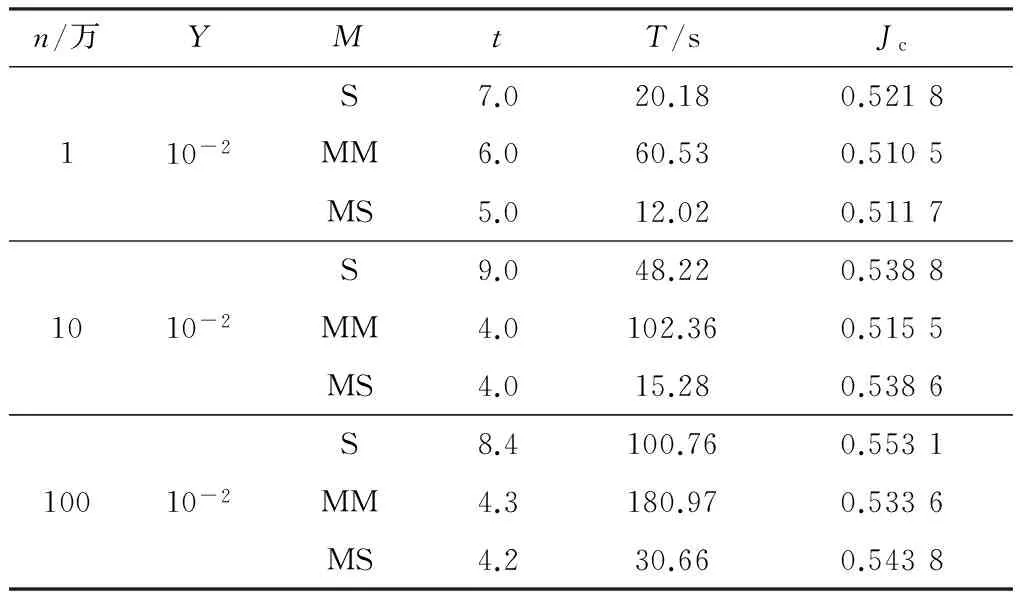
if(Ji-Ji-1 break} 硬件环境如下:四核CPU,主频为3.4 GHz,硬盘2 TB,内存8 GB.软件环境如下:VMware 12.5.2,操作系统CentOS6.5,jdk1.8.0_45,scala-2.10.4,hadoop-2.6.0,spark-1.3.0-bin-hadoop 2.4. 试验内容主要包括两部分: ① 对改进K-means算法的有效性进行验证; ② 在单机和集群环境下对比Spark-KM算法的性能,并验证Spark-KM算法在集群中大数据处理的可扩展性和适应性. 试验中参数含义如下:n为待聚类的数据点个数(单位:万);k为聚类个数;Y为结束条件;M为选用的聚类方法;t为迭代次数;T为运行时间. 5.2.1 改进K-means算法有效性的验证 几种算法可简写如下:S代表普通的K-means算法,即随机选择聚类中心;MM代表通过最大最小距离选择聚类中心的K-means算法;MS代表文中的改进算法,即通过随机抽样,然后用最大最小距离选择聚类中心的K-means算法. 验证试验数据为人工标注的5万条测试数据.表1是不同聚类方法在不同聚类个数中的5次聚类结果的平均值.图8给出了Jc趋势图. 表1 不同方法的聚类结果 图8 Jc趋势图 由表1和图8可见,MM算法在5次试验中都比较稳定,对随机选择聚类中心的聚类算法S起到了优化作用,且明显优于S算法.但是,当数据量很大时,依据最大最小距离算法迭代计算聚类的中心时,不仅会花费大量的时间,也容易导致内存不足.所以,选择这两种距离计算方法的折中,即文中的改进算法MS,通过随机抽样,然后用最大最小距离选择聚类中心的K-means算法. 5.2.2 单机伪分布验证Spark-KM算法有效性 有效性试验中随机产生1万、10万、100万个聚类数据点,单机伪分布,选择100个聚类中心,方法同5.2.1,试验结果见表2. 表2 单机伪分布试验结果 由表2可见,通过3个数据量的试验对比,在数据量较小的情况下,基于最大最小距离计算聚类中心算法MM的聚类准则函数Jc最小,且算法运行时间最短;但是,随着处理的数据量增大,MM算法在迭代计算聚类中心时所需时间过长,由表2可知,100万个数据点的聚类时间已经无法接受,说明这种算法已经不再适合大数据的聚类.文中的改进算法MS,在单机情况下,与S,MM算法相比,在聚类准则函数Jc相差不大且稳定的前提下,有明显的时间优势. 5.2.3 集群环境验证Spark-KM算法有效性 本试验是在VMware中配置5台虚拟机,1台作为master节点,其他4台作为slave节点.为了与单机伪分布进行对比,本试验依然采用5.2.2中的试验数据,聚类中心个数为100,试验结果见表3. 表3 集群试验结果 由表2,3的对比可见,在数据量、迭代次数相同,聚类准则函数Jc相近的情况下,MS算法的时间效率有了明显的提高;同时,S,MM,MS这3种方法在相同数据量的聚类中,MS算法所用时间只有其他两种方法的1/3~2/3,并且随着数据量的增加,MS算法的时间效率比其他两种算法提高得更快.原因在于: ① Spark-KM算法在充分发挥分布式内存计算框架内存计算的高效性基础上,通过改进基于RDD的矩阵分布式计算和广播变量,实现了本地计算,从而减少了节点间的数据传输带来的效率损耗; ② 改进的K-means算法通过抽样的方法避免聚类陷入局部最优,同时最大最小距离计算聚类中心,使聚类中心的选取最优化,从而减少迭代次数. 文中改进了K-means聚类算法,并结合分布式内存计算框架Spark提出了Spark-KM算法.通过随机抽样和基于最大最小距离优化聚类中心的选择;改进Spark的矩阵计算,对原始数据进行矩阵分割,并存储在不同的Spark计算框架的节点当中,能够减少节点间的数据移动次数.试验结果表明,Spark-KM算法能够实现大数据的快速聚类,并且具有很好的可扩展性. 后续将继续研究聚类中心的优化选取方法和分布式矩阵计算,并在改进算法的基础上开发基础函数库. 参考文献(References) [ 1 ] 张庆新,崔展博,马睿,等.基于k-means聚类与径向基神经(RBF)网络的电力系统日负荷预测[J].科学技术与工程,2013, 13(34):10177-10181. ZHANG Q X, CUI Z B, MA R, et al. Daily load forecasting of industrial enterprise power system based onk-means clustering and RBF neural network[J]. Science Technology and Engineering, 2013,13(34):10177-10181.(in Chinese) [ 2 ] 赵国锋,葛丹凤.数据虚拟化研究综述[J].重庆邮电大学学报(自然科学版), 2016, 28 (4): 494-502. ZHAO G F, GE D F. A survey on data virtualization[J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2016, 28(4): 494-502.(in Chinese) [ 3 ] 杨杰明,吴启龙,曲朝阳,等.MapReduce框架下基于抽样的分布式K-Means聚类算法[J]. 