基于新浪微博的爬虫程序设计与实现
2018-05-09胡海潮
胡海潮
(昆明理工大学,云南 昆明 650000)
随着网络技术的快速发展,信息社会进入大数据时代。其中,在线社交网络(Online Social Network,OLSN)所产生的数据特征尤其明显,其规模巨大,内容丰富,影响范围广[1-2]。因此,对此类社交网络数据的采集研究,分析人物特点,获得统计规律具有十分重要的研究意义。
但如何有效地提取出这些信息成为研发人员一个巨大的挑战。其中,新浪微博作为中国最具影响力的社交网络工具之一,所产生的数据有别于传统的线下数据,其数据规模非常大,其信息可以在网络中无限扩展,热点信息存在爆炸性增长特性,这些特点使得通过人工自己来寻求答案不仅费时,而且特别费力[3]。此外,虽然新浪提供了供开发者获取数据的访问编程接口(OpenAPI),但其对普通用户具有权限,抓取频率等都有严格的限制,且无法对微博内容进行搜索[4]。为此,本文提出了一款基于新浪微博的爬虫程序设计方法。
本文以移动端微博用户为例,设计并提出了一款以人与人关系为连接的网络爬虫,可以模拟登录并获取相关人物名称等信息,并将这些数据保存到本地,方便做进一步的数据挖掘与分析。同时,本文爬虫还通过解析关键路径以匹配,利用该匹配功能可以实现网页指定路径的数据提取,最后,通过广度遍历,逐层获得人物之间的关系[5]。使用本文爬虫程序,不仅稳定性强、易操作,而且还能够缩短数据分析人员的开发程序所需时间,使得他们可以将更多的精力放在数据分析上面。
1 相关概念
1.1 网络爬虫
网络爬虫,也被称为网页蜘蛛[6]。简单地说,便是一个计算机程序,按照定义好的规则从互联网上抓取网页信息。网络爬虫这种技术不仅可以用来检查站点中所有链接是否有效,还可被搜索引擎使用,将抓取到的网页的关键数据保存到本地。其最基本的思路为:将一批链接设为种子,然后从这些链接中获取更多的链接进行下一轮抓取[7]。然而实际应用中,由于互联网数据繁多,不可能将网上全部数据抓取下来,我们往往抓取到一定数量后,会自动终止程序。据了解,现今最好的搜索引擎,也无法爬取整个互联网一半的网页。
1.2 Python语言
Python语言是在计算生态的大背景下诞生、发展和再生,是一种功能强大、语法简洁清晰的开源编程语言,且几乎能够在目前所有的操作系统上运行[8-9]。其中,Python3系列语言在Python2的基础上,又做了进一步优化,能够将其他编程语言最优秀的成果封装起来,简化功能实现的复杂度,使我们爬取数据更加简便。Python语言非常强大,是高效率的完全面向对象的语言,能有效而简单地实现面向对象编程,其第三方功能库很多,使用也很方便。因此,本文利用Python3作为编程语言进行相关数据内容的爬取。
1.3 广度遍历
广度遍历是连通图的一种遍历策略。其基本思想是:从图中某一顶点V0出发,首先访问该顶点;随后从V0出发,访问与V0直接相连接但未曾访问的顶点W1,W2,…Wk;然后,依次从W1,W2,…Wk出发,访问与其直接连接但未曾访问的顶点;重复上述步骤直至所有顶点全被访问。由于社区网络用户信息量大、耗时长等原因,实际运行时,我们很难将全部用户信息获取完,所以我们首先会定义运行到多少层用户自动结束。与其相类似的还有深度遍历,此处不再赘述。
2 程序设计
2.1 模拟浏览器登录
模拟浏览器登录有两种实现方法:(1)直接运用网站中的cookie登录。(2)通过模拟提交表单登录。
方法1直接使用cookie登录,避免了因用户频繁输入账号和密码造成的不便,可以安全地登录进微博中,又不泄露用户的隐私,利于系统的分布式实现,可以支持导入第三方的账户,但是由于cookie本身的限制,一般只有3~5天的使用期限。
而方法2较为繁琐,需要提供用户名和密码,网页对其限制性比较大,但可靠性高,且没有时间限制[3]。具体操作步骤如下:(1)通过网址,得到Http头部的Set—cookie值。(2)设置cookie值,post用户名和密码到登录页面。(3)保存返回的set—cookie值,以供方法1使用。(4)设置新的cookie值,再次访问主页,并处理 Location 跳转。
方法1和2各有利弊,本项目由于抓取时间不长。所以直接使用方法1来模拟登录,不仅方便快捷,而且更快实现获取我们想要得到的数据。
2.2 获取用户关注人的总页数与其名称
模拟登录成功后,首先根据用户提供给我们的新浪微博账号(无需密码)进入初始页,由于我们需要爬取该账号关注的人名称,所以得先获取该账户关注人的页数。
步骤如下:(1)进入使用者关注人的第一页。(2)获取该网页的所有文本信息。(3)从文本信息中抽取出页数信息。
关键代码如下:

其中,第三步直接使用XPath表达式,逐级检索,获得最终关键数据:关注人页数。
获取用户名称与获取总页数步骤类似,只是将第三步中提取关键路径改为:user_name1 = selector1.xpath(‘/html/body/div[4]/div[1]/text()’) 即可。
2.3 获取初始用户关注所有人的名称与URL链接
此步为整个过程中较为关键一步,首先得通过链接,从第一页开始获取用户关注人的姓名与URL。这类似2.2,依旧分为3步:进入网址;下载HTML;抽取所需信息。
然而,由于我们需要将其写为一个子函数,且保存两类数据,所以,首先得初始化一个对象items,用以保存从非结构性的数据源提取结构性数据;紧接着,我们按照抽取所需信息的“三步曲”,实现获得当前页面用户关注人的名称与URL链接,随后,我们将获取到的数据保存到items中。由于用户关注人不止一页,而我们之前得到了关注人用户的总页数,此时可以外加一个for循环,逐页访问,获取数据;最后,我们只需要返回items即可。
2.4 写入Excel表格
在获取到我们想要得到的数据后,由于本项目是分析人际关系,且由于新浪微博不存在“重名现象”,所以,我们只需将用户名称与其关注对象名称保存即可,而Excel是较为方便存储的工具,以此作为我们存储信息的文件。
定义一个子函数:excel_write(),传入items与user_name数据;随后,创建Excel表格,定义其名称;Excel表格首行写入关键词:UserName及其HisFollow;最终,定义一个指针index,逐行写入数据。
2.5 广度遍历用户与其关注者
由于第一层的特殊性,随后爬取的第二,三,四……层与其存在部分差异,紧接着,以获取第二至三层数据为例,通过广度遍历获得数据。
思路如下:(1)通过items,获取第二层用户ID。(2)获取第二层用户关注人的总页面。(3)获取用户本身名称。(4)获取用户关注对象所有名称及其URL。(5)写入Excel中。
可以看出来,大体上与2.1~2.4过程类似,只是将2.1的模拟登录改为从items中提取用户ID来;另外,第3步,由于items中其实已经存在第二层用户名称,所以第3步可以直接删除,第一步中直接提取用户名称即可。
其获得部分数据如图1所示。
3 程序的改进与优化
第2节已经完成了程序所需爬取下来的信息,但在运行过程当中,会出现各种各样的问题,本节是在第2节的基础上,对程序进行了改进,提升程序的稳定性、实用性,以及优化程序,使其更为简单合理。
3.1 添加下载延时与访问限速
对一个网站访问过于频繁,往往就会被反爬虫措施所识别和拦截[10],所以,当我们访问网站以及下载网站信息时,往往会设置延时,其中,最简单的是引入sleep库,在需要延时访问或下载信息前加上sleep()即可;其中,括号内填入需要延时的时间。
另外,Scrapy也提供了一种比较智能的方法来解决限速问题,即通过自动限速扩展,该扩展能根据Scrapy服务器及爬取的网站的负载自动限制爬取速度。
3.2 显示提示与出现异常自动处理
由于本程序运行时间较长,当我们需要了解程序运行到哪一步时,不可能中断程序,了解进程。所以,在编写程序时,在相应步骤结束后,加上 print(“… ”) 即可,此优化较为简单,不再叙述。
另外,由于网页的特殊性,程序可能会出现未知错误,而造成中途不再下载数据,浪费时间。所以为了提升程序的健壮性,我们在程序中可能会出现错误的地方加上try…catch…语句,如在获取用户名称时:
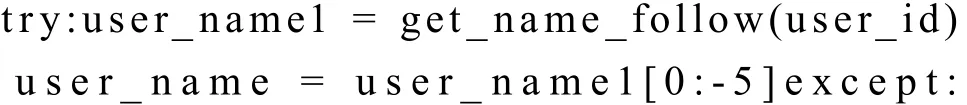
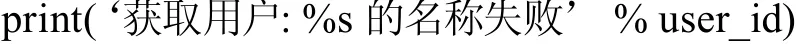

图1 部分爬取数据展示
可以方便地了解在爬取过程中,在哪一步出现了差错,并自动跳过,而不会造成浪费接下来爬取信息的时间。
3.3 翻页功能优化
当我们想要获取关注人信息时,在搜索每名用户时,均要首先获取其关注人页数信息,不仅费时,而且也容易出现错误,此处,我们提出一种新的翻页功能实现的方法,其本质就是通过构造Request并提交Scrapy引擎的过程。
关键步骤是当我们在获取完第n页信息完毕之后,首先抽取下一页的链接,如果存在,便访问下一页,爬取信息,否则跳过。
4 结语
运用Python3丰富的库资源以及快速开发的特点,本文设计并实现了基于新浪微博数据上的社区网络爬虫程序,为研究社会中人物关系者们提供了较为简单方便的新浪微博数据获取程序。该程序使用者仅需提供新浪微博账号即可利用爬虫抓取新浪微博中的人物关联信息,解决了传统爬虫登录、翻页等问题;实验结果表明:该爬虫具有良好的性能,稳定性强,可以投入到日常使用当中,并且有利于对微博的后续挖掘研究。
[参考文献]
[1]杨文刚,韩海涛.大数据背景下基于主题网络爬虫的档案信息采集[J].兰台世界,2015(20):20-21.
[2]郑楷坚,沙瀛.面向主题的社交网络采集技术[J].计算机系统应用,2016(10):173-179.
[3]郭涛,黄铭钧.社区网络爬虫的设计与实现[J].智能计算机与应用,2012(4):65-67.
[4]刘艳平,俞海英,戎沁.Python模拟登录网站并抓取网页的方法[J].微型计算机应用,2015(1):58-60.
[5]魏春蓉,张宇霖.基于新浪微博的社交网络用户关系分析[J].中华文化论坛,2016(9):156-161.
[6]陈琳,任芳.基于Python的新浪微博数据爬虫程序设计[J].技术应用,2016(9):97-99.
[7]罗刚.自己动手写网络爬虫[M].北京:清华大学出版社,2016.
[8]马俊哲.面向微博用户行为数据挖掘的爬虫系统设计与实现[D].武汉:华中科技大学,2016.
[9]范传辉.Python爬虫开发与项目实战[M].北京:机械工业出版社,2017.
[10]陈利婷.大数据时代的反爬虫技术[J].电脑与信息技术,2016(6):60-61.