吉林大学学报(理学版),2017,55(1):109-115. YANG J M, WU Q L, QU C Y, et al. DistributedK-means clustering algorithm based on sampling under Map-Reduce framework[J]. Journal of Jilin University(Science Edition), 2017,55(1):109-115. (in Chinese) [ 4 ] 王飞,秦小麟,刘亮,等.云环境下基于数据流的k-means聚类算法[J].计算机科学, 2015,42(11):235-239,265. WANG F, QIN X L, LIU L, et al. Algorithm fork-means based on data stream in cloud computing[J]. Computer Science,2015,42 (11):235-239,265. (in Chinese) [ 5 ] LIU Y, XU L X, LI M Z. The parallelization of back propagation neural network in MapReduce and Spark[J].International Journal of Parallel Programming, 2017,45(4):760-779. [ 6 ] 朱叶青,牛德姣,蔡涛,等.不同网络环境下大数据系统的测试与分析[J].江苏大学学报(自然科学版),2016,37(4):429-437. ZHU Y Q,NIU D J,CAI T,et al. Test and analysis of big data system in different network environment[J]. Journal of Jiangsu University (Natural Science Edition), 2016, 37(4): 429-437.(in Chinese) [ 7 ] ZADEH R B, MENG X R, ULANOV A, et al. Matrix computations and optimization in Apache Spark[C]∥Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]:ACM, 2016:31-38. [ 8 ] LIU J, LIANG Y, ANSARI N. Spark-based large-scale matrix inversion for big data processing[J]. IEEE Access, 2016, 4: 2166-2176. [ 9 ] 唐云.基于Spark的大规模分布式矩阵运算算法研究与实现[D].南京:南京大学,2016. [10] FRIGGSTAD Z, REZAPOUR M, SALAVATIPOUR M R. Local search yields a PTAS fork-means in doubling metrics[C]∥Proceedings of the Foundations of Compu-ter Science. Piscataway:IEEE,2016:365-374. [11] 尹绪森.Spark MLlib:矩阵参数的模式[J]. 程序员,2014(8):108-112. YIN X S. Model of Spark MLlib: matrix parameter[J]. Programmer,2014(8):108-112. (in Chinese) [12] 王吉源,孟祥茂,廖列法.具有层次结构的K-means聚类算法研究[J].微电子学与计算机,2015,32(12):63-67. WANG J Y, MENG X M, LIAO L F. Research on an improved hierarchical clustering algorithm ofK-means[J]. Microelectronics and Computer,2015,32 (12):63-67. (in Chinese) [13] 王晓华.Spark MLlib机器学习实践[M].北京:清华大学出版社,2015. [14] 兰云旭,王俊峰,唐鹏.基于Spark的并行医学图像处理研究[J].四川大学学报(自然科学版),2017,54(1):65-70. LAN Y X, WANG J F, TANG P. Parallel processing researches of medical image based on Spark[J]. Journal of Sichuan University (Natural Science Edition), 2017, 54(1):65-70. (in Chinese) [15] 郑凤飞,黄文培,贾明正.基于Spark的矩阵分解推荐算法[J].计算机应用,2015, 35(10):2781-2783,2788. ZHENG F F, HUANG W P, JIA M Z. Matrix factorization recommendation algorithm based on Spark [J].Journal of Computer Applications,2015,35(10):2781-2783,2788. (in Chinese)5 试验与结果分析
5.1 试验环境
5.2 试验内容和结果分析
6 结 论
